Logbook 2022 H2
- What is this about?
- Newer entries
- December 2022
- November 2022
- October 2022
- September 2022
- August 2022
- July 2022
- Older entries
- Today I'll go through the tx traces and related code to alter the graph so we can publish it on the website.
- While looking at the code for the token minting I am noticing a FIXME which sounds like fun:
-- FIXME: This doesn't verify that: -- -- (a) A ST is minted with the right 'HydraHeadV1' name -- (b) PTs's name have the right shape (i.e. 28 bytes long) - Let's do this real quick so we get rid of this FIXME. I am using
lengthOfBytestringto check the length of PT tokens - It is a bit awkward that we are not separating PT's and ST and do a separate check but it also works if we check while folding that the token is EITHER of length 28 (for PT's) OR that it has the name "HydraHeadV1" for ST token.
- Ok submitted a PR so now we can move on with the tx traces.
- Continuing with the ST token checks in the head validators
- After removing traces tx sizes went down for around 1kb. Decided to leave the traces out.
- Let's see how much the tx size is reduced by removing traces from initial and commit validators and if they drop significantly I'll remove them.
- Results for the fanout tx, top ones are new and the bottom ones are from the previous commit:
UTxO Tx size % max Mem % max CPU Min fee ₳
1 13459 10.90 4.72 0.86
2 13430 11.79 5.34 0.88
3 13531 13.69 6.37 0.90
5 13603 16.98 8.23 0.95
10 13718 23.96 12.38 1.04
50 15157 85.19 47.72 1.85
59 15477 99.16 55.76 2.03
UTxO Tx size % max Mem % max CPU Min fee ₳
1 14272 10.91 4.72 0.90
2 14309 12.18 5.50 0.92
3 14213 12.95 6.08 0.92
5 14350 16.66 8.11 0.97
10 14595 24.36 12.53 1.08
50 15972 84.90 47.61 1.88
59 16226 98.49 55.49 2.06
So we can see the drop in the tx size around 750/800 bytes. I'll leave the traces out for now and consult with the team if they think we should still keep them around while working on smart contracts.
- Refactoring the code and preparing it for a review.
- Already worked with Arnaud on this and we had a great pairing session before Christmas, go Hydra!
- Each head script datum now contains the head policy id
- Need to make sure every validator checks for presence and correctness of the ST token
- With the new changes the tx size for the fanout tx exceeds 16kb which is a new thing
- Fanout tx doesn't use reference inputs so this looks lika a way forward
- Adding ref inputs didn't work out the way I thought it would. Decided to concentrate on CollectCom tx being too big instead.
- Fixed the collectCom mutation test by adding the logic to check if head id was not manipulated
- Fixed fanout tx size by reducing the number of outputs from 70 to 60. This needs investigating. Tx size is expected to grow bigger
since I added some hew values in the head
Statebut it would be good to start reducing script sizes since we are at point where we are dealing with the on-chain part of the code more so ideally we will get some time to optimize scripts. - Let's check how much we can reduce script size just by removing traces. We got 16399 for fanout tx in the previous test run and now after removing traces the tx size is below 16kb. Nice! But unfortunatelly I'd like to keep traces around so let's see what other tricks we can utilize.
- When we wanted to open a head from the
hydra-node:unstableimage, we realised the last released--hydra-script-tx-idis not holding the right hydra scripts (as they changed onmaster)- We also thought that a cross-check could be helpful here. i.e. the
hydra-nodeerroring if the found scripts are not what was compiled into it. Is it not doing this already?
- We also thought that a cross-check could be helpful here. i.e. the
- SN published the scripts onto
previewtestnet usinghydra-nodefrom revision03f64a7dc8f5e6d3a6144f086f70563461d63036with the command
docker run --rm -it -v /data:/data ghcr.io/input-output-hk/hydra-node:unstable publish-scripts --network-id 2 --node-socket /data/cardano-node/node.socket --cardano-signing-key /data/credentials/sebastian.cardano.sk
(adapt as necessary to paths of volumes, sockets and credentials)
- A
--hydra-scripts-tx-idfor revision03f64a7dc8f5e6d3a6144f086f70563461d63036is:9a078cf71042241734a2d37024e302c2badcf319f47db9641d8cb8cc506522e1
-
Implementing PR review comments I am noticing a failing test on hydra-node related to MBT. The test in question is implementation matches model and the problem is that test never finishes in time. After adding
traceDebuginrunIOSimPropI noticed there is aCommandFailedlog message printed but no errors. -
Sprinkled some
traceto appropriate places whereCommandFailed(in theHeadLogic) and also printed the head state when this happens. Turns out head state is inIdleStatewhich is weird since we are trying to do some actions in the test so head must be opened. Also we are trying toCommitright before so might be related. And thecontentsfield contains this kind of utc time1970-01-01T00:00:16.215388918983Zso might be that changes in theTimeHandleare related... -
Back to
Modelto try to find the culprit. Looks to me like the Init tx didn't do what it is supposed to do so we are stuck at this state... -
Intuition tells me this has to do with changes in the contestation period (now it is part of the
Seedphase in MBT) so I inspected where did we set the values and found in themockChainAndNetworkthat we are using the default value for it! Hardcoding it to 1 made the tests pass! -
Turns out it is quite easy to fix this just by introducing the new parameter to
mockChainAndNetworksince we already have the CP coming in from theSeedat hand. All great so far, I am really great to be able to find out the cause of this since I am not that familiar with MBT. Anyway, all tests are green onhydra-nodeso I can proceed doing the PR review changes.
- After getting everything to build in Github actions and (likely still) via Cicero, the docker build is still failing:
#14 767.2 > Error: Setup: filepath wildcard
#14 767.2 > 'config/cardano-configurations/network/preprod/cardano-node/config.json' does
#14 767.2 > not match any files.
-
Checked the working copy and there is a
hydra-cluster/config/cardano-configurations/network/preprod/cardano-node/config.jsonfile checked out -
This workflow feels annoying and lengthy (nix build in a docker image build). Maybe using
nixto build the image will be better: https://nixos.org/guides/building-and-running-docker-images.html -
After switching to nix build for images I run into the same problem again:
> installing > Error: Setup: filepath wildcard > 'config/cardano-configurations/network/preprod/cardano-node/config.json' does > not match any files.-> Is it cabal not knowing these files? When looking at the nix store path with the source it’s missing the submodule files.
-
The store path in question is
/nix/store/fcd86pgvs6mddwyvyp5mhxfwsi63g873-hydra-root-hydra-cluster-lib-hydra-cluster-root/hydra-cluster/config -
It might be because haskell.nix filters too much files out (see https://input-output-hk.github.io/haskell.nix/tutorials/clean-git.html?highlight=cleangit#cleangit)
My hydra-node is not respoinding since, approximately, december the 13th at 2am.

When trying to ssh into the EC2 hosting it, I get timeout errors.
When looking at the AWS consoleI see that:
- all the checks for the EC2 are ok (2/2 checks passed);
- the CPU utilization, is stuck at, approximately 11% since december the 13th at 2am UTC;
- the CPU Credit Balance is down to 0 since the same time, more or less.


I understand that:
- december the 11th at 15:06 the EC2 starts consuming the CPU burst credit
- december the 11th at 17:19 the EC2 stops consuming the CPU burst credit and start regaining credits
- december the 12th at 10:31 the EC2 starts consuming the CPU burst credit again
- december the 12th at 12:48 CPU burst credit is down to 0
Then we see some CPU burst credit regained but that's marginal, the machine is mainly at 0 CPU burst.
So this EC2 is eating more CPU than it can. I don't know what is consuming the CPU. The burst mode of this instance is set to standard so it can't use more than the daily burst credit. I switch to unlimited to see what happens.
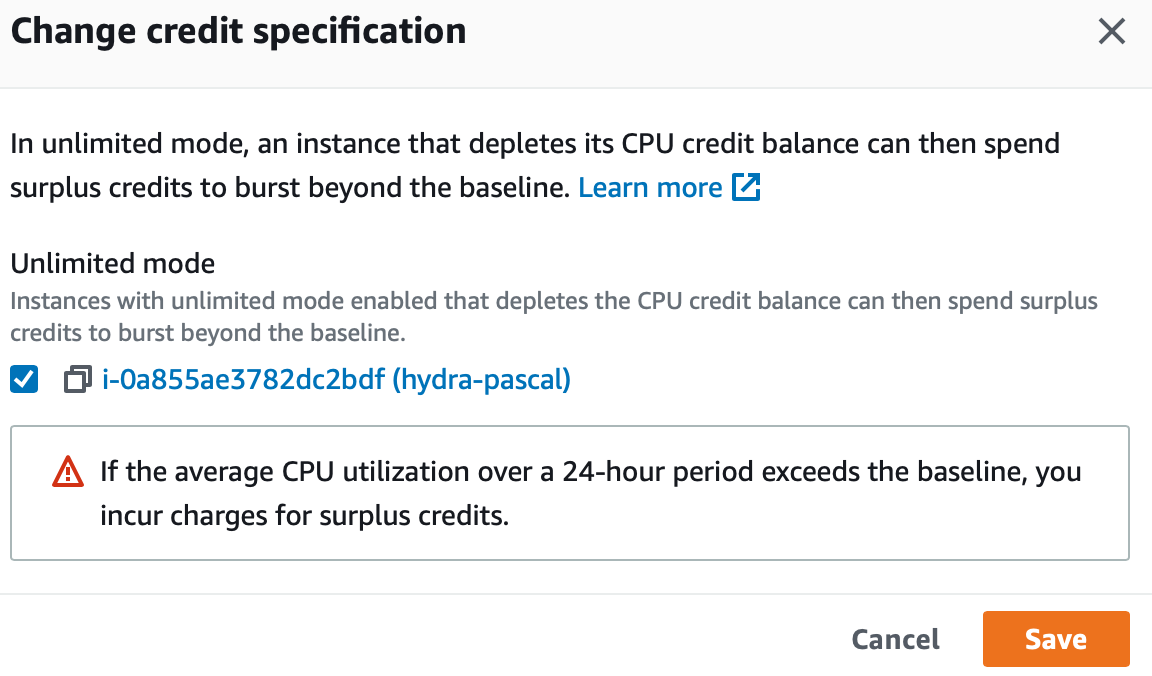
I can see that the machine is now eating as much CPU as it wants. However I'm still not able to connect with ssh. I reboot the machine and now it's ok. I'll let it run and see what happens.
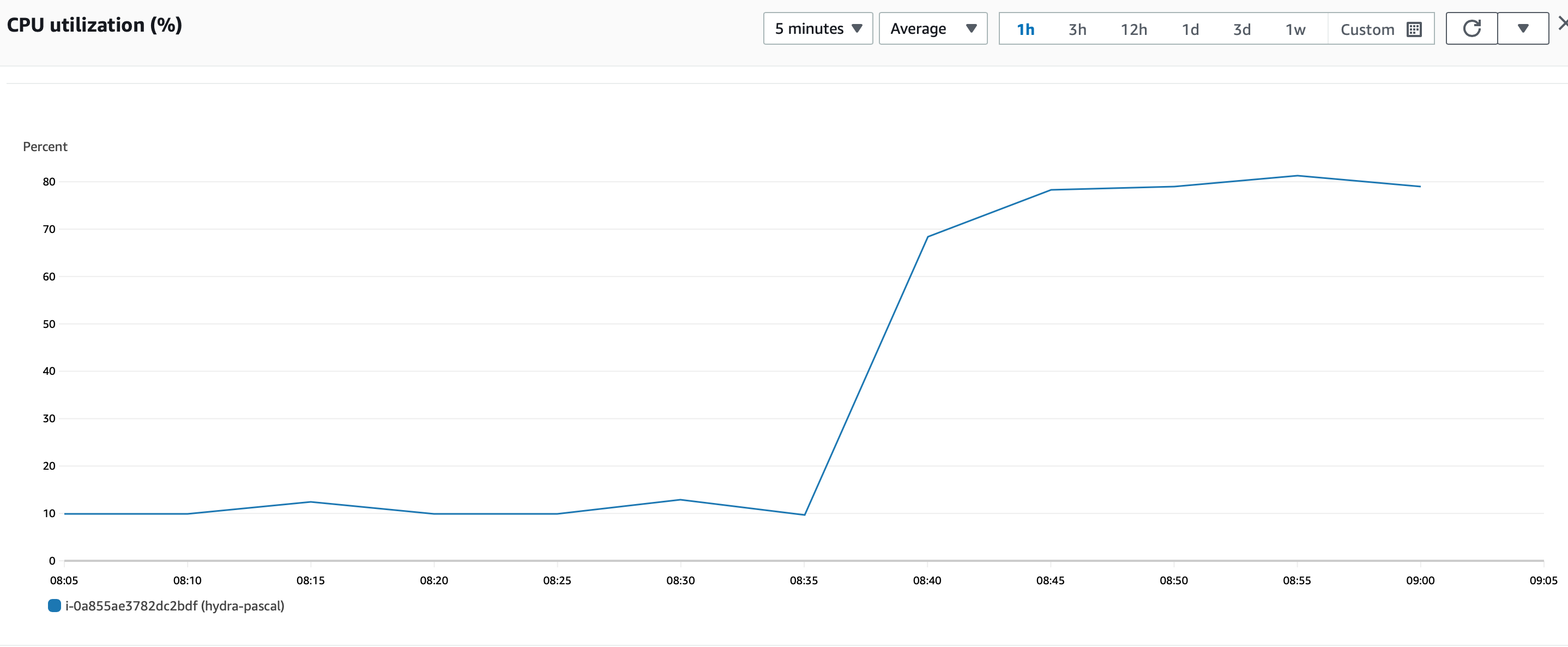
SB had the same problem so we have also change his machine settings but differently so we can compare:
- PG: t2.micro with unlimited credit
- SB: t2.xlarge with standard credit
- Quickly looking into the
PPViewHashesDontMatcherror we receive on the “commitTx using reference scripts” work - The error comes from the
cardano-ledgerand is raised if the script integrity hash of a given tx body does not match the one the ledger (in thecardano-node) computes. - We checked the protocol parameters used yesterday, they are the same.
- What is left are datums, redeemers and the scripts which are converted to “language views”. Are reference scripts also part of the hash? Shouldn’t they be?
- The
cardano-ledgerpasses (and computes) the integrity hash withsNeededscripts.
(Ensemble continued)
-
languagesis used to lookup languages forgetLanguageViewand is coming fromAlonzo.TxInfo! This is a strong indicator, that this function does not take into account reference scripts! Furthermore the return value isSet Language, which would explain why it works for other transactions (abort), but now starts failing forcommit. -
txscriptsis actually fine as it is defined forBabbageEraand would consider reference scripts. But onlyMap.restrictKeysthe passedsNeeded-> where is this coming from. - It ultimately uses function
scriptsNeededFromBodyfor this and it seems it would pick up thespendscripts frominputsTxBodyL. While this not includes reference inputs, it would still resolve tov_initialin our case. i.e. this is fine. - We double checked the
PlutusV2cost model in the protocol parameters again. - Our wallet code, however, is using the
txscriptsof the witness set .. is this different? - We realized that the
langsin the Wallet'sscriptIntegrityHashcomputation is empty, hard-coding it to onlyPlutusV2makes the test pass. Case closed.
How to build a profiled version of hydra packages:
Enter a nix-shell without haskell.nix (It seems haskell.nix requires some more configuration which I was not able to figure out):
nix-shell -A cabalOnly
Configure the following flag in the cabal.project.local
package plutus-core
ghc-options: -fexternal-interpreter
then just run cabal build all --enable-profiling 🎉 Of course it will take ages but then one should be able to run tests and hydra-node with profiling enabled.
I was able to produce a profile report for a single test (the conflict-free liveness property):
Fri Dec 9 13:26 2022 Time and Allocation Profiling Report (Final)
tests +RTS -N -p -RTS -m liveness
total time = 1.44 secs (5767 ticks @ 1000 us, 4 processors)
total alloc = 5,175,508,264 bytes (excludes profiling overheads)
COST CENTRE MODULE SRC %time %alloc
psbUseAsSizedPtr Cardano.Crypto.PinnedSizedBytes src/Cardano/Crypto/PinnedSizedBytes.hs:(211,1)-(213,17) 17.5 0.0
execAtomically.go.WriteTVar Control.Monad.IOSim.Internal src/Control/Monad/IOSim/Internal.hs:(982,55)-(986,79) 9.7 10.0
execAtomically.go.ReadTVar Control.Monad.IOSim.Internal src/Control/Monad/IOSim/Internal.hs:(971,54)-(974,68) 3.3 2.5
foldF Control.Monad.Free.Church src/Control/Monad/Free/Church.hs:194:1-41 2.4 2.2
reschedule.Nothing Control.Monad.IOSim.Internal src/Control/Monad/IOSim/Internal.hs:(690,5)-(715,25) 2.4 1.4
psbToBytes Cardano.Crypto.PinnedSizedBytes src/Cardano/Crypto/PinnedSizedBytes.hs:140:1-46 2.3 11.5
applyRuleInternal Control.State.Transition.Extended src/Control/State/Transition/Extended.hs:(586,1)-(633,34) 2.1 2.5
encodeTerm UntypedPlutusCore.Core.Instance.Flat untyped-plutus-core/src/UntypedPlutusCore/Core/Instance/Flat.hs:(108,1)-(116,67) 2.0 3.3
psbCreate Cardano.Crypto.PinnedSizedBytes src/Cardano/Crypto/PinnedSizedBytes.hs:(216,1)-(222,20) 1.6 0.0
schedule.NewTimeout.2 Control.Monad.IOSim.Internal src/Control/Monad/IOSim/Internal.hs:(340,43)-(354,87) 1.5 0.9
blake2b_libsodium Cardano.Crypto.Hash.Blake2b src/Cardano/Crypto/Hash/Blake2b.hs:(37,1)-(43,104) 1.4 1.4
toBuilder Codec.CBOR.Write src/Codec/CBOR/Write.hs:(102,1)-(103,57) 1.4 1.7
serialise Codec.Serialise src/Codec/Serialise.hs:109:1-48 1.4 2.6
liftF Control.Monad.Free.Class src/Control/Monad/Free/Class.hs:163:1-26 1.2 1.0
stepHydraNode Hydra.Node src/Hydra/Node.hs:(131,1)-(159,51) 1.2 0.7
reschedule.Just Control.Monad.IOSim.Internal src/Control/Monad/IOSim/Internal.hs:(680,5)-(684,66) 1.2 1.5
psbToByteString Cardano.Crypto.PinnedSizedBytes src/Cardano/Crypto/PinnedSizedBytes.hs:143:1-38 1.1 0.4
getSize Flat.Class src/Flat/Class.hs:51:1-20 1.1 0.6
hashWith Cardano.Crypto.Hash.Class src/Cardano/Crypto/Hash/Class.hs:(125,1)-(129,13) 0.9 1.3
. PlutusTx.Base src/PlutusTx/Base.hs:48:1-23 0.9 1.1
toLazyByteString Codec.CBOR.Write src/Codec/CBOR/Write.hs:86:1-49 0.7 8.5
schedule.Output Control.Monad.IOSim.Internal src/Control/Monad/IOSim/Internal.hs:(282,37)-(285,56) 0.7 1.3
getDefTypeCheckConfig PlutusCore.TypeCheck plutus-core/src/PlutusCore/TypeCheck.hs:56:1-74 0.7 1.0
schedule.Atomically Control.Monad.IOSim.Internal src/Control/Monad/IOSim/Internal.hs:(430,41)-(478,24) 0.7 1.6
serialiseAddr Cardano.Ledger.Address src/Cardano/Ledger/Address.hs:146:1-49 0.5 7.2
typeOfBuiltinFunction PlutusCore.Builtin.Meaning plutus-core/src/PlutusCore/Builtin/Meaning.hs:(78,1)-(79,50) 0.4 2.0
Running integration tsets with profiling on gives the following hotspots:
fromList Data.Aeson.KeyMap src/Data/Aeson/KeyMap.hs:236:1-30 16.2 20.9
unsafeInsert Data.HashMap.Internal Data/HashMap/Internal.hs:(888,1)-(918,76) 8.4 10.0
toHashMapText Data.Aeson.KeyMap src/Data/Aeson/KeyMap.hs:540:1-62 6.2 11.9
camelTo2 Data.Aeson.Types.Internal src/Data/Aeson/Types/Internal.hs:(836,1)-(842,33) 4.6 6.4
fromHashMapText Data.Aeson.KeyMap src/Data/Aeson/KeyMap.hs:544:1-66 4.2 8.4
hashByteArrayWithSalt Data.Hashable.LowLevel src/Data/Hashable/LowLevel.hs:(109,1)-(111,20) 2.7 0.0
toList Data.Aeson.KeyMap src/Data/Aeson/KeyMap.hs:242:1-28 2.4 5.0
fromList Data.HashMap.Internal.Strict Data/HashMap/Internal/Strict.hs:638:1-70 2.3 0.0
genericToJSON Data.Aeson.Types.ToJSON src/Data/Aeson/Types/ToJSON.hs:185:1-49 2.3 1.1
flattenObject Data.Aeson.Flatten plutus-core/src/Data/Aeson/Flatten.hs:(37,1)-(46,54) 2.0 2.8
applyCostModelParams PlutusCore.Evaluation.Machine.CostModelInterface plutus-core/src/PlutusCore/Evaluation/Machine/CostModelInterface.hs:191:1-70 1.7 1.6
It seems generating JSON (probably for writing logs?) is the most costly activity that's happening inside the hydra-node.
-
Started with running the hydra cluster tests - I observe
OutsideValidityIntervalUTxOerror when running the single party hydra head test. -
I am suspecting the contestation period value is 1 is causing this based on the log output. Seems like tx validity lower/upper bounds are 18/19 and the network is at slot 19 already so the tx is expired. When changing the contestation period to just 2 the test is passing. I suspected that wait command in the test was causing this so reducing the wait from 600 to 10 and then adding back the contestation period to its original value 1 is also working.
-
Let's run the hydra-cluster and hydra-node tests again to see if there are still issues. All green! We are good to commit and continue.
e4a30f2 -
It is time to tackle the next issue. We want to ignore Init transactions that specify invalid contestation period. And by invalid we consider any contestation period that is different to what we have set when starting up our hydra-node. Ideally we would like to have the log output and/or error out in this case but it seems our architecture is not so flexible to implement this easily. This is one point we would like to address in the future (not the scope of this work here).
-
When observing txs we are already checking if parties/peers match to our node config and all needed PTs exist. I am noticing the readme that hints that this function
observeInitTxshould perhaps return anEitherso we can have some logging in place with the appropriate error message instead of just getting backNothingvalue.Seems this affect a bit bigger piece of code so need to decide if this is a job for a separate PR.
I passed the contestation period coming in from
ChainContexttoobserveInitTxand usedguardto prevent the rest of the code from running in case CP is not matched. Also added a quick test to make sure this is checked (Ignore InitTx with wrong contestation period).f5ef94b -
Now it looks like we got green in all of the tests. Time to see how we can make this code better/remove redundant things we perhaps don't need anymore as the outcome of Init not containing the contestation period. My main suspect is the TUI.hs module and I think we may be able to improve things in there. Or maybe I am just crazy since I didn't find anywhere. Ok, the code I was reffering to is in the MBT (Model Based Testing) framework. I made the changes so that we generate contestation period in the seeding phase instead as part of the
Initconstructor.I made sure all of the places in test code do not use any hardcoded value for the contestation period but re-use the value we have in the underlying context (
ChainContext,HydraContextorEnvironmenttypes)Added the autors option to docusaurus and the actual ADR21 with appropriate avatars.
Now ADR21 is ready to be reviewed!
hydra-node test take 5 minutes to run (excluding compilation time). This makes it painful to run them everytime we change something and it has subtle producitvity impact on the team.
As a first objective, I'd like this tests to take less than a minute. We have 26 test files, that leaves 2.3 seconds per test file.
Time per test file:
-
Hydra.Options: 0.1050 seconds
-
Hydra.Crypto: 0.0062 seconds
-
Hydra.SnapshotStrategy: 0.0655 seconds
-
Hydra.Model: 33.8062 seconds
-
Hydra.Network: 10.2711 seconds
-> Trying to improve Hydra.Network before exploring more
We manage to make existing tests pass by fixing how the start validity time of a close transaction in computed.
Then we use the contestation period as a close grace time replacement for close transactions.
Now that the contestation period has been added as a CLI parameter, we remove it from the API to have something coherent. That means updating all the end to end tests to set the contestation perdiod when starting the node under test instead of on API calls.
Next step is to use the contestation period to filter out head init transaction that we want to be part of. It can be discussed at which level we should do that. However, we already do that kind of stuff for filtering out head init transaction for which we do not agree with the list of members. So we decide to add that in the same part of the code.
Starting from a failing test in hydra-cluster (two heads on the same network do not conflict) - we don't want to just fix it
- we want to really understand what is happening.
We see the error message related to PastHorizon:
user error (PastHorizon {pastHorizonCallStack =
...
,("interpretQuery",SrcLoc {srcLocPackage = "hydra-node-0.9.0-inplace", srcLocModule = "Hydra.Chain.Direct.TimeHandle"
, srcLocFile = "src/Hydra/Chain/Direct/TimeHandle.hs", srcLocStartLine = 91
...
and line related to TimeHandle looks interesting since it points to a place in our code. Namely a function to convert time to slot number slotFromUTCTime.
Ok, so it must be we are handling time incorrectly since we know that we introduced lower tx bound when working on this ADR.
Let's introduce some traces in code to see what do the slots look like when we submit a close tx.
Function name fromPostChainTx doesn't sound
like a good name for it since what we do here is create a tx that will be posted a bit later on after finalizeTx in the submitTx. I am renaming
it to prepareTxToPost.
Traces don't get printed from running the tests in the ghci so let's juse use cabal.
Ok, that was not the issue - prints are still not shown. Let's use error to stop and determine if we are in the right code path.
At this point it is pretty obvoius that constructing a close tx is not erroring out but we know that PastHorizon is happening
when we try to convert time to slots. In the (renamed) function prepareTxToPost we are actually invoking currentPointInTime function so
let's see if that is what is failing here. Bingo! We are correct. This means that the time conversion is failing.
Lets reduce the defaultContestationPeriod
to 10 slots instead of 100 and see what happens. Oh nice, the tests do pass now! But how is this actually related to our tests? My take is we already
plugged in our node's contestationPeriod in the init transaction instead of relying on the client so each time we change this value it needs to
be in sync with the network we are currently in. 100 slots seems to be too much for devnet.
Let's run the hydra-node tests and see if they are green still. It is expected to see json schema missmatches since we introduced a new --contestation-period
param to hydra-node executable. Vast majority of tests are still green but let's wait until the end. Three failing tests - not so bad. Let's inspect.
These are the failing ones:
- Hydra.Node notifies client when postTx throws PostTxError
- Hydra.Options, Hydra Node RunOptions, JSON encoding of RunOptions, produces the same JSON as is found in golden/RunOptions.json
- Hydra.Options, Hydra Node RunOptions, roundtrip parsing & printing
Nice to not see any time failure. We can quickly fix these, that should not be hard.
The fix involves introducing --contestation-period flag into the test cases and fixing the expected json for running options.
Now we are able to proceed further down the rabbit hole and we can actually see our validator failing which is great! We will be able to fix it now.
- When looking into the
stdPR, it seems that the normalnix-shell/nix-buildis not picking up the overlays correctly anymore. Trying to get the project built viahaskell.nixfrom theflake.nixto resolve it.
- We add a contestation-period CLI flag
- We use the contestation-period to open a head (instead of the API param)
- Use the contestation period from the environment instead of the API param
- populate the environment with the CLI flag value
Then we're stuck with some obscure ambiguous arbitrary definition for Natural :(
- Exporting confluence pages to markdown. The node module + pandoc worked, probably pandoc alone would be good enough: https://community.atlassian.com/t5/Confluence-questions/Does-anyone-know-of-a-way-to-export-from-confluence-to-MarkDown/qaq-p/921126
When updating my hydra node to use the unstable version, The CI building my beloved hydra_setup image failed.
Static binary for cardano-node is not available anymore. I opened the following issues to make dev portal and cardano-node maintainers to know about it:
- https://github.com/cardano-foundation/developer-portal/issues/871
- https://github.com/input-output-hk/cardano-node/issues/4688
In the meantime, I happened to still have a static binary for cardano-node 1.35.4 available locally on my machine 😅 so I decided to move forward with a locally built docker image straight on my hydra node.
The EC2 I use to run my cardano-node and hydra-node is deterministically crashing. I see a huge raise in CPU usage and then the machine becomes unreachable.
Looking at the logs:
- I don't see any log after 12:00 UTC eventhough the machine was still up until 12:54
- I see a shitload of cardano-node logs about PeerSelection around 11:48
- I also see super huge cardano-node log messages like this one:
Nov 29 11:48:47 ip-172-31-45-238 391b6ab80c0b[762]: [391b6ab8:cardano.node.InboundGovernor:Info:110] [2022-11-29 11:47:58.77 UTC] TrMuxErrored (ConnectionId {localAddress = 172.17.0.2:3001, remoteAddress = 89.160.112.162:2102}) (InvalidBlock (At (Block {blockPointSlot = SlotNo 2683396, blockPointHash = 1519d70f2ab7eaa26dc19473f3439e194cfc85d588f5186c0fa1f2671a6c26dc})) e005ad37cc9f148412f53d194c3dc63cf9cc5161f2b6de7eb5c00f9f85bd331e (ValidationError (ExtValidationErrorLedger (HardForkLedgerErrorFromEra S (S (S (S (S (Z (WrapLedgerErr {unwrapLedgerErr = BBodyError (BlockTransitionError [ShelleyInAlonzoPredFail (LedgersFailure (LedgerFailure (UtxowFailure (UtxoFailure (FromAlonzoUtxoFail (UtxosFailure (ValidationTagMismatch (IsValid True) (FailedUnexpectedly (PlutusFailure "\nThe 3 arg plutus script (PlutusScript PlutusV2 ScriptHash \"e4f24686d294de43ad630cdb95975aac9616f180bb919402286765f9\") fails.\nCekError An error has occurred: User error:\nThe machine terminated because of an error, either from a built-in function or from an explicit use of 'error'.\nCaused by: (verifyEcdsaSecp256k1Signature #0215630cfe3f332151459cf1960a498238d4de798214b426d4085be50ac454621f #dd043434f92e27ffe7c291ca4c03365efc100a14701872f417d818a06d99916f #b9c12204b299b3be0143552b2bd0f413f2e7b1bd54b7e9281be66a806853e72a387906b3fabeb897f82b04ef37417452556681e057a2bfaafd29eefa15e4c48e)\nThe protocol version is: ProtVer {pvMajor = 8, pvMinor = 0}\nThe data is: Constr 0 [B \"#`ZN\\182\\189\\134\\220\\247g,e%+\\239\\241\\DLE3\\156H\\249M\\255\\254\\254\\t\\146\\157A\\188j\\138\",I 0]\nThe redeemer is: Constr 0 [List [B \"\\185\\193\\\"\\EOT\\178\\153\\179\\190\\SOHCU++\\208\\244\\DC3\\242\\231\\177\\189T\\183\\233(\\ESC\\230j\\128hS\\231*8y\\ACK\\179\\250\\190\\184\\151\\248+\\EOT\\239\\&7AtRUf\\129\\224W\\162\\191\\170\\253)\\238\\250\\NAK\\228\\196\\142\",B \"j\\SOV\\184g\\255\\196x\\156\\201y\\131r?r2\\157p5f\\164\\139\\136t-\\SI\\145(\\228u2YE\\213\\&3o\\145\\232\\223\\&4\\209\\213\\151\\207q.\\SO \\192\\&9\\176\\195\\\\\\251\\&4GG\\238\\238\\249M\\213\\DC4\\CAN\",B \"m\\151Fz;\\151\\206\\&0\\155\\150\\STX\\185#\\177M\\234\\206X\\208\\231\\172\\222,}\\n\\131\\189qR\\229\\170\\157r\\255rl\\NAKe\\240J\\207\\SUB\\135\\225\\170\\188\\168O\\149\\173\\165\\132\\150a+Xpik\\181\\138{z>\",B \"\\DC4\\154\\181P\\DC2\\CANXd\\197_\\254|t\\240q\\230\\193t\\195h\\130\\181\\DC3|j&\\193\\239\\210)\\247d!rRVW\\219mY\\252\\SYNA\\130af+m\\169U\\US[%F^\\241\\DC2n\\132\\137_\\RS\\r\\185\",B \"|\\ESC\\239!\\162\\172\\\\\\180\\193'\\185\\220R\\242\\157ir\\246\\161\\&2\\177\\&6\\160\\166\\136\\220\\154<l}M\\222=\\212\\241\\245\\231\\FS(!\\251\\197\\194.~\\239\\146\\253n`$`\\229\\182\\208M\\164\\181\\US\\134z9\\172\\r\"],List [B \"\\STX\\NAKc\\f\\254?3!QE\\156\\241\\150\\nI\\130\\&8\\212\\222y\\130\\DC4\\180&\\212\\b[\\229\\n\\196Tb\\US\",B \"\\STXQ&\\EM\\255\\237\\163\\226\\213T8\\195\\240\\250KW\\159\\DLE\\147\\165\\162b\\169M\\237\\ACK\\131gB\\135!\\140\\ACK\",B \"\\STX\\130\\SUB\\240\\244\\171P\\181\\DC2\\STX\\213\\153\\224u\\STX\\r\\160/\\192\\UST\\224\\174\\NAK\\158z\\153\\RSl\\ESCwS\\243\",B \"\\STX\\156\\240\\128\\199\\158\\247k\\200R\\185\\136\\203a\\160\\DC1SA@J\\192\\146\\172\\224\\211\\233\\193g\\230R\\128\\183\\&3\",B \"\\ETX\\245{\\226\\\\-\\181\\208\\SYNsS\\154A\\ACK\\EOTG%\\171&\\217\\US\\202\\182\\&2\\139Y>\\DC2q\\156+\\189\\203\"],List [B \"\\STX\\233\\198Z\\134\\148\\223\\252%\\184\\DEL%\\152\\147\\156\\FS\\250\\203*\\187\\154\\185\\&8\\242\\250\\236\\136\\185Ik\\250j\\ACK\",B \"\\ETX!\\202\\ETX=U_\\234\\&0\\153\\229\\SIU8\\144\\255\\229\\196V=\\176`L<7/\\199\\142\\186\\NAK\\185\\238\\184\",B \"\\ETXN\\172S\\136\\255\\145%\\NAK@*X\\136)\\179\\252\\203\\184\\145\\ETX-\\DC3\\ENQ\\169\\190\\140\\227\\192\\\\\\189pR\\153\",B \"\\ETXW|%\\221U\\212\\ENQO\\DC4x\\232\\SUB+\\252\\162\\&4>\\166\\223tl/\\228\\138\\246n\\243\\158S\\145l\\255\",B \"\\ETX\\138\\250\\STXKv\\v\\USmQ[[\\ENQ\\169\\149\\150\\221\\255\\246\\205U\\SYN\\239\\145>\\245,\\SYN\\211\\132\\248\\174\\r\"],Constr 1 []]\nThe third data argument, does not decode to a context\nConstr 0 [Constr 0 [List [Constr 0 [Constr 0 [Constr 0 [B \"6\\204\\149\\151#cV\\247\\243\\CAN\\167\\195?1\\153\\ACK\\195Q\\234\\198\\171 \\169]\\ENQ\\197\\151\\233\\ACK\\150\\159\\234\"],I 0],Constr 0 [Constr 0 [Constr 0 [B \"\\v\\183\\239\\181\\209\\133\\NUL\\244\\n\\147\\155\\148\\243\\131Z\\133\\181ae$\\170Z-J\\167\\142\\GS\\ESC\"],Constr 1 []],Map [(B \"\",Map [(B \"\",I 9957062417)])],Constr 0 [],Constr 1 []]],Constr 0 [Constr 0 [Constr 0 [B \"6\\204\\149\\151#cV\\247\\243\\CAN\\167\\195?1\\153\\ACK\\195Q\\234\\198\\171 \\169]\\ENQ\\197\\151\\233\\ACK\\150\\159\\234\"],I 1],Constr 0 [Constr 0 [Constr 1 [B \"\\228\\242F\\134\\210\\148\\222C\\173c\\f\\219\\149\\151Z\\172\\150\\SYN\\241\\128\\187\\145\\148\\STX(ge\\249\"],Constr 1 []],Map [(B \"\",Map [(B \"\",I 1310240)]),(B \"\\SUB\\236\\166\\157\\235\\152\\253\\157y\\140YS)\\226\\DC4\\161\\&7E85\\161[0\\171\\193\\238\\147C\",Map [(B \"\",I 1)])],Constr 2 [Constr 0 [B \"#`ZN\\182\\189\\134\\220\\247g,e%+\\239\\241\\DLE3\\156H\\249M\\255\\254\\254\\t\\146\\157A\\188j\\138\",I 0]],Constr 1 []]]],List [],List [Constr 0 [Constr 0 [Constr 0 [B \"\\v\\183\\239\\181\\209\\133\\NUL\\244\\n\\147\\155\\148\\243\\131Z\\133\\181ae$\\170Z-J\\167\\142\\GS\\ESC\"],Constr 1 []],Map [(B \"\",Map [(B \"\",I 9956501143)])],Constr 0 [],Constr 1 []],Constr 0 [Constr 0 [Constr 1 [B \"\\228\\242F\\134\\210\\148\\222C\\173c\\f\\219\\149\\151Z\\172\\150\\SYN\\241\\128\\187\\145\\148\\STX(ge\\249\"],Constr 1 []],Map [(B \"\",Map [(B \"\",I 1310240)]),(B \"\\SUB\\236\\166\\157\\235\\152\\253\\157y\\140YS)\\226\\DC4\\161\\&7E85\\161[0\\171\\193\\238\\147C\",Map [(B \"\",I 1)])],Constr 2 [Constr 0 [B \"\\133J\\141\\196.|\\153M\\160\\SOH\\137\\183=k\\238\\130\\SYN4\\DEL\\NUL\\209\\US\\139\\SI\\211|\\132b\\NUL\\ETB\\fM\",I 1]],Constr 1 []]],Map [(B \"\",Map [(B \"\",I 561274)])],Map [(B \"\",Map [(B \"\",I 0)])],List [],Map [],Constr 0 [Constr 0 [Constr 0 [],Constr 1 []],Constr 0 [Constr 2 [],Constr 1 []]],List [],Map [(Constr 1 [Constr 0 [Constr 0 [B \"6\\204\\149\\151#cV\\247\\243\\CAN\\167\\195?1\\153\\ACK\\195Q\\234\\198\\171 \\169]\\ENQ\\197\\151\\233\\ACK\\150\\159\\234\"],I 1]],Constr 0 [List [B \"\\185\\193\\\"\\EOT\\178\\153\\179\\190\\SOHCU++\\208\\244\\DC3\\242\\231\\177\\189T\\183\\233(\\ESC\\230j\\128hS\\231*8y\\ACK\\179\\250\\190\\184\\151\\248+\\EOT\\239\\&7AtRUf\\129\\224W\\162\\191\\170\\253)\\238\\250\\NAK\\228\\196\\142\",B \"j\\SOV\\184g\\255\\196x\\156\\201y\\131r?r2\\157p5f\\164\\139\\136t-\\SI\\145(\\228u2YE\\213\\&3o\\145\\232\\223\\&4\\209\\213\\151\\207q.\\SO \\192\\&9\\176\\195\\\\\\251\\&4GG\\238\\238\\249M\\213\\DC4\\CAN\",B \"m\\151Fz;\\151\\206\\&0\\155\\150\\STX\\185#\\177M\\234\\206X\\208\\231\\172\\222,}\\n\\131\\189qR\\229\\170\\157r\\255rl\\NAKe\\240J\\207\\SUB\\135\\225\\170\\188\\168O\\149\\173\\165\\132\\150a+Xpik\\181\\138{z>\",B \"\\DC4\\154\\181P\\DC2\\CANXd\\197_\\254|t\\240q\\230\\193t\\195h\\130\\181\\DC3|j&\\193\\239\\210)\\247d!rRVW\\219mY\\252\\SYNA\\130af+m\\169U\\US[%F^\\241\\DC2n\\132\\137_\\RS\\r\\185\",B \"|\\ESC\\239!\\162\\172\\\\\\180\\193'\\185\\220R\\242\\157ir\\246\\161\\&2\\177\\&6\\160\\166\\136\\220\\154<l}M\\222=\\212\\241\\245\\231\\FS(!\\251\\197\\194.~\\239\\146\\253n`$`\\229\\182\\208M\\164\\181\\US\\134z9\\172\\r\"],List [B \"\\STX\\NAKc\\f\\254?3!QE\\156\\241\\150\\nI\\130\\&8\\212\\222y\\130\\DC4\\180&\\212\\b[\\229\\n\\196Tb\\US\",B \"\\STXQ&\\EM\\255\\237\\163\\226\\213T8\\195\\240\\250KW\\159\\DLE\\147\\165\\162b\\169M\\237\\ACK\\131gB\\135!\\140\\ACK\",B \"\\STX\\130\\SUB\\240\\244\\171P\\181\\DC2\\STX\\213\\153\\224u\\STX\\r\\160/\\192\\UST\\224\\174\\NAK\\158z\\153\\RSl\\ESCwS\\243\",B \"\\STX\\156\\240\\128\\199\\158\\247k\\200R\\185\\136\\203a\\160\\DC1SA@J\\192\\146\\172\\224\\211\\233\\193g\\230R\\128\\183\\&3\",B \"\\ETX\\245{\\226\\\\-\\181\\208\\SYNsS\\154A\\ACK\\EOTG%\\171&\\217\\US\\202\\182\\&2\\139Y>\\DC2q\\156+\\189\\203\"],List [B \"\\STX\\233\\198Z\\134\\148\\223\\252%\\184\\DEL%\\152\\147\\156\\FS\\250\\203*\\187\\154\\185\\&8\\242\\250\\236\\136\\185Ik\\250j\\ACK\",B \"\\ETX!\\202\\ETX=U_\\234\\&0\\153\\229\\SIU8\\144\\255\\229\\196V=\\176`L<7/\\199\\142\\186\\NAK\\185\\238\\184\",B \"\\ETXN\\172S\\136\\255\\145%\\NAK@*X\\136)\\179\\252\\203\\184\\145\\ETX-\\DC3\\ENQ\\169\\190\\140\\227\\192\\\\\\189pR\\153\",B \"\\ETXW|%\\221U\\212\\ENQO\\DC4x\\232\\SUB+\\252\\162\\&4>\\166\\223tl/\\228\\138\\246n\\243\\158S\\145l\\255\",B \"\\ETX\\138\\250\\STXKv\\v\\USmQ[[\\ENQ\\169\\149\\150\\221\\255\\246\\205U\\SYN\\239\\145>\\245,\\SYN\\211\\132\\248\\174\\r\"],Constr 1 []])],Map [],Constr 0 [B \"\\206\\221\\171\\244\\195c\\225t\\SUB]\\215tv\\a\\DC2\\169#\\158\\&8\\211\\132\\233\\181\\242e\\233\\n\\GS\\DC4\\140\\n\\190\"]],Constr 1 [Constr 0 [Constr 0 [B \"6\\204\\149\\151#cV\\247\\243\\CAN\\167\\195?1\\153\\ACK\\195Q\\234\\198\\171 \\169]\\ENQ\\197\\151\\233\\ACK\\150\\159\\234\"],I 1]]]\n" "hgCYrxoAAyNhGQMsAQEZA+gZAjsAARkD6BlecQQBGQPoGCAaAAHKdhko6wQZWdgYZBlZ2BhkGVnYGGQZWdgYZBlZ2BhkGVnYGGQYZBhkGVnYGGQZTFEYIBoAAqz6GCAZtVEEGgADYxUZAf8AARoAAVw1GCAaAAeXdRk29AQCGgAC/5QaAAbqeBjcAAEBGQPoGW/2BAIaAAO9CBoAA07FGD4BGgAQLg8ZMSoBGgADLoAZAaUBGgAC2ngZA+gZzwYBGgABOjQYIBmo8RggGQPoGCAaAAE6rAEZ4UMEGQPoChoAAwIZGJwBGgADAhkYnAEaAAMgfBkB2QEaAAMwABkB/wEZzPMYIBn9QBggGf/VGCAZWB4YIBlAsxggGgABKt8YIBoAAv+UGgAG6ngY3AABARoAAQ+SGS2nAAEZ6rsYIBoAAv+UGgAG6ngY3AABARoAAv+UGgAG6ngY3AABARoAEbIsGgAF/d4AAhoADFBOGXcSBBoAHWr2GgABQlsEGgAEDGYABAAaAAFPqxggGgADI2EZAywBARmg3hggGgADPXYYIBl59BggGX+4GCAZqV0YIBl99xggGZWqGCAaAiOszAoaAJBjuRkD/QoaAlFehBmAswqCGgAZ/L0aJ3JCMlkSa1kSaAEAADMjIzIjIzIjIzIjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyM1VQHSIjIyMjIjIyUzUzMAowFgCTMzVzRm4c1VzqgDpAAEZmZERCRmZgAgCgCABgBGagMuuNXQqAOZqAy641dCoAxmoDLrjV0KgCmagPOuNXQmrolAFIyYyA1M1c4BOBUBmZmauaM3DmqudUAJIAAjMiEjMAEAMAIyMjIyMjIyMjIyMjIyMzNXNGbhzVXOqAYkAARmZmZmZmZEREREREQkZmZmZmZmACAaAYAWAUASAQAOAMAKAIAGAEZqBOBQauhUAwzUCcCg1dCoBZmoE4FJq6FQCjM1UCt1ygVGroVAJMzVQK3XKBUauhUAgzUCcDA1dCoA5maqBWBi601dCoAxkZGRmZq5ozcOaq51QAkgACMyISMwAQAwAjIyMjMzVzRm4c1VzqgBJAAEZkQkZgAgBgBGagdutNXQqAEYHhq6E1dEoARGTGQJZmrnAPQQASRNVc8oAIm6oAE1dCoARkZGRmZq5ozcOaq51QAkgACMyISMwAQAwAjNQO3WmroVACMDw1dCauiUAIjJjIEszVzgHoIAJImqueUAETdUACauhNXRKAERkxkCOZq5wDkDwEUTVXPKACJuqABNXQqAKZqBO641dCoAhmaqBWBaQAJq6FQAzM1UCt1xAAmroVACMC81dCauiUAIjJjIEMzVzgGoHAIImrolABE1dEoAImrolABE1dEoAImrolABE1dEoAImrolABE1dEoAImrolABE1dEoAImqueUAETdUACauhUAIwHzV0Jq6JQAiMmMgNTNXOATgVAZiBSJqAYkkDUFQ1ABNVc8oAIm6oAETV0SgAiauiUAETVXPKACJuqABM1VQHSMiIjIyUzVTNTM1c0ZuHNTUAciIAIiMzARNVAEIiIAMAIAFIAICwCsQLBM1c4kk6ZXJyb3IgJ21rVXBkYXRlQ29tbWl0dGVlSGFzaFZhbGlkYXRvcic6IG91dHB1dCBtaXNzaW5nIE5GVAACsVM1UzUyMjIyUzUzNVMA8SABMjNQEyIzNQAyIAIAIAE1ABIgARIzABIlM1ACEAEQMgMSABMwLgBFM1AEE1ANSQEDUFQ5ACIQARMzNVMAwSABIjM1c0Zm7QAIAQAEDIDEAMAQAEQLzUAciIgBDcobszI1ABIiIzdKkAAZq6A1AEIiIjN0qQABmroDdQAKZq6A3UgCGaugNQAyIzdKkAAZq6AzdKkAAZq6A3UgBG7ED4zV0BuoABN2IHxmroDdQAEZq6A3UAAm7EDwzV0BunMDQAMzV0CmagBEJm6VIAAzV0BupABN2IHAmbpUgAjdiBuZq6A3UAAm7EDczMyIiEjMzABAFAEADACNVAIIiIiEjMzMAEAcAYAQAMAI1AGIiIAI1AGIiIAE1UAMiABM3AGbgzNwRkZmaqYBokACZGagIkRmagJABgAgBGoB4AJmoCBERgBmAEACQAJEZuAABSACABSAANQBSIiADNVAHIiIiACNVAHIiIiABSACM1UwFBIAEgATUAQiIgAxAsEzVziSAUNlcnJvciAnbWtVcGRhdGVDb21taXR0ZWVIYXNoVmFsaWRhdG9yJzogY29tbWl0dGVlIHNpZ25hdHVyZSBpbnZhbGlkAAKxUzVTNTIyMzVzRm483KGZqpgJiQALigFDNVMBISABIAEAIAEC4C01AGIgAjUAQiIgAxAsEzVziSFCZXJyb3IgJ21rVXBkYXRlQ29tbWl0dGVlSGFzaFZhbGlkYXRvcic6IGN1cnJlbnQgY29tbWl0dGVlIG1pc21hdGNoAAKxUzVTNVM1NQBCIiABIyEwATU1AFIgAiIiIiIiIgCzIAE1UDIiUzUAEQLiIVM1MzVzRm4kzMBQ1NQAiIAEiIgAzUAwiIAEAVIAADADEQMRMAQAEQLBAsEzVziSAVNlcnJvciAnbWtVcGRhdGVDb21taXR0ZWVIYXNoVmFsaWRhdG9yJzogbWlzc2luZyByZWZlcmVuY2UgaW5wdXQgdG8gbGFzdCBtZXJrbGUgcm9vdAACsVM1UzUzNXNGbjzVQASIAI3KGZqpgIiQALigEjNVMBASABIAE1AEIiIAICwCsQLBM1c4kgFIZXJyb3IgJ21rVXBkYXRlQ29tbWl0dGVlSGFzaFZhbGlkYXRvcic6IGV4cGVjdGVkIGRpZmZlcmVudCBuZXcgY29tbWl0dGVlAAKxUzUzNXNGbiDUAUiABNVABIgAQLAKxAsEzVziSVJlcnJvciAnbWtVcGRhdGVDb21taXR0ZWVIYXNoVmFsaWRhdG9yJzogc2lkZWNoYWluIGVwb2NoIGlzIG5vdCBzdHJpY3RseSBpbmNyZWFzaW5nAAKxArECsQKxArECsVMzU1UAEiIgAhMmMgMDNXOJIUZlcnJvciAnbWtVcGRhdGVDb21taXR0ZWVIYXNoVmFsaWRhdG9yJzogbm8gb3V0cHV0IGlubGluZSBkYXR1bSBtaXNzaW5nAAJSEwEwASEyYyAxM1c4kgFGZXJyb3IgJ21rVXBkYXRlQ29tbWl0dGVlSGFzaFZhbGlkYXRvcic6IG5vIG91dHB1dCBpbmxpbmUgZGF0dW0gbWlzc2luZwACYVM1UzU1ABIjUAIiIiIiIiIzM1ANJQNSUDUlA1IzNVMBgSABM1AbIlM1ACIQAxABUDUjUAEiUzVTNTM1c0ZuPNQAiIAI1AEIgAgPAOxMzVzRm4c1ACIgATUAQiABA8A7EDsTUDkAMVA4ANITUAEiNQASIiNQCCI1ACIiIiIiIiMzVTAkEgASI1ACIiJTNTUBgiNQBiIyM1AFIzUAQlM1MzVzRm48AIAEEwEsVADEEsgSyM1AEIEslM1MzVzRm48AIAEEwEsVADEEsVM1ADIVM1ACITNQAiM1ACIzUAIjNQAiMwLQAgASBOIzUAIgTiMwLQAgASIgTiIjNQBCBOIiUzUzNXNGbhwBgAwUQUBUzUzNXNGbhwBQAgUQUBMzVzRm4cAQAEFEFAQUBBQEEkVM1ABIQSRBJEzUEcAYAUQBVBCAKEyYyAvM1c4kgQJMZgACQTAjSYiFTNQARACIhMCdJhNQASIgAyMjIyMzNXNGbhzVXOqAGkAARmZEQkZmACAIAGAEZGRkZGRkZGZmrmjNw5qrnVAGSAAIzMzMiIiISMzMzABAHAGAFAEADACN1pq6FQBjdcauhUAUyMjIzM1c0ZuHUAFIAAjUDMwJjV0JqrnlADIzM1c0ZuHUAJIAIlAzIyYyA8M1c4BcBiB0ByJqrnVABE3VAAmroVAEMCI1dCoAZutNXQqAEbrTV0Jq6JQAiMmMgNzNXOAUgWAaiauiUAETV0SgAiauiUAETV0SgAiaq55QARN1QAJq6FQAzIyMjMzVzRm4c1VzqgBJAAEZqoFJuuNXQqAEbrjV0Jq6JQAiMmMgMzNXOASgUAYiaq55QARN1QAJq6FQAjdcauhNXRKAERkxkBeZq5wCECQC0TV0SgAiaq55QARN1QAJkACaqBSRCJGRESmamZq5ozcSAGkAABWBUIFYqZqAEIFREKmamYAwAQAZCZmaqYBQkACAQZuBAGSACACABEzM1UwCRIAEAcAUAEAMyABNVAsIiUzUAEVAmIhUzUzAGAEACE1ApABFTNTMAUAQAEhNQKjNQLwAwARUCgSMmMgKTNXOAAgPERmauaM3HgBAAgSARmQAJqoExEIkRKZqACJqAMAGRCZmoBIApgCABGZqpgDiQAIAoAgAIkagAkQAIkagAkQAQkQkZgAgBgBERGRkYAIApkACaqBMRGagApAAERqAERKZqZmrmjNx4AQBIE4EwmAOACJgDABmQAJqoEpEZqACkAARGoAREpmpmauaM3HgBADgTASiACJgDABmQAJqoEJEIkSmagAioEZEJmoEhgCABGaqYAwkACAIACZAAmqgQEQiREpmoAIgBEQmYAoARmaqYA4kACAKAIACkQEAIyMjMzVzRm4c1VzqgBJAAEZkQkZgAgBgBG641dCoARutNXQmrolACIyYyAiM1c4AoAuBAJqrnlABE3VAAmQAJqoDpEIkSmagAioD5EJmoEBgCABGaqYAwkACAIACJGRGAEbrAATIAE1UB0iMzNVc+ACSgPEZqA6YAhq6EAIwAzV0QAQChGRkZmauaM3DmqudUAJIAAjMiEjMAEAMAIwCjV0KgBGAKauhNXRKAERkxkA+Zq5wBEBQB0TVXPKACJuqABIyMjIyMzNXNGbhzVXOqAIkAARmZkREJGZmACAKAIAGAEZGRkZmauaM3DmqudUAJIAAjMiEjMAEAMAIwEzV0KgBGagGgJGroTV0SgBEZMZASGaucAWAZAiE1VzygAibqgATV0KgCGZqoBDrlAHNXQqAGZGRkZmauaM3DqACkAIRkJERgBACGroTVXPKAGRmZq5ozcOoASQARGQkRGACAIbrjV0JqrnlAEIzM1c0ZuHUANIAAhIiADIyYyAmM1c4AwA2BIBGBEJqrnVABE3VAAmroVACM1AJdcauhNXRKAERkxkBAZq5wBIBUB4TV0SgAiauiUAETVXPKACJuqABEzVQAXXOtESIyIwAjdWACZAAmqgNERkZmaq58AIlAcIzUBszVQFDAGNVc6oARgCmqueUAIwBDV0QAYCQmroQARIjIyMzNXNGbh1ABSAAI1AUMAU1dCaq55QAyMzNXNGbh1ACSACJQFCMmMgHTNXOAHgJANgNCaq51QARN1QAJGRkZmauaM3DqACkAMRkJERGAIAKYA5q6E1VzygBkZmauaM3DqAEkAIRkJERGAEAKYBJq6E1VzygCEZmauaM3DqAGkAERkJERGACAKYA5q6E1VzygCkZmauaM3DqAIkAARkJERGAGAKbrjV0JqrnlAGIyYyAdM1c4AeAkA2A0AyAwJqrnVABE3VAAkZGRmZq5ozcOaq51QAkgACMyISMwAQAwAjAFNXQqAEbrTV0Jq6JQAiMmMgGTNXOAFgHALiaq55QARN1QAJGRmZq5ozcOaq51QAUgACN1xq6E1VzygBEZMZALmaucAJAMAVE3VAAkZGRkZGRmZq5ozcOoAKQBhCREREQAZGZmrmjNw6gBJAFEJERERACEZmauaM3DqAGkAQRmRCRERERmACASAQbrjV0KgCm601dCauiUAUjMzVzRm4dQBEgBiMyISIiIiMwAgCQCDdcauhUAc3XGroTV0SgDkZmauaM3DqAKkAIRmRCRERERmAMASAQYBhq6FQCTdcauhNXRKASRmZq5ozcOoAyQARGQkREREYA4BBgGmroTVXPKAWRmZq5ozcOoA6QABGQkREREYAoBBgHGroTVXPKAYRkxkBAZq5wBIBUB4B0BwBsBoBkBgTVXOqAIJqrnlADE1VzygBCaq55QARN1QAJGRkZGRmZq5ozcOoAKQARGZkRCRGZgAgCgCABm601dCoAhutNXQqAGbrTV0Jq6JQAyMzNXNGbh1ACSAAIyEiMAIAMwCDV0JqrnlAGIyYyAZM1c4AWAcAuAsJqrnVADE1dEoAImqueUAETdUACRkZGZmrmjNw6gApABEZCRGACAGbrjV0JqrnlADIzM1c0ZuHUAJIAAjISIwAgAzdcauhNVc8oAhGTGQCxmrnACACwFAExNVc6oAIm6oAESIyMjMzVzRm4dQAUgBCEiIAEjMzVzRm4dQAkgAiMhIiMAMAQwBjV0JqrnlAEIzM1c0ZuHUANIAAhIiACIyYyAXM1c4ASAYAqAoAmJqrnVABE3VAAkZGZmrmjNw6gApABEAaRmZq5ozcOoASQABAGkZMZAJmaucAFAIARAQE1VzpuqABSQQNQVDEAERIiMAMwAgASMmMgDTNXOJIBJUV4cGVjdGVkIGV4YWN0bHkgb25lIGNvbW1pdHRlZSBvdXRwdXQAACEgAREiEjMAEAMAISEiMAIAMRIgATIAE1UAciJTNQAhUAgiFTNQAxUAoiEzUAszNXNGbkABAAgCQCDMAcAMAESIAISIAEyABNVAEIlM1ABE3YgCkQmaugN1IARgCAAiJEAEJEJEZgAgCABpMIkZGACACRGYAZgBABAApgF/2Hmf2HmfGEVDESIz2HqA2Hmf2HmfWCBrdZT7nC/4EkUs+7EOrsuWChE8N2qb3C9sZ+o5qXjiR/8A/wID/9h5n1gcGuymneuY/Z15jFlTKeIUoTdFODWhWzCrwe6TQ0D/WBy/ssK/S7RpbYefOsnY1xmkkrJQVRp3OZIPhwzR/wABn9h5n1ggI2BaTra9htz3ZyxlJSvv8RAznEj5Tf/+/gmSnUG8aooA/9h5n59YQLnBIgSymbO+AUNVKyvQ9BPy57G9VLfpKBvmaoBoU+cqOHkGs/q+uJf4KwTvN0F0UlVmgeBXor+q/Snu+hXkxI5YQGoOVrhn/8R4nMl5g3I/cjKdcDVmpIuIdC0PkSjkdTJZRdUzb5Ho3zTR1ZfPcS4OIMA5sMNc+zRHR+7u+U3VFBhYQG2XRno7l84wm5YCuSOxTerOWNDnrN4sfQqDvXFS5aqdcv9ybBVl8ErPGofhqryoT5WtpYSWYStYcGlrtYp7ej5YQBSatVASGFhkxV/+fHTwcebBdMNogrUTfGomwe/SKfdkIXJSVlfbbVn8FkGCYWYrbalVH1slRl7xEm6EiV8eDblYQHwb7yGirFy0wSe53FLynWly9qEysTagpojcmjxsfU3ePdTx9eccKCH7xcIufu+S/W5gJGDlttBNpLUfhno5rA3/n1ghAhVjDP4/MyFRRZzxlgpJgjjU3nmCFLQm1Ahb5
I know they're had been a preview upgrade, maybe I'm not using the last version of cardano-node. Let's update that first.
Upgrading cardano-node from 1.35.4-rc2 to 1.35.4 fixed the problem but I also deleted the cardano db and started a full sync for the preview network.
My hydra-node wanted to start while the cardano node was still synchronizing and I got errors about the hydra scripts not being published yet, which is fair:
Nov 30 09:19:34 ip-172-31-45-238 ae0d18945430[703]: hydra-node: MissingScript {scriptName = "\957Initial", scriptHash = "8d73f125395466f1d68570447e4f4b87cd633c6728f3802b2dcfca20", discoveredScripts = fromList []}
So then, I waited a bit before restarting my hydra-node. At that point, the hydra scripts were known but my cardano-node was not yet still 100% synchronized. Then my hydra-node started exibiting some strange behaviors as it stumbled upon old head initialization transactions on-chain and became stuck on waiting for this old head to be initialized.
That's interesting. That's fair that the node observe an old head being opened as there is no way for it to know it's old. Then, maybe it was an old head that we left open and just forgot about during the tests.
What I did is I just waited for the cardano-node to be fully synchronized and restarted my hydra-node (has to erase its persistent state before so it would only look at the last transactions on chain).
AB on #410
🎉 Finally got to the bottom of things: Turns out the culprit was our genPayment function and more precisely the use of suchThat combinator from QuickCheck which retries a generator if some predicate is false. To find the issue I have added traces to quickcheck-dynamic functions in order to zoom in on the function, retrying with the same seed over and over until I can locate the function livelocking.
Created PR.
Things to do, assuming we merge this PR, in order to :
- Actually validate L1 transactions against a ledger hosted by the mock chain, so that the
ModelSpecproperties can actually run contracts' code - Run clients in multiple threads in order to emulate more faithfully what happens IRL
AB on #410
So the problem definitely lies in the way we are looking for a UTxO when either we want to create a new payment or when we wait for the tx to be observed later on. I have tried to rewrite the waitForUTxOToSpend function and it fails/deadlocks earlier, at a new payment. So it's really surprising it succeeds to post tx in the synchronous case but fails to observe later on the Utxo
- Putting back the blocking
waitForNextcall in thewaitForUTxOToSpendfunction
It now blocks again while waiting to observe the last transaction posted.
- Adding a
timeoutaroundwaitForNextto ensure we retryGetUTxO, I now have a deadlock when posting andAbortTx:(
It's possible the arbitrary TimeHandle generated produces some invalid value that raises an exception?
- Adding a trace after we query
currentPointInTimeto see if we can always post a tx - Normally it should raise an exception if there is a problem but does it?
- The postTx happens so it seems blocked after that...
Is it possible some exception never make its way up the stack and a thread gets stuck?
Using seed 889788874 to ensure I retest the same trace as there apparently are 2 problems:
- when waiting to observe the last posted tx
- when aborting
So it seems the node is receiving correctly the response after retrieving a few unrelated outputs
- But then the test hangs, and I don't see the trace saying the utxo has been observed. Trying to increase the timeout to see if that changes anything, to no avail
- Could this have to do with some RTS issue? Or am I not observing what I think I am observing, eg. some traces get swallowed and never output?
Adding a trace to check whether the UTxO is really found or not:
- So the UTxO is found! What should happen next is a trace about
observed ...but it's not. - Oddly enough this trace is also not shown for the previous node so perhaps this is just an artifact of Haskell's lazy IO?
Trying to get some low-level (OS thread sampling) information to see if it helps:
- Going to try https://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
- Got a sample of the process on Mac OS usign the
Activity Monitor. - I tried to use
perfbut it requiressudowhich breakscabalbecause now all the paths are wrong. I should of course switch the user after runningsudobut I was lazy and thought it would work just as fine on a Mac. - There's really nothing that stands out in the process dump: Threads are waiting, and that's it.
Next attempt: Getting a dump of IOSim events' trace
- It does not show anything significant: The
mainthread is stopped but some threads appear to be blocked?
Adding labels to some TVar and TQueue we are using here and there, and it appears the nodes are blocked on the event-queue. Could it just be the case that the node's threads keep running forever because they are not linked to the main thread? And perhaps I am lucky in other test runs?
- Ensuring all the node's threads are also
cancelled does not solve the issue, but the trace is more explicit at least
All threads now properly terminated:
Time 380.1s - ThreadId [1] chain - EventThrow AsyncCancelled
Time 380.1s - ThreadId [1] chain - EventMask MaskedInterruptible
Time 380.1s - ThreadId [1] chain - EventMask MaskedInterruptible
Time 380.1s - ThreadId [1] chain - EventDeschedule Interruptable
Time 380.1s - ThreadId [1] chain - EventTxCommitted [Labelled (TVarId 2) (Just "async-ThreadId [1]")] [] Nothing
Time 380.1s - ThreadId [] main - EventTxWakeup [Labelled (TVarId 2) (Just "async-ThreadId [1]")]
Time 380.1s - ThreadId [1] chain - EventUnblocked [ThreadId []]
Time 380.1s - ThreadId [1] chain - EventDeschedule Yield
Time 380.1s - ThreadId [] main - EventTxCommitted [] [] Nothing
Time 380.1s - ThreadId [] main - EventUnblocked []
Time 380.1s - ThreadId [] main - EventDeschedule Yield
Time 380.1s - ThreadId [1] chain - EventThreadFinished
Time 380.1s - ThreadId [1] chain - EventDeschedule Terminated
Time 380.1s - ThreadId [] main - EventThrowTo AsyncCancelled (ThreadId [2])
Time 380.1s - ThreadId [] main - EventTxBlocked [Labelled (TVarId 11) (Just "async-ThreadId [2]")] Nothing
Time 380.1s - ThreadId [] main - EventDeschedule Blocked
Time 380.1s - ThreadId [2] node-17f477f5 - EventThrow AsyncCancelled
Time 380.1s - ThreadId [2] node-17f477f5 - EventMask MaskedInterruptible
Time 380.1s - ThreadId [2] node-17f477f5 - EventMask MaskedInterruptible
Time 380.1s - ThreadId [2] node-17f477f5 - EventDeschedule Interruptable
Time 380.1s - ThreadId [2] node-17f477f5 - EventTxCommitted [Labelled (TVarId 11) (Just "async-ThreadId [2]")] [] Nothing
Time 380.1s - ThreadId [] main - EventTxWakeup [Labelled (TVarId 11) (Just "async-ThreadId [2]")]
Time 380.1s - ThreadId [2] node-17f477f5 - EventUnblocked [ThreadId []]
Time 380.1s - ThreadId [2] node-17f477f5 - EventDeschedule Yield
Time 380.1s - ThreadId [] main - EventTxCommitted [] [] Nothing
Time 380.1s - ThreadId [] main - EventUnblocked []
Time 380.1s - ThreadId [] main - EventDeschedule Yield
Time 380.1s - ThreadId [2] node-17f477f5 - EventThreadFinished
Time 380.1s - ThreadId [2] node-17f477f5 - EventDeschedule Terminated
Time 380.1s - ThreadId [] main - EventThrowTo AsyncCancelled (ThreadId [3])
Time 380.1s - ThreadId [] main - EventTxBlocked [Labelled (TVarId 18) (Just "async-ThreadId [3]")] Nothing
Time 380.1s - ThreadId [] main - EventDeschedule Blocked
Time 380.1s - ThreadId [3] node-ae3f4619 - EventThrow AsyncCancelled
Time 380.1s - ThreadId [3] node-ae3f4619 - EventMask MaskedInterruptible
Time 380.1s - ThreadId [3] node-ae3f4619 - EventMask MaskedInterruptible
Time 380.1s - ThreadId [3] node-ae3f4619 - EventDeschedule Interruptable
Time 380.1s - ThreadId [3] node-ae3f4619 - EventTxCommitted [Labelled (TVarId 18) (Just "async-ThreadId [3]")] [] Nothing
Time 380.1s - ThreadId [] main - EventTxWakeup [Labelled (TVarId 18) (Just "async-ThreadId [3]")]
Time 380.1s - ThreadId [3] node-ae3f4619 - EventUnblocked [ThreadId []]
Time 380.1s - ThreadId [3] node-ae3f4619 - EventDeschedule Yield
Time 380.1s - ThreadId [] main - EventTxCommitted [] [] Nothing
Time 380.1s - ThreadId [] main - EventUnblocked []
Time 380.1s - ThreadId [] main - EventDeschedule Yield
Time 380.1s - ThreadId [3] node-ae3f4619 - EventThreadFinished
Time 380.1s - ThreadId [3] node-ae3f4619 - EventDeschedule Terminated
Time 380.1s - ThreadId [] main - EventThrowTo AsyncCancelled (ThreadId [4])
Time 380.1s - ThreadId [] main - EventTxBlocked [Labelled (TVarId 25) (Just "async-ThreadId [4]")] Nothing
Time 380.1s - ThreadId [] main - EventDeschedule Blocked
Time 380.1s - ThreadId [4] node-94455e3e - EventThrow AsyncCancelled
Time 380.1s - ThreadId [4] node-94455e3e - EventMask MaskedInterruptible
Time 380.1s - ThreadId [4] node-94455e3e - EventMask MaskedInterruptible
Time 380.1s - ThreadId [4] node-94455e3e - EventDeschedule Interruptable
Time 380.1s - ThreadId [4] node-94455e3e - EventTxCommitted [Labelled (TVarId 25) (Just "async-ThreadId [4]")] [] Nothing
Time 380.1s - ThreadId [] main - EventTxWakeup [Labelled (TVarId 25) (Just "async-ThreadId [4]")]
Time 380.1s - ThreadId [4] node-94455e3e - EventUnblocked [ThreadId []]
Time 380.1s - ThreadId [4] node-94455e3e - EventDeschedule Yield
Time 380.1s - ThreadId [] main - EventTxCommitted [] [] Nothing
Time 380.1s - ThreadId [] main - EventUnblocked []
Time 380.1s - ThreadId [] main - EventDeschedule Yield
Time 380.1s - ThreadId [4] node-94455e3e - EventThreadFinished
Time 380.1s - ThreadId [4] node-94455e3e - EventDeschedule Terminated
Time 380.1s - ThreadId [] main - EventThreadFinished
yet test still blocks...
- Try to figure out
AcquirePointNotOnChaincrashes. Looking at logs from @pgrange - cardano-node logged
Switched to a fork, new tip, looking for that in the logs - Seems like the consensus does update it’s “followers” of a switch to a fork in
Follower.switchFork. Not really learning much here though. Likely we will see a rollback to the intersection point. Let’s see where we acquire in thehydra-node. (seeouroboros-consensus/src/Ouroboros/Consensus/Storage/ChainDB/Impl/Follower.hs) - Try to move the traces for roll forward / backward even closer into the chain sync handler.
- It’s not clear whether we get a rollback or forward with the
AcquirePointNotOnChainproblem. Switching focus to tackle theAcquirePointTooOldproblem. -
AcquireFailurePointTooOldis returned when requestedpoint < immutablePoint. What isimmutablePoint? (seeouroboros-consensus/src/Ouroboros/Consensus/MiniProtocol/LocalStateQuery/Server.hs) - It’s the
anchorPointof the chain db (seeouroboros-consensus/src/Ouroboros/Consensus/Network/NodeToClient.hs,castPoint . AF.anchorPoint <$> ChainDB.getCurrentChain getChainDB) - Can’t reproduce the
AcquireFailedPointTooOld:( - Seems like the devnet is not writing to
db/immutable, but ony todb/volatile. Because blocks are empty? - Wallet initialization is definitely problematic. How can we efficiently initialize it without trying to
Acquirethe possibly far in the pastChainPoint? - Finally something I can fix: by not querying the tip in the wallet we see an
IntersectionNotFounderror when starting the direct chain on an unknown point. This is what we want!
- Discussing seen / confirmed ledger situation https://github.com/input-output-hk/hydra-poc/issues/612
- Not fully stuck: other transactions could proceed
- ModelSpec would catch this quite easily with a non-perfect model
- Why do we keep a local / seen ledger in the first place (if we wait for finaly / confirmed transactions anyways)?
- We walk through our ledger state update diagrams on miro
- Weird situation:
- Use the confirmed ledger to validate NewTx and also answer GetUTxO
- Use & update the seen ledger when we do validate ReqTx
- The simple without conflict resolution is incomplete in this regards (of course)
- With conflict resolution, we would update the seen ledger with the actually snapshotted ledger state
- We still need a seen state
- To know which transactions can be requested as snapshot
- At least on the next snapshot leader
- But then this would be more complicated
- We drew an updated trace of ledger states and messages in oure miro: https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3458764538771279527&cot=14
- We really need to get a model up, which could produce counter examples like the one we drew
Adding a test to check that all the clients receive all the events after a restart
- the test fail
- because history is stored on disk in the reverse order as how it stored in memory
- fixing that
- Moving
ChainContextout ofChainState: Makes state smaller and it’s all configured anyways. (Later goal: state is just some UTxOs) -
genChainStateWithTxis a bit tricky.. if we want to remove the context fromChainStatewe need to use big tuples and lots of passing around. - The block generation in
HandlersSpecis indicating nicely how contexts / states can be treated separately and maybe merged later?
stepCommits ::
-- | The init transaction
Tx ->
[ChainContext] ->
StateT [Block] Gen [InitialState]- Even after making all
hydra-nodetests pass, I gothydra-clustererrors indicating that theWalletdoes not know UTxOs. Maybe our test coverage is lacking there (now)?
{..., "reason":"ErrTranslationError (TranslationLogicMissingInput (TxIn (TxId {_unTxId = SafeHash \"12f387e5b49b3c86af215ee1eef5a25b2e31699c0f629d161219d5975819f0ac\"}) (TxIx 1)))","tag":"InternalWalletError"}
AB on #410
- Working on making a (dummy) block out of a single ledger tx, as we do in the
WalletSpec, Managed to have theModelrun, connecting all the parts together along with a wallet and dummy state
I can now run ModelSpec with direct chain wired in but it deadlocks on the first commit, I need the logs but I don't have them if I timeout using the within function from QC.
-
Suggestion from Ulf: Add an internal "kill switch", something like a thread with a timeout when seeding?
-
Added a tracer that uses
Debug.trace... -> Got a first answer: Seems like theTickthreaded is flooding the event queuesGot an error trying to post a transaction:
postTxError = NoSeedInputwhich obviously makes sense! Need to provide the seed input from the wallet?
- Upgrade with last version 0.8.0
- Manage persistent storage
- Restart the node
- Had to deal with the preview respin
- Upgrade cardano node
- whipe cardano database
- Upgrade node configuration
- configuration was not fully synced
- re-publish the scripts (had to wait for preview upgrade)
- re-send funds to my node
- mark funds as fuel
- Had to deal with the preview respin
AB on #410
Trying to tie up the knot in the Model to dispatch transactions to the nodes
- My idea was to
flushTQueuefor all txs in between 2 ticks and put them all in a block but this function has only been recently added to theio-simpckalge: https://github.com/input-output-hk/io-sim/commit/051d04f1fb1823837c2600abe1a739c7f8dbb1bc - going to do something much more more simple and simply put each transaction in one block
-
Properties / proofs in updated HeadV1 spec
- maybe not all needed, definitely need to redo them
- would be good to have them to refer from code / tests
- we will start work as the current state of the spec is good -> done by 30th of Nov
-
React on mainchain (L1) protocol changes
- should: not only react, but involve in changes on early stages
- in general: not expect drastic changes, rather gradual
- besides hard-forks and protocol updates: desaster recovery plan exists, but highly unlikely and special handling required
- also: changes to the cardano-node / interfaces (similar to #191)
- make dependencies clear upstream -> as an artifact
-
Hard-forks:
- definition: incompatible changes in cardano concensus / ledger rules
- scope is case-by-case, not necessarily tx format changes
- usually backward compatible, but not necessarily
- not as often, likely maintenance required always
- Next: SECP-features
- Concrete artifact: write-up process (also mention rough 6 months lead time)
-
Protocol parameters:
- to balance block production time budgets (sizes, limits, cost models), e.g.
maxTxExecutionUnits - security paramaters to keep ledger state memory in check, e.g.
utxoCostPerByte - sizes likely never decrease again (many applications depend on them)
- collateral should be fine
- cost models updates are tricky -> they will affect costs / possibility of spending script UTxOs
- Idea: just identify if L1 params are more restrictive than L2 and inform user on changes
- to balance block production time budgets (sizes, limits, cost models), e.g.
Going through the code to gain more domain knowledge. The code is written pretty nicely, I can follow along everything I see so it is just a matter of learning how things operate together. Miro graphs are quite helpful there too. I started from a Chain module in hydra-node since this is something I had mostly seen before. One type alias is maybe not needed but I decided not to touch it for now
type ChainCallback tx m = ChainEvent tx -> m ()
Reading through I though that the chain handle should reflect that in the type name so decided to
change the Chain to ChainHandle. In general seeing a lot of words like chain throws me off a bit
since I am a visual guy.
In order to learn more about how things work I am going from the Main module and working my way down
in order to understand the flows. Sometimes I get confused when we use the work callback many times when talking
about different code. In the chain scenario and withChain/withDirectChain functions the callback means we just put some chain event
into the queue. Quite simple. The action here is that we want to post a tx on-chain where on-chain is the L1 chain.
This action is the actual content of our friend ChainHandle, namely postTx which is there - you guessed it - to post a tx
on a L1 chain (and perhaps fail and throw since it has a MonadThrow constraint).
We define what kind of txs can the ChainHandle post in PostChainTx type which is also defined in the Chain.hs module.
These can be any of Init, Commit, Close, Contest, Fanout and the last but not the least CollectCom. Of course this is all
inline with what I read in the paper.
Ok going back to the withDirectChain - jumping to the Direct.hs module.
withDirectChain takes in many params and one of the capabilities is that we are able to run the main chain from pre-defined
ChainPoint (defined in cardano api) which is neat.
Here is also where we construct our internal wallet TinyWallet whose address is derived from our loaded verification key.
I am tempted to rename the TinyWallet to TinyWalletHandle but I know that the plan is to allow using external wallets so
I will leave it be since it will go away soon anyway. This wallet has capabilities to get its utxos, sign txs and apparently
manage its own internal state which is just a set of wallet utxos. We can update this utxo set when we apply a new block which
contains a tx that modifies our wallet utxo set. I think I'll know more about when exactly this happens after going through a bit
more code.
Ok digging further I discover that we actually use the chain sync ouroboros protocol to tie in this wallet update on a new block.
I should mention we are interested in roll forward and backward which is defined in the appropriate ChainSyncHandler
Maybe I shouldn't get into details but this is how I memorize the best.
Trying to make sense of Hydra V1 specification document, seems weird to me this whole discussion happens in Word!
Here is an attempt at formalising in Haskell one of the validators, namely initial. There are lot of things to define of course but it's possible to massage the code in such a way that it looks very close to what's in the paper...
initial ("context") = do
-- First option: spent by Commit Tx
(pid, val, pkh, val', nu', pid', eta', oMega) <- parse $ do
pid <- omega_ctx & delta
val <- omega_ctx & value
pkh <- [pkh | (p, pkh, 1) <- val, pid == p] !! 1
[(val', nu', (pid', eta'))] <- o !! 1
ci <- rho_ctx -- List of outRefs pointing to committed inputs
-- Needed to tell committed inputs apart from fee inputs
-- Omega is a list of all committed (val,nu,delta)
-- The ordering in Omega corresponds to the ordering in CI
-- (which is assumed implicitly in the next line)
oMega <- [omega | (i_j, omega) <- i, (i_j & outRef) `elem` ci]
return (pid, val, pkh, val', nu', pid', eta', oMega)
check
[ -- PT is there
(pid, pkh, 1) `elem` val'
, -- Committed value in output
val' - (pid, pkh, 1) == val + sum [omega & value | omega <- oMega]
, -- Correct script
nu' == nu_commit
, -- Correct PID
pid' == pid
, -- Committed UTxOs recorded correctly
eta' == recordOutputs (oMega)
, -- Authorization
pks == [pkh]
, -- No forge/burn
mint == 0
]Just thinking this might be even closer in Python
Going through various comments in the paper:
- Kept the idea of having
Ibeing the set of all inputs but the one providing context for the validator, even though it's not technically always the case we do implement this separation - Accepted most comments from SN
- There's no need to check burning in the minting policy as it's checked in the Abort and Fanout
- we dropped the subscript
_SMonI_SMandO_SMbecause they appeared confusing, expressing the opposite of what other similarly subscripted symbols meant - We had an inconclusive discussion over the ordering of committed UTxO: Sandro has written the
ν_initialvalidator for hte general case of multiple UTxO committed off-chain, which means thecollectComwill generate a hash of list of (ordered) UTxO hashes, not of the list of actual UTxO. This might be a problem and a gap to address.
- Debugging EndToEnd: I see a
ToPostforCollectComTx, but anOnChainEventofOnCommitTxafter it. Does it try to collect too early? Is there a state update "race" condition? - Helpful jq filter:
jq 'del(.message.node.event.chainEvent.newChainState.chainState.contents)'to not renderchainStatecontents - Oh no.. I think there is a problem with this approach:
- Commits happen concurrently, but the chain state is updated in isolation
- For example, in a three party Head we will see three commits
- Two threads will be reading/updating the state
- Receiving transactions will
callback, theHydraNodeStateprovides the latestchainStateto the continuation:- The continuation will evolve that chain state into a
cs'and put it as anewChainStateinto the queue
- The continuation will evolve that chain state into a
- The main thread processes events in the
HydraNodequeue:- Processing the
Observationevent for a commit tx will put it'scs'as the latestchainState
- Processing the
- So it's a race condition between when we get callbacks (query the state) and process events (update the state).
- Maybe using
modifyHeadStatein thechainCallbackis not such a dirty hack? We could avoid dealing with updatingchainStatein the head logic, but this is really increasing complexity of data flow.
- When threading through the
chainStateinHeadLogic: The field access and huge amount of arguments inHeadLogicreally needs refactoring. Individual state types should help here. - When debugging, I realize that the
ChainContextis always in the Hydra node logs (as JSON) and it's HUGE.. need to move this out ofChainStateor somehow switch it's JSON instance depending on log/persistence. - After encountering the bug in the head logic, I had the idea of checking chain states in the
simulatedChaintest driver. However, thechainStateVaris shared between nodes and this messes things up. - This will be even a bigger problem with the
Modelusing the realChainStateType Tx. The simulation needs to keep track of a chain state perHydraNode.
- Starting a fresh adr18 branch as it's a PITA to rebase on top of persistence now.
- Start this time with all the types as we had them last time. e.g. that
Observationonly contains a new chain state - E2E tests with new
ChainCallbackare interesting.. shall we really do the chain state book-keeping in the tests?
After further investigation, we discover that, once again, one of of us had the wrong keys for another node. Fixing configuration solved the problem.
Problem with the tui because of the way the docker image handles parameters (add --). #567
Problem with peers blinking. They connect/disconnect in a loop. We see deserialization errors in the logs. It happens we don't use the exact same latest version. Some docker build github action did not use the latest latest image but a not so latest one. Anyway, we should add some tag to our images to be sure about which version is running. See #568
Also, it is hard to read through the logs as there are quite some noise there. Since it's json stuff we should explore how to help filter out interesting logs more easily. See #569
Pascal is unable to initiate a head. Not enough funds error but he has the funds. Maybe the problem comes from the fact that he has two UTxO marked as fuel. One is too small, the other one is OK. Is there a problem with UTxO selection in our code? See #570
TxHash TxIx Amount
--------------------------------------------------------------------------------------
043b9fcb61006b42967714135607b632a9f0d50efbf710822365d214b237a504 0 89832651 lovelace + TxOutDatumNone
043b9fcb61006b42967714135607b632a9f0d50efbf710822365d214b237a504 1 10000000 lovelace + TxOutDatumHash ScriptDataInBabbageEra "a654fb60d21c1fed48db2c320aa6df9737ec0204c0ba53b9b94a09fb40e757f3"
13400285bb2db7179ac470f525fe341b0b2f91f579da265a350fa1db6829bf7f 0 10000000 lovelace + TxOutDatumNone
e9c45dd07cdafd96a399b52c9c73f5d9886bbd283b09b7eae054092e5b926b58 1 3654400 lovelace + TxOutDatumHash ScriptDataInBabbageEra "a654fb60d21c1fed48db2c320aa6df9737ec0204c0ba53b9b94a09fb40e757f3"
Sebastian initializes a head but nobody can see it. Same with Franco and same with Sasha. We discover that some of us still have Arnaud in their setup so it might be the case that the init transaction, including Arnaud, is ignore by other peers that don't know Arnaud. We fix the configurations but we still can't initialize the head. We have to investigate more.
First step, clarify: do we want to improve how we display errors in the TUI, like the size of the error window, scrolling capability, etc.? Or do we want to improve the meaning of the message?
Second, try to reproduce an error using the TUI:
- tried to upgrade a node but has problems with the nodeId parameter format... probably a version error
- tried to FIX xterm error Sasha has observed on his node
The xterm error is due to the static binary of the tui depending, at runtime, to some terminal profile. Adding this to the docker image and setting TERMINFO env variable appropriately solved the issue.
My code has crashed with the following uncatched exception:
Oct 14 15:49:41 ip-172-31-45-238 bc6522f81da8[34927]: hydra-node: QueryException "AcquireFailurePointNotOnChain"
Looking at previous logs, it might be the case that the layer 1 switch to a fork after hydra has taken some block into consideration. Then, querying layer 1 led to an exception. Here are some, probably significatn logs:
# new tip taken into account by hydra-node:
Oct 14 15:49:41 ip-172-31-45-238 bc6522f81da8[34927]: [bc6522f8:cardano.node.ChainDB:Notice:66] [2022-10-14 15:49:41.10 UTC] Chain extended, new tip: 787b2e7bb45f5a77740c6679ca2a35332420eb14a795a1bedcff237126aa84ea at slot 5759381
Oct 14 15:49:41 ip-172-31-45-238 bc6522f81da8[34927]: {"timestamp":"2022-10-14T15:49:41.143911009Z","threadId":49,"namespace":"HydraNode-1","message":{"directChain":{"contents":{"newUTxO":{"3b54e9e04dd621d99b1b5c40d32d9d2c50f19c520ca37b788629d6bfce27a0f6#TxIx 0":{"address":"60edc8831194f67c170d90474a067347b167817ce04e8b6be991e828b5","datum":null,"referenceScript":null,"value":{"lovelace":100000000,"policies":{}}},"e9c45dd07cdafd96a399b52c9c73f5d9886bbd283b09b7eae054092e5b926b58#TxIx 1":{"address":"60edc8831194f67c170d90474a067347b167817ce04e8b6be991e828b5","datum":"a654fb60d21c1fed48db2c320aa6df9737ec0204c0ba53b9b94a09fb40e757f3","referenceScript":null,"value":{"lovelace":3654400,"policies":{}}}},"tag":"ApplyBlock"},"tag":"Wallet"},"tag":"DirectChain"}}
Oct 14 15:49:41 ip-172-31-45-238 bc6522f81da8[34927]: {"timestamp":"2022-10-14T15:49:41.143915519Z","threadId":49,"namespace":"HydraNode-1","message":{"directChain":{"point":"At (Block {blockPointSlot = SlotNo 5759381, blockPointHash = 787b2e7bb45f5a77740c6679ca2a35332420eb14a795a1bedcff237126aa84ea})","tag":"RolledForward"},"tag":"DirectChain"}}
# layer 1 swithes to a fork
Oct 14 15:49:41 ip-172-31-45-238 bc6522f81da8[34927]: [bc6522f8:cardano.node.ChainDB:Info:66] [2022-10-14 15:49:41.22 UTC] Block fits onto some fork: 8adda8ee035fb15aac00c0adbec662c2197cc9c1fbd4282486f6f6513c7700f5 at slot 5759381
Oct 14 15:49:41 ip-172-31-45-238 bc6522f81da8[34927]: [bc6522f8:cardano.node.ChainDB:Notice:66] [2022-10-14 15:49:41.22 UTC] Switched to a fork, new tip: 8adda8ee035fb15aac00c0adbec662c2197cc9c1fbd4282486f6f6513c7700f5 at slot 5759381
# ignoring some "closing connections" logs
# hydra node crashes with an exception:
Oct 14 15:49:41 ip-172-31-45-238 bc6522f81da8[34927]: hydra-node: QueryException "AcquireFailurePointNotOnChain"
Trying to figure out where the problem was in the code I had two issues:
- figuring out that the last message meant that the code abruptedly crashed because of an uncaught exception (trick for later: it's not JSON)
- figuring out which version of the code was running on my node
On my running version, the excepetion is thrown in CardanoClient.hs:294]([https://github.com/input-output-hk/hydra-poc/blob/979a5610eed0372f2826b094419245435ddaa22c/hydra-node/src/Hydra/Chain/CardanoClient.hs#L294) Which would correspond to CardanoClient:295 in current version of the code.
- How do express the rollback tests? One idea: add slot to all server outputs, then we can create
Rollbackevents easily - Problem: it’s a big change and it feels like leaking internal information to the client
- Alternative: Add a
rollbackmethod to the simulated chain, taking a number of “steps” again. - We encounter the problem:
simulatedChainAndNetworkneeds to be abstract overtxand so it’s quite tricky to keep a chain state - We worked around it by adding a
advanceSlottoIsChainState, that way we can increase slots without knowing whether it’s aSimpleTxorTxchain state - Things are becoming quite messy here and there and we discuss & reflect a bit:
- Having the
ChainSlotinside theChainStateType txis maybe more complicated than necessary - Why do all chain events have a
chainStatein the first place? - It would be much clearer if each
ChainEventhas a slot, but onlyObservationmay result in a newchainState
- Having the
-
We mostly discussed rollbacks and how they are handled in the protocol
-
Originating comment triggering this discussion: "wait sufficiently long with first off-chain tx so no rollback will happen below open"
-
First scenario:
- Head is opened with a
collectComtransaction with someu0, recorded as someη0(typically a hash ofu0) - Some off-chain transactions happen leading to a
u1and snapshot signatureξ1 - A rollback happens where
collectComand one party'scommitis not included in the chain anymore - The affected party does
commita *different UTxO into the head and opens the head again withcollectCom - Now, the head could be closed with a proof
ξ1ofu1, although it does not apply tou0
- Head is opened with a
-
Solution:
- Incorporate
η0into anyξ, so snapshot signatures will need to be about the newu, but also aboutu0 - That way, any head opened with different UTxOs will require different signatures
- Incorporate
-
We also consider to include the
HeadIdinto the signature to be clear thatξis about a single, unique head instance -
Second scenario:
- Head gets closed with a
close, leading to a contestation deadlineDL - Some party does
contestcorrectly beforeDL, but that transaction gets rolled back just before the deadline - Now this party has no chance in
contestin time
- Head gets closed with a
-
This would also happen with very small contestation periods.
-
The discussion went around that it would not be a problem on the theoretical
ouroboros, but is one oncardano-> not super conclusive. -
We think we are okay with the fact that a participant in the Head protocol would know the network security parameter and hence how risky some contestation period is.
Pairing on #535
I would like to write a small script to generate a graph out of the execution trace, to ease the understanding of the flow of actions
We have 2 problems:
- In the state model, we have a UTxO with no value which does not really make sense -> we need to remove a fully consumed UTxO
- In the
NewTxgenerator, we generate a tx with 0 value which does not make sense either - The state model is not really faithful to the eUTxO model: A UTxO should just be "consumed" and not "updated"
it "removes assets with 0 amount from Value when mappending" $ do
let zeroADA = lovelaceToValue 0
noValue = mempty
zeroADA <> zeroADA `shouldBe` noValue
but this property fails
forAll genAdaValue $ \val -> do
let zeroADA = lovelaceToValue 0
zeroADA <> val == val
&& val <> zeroADA == val
with the following error:
test/Hydra/ModelSpec.hs:104:3:
1) Hydra.Model ADA Value respects monoid laws
Falsified (after 3 tests):
valueFromList [(AdaAssetId,0)]
We realise that genAdaValue produces 0 ADA Value which is problematic because:
- When
mappending 2Value, there is a normalisation process that removes entries with a 0 amount - In the ledger rules, there's a minimum ada value requirement: Check https://github.com/input-output-hk/cardano-ledger/blob/master/doc/explanations/min-utxo-mary.rst which implies there cannot be a UTxO with no ADAs anyway
What do we do?
- Easy: Fix the generator to ensure it does not generate 0 ADA values
- fix
genAdaValue? - fix the call site -> Commit generator in the
Model
- fix
- less easy: handle this problem at the Model levle? eg. raise an observable error if someone crafts a 0 UTxO? but this should not be possible at all 🤔
In https://github.com/input-output-hk/cardano-ledger/blob/master/eras/shelley-ma/test-suite/src/Test/Cardano/Ledger/ShelleyMA/Serialisation/Generators.hs#L174 we actually can generate 0-valued multi assets.
Got a weird error in CI when it tries to generate documentation (https://github.com/input-output-hk/hydra-poc/actions/runs/3223955249/jobs/5274722994#step:6:110):
Error: Client bundle compiled with errors therefore further build is impossible.
SyntaxError: /home/runner/work/hydra-poc/hydra-poc/docs/benchmarks/tests/hydra-node/hspec-results.md: Expected corresponding JSX closing tag for <port>. (49:66)
47 | <li parentName="ul">{`parses --host option given valid IPv4 and IPv6 addresses`}</li>
48 | <li parentName="ul">{`parses --port option given valid port number`}</li>
> 49 | <li parentName="ul">{`parses --peer `}<host>{`:`}<port>{` option`}</li>
| ^
50 | <li parentName="ul">{`does parse --peer given ipv6 addresses`}</li>
51 | <li parentName="ul">{`parses --monitoring-port option given valid port number`}</li>
52 | <li parentName="ul">{`parses --version flag as a parse error`}</li>
error Command failed with exit code 1.
It seems angle brackets in markdown are not properly escaped !!?? 😮
Managed to get markdown pages generated properly for tests and copied to docs/ directory
Turns out there's no need for a dedicated index page, the subdirectory tests/ will automatically be added as a card on the benchmarks page and the item structure will appear on the side. However, the structure is not quite right:
- The page's title is the first level 1 item of the page which is not what I want
- The top-level directory is named after the directory's name which is ugly: I would like to replace
testswithTest Results
Adding a title to each test results page is straightforward: Just demote each grouping by one level and pass a title string to be used at level 1 for the page.
Managed to change the displayed label for tests but there's still one issue: It generates a page for it which does not really make sense -> skip the sidebars?
- Ok, that was easy: I have previously added an
index.mdpage in thetestsdirectory which generated a page
Started working on a Markdown formatter for hspec tests execution.
- The goal is to be able to generate a page replicating the sturcture of the test tree in markdown for inclusion in the doc website during CI run
- The purpose is to ensure that, by making tests more visible, we provide an accurate representation of what's tested, refining names and labels to make our test suite more expressive, possibly helping identify blind spots
It was surprisingly painful to scaffold the whole test thingy into the hydra-test-utils project:
- Add the
testentry in the.cabalfile with some basic info, trimming down dependencies - Add a
Main.hsandHydraTestUtilsSpec.hsfile undertest/tree - Get basic content, module names, cabal configuration... right
- before seeing the failure
=> need some way to scaffold this kind of stuff ?
Getting to first test still takes about 20 lines of code: I want to test running a Spec with markdown generator on produces some specific content in a given file
- Need to add some dependencies to manipulate files, create a temporary directoy
- Took inspiration from https://github.com/freckle/hspec-junit-formatter/blob/main/library/Test/Hspec/JUnit.hs#L84 which provides the basic structure to react to events issued but hspec when traversing a tree
Tests to write:
- ensure
describeare mapped to headers -
itorspecifyare mapped to list items - succesful test result shown as ✅ or 🔴 or
⚠️ (pending) - summarize execution time
- provide execution time for each test/group
markdownFormatter function is actually quite large, as large as the unit tests -> move it to own module in src/
Trying to implement a naive tree walker and output stuff to the file on the go
- This is inefficient (opening/closing file all the time) but good enough to get a grasp of how the formatting process works
- It does not work as I expect though :) -> text is not appended to the file
There are 2 versions of formatters, one that lives in a FormatM monad where one implements functions in a data structure representing the various events
- I am implementign the simple one, just using a
Format :: Event -> IO ()function that reacts to eachEvent - I can see the
startedanddoneevents are emitted but not the other ones!
There is a PR on hspec describing how to write a custom formatter but it says it requires 2.10.5!
- Could it be the case that the event's based thing is not really available in 2.9.7? And then I need to walk the paths...
- So I am stuck right now, it seems I cannot go down the easy path of using
Event -> IO ()function 🤔 - I will have to resort to reconstructing the tree from
paths :: [(([String], String), Item)]which is deeply annoying - Truth is, having notification for each group/item would be problematic when executing in parallel
Working my way on transforming a list of paths into a tree. Seems like something I have already done in the past, and something quite common, so it's somewhat frustrating I have to do it by hand. Isn't there something in Data.Tree from containers? => :no:
- I am probably trying to make too big a step by writing the algorithm all at once....
I think it would make sense to go down the property route here:
- Generate a tree of tests, and make sure it's properly rendered
- Seems a bit redundant?
- Needed to fiddle a bit with
monadicmonadicIOproppropertyto find the right combination: Turns outpropreturns aSpecbut I need aSpecWith FilePathin order to pass the temporary work directory created in anarounddecorator so I just usedproperty . monadicIOto turn the check into a property - I want to generate an
Arbitrarytree of tests but it's not possible to do it directly, eg. generate aSpecbecause QC requires theainGen ato beShowandEq=> need an intermediate data structure that mimicks the structure of a hspec test and then transform it toSpec. Sounds like a job for an algebra :)
- First step: Change
postTxto take aChainState(via a type family) - Throw out rollback logic right away? Let’s keep it / disable it for later
- Is there an alternative now for where to put the continuation -> into
Observation? Not really, as it won’t make it showable / serializable. - Second step: Update
ChainCallbackand its usage inChain.Direct.Handlers - Call to
observeSomeTxfeels great.. everything falls into place! - Third step: Add
chainStatetoOnChainEffectand wire upchainStateeverywhere inHeadLogic - Where is the initial
chainStatecoming from? 1) Part ofChain tx mor 2) as a second argument on the callback ofwithDirectChain? - We had to do a lot of constraint juggling on
deriving instances-> maybe addChainStateTypetoIsTxas well?
- Franco prepared the implementation where we do only check whether our key is present, but the e2e behavior seemed weird.
- We discussed the behavior of the e2e test where Alice and Bob have only partly overlapping configurations. Especially the case where Alice has nothing configured and "gets pulled in" a head with Bob feels off.
- Indeed, simply beeing more lax on the observation yields situations where Alice would be seeing a Head initialization (commit and abort on it), where they (e.g. Alice + Bob) could open a head, but will be stuck once open.
- We decided to sharpen the purpose of #529 and instead want to be warned about non alignment of configured keys and observed parties/keys in a Head
- Problem: There is no notion of Cardano/Chain keys in the Head Logic
- Even grander problem: The chain layer needs to decide whether it wants to do a state transition or not before yielding control to the logic layer!
- Maybe ADR18 could fix this as there won't be a separate state and the head logic can decide on a transition / or to inform the user only.
My code is not formatted as it should be. I need fourmolu to work from inside vscode.
Looking at it, I notice that some code has not been formatted as expected. I open a P.R. to reformat all the things.
I activate fourmolu in Haskell vscode extension and format on save. It looks like it’s not using fourmolu.yaml configuration :(
But maybe it’s not that? It might actually be a fourmolu version discrepancy inside vscode? I open an issue to ask for more information about it because I don’t know which fourmolu it’s using.
OK… I’ve installed fourmolu 0.6.0 but the project uses 0.4.0 and 0.5.0 introduced a breaking change in some haddock formatting. So my P.R. will just put a mess with everybody’s formatting in the team. And it seems that it’s a bit complicated to update right now because of cabal version dependencies.
So long for the nice and quick brew installation of fourmolu, and back to the long compilation:
time cabal install fourmolu --constraint 'fourmolu == 0.4.0.0'
Tackling an "interesting" problem with Hydra CI leading to this PR: https://github.com/input-output-hk/hydra-poc/pull/536
It took a while to attract some attention but we ultimately get to the bottom of it and it turns out that:
- Hydra-the-CI was configured for Hydra-the-layer-2 here: https://github.com/input-output-hk/ci-ops/blob/master/modules/hydra-master-main.nix#L47-L81
- Hydra notifications reportedly errored on the Hydra side and Devops did not know why
-
devopsgroup was recently added as an admin for ALL IOHK repositories because"Base level escalation access to IOG repos"
- This caused the notification to on the Hydra-the-CI side to succeed but it then reported a failure because there were no required builds in the release.nix configuration
Pairing w/ Pascal on refactoring snapshot, working our way in some test failures on the JSON schema validation, improving the error messages from the test failure when the process does not exist:
- Requires patttern matching on the obscure
OtherErrorIOErrorTypeconstructor which is not yet inSystem.IO.Errorin our base version - Version check on
jsonschemais too stringent -> we had the version provided bybrew install jsonschemaas of now but it's kind of silly. What we probably want is a lower bound
Got failure from CI reproduced -> 🎉
- We should not forget to update the
CHANGELOGas we need to change the logs and that's a breaking change
We explore once again our flaky tests issues together. A transaction has appeared on our cardano-node but the next hydra step will fail.
It happens that the cardano-node has seen the transaction and it has been validated in a black but the hydra-node is lagging behind and did not see this block yet when we ask it to do something with it.
It raises the question: should we expose a way to get hydra-node view of one's assets so that they wait for the hydra-node to have seen it before performing any operation or should we just let the user try to perform the operation and fail with useful information so that they can figure out why it failed?
-
We reviewed the HeadV1 spec together: https://docs.google.com/document/d/1XQ0C7Ko3Ifo5a4TOcW1fDT8gMYryB54PCEgOiFaAwGE/edit?pli=1#heading=h.hrthyvgkkf65
-
We address some of the red notes that are uncertainties or questions. We share questions and simplification suggestions with the idea of keeping specification and code as close as possible to one another.
-
"might want to wait a bit if .s_seen > .s_confirmed not to cause ‘honest’ contests"
- Discussions around the fact that there could still be
AckSnin flight when we see a close transaction. - Looks like Matthias and Sebastian understand each other ;)
- Concluding: We would not accept any
AckSnafter seeing a close and this seems to be an optimization of fewer contest txs -> no need.
- Discussions around the fact that there could still be
-
Re:
OnTimeout ClosedOrContest() notifyClient(“ContestPhaseOver)- Do we need client notifications as part of the specification?
- How current code observes the deadline? Event based? Forever loop or what?
- We do something like this, but don't use it in the actual behavior / logic of the node.
- Conclusion: If it is useful to specify properties and proofs then let’s keep it. Otherwise, we might remove it to simplify the specification.
-
About hashes of transactions in
reqSn- Is it OK if we don’t deal with hashes in the specification? The code does not handle hashes today but sends full transactions. Can we make it simpler to stick to the actual implementation but still optimize later and be ok with the formal proofs?
- This raises another question: maybe this simplification paves the way to other simplifications leading to a trivial/very simple specification but preventing lots of optimization in the code in the future?
- Anyhow: it's a likely optimization we will make and let's just keep it
-
Regarding
reconcileLandTxs_block- When we receive a transaction, we might be lagging behind and see conflicting transactions.
- In the original paper if we can not apply, we just delay the transaction (
waitorpush). - Maybe we can just put the tx back in the queue? Anyway, we want to keep the transaction we observe even though we don’t do anything with them, yet.
- How long should we keep these problematic transactions in the queue? They might become valid later but how long should we keep them? Without any adversary, we should be able to remove all the transactions eventually. But an adversary could create memory leaks by sending loads of never valid transactions.
- Current code implements a timeout for transaction validity to avoid that. We could also have a limited, fixed size queue.
- Not sure if it would make sense to add that level of details in the specification. It could be managed through if you observe something funny, close the head. That should not impact the safety part of the paper so would be easier without it.
-
Flushing the queue
- This is an odd one, and a bit "meta"
- The current implementation is event-based and ensures that all events eventually are processed.
- To simplify the spec we decide to just add a note/assumption that the events queue need to Run-To-Completion (RTC)
-
We also talk a bit about the decision of when do we have to do a snapshot? It looks like the code agrees with the specification even though we have implemented it weirdly.
Completing #497
Found a first issue with the property I check: The Stop action moves the state into Final with an empty confirmed txs set which is undesirable, this action should have no effect and is just there to stop the recursion when generating new txs
I got a BadPrecondition error on the tx that's generated which is odd
First error I see is that the ObserveConfirmedTx action fails in the perform, raising an error as it's not able to find the expected UTxO
- Perhaps it would be cleaner to add a
postcondition🤔 but it's nevertheless a genuine problem - The problem is that I reuse the same function,
waitForUTxOToSpendto check that a UTxO is available for spending in a Tx and to check a UTxO has been spent 🤦 - The
ObserveConfirmedTxshould check the UTxo for the recipient exists instead!
It's not clear at which point the error happens: Could be when trying to apply NewTx or when trying to observe it -> distinguishing the error by returning an Either instead of raising error
- So the test fails when trying to execute the
NewTxaction which is normal because I checked thetopart oftxand not thefromre-:facepalm:
The property now consistently fails with BadPrecondition when applying the supposedly non conflicting transaction
- The
Stopaction is useless as it does not change theWorldStateso moreNewTxcan be generated depending on the size parameter
I generate anyActions before invoking the ObserveConfirmedTx so there might be interleaved transactions that consume the UTxO I expect to find
- Removing it gets me back to the
BadPreconditionstate - Would be nice to improve
BadPreconditionoutput -> it's not clear why it happens, or rather one has to know the structure of the object to decode its output -> add named fields ? -> Issue #19 in q-d
We got the property to pass 🎉 with the following changes:
- We made the UTXO representation closer to the
Paymentrepresentation so that troubleshooting errors is (slightly) more straightforward -> one can lookup the UTxO for a Payment directly into theconfirmedUTxOsinstead of having to do the mental transformation - We fixed the real issue: The
preconditionforNewTxassumed there was only one UTxO available for a given address 🤦
:lightbulb: What if we committed not a UTxO but a signature (mithril based) of some state that's replicated inside the Head and head parties would recreate some state back, wiht a multisignature, prooving that there's a transition from initial to end state
We decide to open a hydra head with all our 5 hydra nodes together.
Each of our hydra node is listening on 0.0.0.0:5001 but it is the key used to identify a node in the head so we can only see us connected to one single peer.
We quickly hacked something by each of us listening on a dedicated port so that we appear with a different name. (Should we use uuid or something?)
We take quite a lot of time to have everyone onboard and ready at the same time. A bit painful to find each others IPs. After 45 minutes or so we are all connected.
Then, we encounter issues related to configuration issues. Despite our node catalog we had on the wiki, we have some misconfiguration between our five nodes.
Sasha initiates a head:
- Pascal sees it immediately
- Sebastian sees it after a few minutes
- Franco does not see it at all.
Sebastian initializes a head:
- Franco sees it immediately
- Sasha and Pascal do no see it.
Sebastian has the wrong cardano verification for Sasha. He fixes it and restart his node. And then re-initializes a head:
- Pascal can see it.
- Sasha does not
- Franco does not
We should show the head ID and more information to ease debugging configuration. Also, the hydra node does not only pay attention to init transactions with our key but only to init transactions _that match all the keys of all the peers. Hence the problem with our configuration issues.
When all is ok, we have the following error because it seems that we are too much people in the head.
Error An error has occurred: User error:\\nThe machine terminated part way through evaluation due to overspending the budg│··············
et.\\nThe budget when the machine terminated was:\\n({ cpu: 674259628\\n| mem: -5522\\n})\\nNegative numbers indicate the overspent budget; note that this only indicatessthe bu│··············
dget that was needed for the next step, not to run the program to completion.
So opening a head with five members is too expensive. But now we can't just abort it because aborption too overspends our budget. So we just lost some test Ada.
We should add a safeguard to avoid that because we lost our funds in the transaction.
We decide to remove Arnaud from the setup and open a head with only four members.
Of course, some of us forgot to remove Arnaud so they do not observe the init transaction.
Let’s restart again.
When people fix their config, they have to restart the node and can’t see previous transactions unless they had the option that make it start from the past in the chain.
Now Pascal has not enough fuel :( probably an optimistic removal of fees from hydra wallet computation. Let’s restart Pascal hydra node and see what happens.
Now the head is opened 🎉 and hydraw is working.
Sasha restart its node for some maintenance. Oops, our head is stuck since there is, for now, no persistent storage of the head state.
- We could try to re-create L1 state using
--start-chain-fromand try closing it (using the initial snapshot) - Would expect contestation by other nodes.
- We also realize that the
10second hard-coded (in the tui?) contestation period is too low for testnet -> make it configurable.
Interesting idea: Asking other nodes for the L2 history of snapshots (signed) to rebuild the HeadState.
- More similar to Cardano
- Could be an alternative to persistence
- Would require peers to keep a history of all snapshots
I have a full node running. I have a nami wallet with preview network funds in it. I've managed to send funds to my cardano-node and I can see the utxo on it.
I try to mark some of my test Ada as fuel for hydra but I have several errors. It happens that I was using to small amounts to create valid transactions.
It looks like we must send at least 100 test Ada to be safe to the cardano-node. Then we should fuel something like 90 000 000 lovelaces. These numbers work.
I've decided to restart my node from scratch. I only keep my secrets (so I don't loose funds) but get rid of all the rest and start from scratch with my docker image. But then I have problems with hydra crashing. It happens that the image starts the hydra-node too soon and since we are not in Babbage era, hydra-node just crash as is expected. So I patch the docker startup script so that we wait for cardano-node to have reach Babbage era before starting hydra.
My hydra-node is up and running and setup with all informations from my future peers as in https://github.com/input-output-hk/hydra-poc/wiki/Hydra-Nodes-Directory
To get more familiar with the tooling, I decide to build my own version of a hydra-node docker image which I plan to make all in one. That is with a cardano-node and a hydra-node running inside the same container.
Installing cardano-node in the image is straightforward using the binary available at https://hydra.iohk.io/build/16338142/download/1/cardano-node-1.35.0-linux.tar.gz
I can compile hydra-node in the image but this takes two hours so I look for a way to cut corners
and though I could still the binary from the hydra-node docker image.
Unfortunately it is linked with n a libc stored in /nix/store/jcb7fny2k03pfbdqk1hcnh12bxgax6vf-glibc-2.33-108/lib/ld-linux-x86-64.so.2
I tried a bit to hack with symbolic links in my docker images but I quickly stopped as it really looked too much of a hack and fragile.
So I decided to go the compilation way. I used the haskell docker image with tag 8.10.7 so that I have the appropriate version of ghc. But it does not compile. This is because of cabal version 3.8.1.0 installed in the image. With cabal 3.6.2.0 compilation works fine:
#> cabal --version
cabal-install version 3.8.1.0
#> ghc --version
The Glorious Glasgow Haskell Compilation System, version 8.10.7
#> cabal build hydra-node
…
Failed to build moo-1.2. The failure occurred during the configure step.
Build log (
/root/.cabal/logs/ghc-8.10.7/moo-1.2-6c72b1ec57cdfd93c8ee847bd6ff6030f0e61f1f9da5e35fff72711d30fcfc62.log
):
Configuring library for moo-1.2..
Error: cabal: Duplicate modules in library: Moo.GeneticAlgorithm.Crossover
Error: cabal: Failed to build moo-1.2 (which is required by exe:hydra-node
from hydra-node-0.7.0). See the build log above for details.
#> cat /root/.cabal/logs/ghc-8.10.7/moo-1.2-6c72b1ec57cdfd93c8ee847bd6ff6030f0e61f1f9da5e35fff72711d30fcfc62.log
Configuring library for moo-1.2..
Error: cabal: Duplicate modules in library: Moo.GeneticAlgorithm.Crossover
#> cabal --version
cabal-install version 3.6.2.0
compiled using version 3.6.2.0 of the Cabal library
#> cabal build hydra-node
... all is fine
I think this is related to this issue: https://github.com/haskell/cabal/issues/8422
So I add to start from scratch and create myself an image that would have the appropriate version of ghc and the appropriate version of cabal.
Then I built hydra-node in the image. It takes, more or less, 3 hours on my laptop:
#> time cabal build hydra-node
real 66m19.769s
user 184m10.393s
sys 12m13.210s
I believe it would help if we shared a binary to the community like what is done with cardano-node.
Trying sample configuration for AWS from a Mac/intel.
I need some stuff on the machine:
brew install aws-cli
brew install terraform
And know, after having configured terraform credentials, let’s just be plain stupid and run terraform to see what happens:
terraform init
Terraform plan
And it works! So let make terraform create its stuff:
terraform apply
Invalid key pair... let’s go back to the doc. Ok, setting up a key pair. Now it’s not clear for me what has to be done on my laptop and what must be done on the remote node. Let’s restart from scratch.
- Generate the hydra signing key file
I’m running it straight from the branch:
mkdir credentials
cabal run -- hydra-tools gen-hydra-key --output-file credentials/hydra-key
- Generate the Cardano key
From my yesterday’s cardano-node compilation:
~/git/github.com/input-output-hk/cardano-node/dist-newstyle/build/x86_64-osx/ghc-8.10.7/cardano-cli-1.35.3/x/cardano-cli/build/cardano-cli/cardano-cli address key-gen --verification-key-file credentials/cardano.vk --signing-key-file credentials/cardano.sk
Sharing my Cardano and hydra keys on the wiki:
#> cat credentials/cardano.vk
#> cat credentials/hydra-key.vk | base64
Getting the other’s credentials from the wiki. Have to base64 decode hydra keys:
echo '9hbFrOewdExHWUEAGD6ZQrK2qW0UhbD4ZPWqs0/YZTQ=' | base64 -d > credentials/arnaud-hydra.vk
- Update testnet.tf
-> seems that it’s actually already ok
- Update docker file
I think it’s too soon at this stage to do so so let’s try with it as it is.
- Promtail
I disconnect prom tail for now as I have no idea how to setup that right now.
Now I scroll down the doc and configure my Cardano.addr :
~/git/github.com/input-output-hk/cardano-node/dist-newstyle/build/x86_64-osx/ghc-8.10.7/cardano-cli-1.35.3/x/cardano-cli/build/cardano-cli/cardano-cli address build --payment-verification-key-file credentials/cardano.vk --testnet-magic 1 > credentials/cardano.addr
LET’S TERRAFORM APPLY ALL THE THINGS!!!
Oups!
aws_instance.hydra: Provisioning with 'remote-exec'...
aws_instance.hydra (remote-exec): Connecting to remote host via SSH...
aws_instance.hydra (remote-exec): Host: 52.47.119.1
aws_instance.hydra (remote-exec): User: ubuntu
aws_instance.hydra (remote-exec): Password: false
aws_instance.hydra (remote-exec): Private key: true
aws_instance.hydra (remote-exec): Certificate: false
aws_instance.hydra (remote-exec): SSH Agent: false
aws_instance.hydra (remote-exec): Checking Host Key: false
aws_instance.hydra (remote-exec): Target Platform: unix
aws_instance.hydra (remote-exec): Connected!
aws_instance.hydra (remote-exec): + set -e
aws_instance.hydra (remote-exec): + '[' 1 -eq 1 ']'
aws_instance.hydra (remote-exec): + GH_USER=pgrange
aws_instance.hydra (remote-exec): + echo 'Accepting github.com key'
aws_instance.hydra (remote-exec): Accepting github.com key
aws_instance.hydra (remote-exec): + sudo ssh-keyscan github.com
aws_instance.hydra (remote-exec): # github.com:22 SSH-2.0-babeld-24a5c4c2
aws_instance.hydra (remote-exec): # github.com:22 SSH-2.0-babeld-24a5c4c2
aws_instance.hydra (remote-exec): # github.com:22 SSH-2.0-babeld-24a5c4c2
aws_instance.hydra (remote-exec): # github.com:22 SSH-2.0-babeld-24a5c4c2
aws_instance.hydra (remote-exec): # github.com:22 SSH-2.0-babeld-24a5c4c2
aws_instance.hydra (remote-exec): + echo 'Downloading gpg key signing testnet dump'
aws_instance.hydra (remote-exec): Downloading gpg key signing testnet dump
aws_instance.hydra (remote-exec): + gpg --import
aws_instance.hydra (remote-exec): + jq -r '.[] | .raw_key'
aws_instance.hydra (remote-exec): + curl https://api.github.com/users/pgrange/gpg_keys
aws_instance.hydra (remote-exec): gpg: directory '/home/ubuntu/.gnupg' created
aws_instance.hydra (remote-exec): gpg: keybox '/home/ubuntu/.gnupg/pubring.kbx' created
aws_instance.hydra (remote-exec): % Total % Received % Xferd Average Speed Time Time Time Current
aws_instance.hydra (remote-exec): Dload Upload Total Spent Left Speed
aws_instance.hydra (remote-exec): 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
aws_instance.hydra (remote-exec): 100 5 100 5 0 0 29 0 --:--:-- --:--:-- --:--:-- 28
aws_instance.hydra (remote-exec): 100 5 100 5 0 0 28 0 --:--:-- --:--:-- --:--:-- 28
aws_instance.hydra (remote-exec): gpg: no valid OpenPGP data found.
aws_instance.hydra (remote-exec): gpg: Total number processed: 0
╷
│ Error: remote-exec provisioner error
│
│ with aws_instance.hydra,
│ on testnet.tf line 124, in resource "aws_instance" "hydra":
│ 124: provisioner "remote-exec" {
│
│ error executing "/tmp/terraform_1087256527.sh": Process exited with status 2
╵
I just restart the terraform apply blindly an get another error:
aws_instance.hydra (remote-exec): Installing jq
aws_instance.hydra (remote-exec): + sudo apt-get install jq -y
aws_instance.hydra (remote-exec): E: Could not get lock /var/lib/dpkg/lock-frontend. It is held by process 1918 (dpkg)
aws_instance.hydra (remote-exec): N: Be aware that removing the lock file is not a solution and may break your system.
aws_instance.hydra (remote-exec): E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), is another process using it?
I guess some dpkg stuff is still running on the machine so let’s ssh and take a look. I run apt update/upgrade and it works fine so the job has finished. I restart terraform apply.
Of course Sasha and Franco do not suffer from this issue, of course. We have two problems:
- The daily apt clean and update is running concurrently to my attempt to install jq. Just add wait for lock in apt command solves this
- The Debian repositories are not up to date and jq is not found. Apt update/upgrade solves this (using apt-get and not apt) Well not enough radical
Terraform apply succeeded in 3’36’’
Started at 10am and it’s 4pm. Now we can start some actual hydra stuff
I have ada on my address 💰
Feedbak shared with FT and doc improved 👍
Resuming work on #498
lsp-haskell and treemacs support started behaving oddly:
▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ \
hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hydra-poc 3 /home/curry▸ hy\
dra-poc 3 /home/curry▸
Finally got some interesting output from the conflict-free liveness property test:
test/Hydra/ModelSpec.hs:97:3:
1) Hydra.Model check conflict-free liveness
uncaught exception: ErrorCall
genPayment impossible in state: Idle {idleParties = [Party {vkey = HydraVerificationKey (VerKeyEd25519DSIGN "be907b4bac84fee5ce8811db2defc9bf0b2a2a2bbc3d54d8a2257ecd70441962")},Party {vkey = HydraVerificationKey (VerKeyEd25519DSIGN "1466ff5d22d044d8bc0abd20876e78f38792b1932fd9ade681e7bf32a103cccb")},Party {vkey = HydraVerificationKey (VerKeyEd25519DSIGN "a1e3763e8d346ed9ca642700b111f91c7a5f4719db48d12b89a7542357dc21fc")},Party {vkey = HydraVerificationKey (VerKeyEd25519DSIGN "b95f40c18524952d0e3a8855ad602ea70559422ac318f32b3a551a5c5e17d881")},Party {vkey = HydraVerificationKey (VerKeyEd25519DSIGN "a5cb01400dd888b1f32c523e8d1ea9a41ca262ff7a0f7bafa1d76e904ae15d1d")},Party {vkey = HydraVerificationKey (VerKeyEd25519DSIGN "0e111bca97888f85cf1e147247ed9b4bee09523a527423025f89a60861348a58")}], cardanoKeys = ["eb9563330be1d9e180b17eed87deed485b4d652260839d169308066a2e87ee3d","ece45e5faaa3c71b8f13b0c64a00155ab4e3b84ce379b923f86099b625a1b61c","dfab855368927f7b21c9d89eedd9a4143b59a400accfc0d8db6611c8
Obviously we cannot generate payment in an arbitrary state but only in Open state -> need to change the property to express that
- Got another failure, this time with a failed precondition: By default,
preconditionreturnsFalse - Property is now running but it's not making progress, seems like it's entering a loop. Perhaps shrinking?
- Got a precondition failure on a
NewTxgeneration which seems odd, raised an issue in QD repo to discuss why this is failing: https://github.com/input-output-hk/quickcheck-dynamic/issues/19 and schedule a meeting w/ Quviq to troubleshoot the problem
Ensemble on #487
- We wondered why the property for Tick was not failing -> it uses an ideal TimeHandle with an
UnsafeIndefiniteSafeZone - Seems like the
epochLengthis actually relevant for how big the “safe zone” is! Need to check the actual details - We got to reproduce the issue in the e2e scenario by just waiting for 20 seconds now. This test is however annoying as it relies on the tuned devnet parameters (which are also used in other places) and it will fail fast, but run long(er) on success.
- On the HandlersSpec level we motivated the change of
TimeHandleto atype GetTimeHandle m = m TimeHandleand executed that interface change ofchainSyncHandler. When being forced to provide aTimeHandle“on demand” now, we realize that this level of testing will always either circumvent the logic (by providing a recent time handle) or exhibit the problem (by providing an old time handle). Adding a test for the latter is probably meaningful. - The EraHistory with/without a safe zone is still confusing as it seems to only contain relative times/bounds and we would need to learn a bit more to confidently use / mock things here.
Still struggling with this nix caching issue. SN figured out that it is probably caused by an architecture issue. The cache is populated with binaries built for x86_64-linux and I'm using a mac-intel. nix cache-info confirms that my derivations are not in cache (note that derivations for x86_64-linux have a different path and are in the cache: /nix/store/wkmj4vf42ws4g6fjis9arxppw9nhc7xs-ghc-shell-for-packages):
#> nix path-info -r /nix/store/6r42kv2npk1xfzp8yvdi30yphq91kizv-ghc-shell-for-packages.drv --store https://cache.iog.io
error: path '/nix/store/6r42kv2npk1xfzp8yvdi30yphq91kizv-ghc-shell-for-packages.drv' is not a valid store path
So one way to solve this would be to ask the CI to build for darwin architecture. Another is to just accept the overhead of building everything once on my machine. After 12 or 24 hours (I unfortunately did not time it and let the machine run during the night so can't be sure of the time) everything has been built on my machine. I'm expecting the next builds to be faster as everything should not change everytime, hoepfully.
All making nix cache work on his machine and no fun makes PG a dull boy. Let’s take a break and just install Cardano-node without nix.
This process highlights that there is a special treatment for libsodium and secp256k1 (this last one is the one that posed problem when first compiling hydra outside of nix).
Everything is working smoothly (it's long, of course, but it works). And installing secp256 that way also seems to solve my previous hydra compilation issues so I'm able to compile it out of nix. I'll let the compilation of hydra and cardano-node run in parrallel and see what happens.
So to summup, nix cache is inefficient for a good reason (not compiled for my architecture) but I was able to, in the end, have a working nix-shell. But then I still have some troubles using it:
- I'm not comfortable with the shell used and I get no history and bad completion
- I'm having a hard time integrating that with my vscode haskell setup
We'll see when everything has been compiled if life is simpler.
cardano-node compilation finished successfully. It took, approximately, 1h30, on my laptop, with another compilation of hydra running in parallel so that's only to use as a broad guestimation of compilation time. But let's say it's ok.
hydra-node compilation finished successfully. It took, also aproximately, 1h30.
I try to open a haskell file in vscode to check if hls works. haskell extension suggests to install cabal-install for cabal project:
#> cabal install cabal-install
Well... it looks like it's ok so I think I'm going to start working with this setup and see what happens.
Ensemble on #487
- We start by reproducing the problem by lowering k in the end-to-end setup and changing one of the scenarios to wait sufficiently enough before close
- Even after lowering to k=10 and waiting for like 20 seconds we could not reproduce the close tx failing because of time conversion
- Of course: the actual problem with a failing
TimeConversionExceptionbringing down the node could only come from theTickhandling code. We will continue tomorrow to write a test exhibiting this.
Trying to fix the link-checker failing jobs by ignoring more patterns. My first attempts at naively fixing the pattern for link checker failed, going to test it locally. The action uses https://github.com/stevenvachon/broken-link-checker so it's easy enough to install and run locally against the hydra.family website
Trying
$ node_modules/.bin/blc "https://hydra.family/head-protocol/" -r --exclude google --exclude github --exclude 'file://'
but the file:// links are still checked 🤔
- Reported a "bug" upstream as I don't understand how
excludeworks: https://github.com/stevenvachon/broken-link-checker/issues/252 - Even checking only internal links is wrong, because haddock links exist for packages which are not there
Helping Sasha run his nodes, seems like he might ran into an an ipv4/ipv6 🎉 -> #500
Taking a look at CONTRIBUTING and checking that everything compile on my machine (mac Intel). I tried running cabal test all straight on without nix but that was a bit reckless:
Failed to build secp256k1-haskell-0.6.0. The failure occurred during the
configure step.
Build log (
/Users/pascal/.cabal/logs/ghc-8.10.7/scp256k1-hskll-0.6.0-afebbf99.log ):
Warning: secp256k1-haskell.cabal:33:3: The field "autogen-modules" is
available only since the Cabal specification version 2.0. This field will be
ignored.
Configuring library for secp256k1-haskell-0.6.0..
cabal-3.6.2.0: The program 'pkg-config' version >=0.9.0 is required but it
could not be found.
cabal: Failed to build secp256k1-haskell-0.6.0 (which is required by test:unit
from plutus-merkle-tree-1.0.0, test:unit from plutus-cbor-1.0.0 and others).
See the build log above for details.
So I install pkg-build with brew install pkg-build. After that, I still get an error for the secp256 compilation:
Failed to build secp256k1-haskell-0.6.0. The failure occurred during the
configure step.
Build log (
/Users/pascal/.cabal/logs/ghc-8.10.7/scp256k1-hskll-0.6.0-afebbf99.log ):
Warning: secp256k1-haskell.cabal:33:3: The field "autogen-modules" is
available only since the Cabal specification version 2.0. This field will be
ignored.
Configuring library for secp256k1-haskell-0.6.0..
cabal-3.6.2.0: The pkg-config package 'libsecp256k1' is required but it could
not be found.
cabal: Failed to build secp256k1-haskell-0.6.0 (which is required by test:unit
from plutus-merkle-tree-1.0.0, test:unit from plutus-cbor-1.0.0 and others).
See the build log above for details.
I decided to be kind and go the nix way. So I installed nix on mac and nix was working ok until I updated my ~/.config/nix/nix.conf file with the following content, as specified in hydra documentattion:
substituters = https://cache.nixos.org https://iohk.cachix.org https://hydra.iohk.io
trusted-public-keys = cache.nixos.org-1:6NCHdD59X431o0gWypbMrAURkbJ16ZPMQFGspcDShjY= iohk.cachix.org-1:DpRUyj7h7V830dp/i6Nti+NEO2/nhblbov/8MW7Rqoo= hydra.iohk.io:f/Ea+s+dFdN+3Y/G+FDgSq+a5NEWhJGzdjvKNGv0/EQ=
This led to the following error when using nix:
warning: ignoring untrusted substituter 'https://iohk.cachix.org'
warning: ignoring untrusted substituter 'https://hydra.iohk.io'
Restarting nix-daemon did not help, neither rebooting the machine.
Thanks to this nix issue, I understant taht this problem is caused by my user not being a trusted user so not allowed to set this parameters. Moving this configuration from ~/.config/nix/nix.conf to /etc/nix/nix.conf I though the issue was solved.
But the first run of nix-shell was taking for ever and recompiling the whole world. So it looks more like the parameter is just ignored.
In the end, I have the following setup:
#> cat /etc/nix/nix.conf
build-users-group = nixbld
trusted-users = root pascal
cat ~/.config/nix/nix.conf
#substituters = https://cache.nixos.org https://iohk.cachix.org https://hydra.iohk.io
substituters = https://cache.nixos.org https://iohk.cachix.org https://cache.iog.io https://hydra-node.cachix.org
trusted-public-keys = cache.nixos.org-1:6NCHdD59X431o0gWypbMrAURkbJ16ZPMQFGspcDShjY= iohk.cachix.org-1:DpRUyj7h7V830dp/i6Nti+NEO2/nhblbov/8MW7Rqoo= hydra.iohk.io:f/Ea+s+dFdN+3Y/G+FDgSq+a5NEWhJGzdjvKNGv0/EQ= hydra-node.cachix.org-1:vK4mOEQDQKl9FTbq76NjOuNaRD4pZLxi1yri31HHmIw=
experimental-features = nix-command flakes
SN helped me because there is still a problem: It's compiling cardano-node but we're expecting to get it from the cache. We fix cache url in nix.conf but still, it compiles cardano-node... let's call it a day :(
I also installed direnv:
#> brew install direnv`
#> cat <<EOF >~/.oh-my-zsh/custom/direnv.zsh
eval "$(direnv hook zsh)"
EOF
Then I start a new shell and allow direnv in hydra-poc: cd hydra-poc ; direnv allow (but you don't want to do that while nix is still installing stuff).
Recreating dev VM with a new base image. I have added github CLI to the image as I would like to find a way to build a daily digest of what's happening on various repos. Ideally, I would like to generate a one-pager that provides information about changes: commits, issues, PRs mainly. Not sure exactly what I am looking for or want to see though...
Catching-up with FT on #494, trying to fix some UI details:
- Remove the
termssubmenu on the sidebar -> Breaks backlinks when jumping to a term definition but seems acceptable for now
Cannot build locally the documentation doing:
$ yarn
$ yarn build
...
[ERROR] Error: Cannot find module './static/docs-metadata.json'
Require stack:
- /home/curry/hydra-poc/docs/docusaurus.config.js
- /home/curry/hydra-poc/docs/node_modules/@docusaurus/core/lib/server/config.js
- /home/curry/hydra-poc/docs/node_modules/@docusaurus/core/lib/server/index.js
- /home/curry/hydra-poc/docs/node_modules/@docusaurus/core/lib/commands/build.js
- /home/curry/hydra-poc/docs/node_modules/@docusaurus/core/lib/index.js
error Command failed with exit code 1.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
error Command failed with exit code 1.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
error Command failed with exit code 1.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
Problem was that my directory was pristine from a git clone and there were no metadata generated for the files -> need add the metadata generation step to the build instructions
Completed first round of definitions for glossary.
Discussing https://github.com/input-output-hk/hydra-poc/issues/485 We realise the current solution (adding a TTL field to the NetworkEvent) is not great
- A better solution would be to handle time bounds in submitted transactions, but seems somewhat involved
- However it seems we already have a notion of time in the head logic based on the chain time through
TickOnChainEvent
Looking at how Tick is currently handled: It's just used for the FanOut otherwise the event is ignored.
- The
Tickevent is emitted on aRollForwardfrom the chain - We would need to record the "current time" in the Head state and then compare some TTL, expressed as
UTCTime, on theReqTxor transactions to this time - A problem is that this could be comparing apples and oranges, or 2 sources of time:
- One source from the chain, which is even non-monotonic as time could possibly go backward when there's a fork (?)
- Another source from the outside world, to add a timestamp to network messages
It seems the work to do is more involved than simply recording the passing of time.
For the moment, we decide to:
- Test our fix works in our deployed Hydraw setting
- Merge as it is and tackle a more involved change tomorrow
TIL: Use --target argument in docker build to selectively build and tag one image in a multi stage build
$ docker build --target hydraw -t abailly/hydraw .
Tyring to recreate a Head with FT using newly build image fixing the reenqueuing problem.
- Turnaround for docker images creation is terrible, seems like caches reuse is totally absent which means the whole nix context has to be downloaded/rebuilt every time.
- What happens when synchronising with the chain, is the hydra-node not available for business? -> It shouldn't be as sync happens in the background, looks like it's just a connectivity problem.
We managed to get our hydra nodes connected but having troubles opening the head: I don't have any UTxO to commit apparently!
- Requested more funds from faucet at my address and it appeared in the TUI 🎉 without restarting anything. I can now commmit and the head is open
Having troubles when closing the head: The TUI crashes as the contestation period structure has changed but the docker image is not updated -> lead to crash
- Could be good to have some versions exchanged when connecting...
- Will restart the stack with newer versions
Addressing #492 via #493, trying to understand why the Test.DirectChain hydra-cluster tests fail regularly on the CI
- Error happens in the chain handlers when we try to post a tx: https://github.com/input-output-hk/hydra-poc/blob/master/hydra-node/src/Hydra/Chain/Direct/Handlers.hs#L129
- The internal wallet is trying to resolve an input which does not exist
-
coverFeeis pure so there's nothing to do there, butfinalizeTxruns inSTMso perhaps we could retry? Was it not the case we retried earlier and we removed this?
-
- The internal wallet is trying to resolve an input which does not exist
- Simply retrying forever does not work as 1/ we have a test for that and it will spin forever, 2/ some transactions will never be valid no matter what
- Also it's hard to know which transaction actually failed to be posted... 🤔 -> adding the
PostChainTxtransaction to the exception helps Seems like it's consistently failing on Commit: https://github.com/input-output-hk/hydra-poc/actions/runs/3060644334/jobs/4939408392#step:8:311 => probably seeding is not there yet?
I could pinpoint the problem of one test failing here: https://github.com/input-output-hk/hydra-poc/blob/abailly-iohk/fix-direct-chain-flakiness/hydra-cluster/test/Test/DirectChainSpec.hs#L113 So I would assume the problem comes from the seedFromFaucet function?
- We
waitForPaymentwhen running the faucet but that does not mean the UTXO is actually available in the Wallet => it could be the case the block has not yet been processed and the wallet is not updated - Adding a
getUTxOfunction to theChainhandle and waiting to ensure we observe the UTxO we just created before proceeding
Discussing #485:
- Previous solution we sketched yesterday is not robust enough:
- It's complicated because it requires checking each tx every time we want to emit a snapshot and partition them
- it does not account for past snapshots or tx that will become applicable in the future (because of network reordering)
- Adding a TTL to the
ReqTxseems simpler and safer:- ReqTx is always handled locally and compared with latest seen Utxo
- It's simple to decrement a counter every time we handle a ReqTx message
Bonus points: it can be stated as a global property of the off-chain protocol:
Every submitted tx will eventually:
- either be included in a confirmed snapshot
- or be flagged as
TxInvalidon every node
We add a new ServerOutput called TxExpired to distinguish this situation
We go for adding a ttl :: TTL field to the NetworkEvent, with a default value set when the NetworkEffect is converted into a NetworkEvent
- The TTL of a NetworkEvent is decreased every time we reenqueue it, up until it gets to 0.
Note that this is a bit gross because it's only useful for
ReqTxand we put it at theNetworkEventlevel.
Reflect:
- Adding
ttlto the NetworkEvent does not seem right because the other events don't care about it, so we should find another way. - what we could do instead is to handle the TTL in the
WaitOnNotApplicableTxinstead so that the expiration is handled within the core event loop, where it should probably be handled? => If we want to notify users we'll need to add the effect in thestepHydraNodefunction which also seems not quite right - Other option: Deal with the TTL in the
ReqTxmessage itself, but then the reenqueuing logic does not change the event/message so where would we decrease the TTL?
We decide to leave it as it is now and request feedback from teammates.
Addressing comments on #476
- Docker build is failing but "not on my machine", why?
Discussing #483
- When retrieving era history, the last (and current) era description used to be unbounded meaning that computing future time worked whatever this future point in time would be
- Now, with later version of the node, the current era in history has an upper bound of
$2k$ (TBC) => Converting future point in time to/from slots is meaningful only up until that point - => You cannot compute a contestation deadline past 2k in the future
- => We retrieve the history at the start of the node only => when 2k blocks have passed, we cannot convert time to/from slots anymore
- Solutions:
- either assume constant slot length in the future => we know that slot length and active slot coefficient are more or less hardcoded now on mainnet
- or refetch history every time we need to compute time
Looking at PR in flights:
- 3 of them are related to #189 -> merging SN's PR and we have some homework to do for the other two
- 1 PR for adding deps #480 which we are reluctant to merge because it adds some nix cruft
- #483 about contestation dealine computation which could be merged with some follow-up work on EraHistory computation
🚀 Let's write a test making the problem manifest
- The problem we are seeing is that 2 transactions gets submitted as
NewTxand are both deemed valid at this point, which means they are sent asReqTx. The 2 txs are valid against the same snapshot, but actually conflicting: They want to consume the same UTxO and only one of them will ever be part of the next snapshot
Our test should:
- send 2 conflicting
NewTx - ultimately observes that one becomes part of a confirmed snapshot and the other one is reported as invalid
When submitting 2 conflicting transactions, both are reported as ValidTx to the client
When emitting a ReqSn as a leader, we should discard in flight transactions that are conflicting with included txs.
- Which implies that when I receive a
ReqSnfor signing, I need both set of transactions in order to be able to discard my own copy of in-flight txs =>ReqSncontains the 2 txs list
We also need to remove the TxValid message in favor of a TxAccepted message -> the tx is only valid when it's part of a confirmed snapshot and post a TxInvalid when a snapshot invalidates it
Actually it's not trivial to express the problem in the test because in theory either one of the 2 conflicting txs could be included in the next snapshot and the other one being termed invalid
- Adding a timeout to the test we wrote as otherwise it spins forever ->
- We have a failing test complete with logs from the IOSim -> we see the first tx confirmed in a snapshot and the second resubmitted forever
Drilling down into the place where ReqSn is emitted -> we use newSn function which is a pure function deciding whether or not we should snapshot, and what to snapshot
- We can add a property expressing the fact that if we decide to snapshot, we should flag conflicting transactions
- Working on #189 to unblock FT running Hydraw instance
- While restarting Hydraw on one node I noticed that the other node which has not been restarted still display the state of hte head, with colored pixels, even though the head has been closed. We probably want to clean up the screen when we receive a
HeadIsClosedmessage
We managed to have 2 nodes connected and got to the point of being able to start Hydraw and interacting with it, until the point where the hydra-node went spinning wheels trying to resubmit the same failed tx again and again. -> #485
Issue with AWS setup was mostly related to permissions of files: When adding a user to a group, the changes are not available until the shell is restarted, eg. user logs out/logs in again. In the case of a non-interactive script this means the changes do not apply to subsequent commands.
-
Incremental commit discussion
- current limitation on collect/abort
- taking a step back, do we even need these?
- parallel commit as an optimization which backfired?
- or is it too early optimization?
- changing the spec too much would result in a delay
- seqeuential commits could be a low-hanging fruit -> but is this worth it?
- if more participants is the reason, many party sequential commit is also much slower
- Manuel: MPTs are not needed for incremental commits, but we will require a new security proof anyhow
-
Manuel has been thinking about a fully dynamic Head (add/remove participants)
- It will never be the HeadV1 though, so maybe not yet discuss this
-
I presented what the spec could be written up (On miro: https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3458764532322623400&cot=14)
-
What are our requirements on the formalism used in the spec?
-
What is the status on the statemachine library stuff in plutus?
- Team has been busy with other things
- Manuel has been looking into some new things, but nothing final
-
Next steps
- We realize there are at least four documents in flight on GDrive.
- Sandro/Matthias will continue on the spec and consolidate the above by next week
- Back at using
contestationDeadlineinstead ofremainingContestationPeriod.- Starting with changing the
OnCloseTxto contain the deadline - Should keep the
ServerOutputsimilar (direct translation) ->contestationDeadlineinHeadIsClosed, ez. - Delay needs a
NominalDiffTimenot aUTCTime-> this is tricky, it’s an indicator that we need to “wait until a point” in the head logic. Two options:- Add another effect or change the
Delayeffect semantics - Drop
Delayand instead keep track of time in theState-> this sounds better, but requires an event to progress time- Could use a wall-clock timer
- Could yield blok-chain time as described in ADR20
- Add another effect or change the
- Starting with changing the
- AFter fixing most of the usage sites it’s about time to extend the
Chain -> HeadLogicinterface to include the newTick UTCTimechain event - Adding a chain tick thread to
simulatedChainAndNetworkturns out to be tricky as this code has grown to be quite contrived..need to refactor. - BehaviorSpec sanity check is not working anymore because of the tick thread as it seems.. how can we convince IOSim that it would wait forever? Can we?
- The factoring of
ClosedState -> Closed ClosedStatehad an impact on serialization (obviously). Maybe I hold off of this for now.. but queue this refactor to be done soon. - Similar to the sanity check of BehaviorSpec, the ModelSpec does likely simulate time instead of detecting the deadline -> the timeout triggers?
- Now.. where do these ticks come from? I would say on each
RollForwardwe would convert the slot to the wall clock time and also yield aTick.. let’s write that in a test. - The
contestationDeadlineinHeadIsClosedshall not be used to wait for directly, but more an approximation -> documented it in the Haddock. This should also go into the API -> how to keep it consistent? - Converting
SlotNo -> UTCTimerequires the protocol parameters and era history -> query them each time when rolling forward? - Tying the knot is not possible and/or cannot re-use
queryTimeHandleas theChainSyncHandlershall not be defined to run inIO - Ended up passing a concrete
TimeHandletochainSyncHandler. Which works, but will use the same params, era history and system start for each run ofhydra-node. - While I could get the handlers unit test to turn green, a new property test on the
TimeHandle(roundtrip ofslotFromPOSIXTimeandslotToPOSIXTime) is still red -> the generator forTimeHandlemight be wrong? - I realize that
slotFromPOSIXTimeis always used withposixToUTCTime.. so we could collapse these two. - When seeing things fail after switching to
UTCTime, I realized my implementation ofposixFromUTCTimewas wrong. The property tests helped identify the issue and indeed one of the roundtrips even highlights the fact thatPOSIXTime -> UTCTime -> POSIXTimeis losless, whileUTCTime -> POSIXTime -> UTCTimelooses precision.
- Have built & pushed
hydrawimage manually to ghcr today -> until we have versioning & release process for this package we don’t want CI push images. - NixOS options for
oci-containersis a straight-forward port of the docker-compose files. BUT, where and how to put the credentials and protocol-parameters? - It’s weird that we need to provide a shelley genesis file -> I’m using the L1 one.
- Also, the nodeId will need to be unique.. why are we requiring this again?
- After setting up the hydra-node and the hydra-tui (on demand) it comes to marking fuel / splitting off utxo’s conventiently. In the GCP setup this is done on setting up the environment.. but shouldn’t this be more on-demand?
- Instead of adding yet another shell script.. maybe showing L1 funds, marking as fuel, creating committable outputs etc. is a nice addition to the TUI as it is having a CardanoClient anyways? For now, use the instructions from
testnets/README.md. - Got the protocol-parameters wrong at first, we need zero fees! Changing the protocol fees required a restart of hydra-node, which required a
--start-chain-from-> god, would it be helpful to have some persistence :D
Oups:
hydraw_1 | src/Hydra/Painter.hs:(34,3)-(41,62): Non-exhaustive patterns in case
hydraw_1 |
Got a connected hydraw working, but drawing fails
hydra-node_1 | {"timestamp":"2022-09-03T08:55:46.938578565Z","threadId":101,"namespace":"HydraNode-1","message":{"api":{"receivedInput":{"tag":"GetUTxO"},"tag":"APIInputReceived"},"tag":"APIServer"}}
hydra-node_1 | {"timestamp":"2022-09-03T08:55:46.938668771Z","threadId":94,"namespace":"HydraNode-1","message":{"node":{"by":{"vkey":"a0c12f92fd4bdaaa62fb4cfb2cc39fdf23f45dab2a06da1d5ebeb77a56053861"},"event":{"clientInput":{"tag":"GetUTxO"},"tag":"ClientEvent"},"tag":"ProcessingEvent"},"tag":"Node"}}
hydra-node_1 | {"timestamp":"2022-09-03T08:55:46.938676332Z","threadId":94,"namespace":"HydraNode-1","message":{"node":{"by":{"vkey":"a0c12f92fd4bdaaa62fb4cfb2cc39fdf23f45dab2a06da1d5ebeb77a56053861"},"effect":{"serverOutput":{"clientInput":{"tag":"GetUTxO"},"tag":"CommandFailed"},"tag":"ClientEffect"},"tag":"ProcessingEffect"},"tag":"Node"}}
hydra-node_1 | {"timestamp":"2022-09-03T08:55:46.938678508Z","threadId":94,"namespace":"HydraNode-1","message":{"node":{"by":{"vkey":"a0c12f92fd4bdaaa62fb4cfb2cc39fdf23f45dab2a06da1d5ebeb77a56053861"},"effect":{"serverOutput":{"clientInput":{"tag":"GetUTxO"},"tag":"CommandFailed"},"tag":"ClientEffect"},"tag":"ProcessedEffect"},"tag":"Node"}}
hydra-node_1 | {"timestamp":"2022-09-03T08:55:46.938679292Z","threadId":94,"namespace":"HydraNode-1","message":{"node":{"by":{"vkey":"a0c12f92fd4bdaaa62fb4cfb2cc39fdf23f45dab2a06da1d5ebeb77a56053861"},"event":{"clientInput":{"tag":"GetUTxO"},"tag":"ClientEvent"},"tag":"ProcessedEvent"},"tag":"Node"}}
hydra-node_1 | {"timestamp":"2022-09-03T08:55:46.938944435Z","threadId":102,"namespace":"HydraNode-1","message":{"api":{"sentOutput":{"clientInput":{"tag":"GetUTxO"},"tag":"CommandFailed"},"tag":"APIOutputSent"},"tag":"APIServer"}}
hydra-node_1 | {"timestamp":"2022-09-03T08:55:46.938968315Z","threadId":108,"namespace":"HydraNode-1","message":{"api":{"sentOutput":{"clientInput":{"tag":"GetUTxO"},"tag":"CommandFailed"},"tag":"APIOutputSent"},"tag":"APIServer"}}
Probably becuase the head is not open 🤦
Note to self: We should really refine the states of the UI to introduce XXXXing states so that user does not retry some action because we are waiting on chain events to appear
Finally managed to get Hydraw running in a single-party Head on top of preview network!
A CI build failed https://github.com/input-output-hk/hydra-poc/runs/8140562062?check_suite_focus=true because I pushed local changes that contained Warnings. This is once again a reminder that I dislike having local and CI builds different as it's a waste of time: We are humans so we forget things, which means we'll unavoidably push changes that will fail which introduces a delay as we need to rework locally, then push again, then wait for green light, etc.
Duplicating existing Dockerfile configuration to build a hydraw image
Making progress, I now have a hydraw image :
$ docker run -ti --entrypoint=hydraw input-output-hk/hydraw
hydraw: set HYDRA_API_HOST environment variable
CallStack (from HasCallStack):
error, called at src/Relude/Debug.hs:288:11 in relude-1.0.0.1-FnlvBqksJVpBc8Ijn4tdSP:Relude.Debug
error, called at app/Main.hs:26:33 in main:Main
Managed to have a hydraw server up and running but it's not very verbose and I don't know why I cannot connect to it! => Need to add some logs...
- But it is supposed to log something when it starts 🤔
- Well, files are supposed to be on the FS served by the executable so that probably explains why it does not work. I would have expected some messages though...
- finally got the expected 404 ! I can connect to the process
-
When reviewing / discussin the Direct.State refactor, we realized that we can simply enumerate all the types and define a much less fancy
observeAllTx(in place ofobserveSomeTxwhich works with existentials) at the cost of needing to enumerate all possible states in a sum type. This seems like a small cost and we got this working quite fast.. let's see how the tests are going. -
Switching everything from
SomeOnChainHeadStatetoChainStatewas fairly straight forward. In that way, the ADT sum-type behaves very similar to the existential. -
Replacing
forAllStwith agenChainStateWithTx :: Gen (ChainState, Tx, ChainTransition)was also simple (and boring!) with thedata ChainTransition = Init | Commit | Collect | Close | Contest | Fanout-> this can be anEnumandBoundedso we can use it forgenericCoverTable-> nice. -
Now, I could throw all existentials and GADTs out of
Hydra.Chain.Direct.State. Deleting code ❤️ -
The development cycle to finish this off was pure bliss:
- Adding the generators to
genChainStateWithTx-> seeing coverage improve - Adding more -> seeing the test fail because
observeAllTxstill mocked - Fixing it by adding
Open st -> second Closed <$> observeClose st txpattern match -> "pattern match on states is redundant" / test passes, but missing coverage on last transition - Adding the last generator -> add alternative of
observeFanoutinClosedcase ofobserveAllTx - All green! 💚
- Adding the generators to
Setting up a working local hoogle server on cardano-node repository:
nix-shell --experimental-features flakes
cabal haddock all --haddock-hoogle
hoogle server --local --port 8000
Trying to build local haddock/hoogle for cardano-node breaks with:
src/Cardano/Analysis/Ground.hs:65:5: error:
parse error on input ‘-- * is: {"unBlockNo":1790}’
|
65 | -- * is: {"unBlockNo":1790}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
cabal: Failed to build documentation for locli-1.29.
-
Trying to get funds from preview testnet's faucet, requires a proper cardano address but I only have cardano signing key -> need to ruin
cardano-clibut I don't have it at hand in the test VM -
Deriving address from sk:
docker run --rm -ti --entrypoint=cardano-cli -v $(pwd):/data -u $(id -u) -w /data inputoutput/cardano-node:latest address build --payment-verification-key-file arnaud.vk export NETWORK_MAGIC=$(jq .networkMagic cardano-configurations/network/preview/genesis/shelley.json) docker run --rm -ti --entrypoint=cardano-cli -v $(pwd):/data -u $(id -u) -w /data inputoutput/cardano-node:latest address build --payment-verification-key-file arnaud.vk --testnet-magic ${NETWORK_MAGIC}Needed to go https://docs.cardano.org/cardano-testnet/tools/faucet to request funds. The first address from google search does not work.
-
Trying to start hydra-node passing the published scripts address fails:
cardano-node_1 | [e50a3b7c:cardano.node.ChainDB:Notice:37] [2022-08-31 13:52:50.60 UTC] Chain extended, new tip: e7ee959818a8f7f122f44f0e04d1a8d5b76b276cf91b250ea36728542f4e5df1 at slot 772663 hydra-node_1 | hydra-node: MissingScript {scriptName = "\957Initial", scriptHash = "8d73f125395466f1d68570447e4f4b87cd633c6728f3802b2dcfca20", discoveredScripts = fromList []} curry_hydra-node_1 exited with code 1Scripts id is available here: https://github.com/input-output-hk/hydra-poc/releases/tag/0.7.0 -> adding it to the environment
-
Actually it works fine -> need time to catch up with the network. Got a running cardano-node + hydra-node stack on top of preview network, now need to create some fuel UTXO?
-
Copy/pasting and adapting the
fuel-testnet.shscript to be able to run with docker containers Managed to havefuel-testnet.shscript work with only docker containers -> I now have a head with fuel UTXO and some other UTXO to commit on preview 🎉
Pairing Session - #467
-
Working on Model to complete
performCommitsuch that it outputs the committed UTXO -
Implemented a reverse lookup function to find who's the committed from a UTxO address, which makes the whole
performCommitcode more complicated than it should be -
Discussed what's really the semantics of this observation process, and whether it makes sense or not -> This lead us to want to see the property failing because of the
postconditionreturningFalse, which was easy enough: Just pass the actingpartyinstead of the observed partyptin theHeadLogic: https://github.com/input-output-hk/hydra-poc/blob/ensemble-upgrade-quickcheck-dynamic-1-0/hydra-node/src/Hydra/HeadLogic.hs#L312 -
Trying to define a
DLbased property, currently struggling to define a proper runner -
Spent time playing type tetris to be able to express a property which works over a DL formula 😓 we really need to unpack this stuff to understand what's going on, esp. as things get more complicated because of
IOSim s
Unpacking the conflict-free liveness property from the paper:
-
network adversary: Behaviour of the adversary is expected to not delay indeinitely messages => all messages eventually get delivered (and all nodes recover from crashes and disconnections)
-
conflict-free : Property of the submitted transaction: No transaction is in conflict with any other transaction (eg. no 2 parties try to spend the same UTxO)
-
We managed to draft a first version of the conflict-free liveness property using DL 🎉 This required introduction of 2 new "technical" actions but this all seems to make sense. and something we could generalise into a "test language" later.
- Discussing specification of current protocol -> realisation that 100% of people want the ability to add/remove funds while the head is opened
- However, it's not as straightforward as we initially thought: Implementing incremental commits/decommits requires significant changes to the protocol, implementation of MPT (because we need to prove membership of UTxO and participation in the head)...
- Revisiting "compact" specification in the form of graphical state machine with annotations -> Seems like it could be more useful than detailing/rewriting what's in the paper
Discussion about our documentation website publication process. It feels awkward, esp. as we've spent 2-3 days last week trying to add some "minor" information which required us to delve deep into the details of the framework.
- There's a cost to pay for each framework, and we know that for each of them customisation will be costly and requires understanding of the framework past the "tutorial"
- docusaurus is a good framework, even though it feels complicated at time and we're not FE experts. There are quite a few other contenders but it's unclear what the benefits would be.
- The pain is felt infrequently and it's not clear how to solve it
Updating #472 following discussion on logging:
- Logging
TxIdwhen posting/receiving transactions from the chain is fine -> we can use it as correlation to look for more information from the chain - Could be interesting to log more information from the block (eg. slots)
- A general principle of logging should be that every "action" (side-effect) should be logged,
-
ProcessingX/ProcessedXpairs of logs are valuable to understand the flow and get timing but the naming is confusing and does not stand out when reading the logs -> replace withBeginXXX/EndXXXpairs
Discussing issue #191
- We should at least clarify the various scenarios outlined
- If any party decides to upgrade a node it impacts all other? => not really, depends on what's touched
- Changes might or might not be breaking
- Having long-running Hydra nodes working and doing stuff with them will shed a lot of light on those issues
Discussing #195
- Seems more important than the previous one because we know Cardano will change
- There are guarantees on the posting direction: A cardano node is supposed to be backward-compatible (if only beecause it needs to revalidate chain from the origin)
- Possible solution would be to ensure that one can read old persisted state with new hydra-node
AB Solo - #189
-
Trying to boot a Hydraw instance remotely on a GCP machine, having trouble uploading keys
-
Need to generate own keys for off and on-chain transactions, but how do I generate Hydra keys? => Writing a simple executable that generates a random Hydra key pair and dumps to some file
-
Built a small utility called
hydra-toolsthat generate a pair of keys. -> #474 Next question is: How do I get the cardano-node config? Seems like the one in the demo is for a block producing node, eg. with KES, VRf, Opcert and what not... I presume it's checked out from cardano-configurations -
Got a bit confused by the content of
testnetsdirectory, seems like it's doing some kind of bash/redirection magic which makes things hard to follow. It assumes thecardano-configurationsdirectory is checked out as a submodule, which requires a bit of knowledge and could lead to confusing errors. -
It's relatively easy to run a mithril-client to list available snapshots and retrieve them so I am going to add that in the script:
docker pull ghcr.io/input-output-hk/mithril-client:latest export NETWORK=testnet export AGGREGATOR_ENDPOINT=https://aggregator.api.mithril.network/aggregator docker run -ti -e NETWORK=$NETWORK -e AGGREGATOR_ENDPOINT=$AGGREGATOR_ENDPOINT ghcr.io/input-output-hk/mithril-client:latest listStill need to ensure the aggregator lives on the preview network otherwise it won't work with our node
- Refactoring Hydra.Chain.Direct.State, goals:
- No semantic changes
- Address https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/test/Hydra/Chain/Direct/StateSpec.hs#L427-L429
- Make
reifyStateredundant / usage simpler in https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/src/Hydra/Chain/Direct/Handlers.hs#L283, e.g. usingcast - Not using kinds & type-level stuff -> less fancy https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/src/Hydra/Chain/Direct/State.hs#L189
- Find alternatives / not require "unsafe" functions https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/src/Hydra/Chain/Direct/Context.hs#L188
- At the very least make them easier to use than https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/src/Hydra/Chain/Direct/Context.hs#L125
- Still allow [[https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/test/Hydra/Chain/Direct/StateSpec.hs#L151-L154]["observe all transactions" test]] and [[https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/test/Hydra/Chain/Direct/StateSpec.hs#L536][forAll.. generators]] as litmus test
- Instead of the "try all"
observeSomeTx, we would want to use specific functions and give the UTCTime to only one of them to address this FIXME: https://github.com/input-output-hk/hydra-poc/blob/aa32a632df9b3d7148acaa0575ff27ffd64c409e/hydra-node/src/Hydra/Chain/Direct/Handlers.hs#L237-L238
- First, I made distinct types and introduced a
ChainContextinstead. - When changing the
forAllInitfunction inStateSpec, things became interesting - Looking at the three call sites of
forAllInit:-
propBelowSizeLimitdoes not access the first argument -> ez -
propIsValiddoes need to get aUTxOfrom it -> let's create a type classHasKnownUTxO -
forAllStthis is the tricky one as it right now requires all property generators to have anOnChainHeadState st-> using type classes here as well
-
- I plan to keep the
ObserveTxtype class. To overcome the limitation with providing additional information (besides the state) to some specific transition, an associated type could work well (last bullet on goals). -
Chain.Direct.ContextandStateSpecmodules require a lot of mocking before actually running something -> it's a big overhaul now. - Moving the
ChainContextinto the individual state types to not make everything more complex (two arguments).- One example is in ContractSpec where we seemingly want to generate init transactions but do not have a context available besides
SomeOnChainHeadState. - NB: The source of ^^^ this is debatable! I disagree with the premise that off-chain should deem a transaction invalid (not being an
Observation Init..) when the on-chain code was okay with it. -> Not bother about this usage now, and suggest to not needing this test / semantics on this in the first place.
- One example is in ContractSpec where we seemingly want to generate init transactions but do not have a context available besides
- Got it compile and obviously all tests with mocks fail -> trackling the transaction enumeration and observeSomeTx now.
- Do we even need
observeSomeTxif we have the ObserveTx type class? - When seeing the
observeAbort& fixing thegetKnownUTxOfunctions for the new types, it becomes very apparent that transaction construction often just needs a way to looupTxIn -> TxOut. That is, the relevant observed UTxO set so far. - When debugging why some
observeXXXfunctions yield Nothing I needed to resort to instrument the actual code often. Instead we should haveEither IgnoredBecause InitObservationas return value. - Failures on
observeSomeTxis not very descriptive (even the rollback codes is a red herring) -> lets improve its output. - When not correctly specifying
transitionsfor e.g.ClosedState, thenobserveSomeTxdoes not try to use them and hydra-node tests pass, but only in the end-to-end we realize we do not observe some transaction. -> Is this machinery really worth it?
-
Adding
--hydra-scripts-tx-idtohydra-clusterwas quite straight forward. Having two mutually exclusive flags, the other being--publish-scriptsseems intuitive enough. -
When trying things out on
vasil-dev, I observed weird things: The node would not be synchronizing past a fixed point.. somehow mydb/was borked as with a new state directory it was fine!?- This was later explained by a temporary fork somehow related to P2P on the vasil-dev testnet over the weekend.
- Resolution of this is to use non-p2p config and resync (that's what I did intuitively, see commits).
-
Also, after correctly synchronizing the scenario was just killed and a
DiffusionErrored thread killedin the cardano-log was a red herring -> the hydra-node was not starting up because of the demo containers running in the background.
Ensemble Session #466
Updating Model code to changes in the q-d API is pretty straightforward -> extract perform outside of State typeclass and wrap it into a RunModel => 🎉 Managed to remove 45 lines and simplify the model
Now introducing specific action constructors to be able to have different return types in Action and thus improve our postcondition to check those. Hitting problem that GADTs don't mix well with record fields syntax: If return type is different then field names must be different. We try to work around the issue by introducing PatternSynonyms but it leads nowhere -> biting the bullet and just pattern-matching
We are hitting an issue trying to get better error from failed property run: There is now Show a constraint on the monitoring function hence it's not possible to provide information when property fails through counterexample. This seems a shortcoming of the model -> add a Show a constraint to StateModel class?
Working on upgrading quickcheck-dynamic to hackage version -> #466
Need to upgrade the index: field in cabal.project to make sure we can resolve q-d
Pulling branch with updated index yields the following error when entering the shell:
$
direnv: loading ~/hydra-poc/.envrc
direnv: using nix
error: Unknown index-state 2022-08-25T00:00:00Z, the latest index-state I know about is 2022-04-06T00:00:00Z. You may need to update to a newer hackage.nix.
(use '--show-trace' to show detailed location information)
direnv: nix-direnv: renewed cache
direnv: export ~XDG_DATA_DIRS
Seems like we also need to update haskell.nix reference because it does not know recent cabal updates, but upgrading haskell.nix puts us in a bad state: In the new shell we start building ghc versions!
Trying to simply update q-d source reference does not work out-of-the-box either, seems like shell is broken in some weird way => resetting to previous situation then using source-repository dependency pointing at the 1.0.0 commit
Turns out version 1.0.0 of quickcheck-dynamic repository has 2 packages so it can't be used directly -> need to a subdir: stanza to tell cabal to build the right package
We finally witness the expected error from Model file:
[36 of 39] Compiling Hydra.Model ( test/Hydra/Model.hs, /home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.7/hydra-node-0.7.0/t/tests/build/tests/tests-tmp/Hydra/Model.o )
test/Hydra/Model.hs:250:8: error:
‘ActionMonad’ is not a (visible) associated type of class ‘StateModel’
|
250 | type ActionMonad (WorldState m) = StateT (Nodes m) m
| ^^^^^^^^^^^
test/Hydra/Model.hs:397:3: error:
‘perform’ is not a (visible) method of class ‘StateModel’
|
397 | perform _ Seed{seedKeys} _ = seedWorld seedKeys
| ^^^^^^^
test/Hydra/Model.hs:444:3: error:
Not in scope: type constructor or class ‘ActionMonad’
|
444 | ActionMonad (WorldState m) ()
| ^^^^^^^^^^^
cabal: Failed to build test:tests from hydra-node-0.7.0.
- Worked together on showing last updated & translated in docs https://github.com/input-output-hk/hydra-poc/pull/457
- Could improve the rendering and use the docusaurus client API to easily access the
currentLocale - We looked for some ways to include the
<DocumentMetadata />component on all pages- Maybe we could use a plugin/theme which does extend the standard
plugin-content-docs/theme-classicplugin/theme - There are some examples which translate "```js live" markdown blocks into live editors -> could use that for our
<TerminalWindow /> - The standard
plugin-content-docsplugin does already determinelastUpdatedAtfor each page, but throws this info away when converting it'sDocMetadatatoGlobalData
- Maybe we could use a plugin/theme which does extend the standard
- On the way we also fixed the "Edit this page" links on translated content, was a simple configuration change to the standard plugin
Tried to set a better dev environment for the docs/ stuff on VM with (plain) Emacs.
- Added prettier to the dev tools so that I can have standardised auto-formatting in and out of IDE, with default configuration which is somewhat ugly but at least standard
- Needed also to add
nodejspackage toshell.nixso that ts-ls (typescript-language-server) is happy
Tried to start the demo using locally built docker containers and ran into an issue with user id: We use the current user's id to run hydra-node container to publish the scripts, but the cardano-node's socket is owned by root so the call fails.
There's apparently a new 1.35.3-new image which allows more customisation through env variables and run the nodes as non-root.
Working on merging configurable peers PR. Slight problem is that this PR was approved 5 days ago and then more commits were added to cope with changes in TUI. Rewinding this PR to some previous commit when it was approved, then stacking another PR on top of it -> Using graphite would help here!
Having a look at how TUI handles peers information, there's some redundancy between peers and peerStatus
Testing the existing TUI for configurable peers:
- Modifying peers on one node is not reflected correctly: When I add a peer on tui-1, I don't see peer connected, or rather I see it disconnected, but it appears as
Peer Connectedon node-2 which is misleading - Seems like peer state is a 2-step process: First know the peer, then connect to it
Back to the drawing board to see the state. Talking through the awkwardness of the peer connected in the TUI leads us to realise this might be premature work: This is not wrong, but it's unclear how this would be useful for actual users/Hydra nodes operators -> reminder that we should start from why, from the users' experience of the thing we are planning to implement. What's the user journey?
This Configurable peers issue went a bit overboard w.r.t the actual need it was meant to address (eg. easily configure benchmarks) and it's great we realise this by trying to fix the TUI
Today we had our very first Fika meeting today
-
#455, addressed some PR comments:
- We stuck to using
race_instaed ofwithAsync+linkas suggested because it seems this would change the semantics of the code: What we want is to run 2 threads in parallel, stopping both whenever one of them copmlete, which is exactly whatrace_does. As per the hackage docs, link only ensures exceptions get propagated from the spawned thread to its continuation but won't stop the latter in case the spawned thread stops expectedly. - Cleaned up testing code a little by introducing a
noNetworkfixture that creates a dummyNetwork
- We stuck to using
-
#457: Reviewed comments and discussed what's the best approach should be.
- It seems there are actually 2 different levels of metadata we are interested in: Site metadata (commit SHA, last publication time) and Page metadata (last omdification time, possibly author, drift of translation from the core EN...)
- Not a big fan of the string interpolation approach which seems repetitive and error prone. Suggested we could handle this in 2 steps:
- Generate a
metadata.jsonfile containing whatever we want, for each page indexed by their path + site level - Use that file in a docusaurus component say
PageMetadataandSiteMetadata - Only modify the global layout so that we don't have to add that information on each page
- Generate a
- Adding
headReferenceto the script registry was quite straight-forward. The roundtrip property ensured it can be looked up and generated, while the end-to-end ensures correct publishing as well. - Most annoying: no internet, working cabal because of a prior
cabal build all, but forgot to lsp and it tries to fetchsource-repository-packagesnow. - When also wanting to publish the head script, it fails because of:
uncaught exception: SubmitTransactionException
SubmitTxValidationError (TxValidationErrorInMode (ShelleyTxValidationError ShelleyBasedEraBabbage (ApplyTxError [UtxowFailure (UtxoFailure (FromAlonzoUtxoFail (MaxTxSizeUTxO 17986 16384)))])) BabbageEraInCardanoMode)
Of course, all three scripts don't fit in a single transaction (barely)
- Transaction sizes of e.g.
collectComreduces from14kto4kthough and result in~0.5 ADAcost improvement. - Was a nice experiment nontheless 🤷
- Providing funds in vasil-dev to "our faucet" from "the faucet":
curl -X POST -s "https://faucet.vasil-dev.world.dev.cardano.org/send-money/$(cardano-cli address build --verification-key-file hydra-cluster/config/credentials/faucet.vk --testnet-magic 9)?api_key=oochuyai3ku4Fei4ahth9ooch9ohth7d"
-
Hoping to wrap up the work on using reference scripts today, the demo still needs to be updated to publish scripts ahead of time and there are various TODOs left in the code that we introduced with this work. Some are easy to address (e.g. moving code to the
hydra-cardano-api) and some may require additional thoughts. I'll address what I can and at least get the branch merged. -
Made progress on getting "dynamically configurable peers" in the system. The network layer has been extended with a
modifyPeerfunction which allows to add or remove network peers dynamically, effectively restarting all network connections. This is only allowed before the application has started (since afterInit, peers are fixed), although debatable? -
We've noticed lately that the user-manual was no longer updated. First, it was due to build failures in the documentation. Then, we inadvertently pushed on the
gh-pagesbranch, overriding the history with wrong information. To prevent this to happen in the future, branch protection were added to thegh-pagesbranch which now prevent the CI workflow to push on the branch (as the workflow force-pushes by default) and we're now "stuck" since only Arnaud & Sebastian have admin access rights (needed to change the branch's settings) on the repository and both are on holidays. We can, in all likelihood, try to configure the workflow action publishing to gh-pages in a way that does not require force-push and that'd be compatible with the branch restriction. -
Meanwhile, we've been working on adding some meta-information to each page of the user-manual to include: (a) the last time a page was updated (linking to the relevant commit), (b) the last time a page was translated (linking to the relevant commit). Ideally, we want to keep both in-sync and having this information visible on each page will not only help us doing so, but it will also inform users about a possible discrepancy in the translated pages.
-
Their questions:
- Cost & complexity of comitting into a Head?
- What if operators don't agree on the state?
- Whats the throughput?
- Can we change the protocol parameters in Hydra Head?
- What about network/consensus parameters?
-
Incremental commit/decommit they think is very important
-
Whats the next step?
- We are looking for launch partners
- They plan to launch their stuff in Q3/Q4
- Demo in Q4 sounds viable to them
- Stay in touch (discord / twitter)
-
Goal: find out how Hydra could play a role in their protocol
-
Principles
- programmable swaps
- decentralized and democratizing
-
Programmable swap
- seems to be a configurable trade
- commit -> execute || commit -> abort
- commits mint tokens
- "active frontier" swaps mean that they are ready (all triggers met)
- explanation focuses on blocks and a certain block enabling triggers
-
This view on Hydra is likely not working that way:
- "All EUTxOs present in active frontier can be moved to the hydra head for execution and once executed, back to layer 1 to settle the trades on the base layer"
- Only makes sense if commit is already done on L2
- Especially if resulting UTxOs get used for many more swaps later
-
No AMM, but order-book -> who runs the order matching?
- Performance degrades with more and more node operators
- If not users, by definition custodial
- Decentralization (MAL token?)
- Fragmentation of liquidity or circumvent via routing?
-
NFT receipts -> needs to be an NFT? Some UTxO with a proof instead?
- It should be good to merge as it is now (modulo some extra proof-reading), important steps and transitions are now properly documented.
- In another increment, we can give a go at improving either the arguments docstrings or, the arguments themselves by introducing proper types for intermediate functions. All-in-all, the head logic is still very hard to read now and it felt that for some function, we even loose a bit of the context by having those naked arguments.
- There are some other TODOs left the code or, unclear pieces of logic that could be good to assess in ensemble and see how to address them.
Their command line tool uses python, so the setup was a bit involved. To get things running (also on NixOS), SN created a repository with a README: https://github.com/ch1bo/snet-demo
-
Intro with a scenario overview
- AI consumer -> AI developer using a channel for payments
- channel getting funded 2 AGIX by consumer (unidirectional)
- developer authorization required to withdraw by provider
- consumer can claim refund if the expiration time for the channel is reached. the consumer can extend the expiration at any time
- off-chain authorization of 0.1 AGIX (stored in etcd? using protobuf comms?), seen by the daemon
- new authorization are not invalidating, but aggregating the amount in later authorizations
- nonces incremented on withdrawal by dev (claim) -> stored on chain
- fast-paced interactions vs. slow main-chain claim -> work around by pre-authorizing enough
- quick discussion on high pre-authorization vs. ability to cheat / withdraw more -> reputation also used
- signature over nonce, block number (not too old), amount, sender id, group numer.. service id?
-
Hands-on section, steps performed:
- seb
-
- setup
snet account balance && snet identity list -
- bring amount to the escrow contract (on chain operation)
snet account deposit 0.000012 submitts
snet account balanceshows funds
-
- create a channel (on chain)
snet channel open-init snet default_group 0.000001 +25days1 submitts returns channel_id
-
- make a call - is an API client and does the payment processing as well
snet client call snet example-service default_group add '{"a":10,"b":32}'1 submitts returns a value: 42
- deamon
-
- show unclaimeds
snet trasurer print-unclaimed --endpoint http://example-service.a.singuralirtynet.io:8088/
- show unclaimeds
-
- claim from chain_id - also two-stage, need to withdraw later
snet trasurer claim <chan_id> --endpoint http://example-service.a.singuralirtynet.io:8088/1 submit
- claim from chain_id - also two-stage, need to withdraw later
-
Architecture notes
- Distributed storage (etcd) to store off-chain state
- Any user could join in on the cluster
- Usually for state within organisation (not global)
- Authenticated using certs
- IPFS for organization metadata
- Used to lookup orgs and services
- This is the "registry" product of SNet
- We used infura to connect to & submit Ethereum txs
- They were using AWS instances
- Signature can be submitted with the call (as Header or part of grpc)
- Client is in between user and network
- Daemon the same on the server side (sidecar proxy)
- Distributed storage (etcd) to store off-chain state
-
Closing notes
- Need to operate a cardano-node and hydra-node is the greatest gap
- SNet expects we already think about that and come up with ideas
- Question: client-side notifications on withdrawal period right now?
- Not really a built-in notification system
- This would correspond on the hydra-node needing to be online & responsive
- The MPE protocol is very client-biased (Tail would be a better fit?)
- The deamon is the boss
- take care of authorizations
- validations
- key verifications
- manages the mechanics
- does not manage the private key of the receipt
- follows the "sidecar" proxy pattern.
-
Multiparty Escrow Contract address: https://etherscan.io/address/0x5e592F9b1d303183d963635f895f0f0C48284f4e#readContract
-
We've been introducing the concept of "script registry" in order to publish and re-use scripts in input references. This is particularly useful for the abort transaction which gets otherwise too large after 1 participant.
-
So far, our approach from the internal code has been to infer the location of scripts (i.e. output references) from a single transaction id. We then resolve the first
NUTxO associated with that transaction id and optimistically look for reference scripts in the associated outputs. -
Regardless of the approach, we now need to provide this extra input to the Hydra node, which sparked a discussion: should this be optional?
- On the one hand, this is clearly needed for the abort transaction. Without that, it isn't possible to abort a realistic Hydra head.
- On the other hand, this makes the user experience quite worse because it now requires user to either publish scripts themselves under the same implicit convention that we're assuming in the code (i.e. in a single tx, within the first
Noutputs) or, it demands that we provide this as configuration upfront.
While making it optional sounds doable, it also incurs a cost on testing and maintenance on a mode that we now isn't realistic for production. Thus, rather than making it optional, we seemingly want to ensure that getting that transaction id (or whatever is needed to construct the script registry) is relatively simple; by providing a command-line command to do so, and by providing configuration for each release with pre-published script references.
- On a recent run of the smoke test agains the
vasil-devtestnet, we got anErrNotEnoughFunds (ChangeError {inputBalance = Coin 4848000, outputBalance = Coin 7298000})failure: https://github.com/input-output-hk/hydra-poc/runs/7563153281?check_suite_focus=true - Looking at the UTxO of
alice.vkonvasil-dev:
TxHash TxIx Amount
--------------------------------------------------------------------------------------
00f5d790c2e8db5d7eca612435722a9d98730c961d58bc9539bc0b87af664fcf 0 50530000 lovelace + TxOutDatumHash ScriptDataInBabbageEra "a654fb60d21c1fed48db2c320aa6df9737ec0204c0ba53b9b94a09fb40e757f3"
0740b13e2af636435fbf2f476aa21651c5c611c228fd40e700c74f50337dcac8 1 96702000 lovelace + TxOutDatumHash ScriptDataInBabbageEra "a654fb60d21c1fed48db2c320aa6df9737ec0204c0ba53b9b94a09fb40e757f3"
0b0a5524dd5dcdd356327a1a985d2eefa3691e00c0feba726759c3d4412e9d1b 1 19444000 lovelace + TxOutDatumHash ScriptDataInBabbageEra "a654fb60d21c1fed48db2c320aa6df9737ec0204c0ba53b9b94a09fb40e757f3"
1fb225ae58f7d90a7813e356b00f579e57a32b95179822e1be6f06ac4239b816 1 4848000 lovelace + TxOutDatumHash ScriptDataInBabbageEra "a654fb60d21c1fed48db2c320aa6df9737ec0204c0ba53b9b94a09fb40e757f3"
- Seems like smoke tests do yield in fuel being left over. (Only failing or all smoke test runs?)
- To unblock running these tests on the
vasil-devtestnet, we could employ some maintenance on the testnet. - Writing a shell script to "squash fuel utxos" on this testnet.
- Despite some bash-fu,
cardano-cliis a bit of a pain to work with if we don't want to have change outputs. - Just building the tx with less outputs, yielding in a change output, does print the (over)estimated fee to the stdout, which we can use.
- Despite some bash-fu,
- Now, running
squash-fuel-utxo.shdoes prepare a signature to compact the fuel of a given.skinto a single output 🆒 - Next we should look into these fuel residuals and maybe add a
finallystep to our smoke test run which sends funds back to the faucet?
- When investigating why the "abort tx using reference scripts" branch is red now, we saw that our script registry roundtrip was red.
- Turns out, we have been generating invalid ScriptRegistry because of an
import qualified Hydra.Contract.Initial as Commit
- Turns out, we have been generating invalid ScriptRegistry because of an
-
Agenda: Inigo + Gamze join us on the topic of MuSig2 / secp256k1
-
Implementation of MuSig2 and a discovery
- working, but was not "good" in terms of separating contexts
- we use it on top of secp256k1 from bitcoin, and make it compatible with the Schnorr protocol standardised in BIP0340
- which seems to be only fine for single signatures
- we need to do some tweaks to the MuSig2 protocol to be compatible with BIP0340 (only uses even y coordinates)
- we can work around this when creating signatures (checking the aggregate key or the signature)
-
We quickly discuss about key aggregation
- we should check and be sure that we do NOT need to aggregate keys in plutus
- only the signature verification can be done on-chain / in plutus
-
On the delay of secp256k1 primitivies
- Plutus builtins are directly bindings to c functions
- Some of these functions were expecting correct public keys, but the binding/glue code was not checking the input structure
- Another delay on vasil hf might make this possible to enable in time
- Other users of schnorr signatures are side chains / bridges
-
On performance
- We do not expect orders of magnitude difference in cost on both verifying / signing
- The cost parameters should give a good understanding of Schnorr vs. Ristretto ed25519
-
Gamze is also workig on Mithril: stake-based threshold signatures lib / mithril-core
-
Open question (other topic):
- in the voting use case
- instead of using public keys / stake keys use something else to retain privacy
- "ring signature schemes" could be relevant
- also e-voting cryptographic protocols
-
Trying to extend
FailedToPostTxerror with a current slot no. It's a bit annoying as we don't have it in the tx submission protocol and only in waiting for the response we can query the current slot. <2022-07-18 Mon 16:24> -
Still not nice to trace or debug the whole thing.. other idea: use the log time and expected slot from that.
-
The cardano node logs much higher slots numbers than the
pointInTimeavailable to the hydra-node:When
hydra-nodelogged the fanout which will fail:{"timestamp":"2022-07-19T14:56:40.015805531Z","threadId":85,"namespace":"HydraNode-1","message":{"directChain":{"pointInTime":{"Right":[169,1658242595000]},"tag":"ToPost","toPost":{"tag":"FanoutTx","utxo":{}}},"tag":"DirectChain"}}The
cardano-nodelogged:{"app":[],"at":"2022-07-19T14:56:40.00Z","data":{"credentials":"Cardano","val":{"kind":"TraceNodeNotLeader","slot":174}},"env":"1.35.0:00000","host":"eiger","loc":null,"msg":"","ns":["cardano.node.Forge"],"pid":"1251951","sev":"Info","thread":"32"}Which is off by
5 slots! -
I think I found the issue: Query tip obviously only returns the
slotNoof the latest block. This is only every 20secs on testnet. Hence, he likelihood of using querying a slotNo/UTCTime "in the past" is higher there, leading to too early fanout transactions. -
Instead of working around it, I decide to try fix the
queryTimeHandleby using thewallclockToSlotto get the slot equivalent using the hosts current time (instead of the latest block tip). -
After switching the implementation of
queryTimeHandleto use the wall clock time, I now get invalid slots (in the future)- Seems like the ledger is also only using block-updated slot numbers. With close deadline at slot 218, posting the fanout tx at around slot 220 (reported by new queryTimeHandle and the cardano-node log), I get this ledger error
{"timestamp":"2022-07-19T16:22:34.036250197Z","threadId":590,"namespace":"debug","message":{"contents":[1,{"postChainTx":{"tag":"FanoutTx","utxo":{}},"postTxError":{"failureReason":"HardForkApplyTxErrFromEra S (S (S (S (S (Z (WrapApplyTxErr {unwrapApplyTxErr = ApplyTxError [UtxowFailure (UtxoFailure (FromAlonzoUtxoFail (OutsideValidityIntervalUTxO (ValidityInterval {invalidBefore = SJust (SlotNo 220), invalidHereafter = SNothing}) (SlotNo 211))))]}))))))","tag":"FailedToPostTx"},"tag":"PostTxOnChainFailed"}],"tag":"ReceivedMessage"}}
indicating that the ledger thinks the current slot is 211.. which matches the last block 👊
- Keeping the
queryTimeHandlelike it is now as it's more consistent with intuition.. we still need to have the hard-coded delay though. - Instead of the
DelaytoShouldPostFanoutwe should be handling the event by comparing it to a slot (tick) updated upon receiving a block and only yield the effect when enough time passed.
- After properly introducing the
ScriptRegistryfor the initial script, we extend it to the commit script - Adding the commit script reference stuff now took us only 12 minutes 💪
- Abort validation test fail now and the redeemer report is unreadable (fixing it). Seems like the script hash was not resolved, maybe the reference inputs are off?
- Debugging the smoke test trying to fan out too early. Hypothesis: something's off with
slot -> timeconversion and/or it's happening because of slower block times on real testnets. Try increase block time of devnet to reproduce on integration tests. - Re-using the
singlePartyHeadFullLifeCyclescenario in the e2e integration tests was nice! - Wanted to implement a
failIfMatchand monitor for the PostTx error on the side, but ourwaitNextprimitives are consuming and not straight forward to implement multiple "watchers". - It's reproducable with both,
slotLength = 1and alsoslotLength = 0.1 - Switching to
activeSlotsCoeff = 1.0(normal for devnet), the problem was NOT observable anymore, while it's happening sometimes withactiveSlotsCoeff = 0.05
Working on https://github.com/input-output-hk/hydra-poc/issues/397
- Finishing
TxOutchanges due toReferenceScripts, tests run again but still fail obviously - We continued implementation of
publishHydraScript, needed to adapt the ADA deposit:v_initialseems to require ~23 ADA - We should not spend Alice's fuel when publishing, but maybe use the faucet key instead
- Wiring
hydraScriptsTxIdthrough direct chain layers to use it inabortTxconstruction. We quickly discussed using a newtype to be more clear of the purpose of theTxId - Now we need to not include scripts and use
PReferenceScriptinstead, adding more things tohydra-cardano-api. - We realise that the
Maybe ScriptHashseems to be only used for minting script references? Maybe that should done differently using a type family usingWitCtx - We ran in into the problem that we referred the
#0output, but that was used as change bymakeTransactionBodyAutoBalanceso#1is correct. Updating the index helped, but this is obviously very fragile -> we drafted aHydraScriptRegistryconcept to resolve referrable UTxOs earlier and reference them with confidence inabortTxet al.
On the (re-)specification of the Coordinated Head Protocol:
-
No progress since last time
-
WIP documents:
-
Summary of last time
- Not dive too deep - okay to be more abstract
- The formalism of the paper is not too bad
- It's great to have script verification be separate from off-chain "value construction"
-
We could still help by documenting the status quo in the Hydra.Logic module!?
- Proposed to do a small task: https://github.com/input-output-hk/hydra-poc/issues/425
-
Rollbacks: relevant, but maybe orthogonal? Shared website documentation https://hydra.family/head-protocol/core-concepts/rollbacks/
- Running something similar like the EndToEndSpec not against the devnet, but against a testnet. Maybe this could be packed into an executable of
hydra-cluster, running a single (non-block producing)cardano-node, ahydra-nodeand one hydra head lifecycle + some seeding/refueling. - When writing the
withCardanoNodeOnKnownNetworkthecardano-nodekeeps crashing because of invalid byron genesis hash -> thewithCardanoNodealways rewrites the system start: need to refactor that into the withBFTNode (or better calledwithCardanoNodeDevnet) - Passing faucet signing keys around could be avoided of using the well-known key from the repository in all testnet networks? This simplifies parameterizatin all around and should be fine as this is only testnet.
- Full life cycle on an existing testnet works now! Fanout comes a bit too early? We do post just after receiving "ReadyToFanout"..
- A single smoke test run of
singlePartyHeadFullLifeCycleseems to cost about 16 tADA.
- Debugging the failing
collectComTxtest inStateSpec- Test failure reports head datum is not matching
- Needed to undo factoring of
genCollectComTxto get a hold of the comitted utxo's whose hash might not match - Turns out: three identical
UTxOsets are committed and they "collapse" when merged into a singleUTxOset
- We should make sure that our generators are not generating ill-formed scenarios, e.g. three txs committing the same utxo
- Implemented some UTxO generator properties
Checking whether PR https://github.com/input-output-hk/quickcheck-dynamic/pull/1 is fine to merge and use in plutus-apps repository.
I wasted time looking for the right way to get a proper sha256 to put in the cabal.project file given some error reported by nix-build.
error: hash mismatch in fixed-output derivation '/nix/store/g590gpmld6bnydhnr7xrjkhzszjvca8k-quickcheck-dynamic-9659630.drv':
specified: sha256-oOIjUJ4nXXwK4KdJaoiKJmvlLkn8r3OnZHpiNTlvOSQ=
got: sha256-TioJQASNrQX6B3n2Cv43X2olyT67//CFQqcpvNW7N60=
The correct answer is :
nix-hash --type sha256 --to-base32 sha256-Z2aTWdLQpSC5GQuIATvZ8hr96p9+7PITxpXHEARmKw8=
but I have used
# install nix-prefetch-git
nix-shell -p nix-prefetch-git
nix-prefetch-git https://github.com/input-output-hk/quickcheck-dynamic 9659630c68c91b86f3007f30b9aa02675bf8c929
which works but is uglier.
#408 Fixing JSON serialisation
Discussing with SN what's the best path forward to fix JSON serialisation:
- Seems like moving to cardano-api's types is the way forward but looks like a hell of a rabbit hole... Don't want to get stuck on the other side of the mirror
- How about using https://github.com/haskell-waargonaut/waargonaut ?
- We should try first to make small change to cardano-api, either:
- Remove the orphan instance and see what changes it entails there => Breaks CI and some code depends on it, but is it a good idea to have those orphans in
cardano-api? - Adapt the existing instance to serialise script completely => roundtrip JSON tests now pass but the tests with hardcoded Tx encodings fail.
- Changing them to actually generate a
Txand do the encoding as part of the test rather than doing it manually.
- Remove the orphan instance and see what changes it entails there => Breaks CI and some code depends on it, but is it a good idea to have those orphans in
Problem is that we now have a dependenc on a private branch...
Current issues w/ Babbage code:
- (MB) Generators for Tx/UTxO
- (AB) JSON de/serialisation
Contract code failures from invalid Tx (generators again?)- Generator of valid tx sequences -> API change in ledger?
- cardano-node not spinning up (config?)
- (AB) Model failing ->
undefinedfield in accounts
- We basically have two issues:
- using IOSim s as monad when tying the know with DynFormula and
- how to use DynFormula to express properties about the model
- On the
IOSim s: quvic has been working in generalizing theStateModelActionMonadtype to take ans.. this should enable us in usingIOSim sand they will also try the change on the examples inplutus-apps - We discussed that we (IOG) will incorporate that change to the standalone
quickcheck-dynamicrepository once it also lands inplutus-apps. Also we will make sureplutus-appsis using the standalone repository after that. - On the
DynFormulathings: It seems like the dynamic logic is only used on the generation side of things right now and does not allow to express properties on the performing side, i.e. on observations on executing the model - While that would be interesting to explore / change there might be work around for now:
- Create an
Assertaction, which takes aVar aand a predicatea -> Boolto "line up" the assertion after the original Action, e.g. if there is aNewTxaction, which returns some kind ofObservationas ana, theAssertaction could be used to check on the actual value ofa
- Create an
Working on JSON roundtrip test failures in ch1bo/babbage-era branch, specifically on ClientInput and ServerOutput.
Where are the ToJSON/FromJSON instances we are using coming from? Seems like we use ledger's ones but I cannot find them in the ledger codebase
- We have custom
ToJSONinstances forToJSON (Ledger.Babbage.ValidatedTx era) - The error lies in the script serialisation, we have a
FromJSON (Ledger.Alonzo.Script era)instance but noToJSONwhich is probably defined in the ledger code? - Orphan
ToJSONinstance for ledgerScriptoutputs a hex-encoded bytestring of the hash of the script, not the script itself. I can define a customToJSONinstance for scripts that output the content of the script hex-encoded because there is aCBORinstance, but there is an overlapping instance error now because ofCardano.Api.Orphans. - It seems cardano-api changed its instance from encoding the script's body to encoding the script's hash because they have their own
ScriptInAnyLangwrapper? We never import directlyCardano.Api.Orphansso it must be imported indirectly, but how do I know the import path? - Actually what happened is that we used to have our own custom instance of
ToJSON Scriptbut it overlaps with this new orphan instance from the cardano-api...
Seems like MB figured out what the correct format is:
{
"script": {
"cborHex": "8303018282051927168200581c0d94e174732ef9aae73f395ab44507bfa983d65023c11a951f0c32e4",
"description": "",
"type": "SimpleScriptV2"
},
"scriptLanguage": "SimpleScriptLanguage SimpleScriptV2"
}
Problem is this format is the one from cardano-api, not from ledger.