Logbook 2021 H1
Fixing issues with my Prometheus PR: The transaction map used to record confirmation time keeps growing and keys are never deleted so should fix that.
Trying to refactor code to use \case instead of pattern-matching on arguments, not sure if it's really better though. It spares couple lines of declaration for the function itself and removes the need for wildcards on unused arguments which is better, but might obscure some inner patterns potentially leading to more refactoring? -> Lead to proposed Coding standard.
While running through the demo we noticed that the nodes stop abruptly because there is a ReqTx coming in while in Closed state.
It's possible that some txs are in flight while closing the head so deifnitely a case we should handle gracefully. Yet there's the question of why we see a tx being in Wait state for a while.
- Writing a unit test to assert we don't crash in this case -> really, we should just simply not crash when we get an
InvalidEvent=> write a property test throwing events at a node and making sure it does not throw
Got annoyed by mock-chain not being configurable: Running the demo interacts with the tests.
We observe that when peers are not connected, messages are "lost" but the client behaviour is weird and does not say much about it. We might want to:
- Pass the list of known parties to the
Heartbeatso it knows which parties should be up from the get go - Get past outputs from the server so we can see the Connected/Disconnected
- Discussion about the
Waits: We should really not reenqueue all the time, but wait till the state change and reprocess the event.
How do we distinguish between transactions that are invalid now and ones that could be valid at some later point => This drags us into the weed of interpreting ledger's errors or crawling past txs/utxos to check which ones have been consumed.
- Providing some non-authoritative feeback when
NewTxis sent is better: Check tx is valid and provide aClientEffectreporting that
Adding TxValid / TxInvalid ServerOutput to provide feedback to the client when it submits a new transaction.
Noticed that the nix-build and with that also the docker build is not succeeding with this error:
error: builder for '/nix/store/5qzggg7ljjhmxr1jfvbfm48333vs76mm-hydra-prelude-lib-hydra-prelude-1.0.0.drv' failed with exit code 1;
last 10 log lines:
> Setup: Encountered missing or private dependencies:
> QuickCheck -any,
> aeson -any,
> cardano-binary -any,
> generic-random -any,
> network -any,
> quickcheck-instances -any,
> random-shuffle -any,
> warp -any
>
For full logs, run 'nix log /nix/store/5qzggg7ljjhmxr1jfvbfm48333vs76mm-hydra-prelude-lib-hydra-prelude-1.0.0.drv'.
This indicates that cabal's build plan is missing those dependencies. As we are somewhat "pinning" the whole build plan using nix to avoid long Resolving dependencies..., cabal does not automatically create a new build plan here. So errors like these can be resoled by updating the materialized dependencies:
Temporarily remove plan-sha256 (and materialized?) from default.nix and run
$ nix-build -A hydra-node.project.plan-nix.passthru.calculateMaterializedSha | bash
trace: To make project.plan-nix for hydra-poc a fixed-output derivation but not materialized, set `plan-sha256` to the output of the 'calculateMaterializedSha' script in 'passthru'.
trace: To materialize project.plan-nix for hydra-poc entirely, pass a writable path as the `materialized` argument and run the 'updateMaterialized' script in 'passthru'.
1ph1yazxqrrbh0q46mdyzzdpdgsvv9rrzl6zl2nmmrmd903a0805
The provided 1ph1yazxqrrbh0q46mdyzzdpdgsvv9rrzl6zl2nmmrmd903a0805 can be set as new plan-sha256 and then
$ nix-build -A hydra-node.project.plan-nix.passthru.updateMaterialized | bash
these 3 derivations will be built:
/nix/store/zfm0h0lfm4j025lsgrvhqwf2lirpqnp1-hydra-poc-plan-to-nix-pkgs.drv
/nix/store/90dk71nv40sppysrq35sqxsxhyx6wy9x-generateMaterialized.drv
/nix/store/dg34q3d7v2djmlrgwigybmj93z8rw330-updateMaterialized.drv
building '/nix/store/zfm0h0lfm4j025lsgrvhqwf2lirpqnp1-hydra-poc-plan-to-nix-pkgs.drv'...
Using index-state 2021-06-02T00:00:00Z
Warning: The package list for 'hackage.haskell.org-at-2021-06-02T000000Z' is
18807 days old.
Run 'cabal update' to get the latest list of available packages.
Warning: Requested index-state 2021-06-02T00:00:00Z is newer than
'hackage.haskell.org-at-2021-06-02T000000Z'! Falling back to older state
(2021-06-01T22:42:25Z).
Resolving dependencies...
Wrote freeze file: /build/tmp.E719eYkdj0/cabal.project.freeze
building '/nix/store/90dk71nv40sppysrq35sqxsxhyx6wy9x-generateMaterialized.drv'...
building '/nix/store/dg34q3d7v2djmlrgwigybmj93z8rw330-updateMaterialized.drv'...
Should have updated the materialized files, ready to be checked in.
Merging JSON PR with some changes in EndToEndSpec to make things more readable
- We noticed that instances of ClientInput / ServerOutput for JSON are handwritten, which is annoying to maintain.
Trying to find a way to have those generated automatically. It's annoying right now because
ServerOutputconstructors have no field names so we would get something like{"tag": "ReadyToCommit", "content": [ ...]}which is annoying. - Tried to use
genericShrinkfor defining shrinker forServerOutputbut it does not work because of overlapping instances. - Need to move types to own module and only export the type and the constructors, not accessors, so that the latter get used by generic JSON deriving but not usable for partial fields access. -> Some legwork, do it later.
Working on improving notifications to end users:
- Renaming
sendResponse->sendOutputfor consistency with the changes in types for API stuff. - Writing a test for API Server to check we get some error message when input cannot be serialised
- Implementing
Committedoutput message for clients to be notified of all commits - Got an unexpected test failure in the init -> commit test because we were not waiting for
ReadyToCommit. Now fixing more failures on BehaviorSpec because we are adding more messages in the mix -> Tests are very strict in the ordering of messgaes read and checked, unlikeHeadLogicSpecorEndToEndSpec.BehaviorSpecis somehow becoming a liability as tests are somewhat hard to change and very brittle to changes in ordering of messages and adding new messages => it this unavoidable?
Working on querying current ledger's state: Client send a GetUTxO input message and receives in return an output listing all consumed UTxOs, and possibly the list of transactions.
- Writing a predicate to wait until some message is seen, with intermediate messages being simply discarded. This seems not to work out of the box though, as there is a timeout thrown. The problem was that no node was doing snapshotting, so there was no way I could observe
SnapshotConfirmed! - Adding the capability to query Committed Utxo before head is open
Having a stab at integrating prometheus stats collector in our demo stack and possibly adding more metrics collection:
- Distribution of confirmation time for each tx?
- Number of confirmed tx
Noticed that running MonitoringSpec tests which use a warp server to run monitoring service ends with:
Hydra.Logging.Monitoring
Prometheus Metrics
tests: Thread killed by timeout manager
provides count of confirmed transactions from traces
tests: Thread killed by timeout manager
provides histogram of txs confirmation time from traces
This is apparently a recent issue
-
Review Heartbeat PR
- Discussion about Peers vs. Parties -> It makes sense to use
Partybecause we interested in having
- Discussion about Peers vs. Parties -> It makes sense to use
-
Review JSON PR Have "generic" in all sense of the term instance of
Arbitrarypossibly using generic-random -> Write a coding convention about it:- It makes sense to have one
Arbitraryinstance for all "API" types - We can use that in tests when we don't care about the actual value and get more coverage
- We can refine it through
newtypewrappers when needed - Does not preclude the use of specialised generators when testing properties
- It makes sense to have one
-
Missing from demo:
- remove snapshotted txs from the seen txs
- query current ledger state
- provide feedback upon commit
- provide feedback upon invalid tx
- latch client effects to allow clients to "catch up"
-
Discussed demo story:
- Three parties because this is not lightning
- Websocket clients connected to each node
- Init, no parameters because it's a "single head per node" right now
- Commit some UTxO (only numbers for simple ledger) taking turns, last node will also CollectCom
- use numbers indicating "ownership" of party (11, 12 for party 1), but Simple ledger has no notion of ownership or allowed to spend
- Submit a couple of transactions and occasionally query utxo setin between
- a valid tx
- an invalid tx -> because already spent (using the same utxo)
- a "not yet valid" tx -> because utxo not yet existing (gets put on hold)
- a tx "filling the gap" and making the one before also valid -> both are snapshotted
- Close the head, all hydra nodes should
NotContest, contestation period should be around 10 seconds - Fanout get's posted and is seen in by all nodes
We want to send a ReqSn after each (or window) ReqTx for the coordinated protocol
- Renamed and simplified
confirmedTxs->seenTxsas a list of TXs - Renamed
confirmedUTxO->seenUTxO - Changing
TxConfirmednotification toTxSeen=> There are notconfirmedTxsin theClosedoutput anymore, only UTxO => There are no hanging transactions anymore because transactions become really valid only after a snapshot is issued - Rip out
AckTxfrom the protocol - Check non leader does not send
ReqSn
There is a problem with leader "election" in the ReqTx: By default, we use number 1 but really we want to use the index of a party in a list of parties.
This list should not contain duplicate and the ordering should be the same for all nodes. And independent of the actual implementation of the ordering, like an Ord instance in Haskell. => this should be specified somewhere in our API? or the contracts actually...
- Replace
allPartieswithotherPartiesso that we make theEnvironmentmore fail proof - Slightly struggling to make the
isLeaderfunction right, sticking to hardcoded first element of the list of parties in the current head -
initEnvironmenthad snapshot strategy hardcoded toNoSnapshot=> predicate for leader fails. Also had an off-by-one error in determining the leader, using index 1 instead of 0
What happens when the leader concurrently emits 2 different snapshots with different content? This can happen if the leader receives 2 different ReqTx in "a row"?
In hydra-sim this is handled by having a NewSn message coming from a daemon that triggers the snapshotting: This message just takes all "confirmed" transactions accrued in the leader's state and create a new snapshot out of it, hence ReqTx can be processed concurrently as long as they cleanly apply to the current pending UTxO. We don't have such a mechanism in our current hydra-node implementation so the ReqSn emission is triggered by the ReqTx handling which leads to potentially conflicting situation. Possible solutions are:
- When leader emitted a
ReqSn, change the state andWaitif there are moreReqTxcoming in until the snapshot has been processed by all nodes? - Implement snapshotting thread that wraps the
HeadLogicinside the node and injectsNewSnmessages at the right time?
- From the ensemble session we identified, that we would be fine to just accrue
seenTxswhile the current snapshot is getting signed and a later snapshot would include them. - We also identified where changes are necessary in the protocol, but exercising this in the
HeadLogicSpecis unconfortable as this is ideally expressed in assertions on the whole node's behavior on processing multiple events - So I set off to revive the
Hydra.NodeSpec, which ought to be the right level of detail to express such scenarios - For example:
- Test that the node processes as the snapshot leader
[ReqTx, ReqTx, ReqTx]into[ReqSn, ReqSn, ReqSn]with a single tx each, and - (keeping the state) processes then
[ReqSn, ReqTx, ReqTx]into[AckSn]plus some internal book keeping onseenTxs
- Test that the node processes as the snapshot leader
- Trying to reduce
Resolving dependencies...time. This is slowing us down as it can take ages recently. - Likely this is coming from
cabalas it needs to solve all the dependencies and constraints. As we have added some more dependencies recently this time got longer (> 10mins for some of us) - Idea: side-step dependency solving by keeping the
plan.json; this is what.freezefiles are doing? Usinghaskell.nix, this is what materialization is doing - Followed the steps in the
haskell.nixmanual and it seems to be faster now for me.. but also onmaster, so maybe the fact, that a plan is cached is also cached in my/nix/storenow?
Troubleshooting NetworkSpec with Marcin, it appears the problem comes from the ipRetryDelay which is hardcoded to 10s in the Worker.hs code in Ouroboros. Increasing the test's timeout to 30s makes it pass as the worker thread now has the time to retry connecting. Here is the relevant part of the code:
-- We always wait at least 'ipRetryDelay' seconds between calls to
-- 'getTargets', and before trying to restart the subscriptions we also
-- wait 1 second so that if multiple subscription targets fail around the
-- same time we will try to restart with a valency
-- higher than 1.
Note that Subscriptions will be replaced by https://input-output-hk.github.io/ouroboros-network/ouroboros-network/Ouroboros-Network-PeerSelection-Governor.html so it does not make sense to try to make this delay configurable.
Working together on signing and validating messages. We now correctly pass the keys to the nodes at startup and when we initialise the head.
We won't care about AckTx because in the coordinated protocol, we don't sign individual transactions, only the snapshots.
Writing a unit test in the head to ensure we don't validate a snapshot if we get a wrong signature:
- Modify
AckSnto pass aSigned Snapshotwhich will contain the signature for the given data - Do we put the data in the signature? probably not usually
Why is there not a Generic instance for FromCBOR/ToCBOR?
There is a Typeable a constraint on FromCBOR for the sake of providing better error reporting. Typeable is special: https://ghc.gitlab.haskell.org/ghc/doc/users_guide/exts/deriving_extra.html#deriving-typeable-instances
Discussion around how to define "objects" we need for our test, esp. if we sould explicitly have a valid signature for the test which checks leadershipr -> this begs for having test builder to help us define "interesting" values
We need different tests for the verification of signature of snapshot:
- snapshot signed is not the right one but is signed by right party
- snapshot is the right one but signed by wrong party (unknown one or invalid key)
- check that when we received a valid signature from an unknown party, we don't use it as AckSn
Going to continue pairing beginning of afternoon to get to a green state, then working on our own:
- JSON interface
- Saner Heartbeat
- Merging NetworkSpec stuff
- Walk-through of recent
ExternalPABwork, made it finally pass tests and merge it tomasteras an "experiment covered by tests" - Discussed issues with
ouroboros-networking, re-/connection anderrorPolicies - Reflected on current work backlog, prototype scope (on the miro board), as well as what we think would be a meaningful scope for the next and following quarter (in Confluence)
- Started to write down instructions on how to use the
hydra-nodein a demo scenario here: https://github.com/input-output-hk/hydra-poc/tree/demo - Heartbeating is somewhat in the way right now
- The
--node-idis only used for the logs right now, maybe use change the command line options to just use 4000 +node-idwhen--api-portnot set explicitly etc?
Continued work on the "external" PAB chain client
- All kinds of dependency errors led me to copying the
cabal.projectfrom the latestplutus-starterverbatim (below our ownpackages) - This then also required an
allow-newerbecause ofattoparsecas dependency ofsnap-serveras dependency ofekgas dependency ofiohk-monitoring - Hit a wall as everything from the branch compiled but
masterwas still broken -> paired with AB to fix master - After merging
masterback in, ledger tests were still failing - Weirdly the (more recent?)
cardano-ledger-specsversion viaplutusis now havingapplyTxsTransitionagain as exported function. So I went on to change (back) theHydra.Ledger.MaryTestimplementation - One of
hydra-plutustests was failing- Investigated closer with AB and we identified that
assertFailedTransactionwas not providing our predicate with any failed transactions (but we expect one) - Asked in the #plutus channel, and the reason is, that the wallet now does validate txs before submitting them and they would not be part of
failedTransactionsanymore - However there is no alternative to assert this (right now - they are working on it), so I marked the tests as
expectFail
- Investigated closer with AB and we identified that
Still having troubles with master not building and tests failing: 0MQ based tests for mock chain are hanging
-
Found "faulty" commit to be the one replacing the
NaturalinPartywith an actual Verification key which is not unexpected. -
Replacing
arbitraryNaturalby agenPartywhich contains anundefinedvalue so that I can track what happens and where this is evalauted -
Looks like it's hanging in the
readsfunctioninstance Read Party where readsPrec = error "TODO: use json or cbor instead"is what we have, going to replace with a dummy value just for the sake of checking it's the issue
We are using
concurrently_which runs until all threads are finished, replacing withrace_to run until one of the threads finishes so that we catch exceptions earlier. I suspect one of the thread crashes due to the faulty read and the other ones are hanging.
Pairing with SN, we managed to get ZeroMQ test to stop hanging by implementing proper Read instance for Party and orphan for MockDSIGN
Still having test failures in options and serialisation
Working on PR https://github.com/input-output-hk/hydra-poc/pull/25
- Network tests are still flaky, esp. the Ouroboros ones which fail every so often in an odd way: the timeout that expires is the inner one waiting for the MVar and not the outer one
- Depending on hydra-node in local-cluster seems kinda wrong so trying to sever that link
Trying to remove some warnings in cabal build about incorrect versions, aparently coming from https://github.com/haskell/cabal/issues/5119 which is not fixed (last comment is from 11 days ago and is about looking for a good soul to make a PR...). Going to leave as it is now, unfortunately.
Trying to fix flackiness of network tests, possibly using traces as a synchronisation mechanism rather than waiting:
- Running the tests repeatedly does not reproduce the errors seen. The traces dumped are not very informative on what's going wrong unfortunately...
- Running the tests with
parallelbreaks, probably because the Ouroboros tests reuse the same ports? - Using local Unix sockets with unique names would make the tests more reliable but then it would not test the same thing.
Refactoring local-cluster code to remove Logging --> shaving yak moving Ports module which could also be useful in hydra-node. This lead to this PR to unify/simplify/clarify code in local-cluster project.
- Use random ports allocator in
NetworkSpectests to ensure tests use own ports - Ouroboros tests are now consistently failing when allocating random ports, seems like tests are either very fast, or timeout, which means there is a race condition somewhere.
- Oddly enough, test in CI fails on the inner wait for taking recevied value from MVar
- Worked together on adding keys for identifying parties
Quick discussion about https://github.com/input-output-hk/hydra-poc/pull/23 on how to make tests better, solution to test's synchronization problem is to do the same thing as in EndToEnd test:
- If client's connection fails, retry until some timeout fires
- Sync the sending of message with client's being connected
Then we did not actually program but went through MPT principles to understand what their use entails, and get some intuitions on how they work
Going through construction of MPT: https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3074457360345521692&cot=14, with some references articles in mind:
- https://medium.com/@chiqing/merkle-patricia-trie-explained-ae3ac6a7e123
- https://blog.ethereum.org/2015/11/15/merkling-in-ethereum/
- https://easythereentropy.wordpress.com/2014/06/04/understanding-the-ethereum-trie/
- https://eth.wiki/en/fundamentals/patricia-tree
Some conclusions:
- We need to bound the size of UTxO in the snapshot and the number of hanging transactions to make it sure honest nodes can post a
CloseorContestas a single transaction - The Fanout is not bounded in size because it can be made into several transactions, but the close is because it needs to be atomic otherwise adversaries could stall the head and prevent closing or contestation by exhausting the contestation period (something like slowloris?)
- Nodes should track the size of snapshots and hanging txs in the head state and refuse to sign more txs when reaching a limit
- MPTs are useful for 2 aspects: having a O(log(n)) bound on the siez of proof for each txout to add/remove, enabling splitting of fanout
- We need to bound the number of UTxO "in flight", which is what the concurrency level is about, but we need not to track the TX themselves as what counts in size is number of txout add/removed
- what about size of contracts? if adding MPT handling to contracts increase the size too much, this will be annoying
- size of types, even when church-encoded
Syncing for solo work:
- AB: Coordinated protocol, tying loose ends on PRs
- MB: docker
- SN: Key material configuration
Considering adding graphmod generated diagram of modules in the architecture documents.
Graph can be generated with:
find . -name \*.hs | grep -v dist-newstyle | graphmod -isrc/ -itest | tred | dot -Tpdf -o deps.pdf
Which could be run as part of the build and added to the docs/ directory
Removes MockTx everywhere in favor of SimpleTx, including in "documentation". This highlights once again that Read/Show are not ideal serialisation formats.
Improving WS ServerSpec tests, it's annoying that runServer cannot be given a Socket but always requires a Port.
-
Warp provides
openFreePortfunction to allocate a randomSocketand aPort, and it happens we have warp package in scope so let's use that. - Using a "Semaphore" to synchronize clients and responses sending but still having a race condition as the clients can start before the server so are unable to connect.
-
runClient rethrows an exception thrown by
connectto the socket, and concurrently_ rethrows it too, but withAsync provides anAsyncwhich "holds" the return value, or exception, thrown by inner thread. - When running the test client, I need to catch exceptions and retry with a timeout limit
- Had a quick look into the "Configure nodes with key pairs" topic and it is actually quite undefined:
- Do we really want to parameterize the node with other parties pubkeys or rather pass them with the other
HeadParametersfrom the client using theInitcommand? - Where would the key material come from? i.e. would we use the
cardano-cli, another cardano tool or something we create? - I'm a bit overwhelmed by the wealth of "crypto modules" providing key handling in the already existing cardano ecosystem, here some notes:
-
cardano-base/cardano-crypto-class/src/Cardano/Crypto/DSIGN/Class.hsalong with it'sEd25519seems to be the very basic de-/serialization of ed25519 keys and signing/verifying them - The cardano-cli seems to use
cardano-node/cardano-cli/src/Cardano/CLI/Shelley/Key.hsfor deserializing keys -
readVerificationKeyOrFileindicates that verification keys are stored in an "TextEnvelope" as Bech32 encoded values, also that there are multiplekeyroles -
cardano-node/cardano-api/src/Cardano/Api/KeysShelley.hscontains several key types (roles) - how different are they really? - Normal and extended keys are seemingly distinguished:
- normal are basically tagged
Shelley.VKeyfromcardano-ledger-specs - extended keys are newtype wrapped
Crypto.HD.XPubfromcardano-crypto
- normal are basically tagged
- The
Shelley.VKeyfrom above is defined incardano-ledger-specs/shelley/chain-and-ledger/executable-spec/src/Shelley/Spec/Ledger/Keys.hsand is a newtype-wrappedVerKeyDSIGNfromcardano-crypto-class, parameterized withStandardCryptodefined inouroboros-network/ouroboros-consensus-shelley/src/Ouroboros/Consensus/Shelley/Protocol/Crypto.hs.. which is selectingEd25519viatype DSIGN StandardCrypto = Ed25519DSIGN
-
- How deep into this stack 👆 do we want dive / how coupled to these packages do we want to be?
- Merkle Patricia Trees (MPT) are supposed to come as a potential solution to the problem w.r.t to the size and feasibility of close / contest / fanout transactions.
- Verifying the membership of an element to the tree requires the MPT root hash, the element itself, and all the nodes on the path from the element to the root. Note that the path is typically rather short, especially on "small" (e.g. < 1000) UTxO sets where the chances of finding common prefixes longer than 3 digits is already quite small.
- An MPT are bigger than a simple key:value map since they include hashes of each nodes. Although on the plus side, since they are trees, MPT can be split into subtrees.
- One thing is still a little bit unclear to me w.r.t the "security proof" coming with the verification of a tree. Unlike Merkle trees, which requires all the OTHER nodes' hashes to perform a verification, (that is, requires the missing information needed to re-hash the structure and compare it with the root), MPT require the nodes on the path and prove membership by simply walking the path from the root down to the element. How does one prove that the given hashes do indeed correspond to what they claim? In the case of Ethereum (which also uses MPT for storing various piece of information, like the balances of all accounts), a node maintain the entire MPT, so arguably, if someone provides a node with a path and ask for verification, then necessarily if the node finds a path down to the element then the proof was valid (provided that the node itself only maintain a valid MPT, but that's a given). In the case of Hydra and on-chain validator however, the MPT is meant to be provided by the user in the Close / Contest or Fanout transactions. There's therefore no guarantee that the tree will actually be valid and it must be verified, which requires the entire tree to re-compute the chain of hashes (or more exactly, like Merkle trees, it requires all the other nodes, but since each layer can have 16 branches... all the other nodes is almost all the tree...).
- Quick introduction to impact mapping technique by Arnaud
- We exercise a quick example on the miro board
- Starting discussion about our goal - start with "why"
- It should be SMART (the acronym)?
- Our vision is "Hydra is supporting growth and adoption of the cardano ecosystem"
- But that is not a goal, per se; it is not measurable
- There is also OKRs (in how to specify goals)
- Is our goal to reach X number of transactions done through hydra, or rather X percent of all Cardano transactions being done on hydra? i.e. should it be relative?
- We can imagine many ways to contribute to many different goals, but which one is most valuable to us, to the business, to the world?
- Is value locked or number of transactions a useful metric for adoption?
- What are people using Cardano right now?
- NFT sales since mary
- Oracle providers
- Metadata for tracking and recording things
- Are fees a problem right now for Cardano? i.e. is it a good goal to reduce them using Hydra (in some applications)
- We are building a solution for the community; in the spirit of open-source development
- We are not building a turn-key-solution for individual customers
- However, we could build one showcase-product using a more general platform
- Creating a reference implementation is all good & fine, also the theoretical possibility of other implementations interacting with our solution; but we should not rely on it for our success (seeing Cardano)
- We part by thinking about "the goal" and meet again next week
Implementing Wait for ReqTx
- We don't need to add more information to
Waitas we know the event it carries from the event processor - But we would need it for tracing/infomration/tracking purpose higher up in the stack?
Writing a BehaviorSpec to check we are indeed processing the Wait:
- Although there is a
panicin the event processing logic, it's not forced so we don't see it fails there - ⇒
waitForResponsetransaction confirmed - We see test failing on a timeout, still not panicking through -> Why?
- The test fails before reaching
Waitfailure -> removing verification inNewTxfor the moment in order to ensure we actuallypanic - Do we need
Waitor can we just return aDelayeffect? Seems like even though they are equivalent, they are actually 2 different concepts, we want theoutcometo express the fact the state in unchanged, and unchangeable, while waiting
What's next?
- there's a
panicin ackTx - there's another one in
ackSn-> need to check all transactions apply - There's no way we can currently express the paper's constraints for
AckSnbecause messages are always ordered and all nodes are supposedly honest - in the paper we receive a list of hashes for transactions instead of transactions again -> optimisation for later
Back to reqSn:
- we can only right now write unit tests and not higher-level ones, because we don't have a way to construct a ahead-of-time snapshot. possible solutions: * write an adversarial node * increase concurrency level of event processing to produce out-of-order (or lagging code) * remove the limitation on network messages ordering so that we can simulate reordering of messages?
- lifting the condition on snapshot number to a guard at the case level expressed as
requirein the paper - adding more unit tests with ill-constructed snapshots, distinguishing
Waitresults from returnError
Implementing leader check in ReqSn, got surprised by the behaviour of REqSn and isLeader:
- having declarations far from their use in tests is annoying
- snapshot leader is still hard-coded to one
Renaming SnapshotAfter to SnapshotAfterEachTx
Signing and verifying is the next interesting to do as this will lead us to replace the fake Party type with some actually interesting data for peers in the network, eg. pub/private keys, signing, multisigning, hashes...
Status update on Multi-Signature work by @Inigo and how to proceed with "verification over a non prime order group"
- MuSig2 is non defined about non-prime curves
- Ristretto: encode non-prime group specially to "protect security?"
- Goal is still that the verifier does not need to know about this
- Where to go frome here?
- Sandro, Peter and Matthias would be able to work through current findings, but need to find time for it
- How urgent? Not needed right now.. but in the next weeks/months (quarter) would be good
- There is a rust implementation of Ristretto-Ed25519 used by Jormungandr?
- https://github.com/input-output-hk/chain-libs/blob/efe489d1bafa34ab763a4bfdddb6057d0080033a/chain-vote/src/gang/ristretto255.rs
- Uses ristretto for all cryptographic operations, maybe not fully transparent for verifier.
- Inigo will have a look whether this is similar.
- In general we think this should be possible (without changing the verifier), but we noted that we would need to know if this plan does not work out rather earlier than later
We want to speak about the On-Chain-Verification (OCV) algorithms:
- Q: OCV close is confusing, does "apply a transaction to snapshot" needs to be really done on-chain? it is theoretically possible, but practically too expensive in terms of space and time
- Q: Leaving (hanging) transactions aside, would closing / contesting a head mean that the whole UTxO set need to be posted on chain?
- Verifying signatures is possibly expensive, can't be offloaded to the ledger as "parts" of the tx
- When closing a head, you do not need to provide the full tx on close -> Merkle trees allow to post only hashed information
- yet? maybe avenue of improvement
- For distributing outputs (fanout), splitting it in multiple txs ought to be used
- MPT are pretty essential to implement the protocol
- We would only provide proofs of transactions being applicable to a UTXO set
- What happens if all participants lose the pre-images (not enough info on chain)?
- The security requires that at least one participant behaves well
- Losing memory of everything is not well-behaved
- Blockchains are not databases!
- Simulations showed that snapshotting is not affecting performance, so number of hanging transactions could be bounded
- Snapshotting after every transaction would limit number of txs per snapshot naturally
- Does not require much data being submitted or time expensive things (e.g. tx validation)
- Whats the point of signing transactions in the first place?
- Helps in performance because of concurrency
- Especially when txs do not depend on each other
- How expensive is signature validation in plutus?
- Discussions around, not sure, rough guesses at first, but then:
- 42 microseconds on Duncan's desktop
- How would be find out whether something fits in space/time with plutus
- Ballpark: micro or milliseconds is ok, more is not
- In the plutus repository there is a benchmark/tests and we could compare it with that (also with marlowe scripts)
- Re-assure: When broadcasting Acks we don't need Confs, right? Yes
- Pushed some minor "Quality-of-life" changes to
master:- Use a
TQueueinstead ofTMVaras a channel to send responses to clients in test, because the latter makes the communication synchronous which blocks the node if a client does not read sent responses - Add Node's id to logs because logs in
BehaviorSpeccan come from different nodes - Remove one
panicfromupdate, return aLogicErrorand throw returned exception at the level ofeventHandlerbecause otherwise we fail to properly capture the log and don't know what sequence of action lead to the error
- Use a
- Implemented a
SimpleTxtransaction type that mimics UTxOs and pushed a PR
Going to modify HeadLogic to actually commit and collect UTxOs.
- Changed Commit and CommitTx to take UTxOs. To minimize change I tried to make
MockTxaNumbut this was really silly so I just bit the bullet and changed all occurences with a list of numbers to aUTxO MockTxwhich is jsut a[MockTx] - Tests are now inconsistent because we return empty snapshots and do not take into account the committed UTxOs. I modified
BehaviorSpecto reflect how close and finalise txs should look like and now they all fail of course, so I will need to fix the actual code. - Now facing the issue that UTxO tx is not a Monoid, which is the case only because UTxOs in Mary is not a monoid: https://input-output-rnd.slack.com/archives/CCRB7BU8Y/p1623748685431600 Looking at UTxO and TxIn definition, it seems defining a Monoid instance would be straightforward... I define an orphan one just for the sake of moving forward.
- We can now commit and collect properly UTxOs and all unit tests are passing, fixing ete test
- ETE test is failing after modification with a cryptic error: Seems like it fails to detect the
HeadIsOpenmessage with correct values, now digging into traces- Found the issue: The
Commitcommand requires a UTxO whihc in our case is a list of txs. This reveals the limits of using Read/Show instance for communicating with the client, as it makes the messages dependent on spaces and textual representation which is hard to parse https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3074457360210681480&cot=14
- Found the issue: The
- submitted PR #20
Started work on a more thorough property test that will hopefully exercise more logic, using SimpleTx:
-
Property test is hanging mysteriously, probably because the run keeps failing, trying to make sense of it by writing a single test with a single generated list of txs and initial UTxO
-
The list was geneated in reverse order and reversed when applied, now generating in the correct order which implies modifying the shrinker. I changed the generator for sequences to take a UTxO but did not change the maximum index. This works fine when starting with
memptybut of course not when starting with something... -
Implemented waiting for
HeadIsFinalisedmessage but I still get no Utxo, so most probably I am not waiting enough when injecting new transactions. Tried to add a wait forSnapshotConfirmedbut was not conclusive either ⇒ Going to capture the traces of each node and dump them in case of errors, captured through theIOSimtracing capabilities. -
Capturing traces in IOSim, but now some other tests are failing, namely the ones about capturing logs which totally makes sense.
-
Wrote a tracer for
IOSimbut I fail to see the logs usingtraceMwhich usesDynamicbased tracing. Well, the problem is "obvious": I am trying to get dynamicHydraLoglogs but I only haveNodelogs... -
Still having failing tests when trying to apply several transactions, but I now have a failure:
FailureException (HUnitFailure (Just (SrcLoc {srcLocPackage = "main", srcLocModule = "Hydra.BehaviorSpec", srcLocFile = "hydra-node/test/Hydra/BehaviorSpec.hs", srcLocStartLine = 229, srcLocStartCol = 31, srcLocEndLine = 229, srcLocEndCol = 110})) (ExpectedButGot Nothing "SnapshotConfirmed 7" "TxInvalid (SimpleTx {txId = 2, txInputs = fromList [5,6,9], txOutputs = fromList [10,11]})"))What happens is that I try to apply transactions to quickly when we get the
NewTxcommand, whereas it should actuallyWaitfor it to be applicable. I guess this points to the need of handlingWaitoutcome... -
Handling
Waitis easy enough as we already have aDelayeffect. The test now fails beacuse thewaitForResponsechecks the next response whereas we want to wait for some response. -
The test fails with a
HUnitFailurebeing thrown which is annoying because normally I would expect the failure to be caught by therunSimTraceso I can react on it later on. The problem is that theselectTraceEventsfunction actually throws aFailureExceptionwhen it encounters an exception in the event trace, which is annoying, so I need a custom selector. -
Wrote another function to actually retrieve the logs from the
EventLogbut it's choking on the amount of data and representing the logs. Trimming the number of transactions finally gives me the logs, which are somewhat huge:No Utxo computed, trace: [ProcessingEvent (ClientEvent (Init [1,2])) , ProcessingEffect (OnChainEffect (InitTx (fromList [ParticipationToken {totalTokens = 2, thisToken = 1},ParticipationToken {totalTokens = 2, thisToken = 2}]))) , ProcessingEvent (OnChainEvent (InitTx (fromList [ParticipationToken {totalTokens = 2, thisToken = 1},ParticipationToken {totalTokens = 2, thisToken = 2}]))) , ProcessedEffect (OnChainEffect (InitTx (fromList [ParticipationToken {totalTokens = 2, thisToken = 1},ParticipationToken {totalTokens = 2, thisToken = 2}]))) , ProcessedEvent (ClientEvent (Init [1,2])) .... , ProcessingEvent (NetworkEvent (ReqTx (SimpleTx {txId = 2, txInputs = fromList [3,6,7,8,11,12], txOutputs = fromList [13,14,15,16,17,18]}))) , ProcessingEffect (NetworkEffect (AckTx 1 (SimpleTx {txId = 2, txInputs = fromList [3,6,7,8,11,12], txOutputs = fromList [13,14,15,16,17,18]}))) , ProcessedEffect (NetworkEffect (AckTx 1 (SimpleTx {txId = 2, txInputs = fromList [3,6,7,8,11,12], txOutputs = fromList [13,14,15,16,17,18]}))) , ProcessedEvent (NetworkEvent (ReqTx (SimpleTx {txId = 2, txInputs = fromList [3,6,7,8,11,12], txOutputs = fromList [13,14,15,16,17,18]}))) , ProcessingEvent (NetworkEvent (AckTx 1 (SimpleTx {txId = 2, txInputs = fromList [3,6,7,8,11,12], txOutputs = fromList [13,14,15,16,17,18]}))) , ProcessedEvent (NetworkEvent (AckTx 1 (SimpleTx {txId = 2, txInputs = fromList [3,6,7,8,11,12], txOutputs = fromList [13,14,15,16,17,18]})))] -
While running a longer test to apply transactions, I got the following error:
FatalError {fatalErrorMessage = "UNHANDLED EVENT: on 1 of event NetworkEvent (AckSn (Snapshot {number = 1, utxo = fromList [1,3,4,5,6,7,8,9], confirmed = [SimpleTx {txId = 1, txInputs = fromList [2], txOutputs = fromList [3,4,5,6,7,8,9]}]})) in state ClosedState (fromList [1,3,4,5,6,7,8,9])"}Which is quite unexpected, indeed.
Reviewing what needs to be done on HeadLogic
- InitTx parameters should probably be PubKeyHash, participation tokens are not really used in the protocol itself, they are part of the OCV
- Is the result of observing init tx different than posting it -> not at this stage
- commits are not ok -> we should replace that with UTxOs
- collectCom is faked -> empty UTxO and does not care with committed values -> should be a parameter of CollectComTx that's observed
- do the chainclient knows about tx? -> it needs to in order to create/consumes UTxOs at least in the
collectComfanouttransactions
discussion about how to use the mainchain as an event sourced DB?
-
Is the chain the ultimate source of truth? Is our property (that all chain events should be valid in all states) about chain events true?
- committx are not only layer 2, they are observable on chain and not only in the head
- the committx event does not change the state, but for the last Commit which triggers the
CollectComTx - a node could bootstrap its state from the chain by observing the events there
-
Pb: How to fit a list of tx inside a tx?
- you might not care because you are not going to post a tx which contains those, because nodes contain some state that allow them to check
- we really want to check that with the research team: How does the closetx/contest really should work on-chain?
- if the closetx is not posting the full data, there is no way observing it from the chain one can reconstruct it
-
What would we be seeing on the chain? it should be ok to post only proofs
- verify the OCV code for Head
-
what's the safety guarantees after all?
Problems w/ current head protocol implementation:
- size of txs, putting list of txs and snapshots as part of Close and Context will probably overcome the limits of Tx size in cardano
- OCV requires validation transactions and this seems very hard to do in the blockchain, or at least computationally intensive
- size of UTxOs in the FanOut tranasction might be very large
A lot of complexity comes from the fact txs can be confirmed outside of snapshots and we need to account for those supernumerary txs on top of snapshots, what if we only cared about snapshots?
- Continue work on getting a
hydra-pabrunning- The fact that all our
Contracts are parameterized byHeadParametersis a bit annoying, going to hardcode it like in theContractTestfor now - Using it in a PAB seems to require
ToSchemainstances,TxOuthas no such instances -> orphan instances - Compiles now and available endpoints can be queried using HTTP:
curl localhost:8080/api/new/contract/definitions | jq '.[].csrSchemas[].endpointDescription.getEndpointDescription' - Added code which activates all (currently 2) wallets and writes
Wxxx.cidfiles similar as Lars has done it in the plutus pioneers examples - The de-/serialization seems to silently fail
- e.g.
initendpoint does have a()param -
curl -X POST http://localhost:8080/api/new/contract/instance/$(cat W1.cid)/endpoint/init -H 'content-type: application/json' --data '{}'does not work, but returns200 OKand[]as body -
curl -X POST http://localhost:8080/api/new/contract/instance/$(cat W1.cid)/endpoint/init -H 'content-type: application/json' --data '[]'does work and simulate submitting the init tx - Also, after failing like above, the next invocation will block!?
- Multiple correct invocations of
initdo work
- e.g.
- The fact that all our
- Messed around with getting ouroboros-network and the ledger things work again (..because of bumped dependencies..because of plutus)
- Created a first
ExternalPABwhich just usesreqto invoke the "init" endpoint
Read the artcile about Life and death of plasma
- gives a good overview of Ethereum scalability solutions
- starts explaining former Plasma ideas and more recent zk- and optimistic rollups
- more details about rollups
- the zero-knowledge (zk) stuff is still a bit strange, but is maybe just more fancy crypto in place to do the same as Hydra's multi-signatures incl. plutus validation?
- optimistic rollups remind me of collateralization / punishment mechanisms as they are discussed for the something like the Hydra tail
Looking into how to interact with / embed the PAB as ChainClient:
- Starting with "using" the PAB the normal way, i.e. launch it + the playground from the plutus repository?
- This PAB Architecture document mentions that "Additional configurations can be created in Haskell using the plutus-pab library."
- The plutus-starter repository seems to be a good starting point to running the PAB
- Using vscode with it's devcontainer support (for now)
-
pab/Main.hsseems to a stand-alone PAB with theGameContract"pre-loaded" - contract instances can be "activated" and endpoints can be invoked using HTTP, while websockets are available for observing state changes
- The stand-alone PAB runs a simulation by
Simulator.runSimulationWithwithmkSimulatorHandlers, which essentially does simulate multiple wallets / contract instances like theEmulatorTrace - Using this we should be able to define a chain client, which talks to such a stand-alone (simulated) PAB instance
- Is there also a way to run
PABActionin a non-simulated way against a mocked wallet / cardano-node?- Besides the Simulator, there is only
PAB.App.runAppwhich callsrunPAB, this time withappEffectHandlers - This seems to be the "proper" handle for interfacing with a wallet and cardano-node, notably:
- Starts
Client.runTxSender,Client.runChainSync'andBlockchainEnv.startNodeClient, seemingly connecting to a cardano-node given aMockServerConfig - Keeps contract state optionally in an
SqliteBackend - Calls a "contract exe" using
handleContractEffectContractExe-> this is not what we want, right? - Interacts with a real wallet using
handleWalletClient
- Starts
- The
App.Cliseems to be used for various things (refer toConfigCommandtype) - This definitely hints towards the possibility of using PAB as-a-library for realizing a chain client interface, but seems to be quite involved now and not ready yet.
- Besides the Simulator, there is only
- Set off to draft a
Hydra.Chain.ExternalPABwhich uses HTTP requests to talk to a PAB running our contract offchain code- The scenario is very similar to lectures 6 and 10 of the plutus pioneer program
- Created a
hydra-pabexecutable inhydra-plutusrepository - Required to change many
source-repository-packageandindex-state... this was a PITA
- Change fanout logic to use the
FanoutTxinstead of theClosedState - Discussion that
FanoutTxshould be always able to be handled - Define a more general property that
OnChainTxcan be handled in all states- Uncovered another short cut we took at the
CloseTx - Note to ourselves: We should revisit the "contestation phase"...
- What would we do when we see a
CommitTxwhen we are not inCollectingState?
- Uncovered another short cut we took at the
-
Fiddling w/ CI: Looking at way to run github actions locally, using https://github.com/nektos/act
Seems like https://github.com/cachix/install-nix-action does not work properly because it is running in a docker image and requires systemd to provide multi-user nix access. Adding
install_options: '--no-daemon'does not help, the option gets superseded by other options from the installer. Following suggestions from the README, trying to use a different ubuntu image but that's a desparate move anyhow, because a docker image will probably never provide systemd -> 💣 -
Fixing cache problem in GitHub actions: https://github.com/input-output-hk/hydra-poc/runs/2795848475?check_suite_focus=true#step:6:1377 shows that we are rebuilding all dependencies, all the time. however, when I run locally a build within
nix-shellthose packages are properly cached in `~/.cabal/store so they should be cached in the CI build tooSeems like the cache is actually not created: https://github.com/input-output-hk/hydra-poc/runs/2795848475?check_suite_focus=true#step:10:2 The cache key is computed thus:
key: ${{ runner.os }}-${{ hashFiles('cabal.project.freeze') }}but the
cabal.project.freezefile was removed in a previous commit. Adding it back should give us back better caching behavior.However: cabal.project.freeze is generated with flags which then conflicts with potential
cabal.project.localflags, and it's not really needed as long as theindex-stateis pinned down -> usecabal.projectas the key to the caching index -
Red Bin:
Setup a Red bin for defects in the software development process: https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3074457360036232067&cot=14, and added it as part of coding Standards
-
Looking at how to improve tests results report in the CI:
- There is a junit-report-action which provides checks fro PR reporting
- another one is test-reporter
- and yet another publish-unit-test-results
This means we need to publish the tests execution result in JUnit XML format:
- hspec-junit-formatter provides a way to do that but it requires some configuration in the Main file which kind of breaks hspec-discover mechanism in a way? I think it's possible to use hspec-discover with a non empty file though...
-
Wrapping up work on publishing Haddock documentation in CI.
Instead of having multiple steps with inline bash stuff in the CI job, I would rather have a
build-ci.shscript that's invoked from the step and contains everythingWe now have a website published at URL https://input-output-hk.github.io/hydra-poc 🍾
-
Some discussions about UTxO vs Ledger state in the context of the Head. The entire paper really only considers UTxO and only makes it possible to snapshot and fanout UTxOs. This means that other typical information in the ledger state (e.g. stake keys, pools, protocol params) are not representable inside the head; Should the head refuse to validate transactions which carry such additional information / certificates?
-
Discussion about closing / fanout and inception problem. Asking ledger team about possibilities of how to validate such transactions without actually providing the transactions. We need some clarity on this and will bring this up in the next Hydra engineering meeting.
Ensembling on snapshotting code:
- We need a snapshot number and can assume strategy is always
SnapshotAfter 1, ie. we don't yet handle the number of txs to snapshot - We can handle leadership by having a single node with a
SnapshotAfterstrategy - Failing test is easy: invert the UTxo set and list of Txs in the Closing message
- We should use tags instead of
Textfor CBOR serialisation
Meta: Can we really TDDrive development of a protocol such as the Hydra Head? Working on the snapshot part makes it clear that there are a lot of details to get right, and a small step inside-out TDD approach might not fit so well: We lose the "big picture" of the protocol
Representation of UTXO in Mock TX is a bit cumbersome because it's the same as a list of TXs
- TODO: Use a
newtypewrapper to disambiguate?
Improving network heartbeat [PR])https://github.com/input-output-hk/hydra-poc/pull/15) following code review.
Reviewing test refactoring PR together
- need to introduce io-sim-classes lifted versions for various hspec combinators
- first step towards a
Test.Prelude - still not strict shutdown, there are dangling threads which are not properlu closed/bracketed
- we could have a more polymorphic describe/it combinators to allow running in somehitng else than IO
- for tracing, we could create a tracer that piggybacks on dynamic tracing in IOSim
Reviewing network heartbeat PR together:
- Current heartbeat is not very useful, a more useful one would be a
heartbeat that only sends a ping if last message was sent more
than
ping_intervalbefore - rename
HydraNetwork->Network
At least 2 shortcomings in current snapshotting:
- Leader never changes and is hardcoded to 1
- Actually tally Acks before confirming the snapshot
- Have a better representation for MockTx
- Replace single tx
applyTransactionwith applying a list of txs
Implementing BroadcastToSelf network transformer that will ensure all sent messages are also sent back to the node
Interestingly, when I wire in withBroadcastToSelf into Main at the outer layer, the test for prometheus events in ETE test fails with one less event: This is so because we now only send back network events that are actually sent by the logic, and so we are missing the Ping 1 which the node sends initially for heartbeat.
Inverting the order of withHeartbeat and withBroadcastToSelf fixes the issue and we get back the same number of events than before
Created PR for BroadcastToSelf
Want to publish haddock to github pages
Generating documentation for all our packages amounts to
$ cabal haddock -fdefer-plugin-errors all
@mpj put together some nix hack to combine the haddocks for a bunch of modules: https://github.com/input-output-hk/plutus/pull/484
The problem is that all docs are generated individually into packages' build directory which makes it somewhat painful to publish. I could hack something with hardcoded links to a root index.html for each project in a single page?
There is an updated nix expression at https://github.com/input-output-hk/plutus/blob/master/nix/lib/haddock-combine.nix
- Review PR #13 and made a lot improvements to wordings. Some
follow-up actions we might want to undertake to better align code
and architecture description:
- Rename
ClientRequestandClientResponsetoInputandOutputrespectively - Add some juicy bits from Nygard's article to ADR 0001
- Rename
OnChain->ChainClientand check consistency for this component - Check links in Github docs/ directory, could be done in an action
- publish haddock as github pages
- publish
docs/content alongside Haddock documentation
- Rename
- Left
ADR0007
as
Proposedpending some concrete example with the network layer
- Kept working and mostly done with working on Network Heartbeat as a kind of show case for ADR0007, PR should follow soon
- In the spirit of Living Documentation I have also started
exploring the using GHC
Annotations
to identify architecturally significant TLDs. Currently only scaffolding things and annotating elements with
Componentto identify the things which are components in our architecture.
I managed to have a working plugin that list all annotated elements along with their annotation into a file. The idea would be to generate a markdown-formatted file containing entries for each annotated element, possibly with comments and linking to the source code. This file would be generated during build and published to the documentation's site thus ensuring up-to-date and accurate information about each architecturally significant element in the source code.
Some more references on this :
- There is even a study on the impact of architectural annotations on software archiecture comprehension and understanding.
- Structurizr leverages annotations for documenting C4 architecture
- Nick Tune discusses the issues with living documentation and self-documenting architecture
When closing a head, a head member must provide:
- A set of transactions not yet in a previous snapshot
- A set of transaction signatures
- A snapshot number
- A snapshot signature
The on-chain code must then check that:
- All the signatures for transactions are valid
- The signature of the snapshot is valid
- All transactions can be applied to the current snapshot's UTxO
The Ledger has a mechanism for verifying additional signatures of the transaction body, but not for verifying signatures of any arbitrary piece of metadata in the transaction. Which pushes the signature verification onto the contract itself which is likely not realistic given (a) the complexity of such primitive and (b) the execution budget necessary to verify not one, but many signatures.
Besides, each transaction must figure in the close transaction, with their signature. Running some rapid calculation and considering a typical 250 bytes transaction on the mainchain, it would mean that around 60 transactions can fit in a close, not even considering the snapshot itself and other constituents such as, the contract.
Likely, transaction inside the head shall be more limited in size than mainnets, transactions, or, we must find a way to produce commits or snapshots which does not involve passing full transactions (ideally, passing only the resulting UTxO and providing a signature for each UTxO consumption could save a lot of space).
We managed to make the BehaviorSpec use io-sim and I continued a bit on refactoring, notably the startHydraNode is now a withHydraNode. https://github.com/input-output-hk/hydra-poc/pull/14
Multiple things though:
- I could not get rid of HydraProcess completely, as the test still needs a way to capture ClientResponse and waitForResponse, so I renamed it to TestHydraNode at least
- The
capturedLogcould be delegated toIOSim/Traceinstead of the custom handle /withHydraNode - This
withHydraNodelooks a hell like the more general with-pattern and we probably should refactor thehydra-node/exe/Main.hsto use such awithHydraNodeas well (with the API server attached), while the test requires the simplesendResponse = atomically . putTMVar responsedecoration
Discussed ADRs and the Architecture PR
- Add a README.md into
docs/adrscould help navigate it and serve as an index of important (non-superseeded) ADRs - Move component description to Haddocks of modules as they are very detailed and source code centric
- The component diagram could serve as an overview and serve as an index of important modules linking to the
.hsfile or ideally the rendered module documentation (later) - This way we have a minimal overhead and as-close-to-code architecture documentation
- We might not keep the Haddocks (when we also throw away code), but the ADRs definitely qualify as a deliverable and will serve us well for developing the "real" product
Paired on making the ETE tests green
- Initialize the
partiesinHeadParametersfromInitTxinstead of theInitclient request - Re-use
Set ParticipationTokenfor this, although we might not be able to do this anymore in a later, more realistic setting
Fixed the NetworkSpec property tests as they were failing with ArithUnderflow, by ensuring we generate Positive Int
Worked on refactoring the UTxO and LedgerState type families into a single class Tx
- This class also collects all
EqandShowconstraints as super classes - Makes the standalone
deriving instancea bit simpler as they only require aTx txconstraint - Possible next step: Get rid of the
txtype variable using existential types, eg.data HydraMessage = forall tx. Tx tx => ReqTx tx
Started work on driving protocol logic to snapshotting
- We changed
HeadIsClosedto report on snapshottedUTxO, aSnapshotNumberand a list of confirmed (hanging) transactions - We introduced
data SnapshotStrategy = NoSnapshots | SnapshotAfter Natural - Updated
BehaviorSpecto have this new format forHeadIsClosedand aSnapshotStrategy, but no actual assertion of the txs being in the snapshottedUTxOset or a non-zero snapshot number - Interesting question: What happens if nodes have different snapshot strategies?
- Continued in fleshing out the actual protocol by extending the
EndToEndSpec, following the user journey - Added a
NewTxclient request and assert that the submittedtx(only an integer inMockTx) is in the closed and finalizedUTxOset (only a list of txs forMockTx) - We could make that test green by simply taking the first
AckTxand treat it as enough to update theconfirmedLedger+nubwhen applying transactions to the mock ledger - This is obviously faking the real logic, so we wrote a
HeadLogicSpecunit test, which asserts that only after seeign anAckTxfrom eachparty, the tx is added to theHeadStateas confirmed transaction - We keep a
Map tx (Set Party)as a data structure for all seensignaturesand made this test pass- This hinted that we likely want to have a
TxId txtype family and forced us to add some moreEq txandShow txconstraints - We all think that refactoring all the type families into a type class is long overdue!
- This hinted that we likely want to have a
- When trying the full end-to-end test again, we realize that our
Hydra.Network.Ouroborosis not broadcasting messages to itself, but the logic relies on this fact- We add this semantics and a
pendingtest, which should assert this properly
- We add this semantics and a
Today's TDD pattern was interesting and we should reflect on how to improve it:
- We started with a (failing) ETE test that injects a new transaction and expect it to be seen confirmed eventually at all nodes
- We made the test pass naively by confirming it on the first
AckTxmessage received - We then wrote a unit test at the level of the
HeadLogic'supdatefunction to assert a more stringent condition, namely that a node confirms a transaction iff. it has receivedAckTxfrom all the parties in the Head, including itself - To make this unit test pass we had to modify the state of the Head by:
- adding the list of parties in the
HeadParameters, which lead to a discussion on whether or not this was the right thing to do as theHeadParametersbeing part ofHeadStateimplies the head's logic can change them which does not make sense for the list of parties - adding a map from transactions (ideally TxIDs) to a Set of signatures in the
SimpleHeadState, which is thetransactionObjectspart of the state in the paper - Then we tally the "signatures" from the
AckTxwe receive, until we get all of them and then we confirm the tx
- adding the list of parties in the
- The EndToEnd test was still failing though. Analysing the trace we noticed that nodes were not receiving their own
ReqTxandAckTxmessages which means the tx could never be confirmed- => This is an assumption we made but never concretised through a test
- This should be a property of the network layer and tested there
- Fixing that (without a test) was easy enough but the EndToEnd test still fails
- Going through the logs again, everything seemed fine, all messages were there but we simply did not see the expected
TxConfirmedmessage- Increasing timeouts did not help
- Only node 1 ever confirmed a transaction
- the issue was that the list of known parties is only initialised as a consequence of the
Initcommand, which contains this list, so the other nodes never receive it
- On the plus side:
- Our high-level EndToEnd test caught two errors
- The traces are relatively straighforward to analyse and provide accurate information about a node's behaviour (not so much for the network traces which are somewhat too noisy)
- On the minus side:
- Troubleshooting protocol errors from the traces is hard
- Our HeadLogic unit test somehow relied on the assumption the network would relay the node's own messages, an assumption which is true in the mock network in
BehaviorSpecbut not tested and hence false in concreteOuroborosandZeroMQimplementations.
- More work on Technical Architecture document, adding sections on networking and on-chain messaging
- Started extraction of principles section into Architecture Decision Records, which are currently available in a branch
- Also started work on generifying the
HydraNetworklayer in order to be able to implement network related features without relying on specific technological implementation. This is also in a branch
We discussed again what we learned from the engineering meeting:
- We don't need the buffer, a simple outbound queue suffices
- Mixing of business logic and network part we feel uneasy, although we get the point of the benefits
- The tx submission protocol is still different
- The 2-state part of it at least
- The size of our messages are not always big
- Separation of "events to handle" and "buffer"
- We got the point of robustness and are sold to it
- Resilience in presence of (network) crashes and less often need to close the head
- Main difference to tx submission:
- We maybe not have a problem with ordering
- As long as we relay all messages in order
- And do not drop some messages in the application
- Snapshots provide the same natural pruning
- Do we need Relaying?
- It complicates things, but eventually is required
- So we leave it out for now and refined the drawing for a fully connected network without relaying
What did the team achieve this week?
- Discussed the pull-based approach to networking using ouroboros-network, internally and in the Hydra engineering meeting
- Took our preliminary user journey, extended our end-to-end tests based on this and drove implementation of the "closing" of a Head using that
- Build Hydra-the-project using Hydra-the-CI, primarily to cache derivations used for our nix-shell
- Provide first metrics from the hydra-node using prometheus
- Provided feedback about data and tail simulation results to researchers, adapted the simulations with updates to the protocol and ran more simulations
What are the main goals to achieve next week?
- Welcome Ahmad as Product manager to the team and onboard him
- Fill in the gaps in our Head logic and implement the coordinated Head protocol in a test-driven way
- Finalize tail simulations for the paper
Worked on completing the user journey as an End-to-End test:
- Add closing logic of the head
- Add a
UTxOtype family in Ledge. This propagates constraints everywhere, we really need a proper typeclass as an interface to ledger and transaction related types and functions, while keeping a handle for validation and confirmation of transactions - We need to post fanout transaction after some contestation period, which requires a way to
Delaythis effect- Trying to model this as a special case of
postTxhighlights the fact this is putting too much responsibility on theOnChainClientinterface - Option 1 would be to handle the delay in the event loop: provide a
Delayeffect which enqueues an event, and do not process the event before it times out - Option 2 is to
Delayan effect and spawn anasyncto do the effect later - In the particular case at hand, we just handle a single effect which is posting a FanoutTx
- Trying to model this as a special case of
- Got a passing test with hardcoded contestation period and delay effect (option 2)
- Trying the other option (delay event) and keeping it as it seems "better":
- applying an effect unconditionally after some time is probably wrong in general
- when delaying an event, we make this delayed action dependent on the state at the time of its handling and not at the time of its initiation which makes more sense: Some planned for effects might have become irrelevant because of concurrent changes
- We also move
Waitout ofEffectand intoOutcomealthough it's not used yet
-
Implement
--versionflag forhydra-node, see PR- this reuses what is done in the cardano-wallet with a minor tweak to use the SHA1 as a label in the sense of semver. The version number is extracted from
hydra-node.cabalfile viaPaths_hydra_nodemodule and the git SHA1 is injected using TH from commandgit rev-parse HEAD - We could also use
git describe HEADas a way to get both tag and commit info from git but then this information would be redundant with what cabal provides - When running this command in
ouroboros-networkfor example, I get the following result:This is so because a git repo can contain several packages, each with an executable or library at a different version so version tags alone might not give enough information and one needs to namespace tags.$ git describe --tags HEAD node/1.18.0-1169-gba062897f
- this reuses what is done in the cardano-wallet with a minor tweak to use the SHA1 as a label in the sense of semver. The version number is extracted from
-
Working on Technical Architecture Document
The following diagram was drawn to provide some more concrete grounds for the Engineering meeting (see below for minutes).
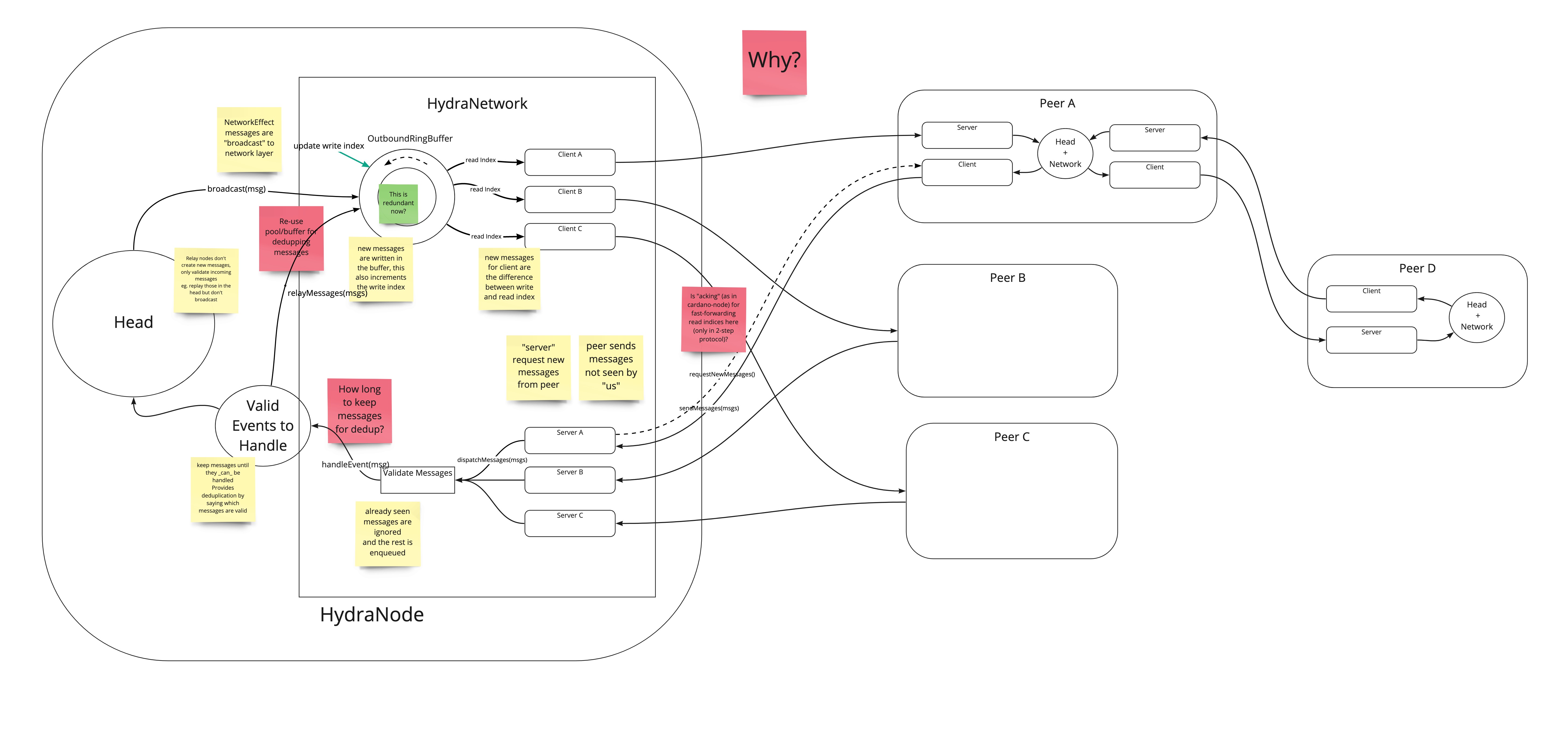
Agenda
- We showcase our current understanding of how Hydra head messaging could be done using a pull-based ouroboros-network layer (after we had a quick look on the cardano-node tx submission in-/outbound parts)
- Discussion on things we misunderstood or have not considered, as well as where to look in the cardano codebase for stealing code
Minutes
- Intro & Arnaud walks through the pull-based message flow image
- Did we understand it properly? Duncan starts to highlight differences to the cardano-node
- Why a ring-buffer?
- Tx validation does side-step deduplication, invalid txs can just be dropped
- Keep positive information instead of negative, i.e. keep track of expectations / whitelist instead of a blacklist9
- Use application knowledge to now what to keep -> is this possible?
- Maybe we can decide in the "application" level better "how long to keep" some messages
- 2-step protocol is to flood the network only with ids, not the actual transactions
- We might have big messages as well
- Adds latency, but not too much (because of pipelining)
- Mempool holds transactions and is flushed when there is a new block
- Implicitly because txs become invalid when they are incorporated in the ledger state
- Provides a natural point when to collect garbage by clearing the mempool
- Mempool code is using finger trees
- Mempool provides back-pressure because it has a bounded size
- similar idea as depicted ring buffer
- What is our positive tracking state? It is expecting AckTx upon seeing a ReqTx?
- Discuss "Events to handle"
- How long would the protocol wait for a ReqTx after seeing an AckTx -> application level decision
- Can we get stuck to this?
- How would relaying work? A relay node would not pick the ReqTx and keep it in a buffer, but still relay it
- Seeing a snapshot confirmed would flush the buffer in a relay as well
- Caveat in ouroboros-network right now:
- Possibility of multiple equal messages received at the same time
- Sharing some state between servers (inbound) could work around that
- We could use simulations to also simulate multiple hop broadcast
- What is bandwidth saturation property?
- Aligning the window of in-flight transaction + pipelining to saturate
- Why? What is the benefit of this kind of network architecture?
- very robust and very flexible
- everything is bounded
- deals with back-pressure cleanly
- deals with coming and going of (relaying) nodes
- it's efficient (maybe only using 2-step broadcast)
Our connection check for ZMQ-based networking was naive and the test is failing in CI. We need a proper protocol-level test that's based on actual messages sent and received between the nodes, but this is more involved as it requires some modifications to the logic itself: NetworkEffect should not be handled until the network is actually connected so there is a handshake phase before that.
Goal for pair session:
- move network check from HydraNode to the Network layer
- note that the
NetworkMutableStatelayer in Ouroboros network contains already information about the peers so we could use that, but this mean we need some monitoring thread to check changes in this state and send some notification
Discussing pull-based protocol:
- ask each peer what is "new"? => we need a global counter on messages, but how do you get one?
- Request for new messages
- -> How to provide new messages -> snapshot based synchronization point? => there is an intertwining of network and application layer
- locally incrementing counter -> vector of numbers?
- we would like to avoid having having a link between network layer which exchange messages and application layer which takes care of confirmation/snapshotting
- msgids are unique => "give me all msgids you have" then merge with what you have
- having multiple heads over a single network? -> we need prefix-based namespacing
Potential solution inspired by Ouroboros.Network.TxSubmission.Outbound/Inbound protocols:
- each message has a unique id (hash of message?)
- node maintains one outbound messages buffer (ring buffer?) which is fed by
NetworkEffect- => guarantees proper ordering of messages from the Head's logic
- server maintains an index for each peer about messages the peer has requested (similar to acknowledged txs)
- this index is advanced when peer requests "new" messages => we just send X messages from its index and advance it
- buffer can be flushed (write index advanced) to index Y when all peers are passed Y
- node has one inbound messages buffer
- it maintains an index of seen messages for each peer it knows
- it periodically polls the peers for new messages and retrieves those not seen, advancing its index
- messages received are sent to an inbound buffer
- head pull from inbound buffer and tries to apply message to its state
- if OK => message is put in the outbound queue, eg. it's a
NetworkEffect - if
Wait=> message is put back in inbound buffer to be reprocessed later
- if OK => message is put in the outbound queue, eg. it's a
- Problem: how do we prevent messages from looping?
- with unique message ids => only put in inbound buffer message with unknown ids => we need to keep an index of all seen message ids so far
- we could also link messages from a single peer in the same way a git commit is linked to its predecessor => we only have to keep "branches" per peer and prune branches as soon as we have received messages with IDs => instead of an index of all messages, we have an ordered index by peer
See also Miro board
- We got our
hydra-pocrepository enabled as a jobset on theCardanoproject: https://hydra.iohk.io/jobset/Cardano/hydra-poc#tabs-configuration - Goal: Have our shell derivation be built by Hydra (CI) so we can use the cached outputs from
hyrda.iohk.io - Try to get the canonical simple
pkgs.hellobuilt using<nixpkgs>fails, also pinning the nixpkgs usingbuiltins.fetchTarballseems not to work - Seems like only
masteris built (although there is some mention of "githubpulls" here) - Pinning using
bultings.fetchTarballresulted in
"access to URI 'https://github.com/nixos/nixpkgs/archive/1232484e2bbd1c84f968010ea5043a73111f7549.tar.gz' is forbidden in restricted mode"
- Adding a
sha256to thefetchTarballdoes not seem to help either - Using
nix-build -I release.nix ./release.nix -A hello --restrict-evalthe same error can be reproduced locally - This begs the question now, how upstream sources are fetched? niv?
- Setting off to re-creating the sources.nix/.json structure of similar projects using
niv - Seems like fetching
iohk-nixand using thatnixpkgsdid the trick andpkgs.hellocould be built now! - Verifying by changing the
hellojob (no rebuild if evaluation resulted in same derivation) - Adding a job to build the shell derivation of
shell.nix; this will definitely fail becausemkShellprevents build, but doing it to check whether fetching dependencies is allowed this time within restricted eval -> nice, got the expected error
nobuildPhase
This derivation is not meant to be built, aborting
builder for '/nix/store/7a2xd6y966i24jyir6722fp5dga44m0q-hydra-node-env.drv' failed with exit code 1
-
Quick hack to have it building on hyrda is to replace
mkShellwithstdenv.mkDerivation- This might not be a perfect drop-in replacement because
mkShellmerges buildInputs, nativeBuildInputs, ... - This makes it pass, but the closure is 0.0MB .. so likely not going to work for caching build tools
- This might not be a perfect drop-in replacement because
-
Instead, I continue with replacing
mkShellwithhaskell.nix'sshellForas the latter seems not to prevent building- Requires us to use
haskell-nix.projectwhich makes the whole thing built by nix (well, why not) - This in turn requires
--sha256comments in thecabal.project - Those sha256sums can be determined like this
nix-prefetch-git https://github.com/shmish111/purescript-bridge.git 6a92d7853ea514be8b70bab5e72077bf5a510596 - (Do we really need all those purescript dependencies?)
- Moved things around so there is now a
default.nixwhich holds our packages and for example thehydra-nodeexe can be built using:nix-build -A hydra-node.components.exes.hydra-node
- Requires us to use
-
Created this
release.nixnow and have the CI build it, ideally a local build of the shell would download stuff fromhydra.iohk.io:
{ ... }:
let
hsPkgs = import ./default.nix { };
in
{
# Build shell derivation to cache it
shell = import ./shell.nix { };
# Build executables only (for now)
hydra-node = hsPkgs.hydra-node.components.exes.hydra-node;
mock-chain = hsPkgs.hydra-node.components.exes.mock-chain;
}
- Reading https://blog.statechannels.org/virtual-channels/ They provide a demo for paid torrenting: https://blog.statechannels.org/introducing-web3torrent/ which enables seeders to get paid for maintaining torrents and leechers to make micropayments for each downloaded block.
- Reading more about prometheus metrics, because that's what we need to expose at the end as Prometheus is the defacto standard in software monitoring
The EKG adapter needs some kind of wrapping of EKG store in Prometheus'
ResourceT: https://hackage.haskell.org/package/ekg-prometheus-adapter
- Reviewing PR on monitoring -> The burden of updating metrics should lay on the consumer, the producer of a trace should not be aware about it
- Working on brodcasting for Ouroboros network implementation:
- As we are not relaying messages in any way, we need a way to duplicate messages for each client connection when sending
We don't have
TChanin MonadSTM or io-sim-classes, but they are handy as they provide broadcasting and duplicating messages capabilities. Asking for more information from the network team: It was simply never needed, so we could provide a PR! However, this is not the way ouroboros is meant to work, as it's really a duplex network where any part can initiate a connection.
- As we are not relaying messages in any way, we need a way to duplicate messages for each client connection when sending
We don't have
- Struggle to get the configuration right when all nodes are connecting to each other nodes: In the ouroboros
Workercode, theSnocketis bound to the local address, passing 0 as port binds it to a random system-assigned address which is what we want for a client. So we need to distinguish the client and the server's addresses when initialising the network stack - Replacing 0MQ with Ouroboros network in the main and ETE tests. Establishing connection is slower so we need a mechanism to know whether or not the node is connected to its network.
- We push an event in the internal queue when the
NetworkConnectedand send aNodeConnectedToNetworkresponse effect
- We push an event in the internal queue when the
- This is currently done in the
runHydraNodefunction but it really should happen only in the network layer and be just like any other event.
-
Reviewing PR
- better to use more generic or more specialised functions (eg.
traversevs.mapRight?) => better use more generic when it's a "standard" function, like from Functor/applicative/monad universe - What's the right process for reviewing PRs assuming we would like to avoid asycnhronous discussions? writer presenting it to the others vs. readers going through it and asking questions?
- better to use more generic or more specialised functions (eg.
-
Trying to design a user journey based on an "Exchange" scenario
- having real crypto exchanges example is difficult as we don't know how they work, we would set unwanted expectations, and we don't know if exchanges really have a use case for Hydra Head
- expressing it as something more abstract trading/marketplace?
-
How about NFT market?
- who owns the NFTs ? is the marketmaker the one who owns them?
- smart contracts could be used to guarantee you can trade the NFTs?
- using multisig script to validate sell, trusting some intermediary?
-
Ask for help from an expert in exchanges?
-
Discussion about internal vs. external commits and transactions:
- We settled on having commits being done from the PAB's wallet because this is simpler as the commmit transaction needs access to the spent UTxOs and be funded
- Actually the commits could also be done as external transactions, with only the Hydra node observing them. Transactions driving the Head SM would still be done internally, using PAB/Wallet
- Another scenario is where all the transactions will be crafted and posted externally, with the Hydra node only observing the chain and providing a view on the current state and parameters needed to create a transaction
-
Continued the Hydra / Plutus walkthrough article. Reviewed some of the earlier part and completed the Init / Abort and commit phases. Now remains the collect com, and likely some polishing: https://hackmd.io/c1hpXLmcRT-gHXRDVHkvDA?view
-
I've reached out to Romain about the whether this is indeed in the lights of what he had in mind. It's quite technical and really targetted towards developers starting with Plutus but I think it could make a nice blogpost / walkthrough.
- Remove hardcoding of host and port for hydra node executables:
- Add
--hostargument to define the interface to listen on - Add
--portargument to define the port to listen on - Add
--peersargument to define which hosts to connect to - Add
--api-hostand--api-portto define host/port for API connections
- Add
- Seems like using the iproute package for managing IP addresses would be a good idea, this is what's done already inside ouroboros networking layer.
- Trying to apply the Parse, don't validate principle on the
Optiontype and associated value, making sure things are properly parsed at the input side of the side and produce valid values with the proper types. - working on adding metrics to the hydra-node server so that we can get some metrics and monitoring tools.
- There is https://github.com/fimad/prometheus-haskell client library for Prometheus
- The "standard" way of exposing metrics is to provide a HTTP server on some port with a
/metricsendpoint, the Prometheus format is defined here: https://prometheus.io/docs/instrumenting/exposition_formats/
- Wrote an ETE test to query metrics on a running node using HTTP, assuming EKG format: https://hackage.haskell.org/package/ekg-0.4.0.15/docs/System-Remote-Monitoring.html -> test fails
- Added EKG server to the Switchboard, hopefully it should be closed when the tracer is shutdown
- The test runs too fast and the server is not up when the client requests the metrics so it fails without being able to connect to it => need to retry with some delay, which is fine as the tests are wrapped in a timeout anyways
- It's not clear how to send metrics to the tracer, see traceCounter function in the node for an example? Seems relatively straightforward.
- Ideally, I would like the same trace to be used both as tracing and sometimes as a metric, in order not to clutter the code with tracing statements
- Ad-hoc discussion on the tail simulation and collected notes which we would like to discuss / have as feedback to researchers
- Add
AmounttoCommitandNewTxAPI commands and account for it in theMockLedgerState. We deliberately simplified the commited UTxO state to just a map ofAmountand added a new end-to-end test (which should likely become a more lower-level test) which should not accept aNewTxwhich exceeds the current amount in the ledger state. - Made the
hydra-pocrepository public and relayouted the README page a bit.
-
I've continued working on the Hydra tail simulation, now including the concept of payment window and settlement delays. Also reworked a bit the on-chain data to discard some of the less relevant data points. PR opened here: https://github.com/input-output-hk/hydra-sim/pull/17
-
Stored results of some simulations in https://hackmd.io/xpiQkHB7Q6SHXRjjxnXC9g?view, we've raised a couple of questions / ideas to the research team as a result.
- We prepared a new frame on our miro board and collected work items still to be done for the prototype
- After filtering, grouping and discussing those items, we also identified which of them should be tackled definitely in an ensemble session
- The alternative being doing those tasks individually on the side on a branch and only integrate them together
- Although informal, this low-tech way of structuring the next month seemed sufficient to us
-
Use
websocketsinstead of a UNIX domain socket inhydra-nodeand E2E tests -
This forced us to not cheat like we did with the domain socket and set up a broadcast channel before starting the server, then responses to need to be fanned-out to all connected clients
-
Started to use
iohk-monitoringframework in thehydra-nodesimilarly as we already did in thelocal-clustertests also using aLoggingmodule as adapter (also anticipating, that the logging framework might change at some point -> anti-corruption layer): From: Serge KosyrevWhat to use if iohk-monitoring is deprecated? @Arnaud Bailly, contra-tracer as basis for the client code, and trace-dispatcher (which is currently being developed in the cardano-node repository) in place of the rest of the iohk-monitoring stack.
-
Simplified usage away from
Severity-levels to only havedata Verbosity = Quiet | Verboseand a single--quietcommand line flag
- Merging MB's branch with plutus contracts work, trying to understand why one plutus test is failing. Coming back to this after a few week make it somewhat hard to grok again. It's actually expected the test fails, it is a negative test that asserts the given transaction should fail
- Tried to make tests' description more explicit for our future selves.
- Regarding transactions synchronisation issues when nodes come up and down, this is the pattern that's of interest for us: https://zguide.zeromq.org/docs/chapter5/#Getting-an-Out-of-Band-Snapshot
- This requires an ordering of messages, which is somewhat easily done for on-chain transactions
- We start syncing first but don't process the messages until we get state catched-up with
- We then release the queue for processing and discard received transactions that are logically part of the new state
- Migrating our crude text-based traces to contra-tracer:
- migrate all logs to use Tracer framework in hydra-node
- configure logs to be quiet/verbose so that tests can be silent
- move APIServer code to own module
- make it possible to capture logs when tests fail -> use wallet's utility as in https://github.com/input-output-hk/cardano-wallet/blob/e3f9854a2c968e1b51de5f47579b0b8e60c8a118/lib/test-utils/src/Test/Utils/Trace.hs#L66
- check exit code of started processes in tests to not wait when the process fails (exits with non-zero code)
- Goal: Extend the existing ETE test to post a
NewTxand then expectTxReceivedevent on other nodes - Extending the test is pretty straightforward, we also improve how it waits and reports errors
- We spend time troubleshooting ETE test which does not behave as expected. This is caused by some odd behaviour in the API parsing input messages which blocks and does not fail as expected -> We need to switch to something better than Unix sockets and
Read/Showserialisation - ETE tests are flacky because if a node is slow to start it can lose messages from the chain: The chain sync
Subscription connection happens in the background and can lose messages that arePublished before it's connected => We need to make sure the node is connected to the chain in order to be sure it's started, then notify the client in some ways- use
ClientResponsemessage once the connection is established - also can send regular status messages at some predefined interval, like a heartbeat
- use ZMQ's monitor function for the mock chain but to be connected to
- We should also catch-up with previous messages from the chain
- use
- API is an interesting problem because it needs to run as a server and communicate with client and sending responses only when connected
- Our logging is really crude, we need really to move to iohk-monitoring based
Control.Tracers
Updated plan:
- Write an "end-to-end" test describing some basic interaction between 3 nodes run as processes
With a simple Init [1,2,3] commandWith complete sequence, including transactions
-
Make it pass using:A basic pub/sub 0MQ-based network layerA mock chain transporting mock transactionsA mock ledgerExposing the node's API through a socket
- Implement a REPL talking to a node through its socket API
- Implement proper logging to get some more structured feedback from running nodes
- Implement actual Mary chain (!) ledger inside node
- Replace mock chain with realish chain based on Plutus SC and simulated cardano node
- Replace 0MQ-based network with Ouroboros-based network
- Implement Head protocol using hydra-sim as a library (eg. using the same code for simulation and implementation of the heart of the protocol, as long as we can)
We close the day and week with a short recap and next week's goals. Also we decided that we want to further discuss and detail the steps mentioned above into a prioritized backlog on our virtual whiteboard early next week.
- Rewrite ETE test to use text messages instead of redundant data type
- Working on limiting ETE tests flackiness and minor:
- added a function in the mock chain and the client to « catchup »: the client first connects to the chain, pulls transactions log and then subscribe to chain sync. This seemed to me more in line with what we would do for real.
- It s not completely fool proof of course, we would need to actually start syncing before catching up and deduping to ensure we don’t lose any txs but that’s a reasonable approximation for now and it seems to stabilise the tests
- This is actually an problem which manifests itself with our mock ZMQ chain but a one we'll have with a real chain client: How to ensure completeness and total ordering of the transactions log relevant to a head? See Miro board for some exposition of the problem, to be discussed.
Goal: Shape the prototype driven by outside-in tests
Short-term plan:
- Write an "end-to-end" test describing some basic interaction between 3 nodes run as processes
With a simple Init [1,2,3] command- With complete sequence, including transactions
- Make it pass using:
- A basic pub/sub 0MQ-based network layer
A mock chain transporting mock transactions- A mock ledger
Exposing the node's API through a socket
- Implement a REPL talking to a node through its socket API
- Implement proper logging to get some more structured feedback from running nodes
- Implement actual Mary chain (!) ledger inside node
- Replace mock chain with realish chain based on Plutus SC and simulated cardano node
- Replace 0MQ-based network with Ouroboros-based network
- Implement Head protocol using hydra-sim as a library (eg. using the same code for simulation and implementation of the heart of the protocol, as long as we can)
-
Spent time troubleshooting threads locking while writing a simple test for MockZMQChain, turns out the
ipc://andinproc://transports are somehow blocking in a way I did not try to investigate, so changed to usingtcp://and it works- SN confirm it's a bad idea to use those in Haskell code -> let's stick to
tcp://transport
- SN confirm it's a bad idea to use those in Haskell code -> let's stick to
-
we finally have a working 3-nodes cluster
- we start a mock chain on default ports (56789 and 56790)
- we start 3 nodes that connect to the mock chain
-
Working with Unix sockets was somewhat of a PITA, but exposing an interface which is full duplex forces the client into a specific direction, not encouraging users towards a request/response as HTTP would do, plus we can always rebuild HTTP on top of it
- Hydra node clients should expect fully asynchronous behaviour
- Websockets would be a drop-in replacement for what we have now (UNIX sockets)
- What kind of information will Hydra node exchanges between each others
- Messages with envelope, mostly transactions and signatures.
- In the case of Cardano, the protocol is purposely defensive to prevent overflow from peers. This prevents another peer from overflowing you with message. Instead, you request for messages from peers (pull-based approach).
- Marcin: you need to know what is going to be the environment in order to design / choose the networking model. For example, if connections are authenticated, then it means there's a notion of identity which brings its own set of problems in. For example: how easy is it to get a new id? Can you trust a peer behind an id?
- For Hydra, channels between peers are authenticated. And, heads are mostly private, between a small set of participants who knows each other upfront. Keys / identities and network addresses aren't published on any public media, but rather shared via some off band mechanism. A typical use-case: two exchanges setting up a head to speed up their traffic.
- Marcin: Pull-based protocol works best in network protocols because the party which needs the information actually drives the demand. It does not create additional traffic.
- Another need for Hydra is the need for running multiple heads with (possibly) different peers. Such that, a Hydra peer may multicast to only some peers but not all of them.
- Marcin: A similar use-case may be the "block-fetch" protocol which download blocks from a single peer, and not from the entire network.
- In the case where we could pick ouroboros-network, is there a way to streamline our development requirements to the team? How?
- To be discussed with project managers.
- Marcin: Since you have a fixed set of participants, there's no need for peer discovery. This is very much like the Cardano network currently works where the topology is fixed and known from the start.
- Did we use the right functions / integration approach?
- Marcin: Yes. Although, you're using the old interface for the multiplexer. The downside being that if you run multiple protocols and one of them finishes, the connection is torn down. There's a new interface changing this.
- ouroboros-network mostly gives us point-to-point connections, so the network (as in a logical group of peers) only lives in the application logic which has to manage all the connection itself, correct?
- Marcin: Indeed. If you want a broadcast, then your application needs to send a message through each of the connections.
- In your opinion, Is this something which should be handled by the network protocol itself (using something like diffusion), or in the application logic?
- Marcin: We do something similar with the transaction submission in Cardano. What is done here is to first announce what transaction ids that we know, and then let peers choose which one they want to download.
- Another interesting topic w.r.t to the network layer is the lifespan of a message. How long does it take for a message to expire?
- In the case of Hydra, this is mitigated to some extend by snapshots and, by possibly having explicit re-submission by the application logic.
- If possible, sticking to direct point-to-point connection may be simpler but relaying using ouroboros-network is possible (like it's done for transactions). Use cases will be the main decision driver here.
- Wrapped up an initial PR for the Hydra Tail simulation, and reviewed it with Philipp in a call, walking him through the approach and the datasets. I also introduced some "last minute" requests changes shared by the researchers during the research meeting (namely: look at the transaction volume in USD instead of Ada and do not include transactions made to Byron addresses in the dataset).
- Picking up where we left on implementing Ouroboros-based networking solution, looking at cardano-node code to understand how to do connections with retries
- chasing Node's call stack but getting in the weeds of packages, looking at
Subscriptionwhich seemed promising - Had to go low-level Looking for ways to resolve strings into
SockAddr, ouroboros uses iproute package but is it really useful? Probably for better error handling but the examples useread... - got a failing test after 1.5 hours adding low-level networking code, now trying to listen to server
- got a passing test at last, we need to wait once both servers are running in order to make sure the message reaches its destination
- chasing Node's call stack but getting in the weeds of packages, looking at
Implementing HydraNetwork over 0MQ sockets, plan is to use Pub/Sub sockets: Each node will open a single Pub socket to broadcast messages and multiple Sub sockets to each peer. This is gross and does not provide any kind of reliability but will suffice for the moment.
- It would be nice to handle node crashes by providing an out-of-band messages catchup mechanism, eg. using some form of Req/Rep socket or possibly a Dealer/Router to load balance across nodes? When a node recovers from crash, it can ask any of its peers for the previous messages.
- using
lsof -p <pid>I can see the sockets are connected to each other:ghc 53011 curry 62u IPv4 143439 0t0 TCP localhost:59420->localhost:55677 (ESTABLISHED) ghc 53011 curry 63u a_inode 0,14 0 11421 [eventfd] ghc 53011 curry 64u a_inode 0,14 0 11421 [eventpoll] ghc 53011 curry 65u IPv4 140876 0t0 TCP localhost:55677->localhost:59420 (ESTABLISHED) ghc 53011 curry 66u a_inode 0,14 0 11421 [eventfd] ghc 53011 curry 67u IPv4 141503 0t0 TCP localhost:55679 (LISTEN) ghc 53011 curry 68u a_inode 0,14 0 11421 [eventfd] ghc 53011 curry 69u a_inode 0,14 0 11421 [eventfd] ghc 53011 curry 70u a_inode 0,14 0 11421 [eventpoll] ghc 53011 curry 71u IPv4 143440 0t0 TCP localhost:44422->localhost:55679 (ESTABLISHED) ghc 53011 curry 72u a_inode 0,14 0 11421 [eventfd] ghc 53011 curry 73u a_inode 0,14 0 11421 [eventpoll] ghc 53011 curry 74u IPv4 144626 0t0 TCP localhost:55679->localhost:44422 (ESTABLISHED) ghc 53011 curry 75u a_inode 0,14 0 11421 [eventfd] ghc 53011 curry 76u IPv4 140877 0t0 TCP localhost:36162->localhost:55678 (ESTABLISHED) ghc 53011 curry 77u IPv4 140878 0t0 TCP localhost:59426->localhost:55677 (ESTABLISHED) ghc 53011 curry 78u IPv4 138975 0t0 TCP localhost:55678->localhost:36162 (ESTABLISHED) ghc 53011 curry 79u IPv4 144627 0t0 TCP localhost:55677->localhost:59426 (ESTABLISHED) ghc 53011 curry 80u IPv4 138976 0t0 TCP localhost:44428->localhost:55679 (ESTABLISHED) ghc 53011 curry 81u IPv4 144628 0t0 TCP localhost:55679->localhost:44428 (ESTABLISHED) ghc 53011 curry 82u IPv4 138977 0t0 TCP localhost:36168->localhost:55678 (ESTABLISHED) ghc 53011 curry 83u IPv4 141504 0t0 TCP localhost:55678->localhost:36168 (ESTABLISHED)
Some interesting takeaways from fiddling with 0MQ:
-
From https://zguide.zeromq.org/docs/chapter1/#Getting-the-Message-Out
Note that when you use a SUB socket you must set a subscription using
zmq_setsockopt()andSUBSCRIBE, as in this code. If you don’t set any subscription, you won’t get any messages. It’s a common mistake for beginners. -
From https://zguide.zeromq.org/docs/chapter2/#Missing-Message-Problem-Solver
Even if you synchronize a SUB and PUB socket, you may still lose messages. It’s due to the fact that internal queues aren’t created until a connection is actually created. If you can switch the bind/connect direction so the SUB socket binds, and the PUB socket connects, you may find it works more as you’d expect.
I tried inverting the
binds andconnects betweenSubandPuband it still works but I nevertheless have to wait before broadcasting, which makes sense because there are 3 "nodes" involved and the various threads can still start out of order. -
The 0MQ guide proposes various ways to synchronize publish/subscribe patterns. In practice, we can live with it in a prototype because the nodes will still synchronise through the mainchain but we'll need a proper solution in the medium term otherwise it won't be practical. Nodes need to have a guarantee messages are delivered and fetchable, even in case of crashes and restarts.Probably the "right" way to do that would be to REQ/REP sockets and check proper delivery of messages. 0MQ provides a
pollmechanism which allows one to receive/send over multiple sockets in an asynchronous way. Also, https://zguide.zeromq.org/docs/chapter2/#Node-Coordination suggest to use REQ/REP for synchronising nodes first, before using pub/sub.
Not complete, only the most important functions regarding connecting the network are mentioned
-
handleSipleNode: sets updiffusionArgumentsfrom configuration etc.-
Node.run: sets upllrnRunDataDiffusionwithstdLowLevelRunNodeArgsIOand callsrunWith-
Node.runWith: runsDiffusionApplicationsusingllrnRunDataDiffusion -
stdLowLevelRunNodeArgsIO: definesllrnRunDataDiffusionin terms ofstdRunDataDiffusion-
stdRunDataDiffusion:runDataDiffusion-
runDataDiffusion: forks all the threads, notably “subscription workers” for peers-
runIpSubscriptionWorker: primesipSubscriptionWorkerwithDiffusionApplications/DiffusionArguments-
NodeToNode.ipSubscriptionWorker: aSubscription.ipSubscriptionWorkerwithconnectToNode'as continuation-
Subscription.ipSubscriptionWorker-
subscriptionWorker: aworkerwithsocketStateChangeTxandcompleteApplicationTxcallbacks-
worker: tries to connect and invokes continuation on succesful connections? -
subscriptionLoop: loops over subscription targets and tries to connect (viainnerLoopandinnerStep) -
safeConnect: bracket around Snocket open / close + extra actions (for updating some connection status) -
connAction: updates subscription worker state and calls continuation mainLoop
-
-
-
connectToNode': start a handshake and given ourobouros application (hereDiffusionApplications) using existing socket
-
-
-
-
-
-
-
- AB Moved changes made in
mastertoabailly-iohk/network-experiments - SN Tried to verbalize & illustrate the testing strategy as a pyramid
see Testing Strategy
Plan for today:
-
make 2 nodes communicate with each other by implementing mock
NewTxcommand andReqTxmessage -
implement
HydraNetwork- a central MQ, eg. Google Pub/Sub: only need 1 address for configuration, namely the topic?
- 0MQ -> https://gitlab.com/twittner/zeromq-haskell/-/tree/develop/examples
- Ouroboros (see FireForget example)
- Considering testing https://hackage.haskell.org/package/amqp which is a RabbitMQ client
- GCP provides pre-canned images of a RabbitMQ server: https://console.cloud.google.com/marketplace/product/click-to-deploy-images/rabbitmq?project=iog-hydra&folder=&organizationId=
- Better to use a simple docker image: https://registry.hub.docker.com/_/rabbitmq/
-
Got a passing "integration test" whereby 2 nodes apply transactions upon receiving a
ReqTxmessage and update their ledger, using a MockTx. Fleshed out more of the internal logic, with shortcutting the whole confirmation dance in order to get to the point (have nodes exchangin transactions) faster -
Hit a minor problem is that there's actually 2 networks involved in the Hydra nodes cluster:
- One between nodes, using
HydraNetwork - One to the chain, using
OnChainTx - So I need some sort of mock chain to be able to interconnect nodes one to each other
- One between nodes, using
-
Went on implemeting a 0MQ based
mock-chainprogram that can route transactions posted by several nodes. This was relatively straightforward except for the time I wasted because I forgot a call tosubscribeand of course there's nothing to tell me I wasn't able to receive anything. In the end, it's now possible to have 1 or more nodes talk to amock-chaininstance running somewhere (can be tcp, or unix sockets or even in memory queues) and run the Init -> commit -> close logic -
Note there exists Curve0MQ which is a protocol for encrypting communications between 0MQ sockets.
-
Does work in a decentralized manner?
- Sounds more like a philosophical question. Charles would probably say that it must be.
- From a technical standpoint, maybe not. Especially for the MVP. But from the security standpoint, not relying on a central external service for the good functioning of the protocol is essential.
- The Head protocol is not live under adversarial conditions anyhow, so there is no extra security gained from running over a decentralised network
- From a product/MVP standpoint, not much is lost with having a centralised solution at first
-
Allow for connections of hydra-nodes running next to cardano-node?
- Seems to be a confusing question... need rephrasing / additional context
- This question is more about deployment / infrastructure than about networking
- It depends on the use cases envisioned => Hydra nodes should be flexible to support different kind of network connectivity?
-
Allow for private messaging within the Head?
- Sort of orthogonal to the networking layer, can be added on top if needed.
-
Allow multiple heads communicate over the same network
- What's multiple? 10? 100.000?
- The paper assumes point-to-point connection, but is it a requirement for the physical network?
- May depend on the use-case and what head members do want? Both use-cases where members want to share a network or to have a private one can are imaginable. We perhaps want to keep that somewhat flexible and allow users to chose what type of network they want to join / establish head on.
-
Should all failures force the head to be closed?
- Hard to answer as it depends on how much we still want to trust other peer
- The closing policy was intentionally left implicit in the paper, it could be configurable.
- We maybe need a more elaborate heuristic and allow some flexibility to cope with possible network failures. However, behaviors which impact the liveness too much should likely force closing of the head.
-
Know connectivity of head members
- Harder to do in a decentralized setup than centralized one.
- Right thing to do usually: rely on replies as part of the protocol and don't bother with low-level networking stuff for that.
- Taking a stab on a prototype user journey using an activity diagram, as well as some wireframes
- Random Discussion / brain storm between SN/AB
- Is a single-node hydra head meaningful? It basically would be an aggregating / sub-ledger. Maybe simplifies "using application"? "Cardano-ledger-as-a-service"
- Poker game as a narrative
- could be simple payment txs -> good enough
- but also plutus running in Hydra is thinkable -> would require PAB "in front of" Hydra
- About network requirements:
- There are no real requirements onto networking as far as the Hyrda protocol goes
- Different to Cardano-node, where the consensus requires things
-
New networking requirements draft for tomorrow's engineering meeting:
-
Reliable message delivery to all other Hydra Head members (at least once)
- must-have
- i.e. multicast to Head
-
Does work in a decentralized manner
- must or should?
- i.e. no central message broker required
- if centralized is a no-go, is a centralized relay / discover service ok?
-
Allow for connections of hydra-nodes running next to cardano-nodes
- should
- even if they are behind NAT / Firewalls
- "Similar topology as cardano-node" is not really required though
-
Allow multiple heads communicate over the same network
- should
- ideally in a non-wasteful manner
-
Allow for private messaging within a Hydra Head
- should
- e.g. using encryption and/or dedicated connections
-
Network topology can be independent of Head topology
- should
- a single peer / connection may not represent a single Head member directly
-
Know connectivity to other Head members
- nice-to-have
- however, this needs to be dealt with simple timeouts anyways (same as if someone deliberately stalls)
-
Connection failures do not force the head to be closed
- nice-to-have
- How long being offline is allowed?
- Resilience / persistence -> re-deliver messages when node re-connects
- Which component does re-deliver messages?
- This is why there will be a Tail protocol -> NOT A REQUIREMENT?
-
- We had to pending/failing tests to fix after we introduced several commit transactions
- We need to collect and "tally" the commits until we've seen all parties committing, then post the
CollectComtransaction, and only then move to theOpenstate- Introduced some types and structure to represent the logic of init/commit/collectcom
- The
Initcommand takes a list ofParty. This is simply a number right now but should actually be the list of keys of the involved parties - These keys yield a
SetofParticipationTokenthat are created as part of theInitTxtransaction - Each
Commitconsumes its ownParticipationTokenwhich is removed by all participants when they see theCommitTxtransaction - The last committed posts the
CollectComTxwhich actually opens the state (with the UTxOs posted)
- The
- tests failed before we added the last step so we also changed the simluated
OnChainclient to simply drop "duplicate" transactions, where duplicate transactions are simply identicalOnChainTxvalues. This is an approximation of the blockchain behaviour which won't let you post 2 transactions that consume the same inputs, which is modelled here by having 2 identical values.
- Introduced some types and structure to represent the logic of init/commit/collectcom
Looking into existing messaging middleware/platforms we could use for Hydra. The idea is that rather than building in some messaging tranport system we could simply leverage existing software providing the kind of network primitives we are interested in:
-
decentralised solutions are better
-
for the head, it boils down to: Secure transport, P2P and Multicast messaging, reliable delivery (at least once?) to all nodes
-
for the tail, we might need: Pub/sub, persistence
-
https://matrix.org/, a distributed/decentralised system for Messaging and VoIP. main server is https://github.com/matrix-org/synapse/ a python implementation.
-
https://nats.io/ geared towards messaging for software/IOT, eg. more like MQTT than Jabber. There is a Haskell client: https://github.com/ondrap/nats-queue Mostly pub/sub but can also do req/response. Server is built in Go: https://github.com/nats-io/nats-server
-
MQTT has quite a few servers/clients available: https://mqtt.org/software/ (including Haskell client: http://hackage.haskell.org/package/net-mqtt) Reference server is Mosquitto. MQTT brokers are mostly centralised in nature, so one has to setup a MQTT Bridge to provide relaying capabilities, which seems like an additional layer of complexity.
-
Grav is only available embedded in Go programs, but provides broker-less message routing
-
Kafka is one of the most deployed message broker, but it's very centralised, relying on zookeeper cluster to keep kafka cluster information. Not suitable for our use case probably...
-
RabbitMQ also provides way to make the message broker distributed, usign either a clustering mode which replicates everything across a cluster of nodes, but it's still very centralised.
-
NSQ is another "real-time" distributed messaging platform, in go. Seems pretty similar to nats but much less mature. There is an embyronic Haskell client https://github.com/pharaun/hsnsq
We should probably make core Hydra node ignorant of the underlying network topology and allow for various deployment and configuration options, possibly with different "plugins" for different messaging infrastructure.
- Presented the work done on the simulation and researchers raised a few points:
-
The client "deactivation" behavior should be more immediate. That is, we expect client to go offline pretty much immediately after having submitted a transaction. We may also consider the case where clients may simply go online to pull latest data from the server without submitting anything. The simulation needs to be adjusted accordingly.
-
They expressed interest into hooking real data into the system as an alternative approach to using baselines. The idea would be to run the simulation in a fast-forward mode but using real data from the main chain. Using stake keys as identifiers, we currently have more than 680.000 wallets / clients which is deemed unrealistic for a single tail so we want to group some wallets together to reduce the number of clients down to ~1000 and have an increased traffic per client. Then, use such a dataset to feed the simulation with various parameters and show that the tail would have been able to run such a traffic at a higher throughput (maybe?)
-
- Thinking about and drafting requirements for our networking layer:
- Connect hydra-nodes to form a Hydra head
- static configuration
- setup based on Init (command or tx metadata?)
- Allow for similar topology as Cardano network
- essentially NAT & firewall traversal
- Syncthing relays TCP/TLS connections, which might be similar
- Deliver messages to other Hydra head members
- No individual messages required though
- Capable of routing/addressing?
- Share connections between multiple Hydra Heads and target individual groups of paricipants (multicast)
- Head-Head communication
- Routing in bitcoin lightning: FLARE
- what does this mean?
- Connect hydra-nodes to form a Hydra head
- Had meetings about getting to know people and potential use cases for Hydra
- Thought about what the Hydra Prototype user interface features / user stories could be
- Assumptions for the prototype:
- Only one Head per process
- Connected wallet with funds (behind Chain client)
-
Focus on explaining not efficiencyInteractive user interface (whereas later iterations are likely driven by an API)
- Features:
- Display current Head state and possible actions (commands)
- Visualize committed / current UTXO set
- Visualize network & chain events
- Display peers / connections
- Connect to peers (add/remove)
- Initialize a Head by providing parameters
- Display commit prompt
- Commit value to a Head
- Display that all committed / prompt to collect
- Close a Head
- Display contestation period / prompt (when something to contest)
- Pick & load transaction from file to send into Head
- Display errors
- Display node metrics
- Assumptions for the prototype:
- Only AB and SN today, MB focus on hydra simulations
- We worked in a fully TDD mode today
- Added a couple of tests to cover the full lifecycle of a hydra head
- We got rid of the
init,newTxandclosefunctions as we were puttingClientEvents into the event queue of the hydra node instead - Interesting forth and back on the interface between test suite and
runHydraNode, notably thesendCommandandwaitForResponseabstractions for theHydraProcess - Fully embrace that asynchronous interaction pattern for the time being
- Fleshing out the
Hydra.Logic.updatefunction felt very natural - Having tests with two nodes required to be explicit individual
HeadStates and alternating betweenClientEffectandChainEffect, i.e. the test suite + architecture didn't allow for short-cuts, which is a great property (in SN's opinion) - Furthermore, the actual business logic is contained in
Hydra.Logicas pure function and with some syntactic sugar / helper functions will be likely be easy to digest and review -> hopes are high that this is also a good interface to researchers
Research papers on Pub/Sub perf/reliability modelling :
- https://hal.inria.fr/hal-01893926/document
- http://www.dvs.tu-darmstadt.de/publications/pdf/jms2009PS.pdf
- https://arxiv.org/pdf/1709.00333.pdf
- http://www.scalagent.com/IMG/pdf/Benchmark_MQTT_servers-v1-1.pdf
- http://wiki.zeromq.org/whitepapers:measuring-performance
-
Created some scripts to (a) download the mainchain data, (b) process and transform the data to group it by "wallet / stake keys". https://gist.github.com/KtorZ/7d9994b7ee3215957628370386866802
-
Started working on a simplified Tail simulation from the hydra-sim code.
- I've re-used the same approach as for the Head, that is, running a simulation in the IOSim monad, and then analyzing it. Except that for now, I am not yet analyzing the data 😬 ... simply printing out the trace to stdout.
- So far, it's modelling a very simple message broker with simple pre-configured subscriptions.
- Each client has the same behavior, but has random activation and deactivation patterns as discussed with the researchers.
- Continued on the
hydra-node:test:integrationtest, although we seem not to agree on what an integration test is - Connect the pre-existing logic of
initwith the test suite - Added a test case about hydra node behavior for
initandcommitfor a single hydra node - Interleaved discussion about level of detail and what this test suite should be covering
- Bit the bullet and started formulating a test case involving two hydra nodes
where one would
initandcommit, but the other onlycommitand then wanting tonewTx - This led us to implementing a mocked "chain" and corresponding
OnChaininterfaces to connect the two nodes -> made the test pass! - When implementing this, we realized that having the business logic in two
separate places (concretely:
Node.initandLogic.updatefunctions) felt weird and that an approach of having client commands (ClientRequest) next to other events and a single function forState -> Event -> Outcomeis the natural way forward
- Wrote an
autotest.shscript that (ab)uses cabal's GHC_ENVIRONMENT and ghci to load all source files and run all Hspec tests. This is pretty fast thanks to the use of ghci. - Things got a bit trickier trying to also compile and run hydra-plutus tests: The tests use tasty so no luck running them without some more additional fiddling, and the PLC plugin requires additional flags and slows down the compilation process
-
While working on the Hydra Walkthrough, I thought about attempting to simplify a bit the on-chain validation logic to avoid re-using the same validation functions in multiple validators as Sebastien raised this as a confusing part on several occasions. I had thought for a few days about this so it was good timing to try it out and it seems to work pretty nicely (test code and off-chain code is untouched (except some cosmethic changes) and everything still seem to work. The main idea is to delegate most of the validation logic from the commit and initial validators to the main Hydra validator; the trick for achieving this is to require that one of the input is actually a UTxO held by the Hydra contract (for which we know the address that is unique per Head instance) with an expected redeemer as transition. This highly simplifies the commit and initial validator which then only need to check for what is specific to them, and leave the rest of the validations to the Hydra validators. It materializes as such:
initialValidator HeadParameters{policyId} hydraScript commitScript vk ref ctx = consumedByCommit || consumedByAbort where consumedByCommit = mustCommitUtxo commitScript (vk, ref) ctx consumedByAbort = mustRunContract hydraScript Abort ctx commitValidator hydraScript committedOut () ctx = consumedByCollectCom || consumedByAbort where consumedByCollectCom = mustRunContract hydraScript CollectCom ctx consumedByAbort = and [ mustRunContract hydraScript Abort ctx , mustReimburse committedOut ctx ]
It is then the responsibility of the Hydra validator to check for instance that all members have committed, or that an abort does indeed burn all participation tokens. Much nicer 👍
- What to keep/throwaway from existing hydra-sim code?
- We could keep networking stuff (Multiplexer and friends) but communication patterns are very different in the tail??
- We don't want to break the head
- There's connection/disconnection involved in tails
- Trying to reuse might be more complicated than writing something specific (esp. without tests...)
- What needs to be done for the tail protocol simulation?
- we need only baselines right now but we not only need that
- let's check with Researchers
- what format do we want? CSV format == columns definining the parameters of the simulation, then some measure
- Baseline = time to send/rcv a transaction for connected tail clients through a node
- a tx with some UTXO is visible by all clients interested?
- Tail = 1 server to which multiple clients are connected
- pure tail = message brokerage (persistence)
- clients can come/go but when they send a tx to the tail server, the tx is "recorded" and "guaranteed" to reach the recipient, assuming the latter is connected to the tail
- how does a server identifies a client? -> some specific address/public key, ~ topic
- TX are isomorphic -> "standard" addresses
- no way to know how the pub keys are derived -> it's not trivial to derive addresses from pub keys
- client needs to subscribe to addresses it is interested in => a client wishing to receive something through the tail must publish pub keys he is interested in
- "unknown" addresses would be put on-chain immediately
- addresses of interest == topics which are kept
- MQTT provides some QoS
- reusing real data from Cardano ?
- does not make sense to reuse as is because of data complexity
- but reuse the pattern, the graph structure
- make results depending on the number of clients (10 --> 10000 ..), extract communication pattern from existing transactions
- replay a transactions exchanges scenario, where clients come online, post a tx, go offline, at the timestamp of the tx
- but clients make few transactions (like 1/day for very active wallets) -> derive configuration parameters, like the distribution of clients in tx frequencies buckets
- find hyper-parameters to resample a scenario
- would be interesting to know how fast a real sequence of transactions could have been done on a tail
- why Hydra?
- if no one cheats it's faster and cheaper
- if someone cheats, it's always possible to go back to the mainchain
- this is true of monetary txs (cannot lose money) but what about smart contracts? -> A tail server could withhold a tx containing a smart contract "invocation" with adversarial effects
- NFTs also could be problematic
- not a problem for us :) -> that's research
- first step: wireframing of the simulation setup (actors, messages, networking patterns...)
- persistence? -> incur some added delay?
- // simulating MQTT
- Started collecting information about all the Hydra protocols (besides Head) here
- Discussed Alonzo fee inputs (spec) and what we think of it being in the Plutus
TxInfoAPI- In hydra this would likely be always
[], any script relying on it would not work obviously - Why have
txInfoInputsFeeswhen there are no "Redeemer budgets", which seem to be on the same "level" - Our personal plutus experience: It would be just another way to shoot yourself into the foot -> KISS
- In hydra this would likely be always
Messing up with ghcid in order to try to speedup tests execution time turnaround.
-
It does not work out-of-the-box, so investigating how to run
cabal replto prepare the proper command forghcid, but giving up on this for the moment -
Found the code responsible for the
divide by zeroobserved by Sebastian: We are computing averages of an empty list -
Trying to setup a crude watch based loop in hydra-sim to get better tests feedback
-
Got a basic
watch.pyscript working that runcabal teston each change, based on a previous tcr script, now looking for a way to speed compilation time. Give up after a while as I cannot seem to be able to load stuff in GHCi correctly -
Now making some progress in ensuring average computations are safer: Want to return 0 when averaging an empty list
-
Retrying to run simulations with coordinated protocol and checking why I got no difference with Simple vanilla proto. Actually the Coordinated protocol code is pretty naive and does not work as is, need to modify and update both signed and confirmed transactions set as the snapshot daemon only reap out confirmed transactions for snapshotting purpose The problem in
Analyseis that we look for the confirmation message to check the number of confirmed transactions processed by the cluster, which does not work in the case ofCoordinatedprotocol because there aren't any. What we want is to get an estimate of the tps for transactions which are part of a snapshot, or an estimate of the number of tx/second derived from the number of snapshots per second -
Got some more sensible results running simulation with Vanilla and Coordinated protocol for a small test case side-by-side, but there is a discrepancy in
Processed 500 transactions, which comes from theconcurrencylevel set in the simulation which arbitrarily limits the number of "in-flight" transactions, so that when this limit is reached, no more transactions can be submitted. ThehsTxsInflightfield of the node's state needs to be updated when the transactions are confirmed by a snapshot. -
Finally get consistent results, eg. the same number of transactions is processed in all runs, and the throughput is better in the coordinated case: Simple:
Processed 2000 transactions. Made 4 snapshots. Transaction throughput (tx per second): 635.8583367237499 Snapshot throughput (tx in snaps per second): 567.6559905357556 Average tx confirmation time: 0.75892149875s Average snapshot size: 500.0Coordinated:
There were 2000 unconfirmed transactions. Processed 2000 transactions. Made 8 snapshots. Transaction throughput (tx per second): 0.0 Snapshot throughput (tx in snaps per second): 965.1536551009842 Average tx confirmation time: 0s Average snapshot size: 250.0
- I want to generate a code coverage report for hydra-poc, and possibly publish it, but coverage generation fails:
% cabal new-test --enable-coverage all
Error:
Internal libraries only supported with per-component builds.
Per-component builds were disabled because program coverage is enabled
In the package 'typerep-map-0.3.3.0'
-
Looking into cabal source code for the error message: https://github.com/haskell/cabal/blob/00a2351789a460700a2567eb5ecc42cca0af913f/Cabal/ChangeLog.md There is a test case which looks similar to waht I am seeing: https://github.com/haskell/cabal/blob/00a2351789a460700a2567eb5ecc42cca0af913f/cabal-testsuite/PackageTests/InternalLibraries/cabal-per-package.out and
typerep-maphas an internal library defined: https://github.com/kowainik/typerep-map/blob/main/typerep-map.cabal#L80 -
Found the place where the error message is created: https://github.com/haskell/cabal/blob/00a2351789a460700a2567eb5ecc42cca0af913f/cabal-install/src/Distribution/Client/ProjectPlanning.hs#L1378
-
So there is a concept of "per-package" and "per-component" build in cabal and the latter cannot be enabled if various conditions are set: we are in
configurephase, cabal version is less than 1.8, the--disable-per-componentflag is set or coverage is set.. -
However, per-component is needed for builds with so-called "internal libraries", eg. packagse containing several named libraries, which is the case of typerep-map:
library typerep-extra-impls import: common-options hs-source-dirs: typerep-extra-impls exposed-modules: Data.TypeRep.CMap Data.TypeRep.OptimalVector Data.TypeRep.Vector build-depends: containers >= 0.5.10.2 && < 0.7 , vector ^>= 0.12.0.1 , deepseq ^>= 1.4 -
Tt's working if I narrow
coverage: Truestatement to the relevant packages. There was an interaction withcabal.project.localfile which had thecoverage: Trueflag thus enabled for all packages!! Note to self: Do not usecabal.project.local -
Now running into another problem:
Test suite logged to: /home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-model-0.1.0.0/t/hydra-model-test/test/hydra-model-0.1.0.0-hydra-model-test.log hpc: can not find hydra-node-0.1.0-inplace/Hydra.Logic.SimpleHead in ./.hpc, /home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-model-0.1.0.0/t/hydra-model-test/hpc/vanilla/mix/hydra-model-0.1.0.0, /home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-model-0.1.0.0/t/hydra-model-test/hpc/vanilla/mix/hydra-model-test CallStack (from HasCallStack): error, called at libraries/hpc/Trace/Hpc/Mix.hs:122:15 in hpc-0.6.1.0:Trace.Hpc.Mix cabal: Tests failed for test:hydra-model-test from hydra-model-0.1.0.0. -
So it seems there is
.tixfile and several.mixfiles whic are generated, but running hpc does not seem to find them! Found the cabal issue and fix for this problem: https://github.com/haskell/cabal/pull/7250 but it's been merged only a few weeks ago. Is there a workaround? Looking at this previous issue to find one: https://github.com/haskell/cabal/issues/5433 -
I found the right invocation to get a coverage report:
$ /nix/store/s07x6jlslgvxwrh6fa4zwyrlvyfgp9as-ghc-8.10.4/bin/hpc markup \ /home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/t/tests/hpc/vanilla/tix/tests/tests.tix \ '--destdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/t/tests/hpc/vanilla/html/tests' \ '--hpcdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/t/tests/hpc/vanilla/mix/tests' \ '--hpcdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/hpc/dyn/mix/hydra-node-0.1.0/' \ --srcdir hydra-node/The actual invocation has
hpcdirwrong and nosrcdirwhich prevents finding the files:$ /nix/store/s07x6jlslgvxwrh6fa4zwyrlvyfgp9as-ghc-8.10.4/bin/hpc markup \ /home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/t/tests/hpc/vanilla/tix/tests/tests.tix \ '--destdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/t/tests/hpc/vanilla/html/tests' \ '--hpcdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/t/tests/hpc/vanilla/mix/tests' \ '--hpcdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/t/tests/hpc/vanilla/mix/hydra-node-0.1.0' \ '--exclude=Hydra.Node.RunSpec' '--exclude=Hydra.NodeSpec' '--exclude=Hydra.LedgerSpec' '--exclude=Main'The second
hpcdirargument does not exist! -
Correct invocation for
cabal test hydra-modelis:/nix/store/s07x6jlslgvxwrh6fa4zwyrlvyfgp9as-ghc-8.10.4/bin/hpc markup \ /home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-model-0.1.0.0/t/hydra-model-test/hpc/vanilla/tix/hydra-model-test/hydra-model-test.tix \ '--destdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-model-0.1.0.0/t/hydra-model-test/hpc/vanilla/html/hydra-model-test' \ --hpcdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-model-0.1.0.0/t/hydra-model-test/hpc/vanilla/mix/hydra-model-test \ --hpcdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-node-0.1.0/hpc/vanilla/mix/hydra-node-0.1.0/ \ --hpcdir=/home/curry/hydra-poc/dist-newstyle/build/x86_64-linux/ghc-8.10.4/hydra-model-0.1.0.0/hpc/vanilla/mix/hydra-model-0.1.0.0 \ --srcdir hydra-node --srcdir hydra-model
- Frustrating mob session this afternoon, trying to write "integration" or "acceptance" tests to drive the development and design of the "Hydra Node", eg. the main component of Hydra which clients interact with.
- Shared with the team Thomas Pierrain's blog post on the Outside-In Diamond TDD approach he is using.
- To summarize:
- Focusing on unit tests does not leverage the value proposition of TDD
- Tests should be written under-the-skin so to speak, eg. without having to deal with a specific external representation as an interface, whether it be a RESTish API, a command-line interface, a gRPC server... This also means there is little value in bringing in some specialised test language à la gherkin
- They express how a typical client would use a Hydra Node: What they can observe from the node's internal state, what kind of commands or queries they can send or ask to it, along with responses they get, from the point of view of the client. For example, they should express what happens from the point of view of the client when it wants to start a new Head? It should probably send an
Initcommand, possibly with some parameters and configuration, this command might or might not make sense for the node depending on its current state, the command might be handled synchronously or asynchronously and thus the client might need to have some feedback, perhaps some indication about progress of the command, etc. - While not depending on a particular client-facing interface, they should cover as much as possible of the system, but not too much!
- Yet those tests should be fast, hence they should not rely on complicated IO/side-effecting setup, as there might be a lot of them
- So we might want to take emulate some IO-heavy parts like networking (perhaps not all of networking, maybe we can get away with local sockets and have a full protocol stack, or if it's cumbersome we can have a queue-based networking layer....)
- We might also want to not depend on running an actual cardano-node, or even completely abstract the
OnChainside - But having a "real" ledger makes sense and would allow us to express more user-centric use cases
- "fuzzers" (eg.
Arbitraryvalues) are very useful in increasing the "coverage" and diversity of data used when running the tests
In the case of a HydraNode, here is what we could have for a starter:
spec :: Spec
spec = around startStopHydraNode $
describe "Hydra node integration" $ do
it "does accept Init command" $ \hydraNode -> do
sendCommand hydraNode Init `shouldReturn` CommandAccepted
-- | This is a test-only adapter to handle actually running a single fulll
-- `HydraNode` within the context of "high-level" tests
startStopHydraNode :: (HydraNode MockTx IO -> IO ()) -> IO ()
startStopHydraNode act = do
node <- createHydraNode mockLedger
withAsync (runHydraNode node) $ \thread -> do
act node
cancel thread
What did the team achieve this week?
- Worked more on plutus contracts, covered most of our use case with and without the Plutus.Contract.Statemachine library
- Digested some experiments we made individually on writing the hydra protocol logic
- Engineering meeting on multi-signatures and identified MuSig2 with schnorr-compatible signatures (includes Ed25519) and a non-interactive additional round to sign things as a good starting point
- Created a monthly report https://input-output.atlassian.net/wiki/spaces/HYDRA/pages/2575630462/Monthly+report+-+April+2021
What are the main goals to achieve next week?
- Formulate a demonstrative use case which we'll use during prototype development (e.g. poker game)
- Re-imagine our integration test suite and work our way from the outside in to implementing a hydra-node prototype
- summarize experience about the eUTXO model, using Hydra as an interesting use case
- how does it work, what you put in context, how to build TX
- what's difficult in Plutus, backward validation, feels like a lot of duplication (on-chain code is close to off-chain), sufficiently common to be a pain to maintain but sufficiently different ot have 2 code bases
- need to see Lars' video again? -> introduction
- multiple contracts? => non-trivial validators
- contract state-machine
- package everything in a single validator, is it a good idea? Is it even possible?
- design practice ? multiple validators => multiple addresses or single validator => multiple branches
- ambivalency between building tx and validate tx => feels like double work, confusing on/off-chain
- blurring the line is hard but there's redundancy by keeping it separate
- // with isomorphic JS => doable, but does it really payoff? useful for serialising stuff but does it really pays in the application dev?
- nice analogy
- arguments against sharing types/code between layers (generating FE code from BE code...)
- Lars explained why
INLINEABLEis needed => TH is used to compile Plutus and the whole expression needs to be pulled in for compilation - Why is plutus not compileed in a separate step?
- interleaved magically inside Haskell?
- could be a "main" function and pass that to a separate Plutus compiler?
- sharing should not be the default, sharing types is fine in a closed immutable world
- what about changes in off-chain code? By having "magic" deserialisation/serialisation
- Plutus is doing the same thing as ASP.Net, GWT for Java -> making everything as a closed world
- think of a life-insurance smart contract? =>
- taking control of the binary formats to preserve backward compatibility -> make everything a ByteString
Revisiting yesterday's code on abort
How do we unit test validators?
- building a ValidatorCtx/ScriptContext for unit testing purpose of specific validators?
- we need some combinators to easily build a Tx that can serve as a context for a specific validator or validators to be run
The onchain and offchain contracts are alreayd too large and complicated to be properly understandable. The tests failure are extremely hard to grok because we are testing a ccomplete trace of execution, and there is not much support to unit tests validators and endpoints apparently?
- Got errors from passing the wrong datum in one contract,
Datumis an opaque type and we deserialised it in another contract so we ended up with a validation error - types are checked within the context of a single "contract"?
- How to TDD both on-chain and off-chain contracts?
Struggling to get collectcom validator passing, would passing the Redeemer from off-chain code might makes things code simpler?
- the commit validator could check the redeemer passed by the collectcom or abort contains its own output
- in order to things "in parallel", concurrency is captured by tokens being distributed to parties
- lot of ways to construct txs and validators, but not much way to test it
- if a validator is just enough, its easier to write and test
- use FOL to prove the validators? => theorem about the "context" in which the validator runs
- commits can constrain the output of the tx they are consumed
- the commit could only check that it is part of tx where the ouptut is the "right script", hence delegating trust to this script
- Wrapping up spike on writing BDD-style tests for Hydra Node(s) combined with Property-Based Testing in order to drive our design and development of the nodes
- Inigo prepared a document with multiple constructions
- Multisig glossary
- Pairing = scheme that relies on pairing means that it is not Schnorr-compatible.
- Schnorr-compatible = verification procedure of the signature is the same as the one used for Ed25519 (analogous to how extended vs non-extended keys work on mainchain)
- Commitment = a random nonce generated and shared by each participant, for every signature.
- Trade-offs regarding multi-signatures algorithms
- Interactive rounds vs non-interactive rounds (interactive = members must exchanges commitments)
- Schnorr-compatible schemes require however multiple rounds of interactions between members. So it makes the Hydra head more complicated (could be done with several rounds of broadcast 'ack')
- Pairing / Schnorr-compatibility
- Size of the signatures
- Complexity of the signature verification
- Implementation and usage of the scheme
- Schnorr-compatible scheme are more easily implemented, especially on top of libsodium.
- Interactive rounds vs non-interactive rounds (interactive = members must exchanges commitments)
- There's no way to verify cryptographic signatures in on-chain contract at the moment, but validators can verify that transactions do include some specific signatures checked by the ledger.
- Requirements from the node:
- Using Schnorr-compatible scheme is really nice / bonus
- Relying on libsodium to implement new multisig primitives is still okay
- Requiring the use of new crypto libraries is a big deal
- Musig2 seems to be a likely candidate, although it's fairly new and the security proof would have to be checked with more details.
In order to complete my ETE tests, I need to modify property checked so that it only takes care of what nodes are sending to the outside world, eg. on-chain TX for the Init and Close which should contain the final confirmed UTxO set
- Detached some components of Node from being tied to IO and instead use io-sim-classes, so that we can use IOSim runner to simulate IO
- Got stuck in the Model trying to use
runIOSimbecause theIOSimmonad requires an existentialstype parameter, eg. likeSTdoes, in order to ensure thread safety and local use, so I cannot return paramaterizedModelwith the underlying monad. Solution is probably to return some result independent of theModeldata type. - Managed to workaround the existential
sbut now I have a problem with my tests as I need to observe some results from the nodes but I cannot do that because I don't have the nodes available anymore in the outcome ofrunModel. This is actually a good thing as it highlights a flaw in the way the tests are writtent: They should depend on observed behaviour during the run and not on the the nodes which won't exist anymore at the end of the run. Next step: Transform the test and model so that it captures the on-chain transactions sent by the nodes and accumulate those in the state so that the final proeprty check is independent on having an interface over each node. TheModelis setup but still need to flesh out actual work to handle various actions, and fill in the mocks to handle inter-node and on-chain communications - At first, I can have
HydraNetworknot relay messages and only ensure theOnChainClientpropagatesInitandCloseto both nodes? - handling
NewTxis pretty straightforward, just need to issue the command to theNode, no need to care about serialization and what not as everything is in RAM - My idea is that
Initcallback should propagate the initial UTxO set to each node, andClosewill introspect the nodes to retrieve their current UTxOs and store them in the HEad State - When this error surfaces, it's kinda scary as it means I don't really understand how TX generation works:
This certainly warrants more discussions with the ledger team in order to fully understand how to use the generators
Exception thrown while showing test case: 'FatalError {fatalErrorMessage = "Should not happen as the tx is guaranteed to be valid?"}' - Interestingly, the test now triggers an
undefinedinside the Node's code proper:Exception thrown while showing test case: Prelude.undefined CallStack (from HasCallStack): error, called at libraries/base/GHC/Err.hs:79:14 in base:GHC.Err undefined, called at src/Hydra/Ledger.hs:42:25 in hydra-node-0.1.0-inplace:Hydra.Ledger - Replaced the
undefinedinLedgerwith a default value which previously was built inside theModel. I moved the corresponding function toLedgerwhere it makes sense, allowing us to "easily" build aLedgerStatefromUtxo. I now have another error from the Node:which is interesting as it points to the missing parts of theException thrown while showing test case: 'FatalError {fatalErrorMessage = "TODO: Not in OpenState"}'Node's logic! - I should also implement basic shrinking of the
Actionsin order to reduce noise in the trace and get the simplest errors first Also, the property and generator are pretty naive, which is fine as the currentModelis simple. The actions generation should be interleaved with execution and not completely produced up-front as it makes double work when it comes to defining what actions can be generated from current model's state - Simplifying the model to focus on
Init/Closelogic, making sure I can observe the initial UTXO being passed across the nodes. I should probably have done that from the get-go, and that's also probably how we should approach the building of the node: Start from a very simple transition system, maybe even one state, then add more meaningful transitions, split and refine state as mandated by the protocol and the tests - Making progress towards initialising the ledger's state with whatever comes from the on-chain client, hence simulating
Init --> CollectComsequence and properly setting the starting state of the head with the UTXO generated. The Model does not yet propagate that event but should be relatively simple to wire, then I can decomment the NewTx handling which should work out of the box (famous last words). Still facing an issue though as the failure shows I don't get any confirmedLedger from the nodes which is annoying... Will sort that out tomorrow.
-
We showcase what we did on Friday and this morning on our own
- SN did explore a "monadic" way of writing the business logic
- We like the
OpenState -> m OpenStatepart of signatures - State handling is still messy, but we think we could write helpers (similar to
mtl) - Results/errors would need to be composed quite verbosely
- We like the
- MB did draft the business logic as a DSL + interpreter
- We think it's cool but likely overkill
- Faces the same problems as other approaches
- AB did take a step back and crafted an integration test suite which works just "under the skin" of a
hydra-nodeand uses Quickcheck for generating transactions- Groups all handles into
HydraNodetype - We like the level at which this is testing as it's easy to interact with a
HydraNode, but still allows stitching multiple instances into a network (as multiple threads, connected using in-process channels or local sockets)
- Groups all handles into
- SN did explore a "monadic" way of writing the business logic
-
We revisit how
hydra-simis doing things -
Seems like a pure "reactor" function like the handleMessage in SimpleProtocolHandler is a good idea:
- It basically as 3 outcomes: either transition and send some message, wait which effectively reenqueues the event, or reject the transition
- We want to implement the Head protocol that way
-
The doubts are more: How does this interact with the "higher level" state machine, and the otehr commands that can come from various sources, incluing the init and close
-
Seems like no-one has a definitive argument on which approach is better to do this Proposed solution is to implement a dead-simple Hydra node which includes the Init -> Open -> Close logic, in a simplified way, and with proper tests, with one way of structuring the code (eg. the monadic one let's say) and evaluate how it looks like once implemented
-
This means:
- Init message comes from the "client" and sets the initial state, it also triggers on-chain message which then defines the UTxO set the head starts in
- Open state is implemented using simple protocol version (or coordinated one if it's faster) and the pure SM approach
- Close message comes form the client at any time and generates also a "fan-out" transaction with all confirmed UTxOs from the head
-
We can write high-level test observing that:
- Given some intiial UTxO set
- When we sand Init then a seqeunce of NewTx posted from either nodes
- Then we observe a fanout transaction which contains the expected UTxOs
Morning goals:
- Generate a valid tx from an existing UTxO set
- Define a Node client interface that can be called for actions
- Wire nodes using hydra-sim's fake network?
Got side-tracked into configuring emacs projectile to correctly recognize haskell-cabal project and switch between test and prod files, following https://docs.projectile.mx/projectile/projects.html
-
haskell-cabalproject type should be recognized by default : https://github.com/bbatsov/projectile/blob/master/projectile.el#L2671 because the project is a multi-packages cabal project, withcabal.projectat root of directory and not a*.cabalfile, it cannot - Interestingly,
hydra-simis recognized as anixproject type, becasue of thedefault.nixfile at the top-level, and unfortunately not as ahaskell-cabalproject - It's possible to force the project type to be recognised using
.dir-locals.elbut this seems kind of evil - Another problem is that for projectile's build and test command to work, it would need to be run within
nix-shellwhich takes a while to startup. - Entering
nix-shellinhydra-poctakes > 18s => should checknix-direnvbehaviour as this should not be the case
Trying to generate a random starting state for the ledger, which has as complex structure
- Tere exist generators for all parts though, only have to find them...
- There is a
LedgerEnvand aLedgersEnvinSTSthat differ only by the addition of an index in the former. Seems like aMemPoolis comprised of several ledgers which are somehow indexed? - Turns out the
applyTxsTransitionneeded a specific import to compile:The error message was moderately helpful even though it provided some hints about a missing instance, yet it's pretty hard to guess where the instance is or could be defined (could be in several placeS).import Shelley.Spec.Ledger.PParams (PParams' (..)) - Refactoring hydra-node to extract a workable interface for a single hydra node
-
Merged back
ledger-testbranch work intomaster-
LedgerStateis a type family indexed by the concrete ledger used
-
-
Starting mob with 20' sessions, did 5 rounds
- Wired a "real" cardano ledger into a test checking an invalid tx was actually rejected
- Refactored code to use
handleNextEventfunction without a queue, passing aClientEventand handling it down intoupdatefunction - This lead to some more
txvariable percolating all over the place, then some design discussion on how to best handle
-
Follow-up Exploration paths:
- DSL for head state logic (Matthias)
- Monadic / handles style (Sebastian)
- State-machine modelling (Arnaud)
-
What to implement to be "represensative enough"?
- Init:
- Main state transition from Init to Open
- NewTx:
- Validate tx
- Needs feedback to client
- Modifies the ledger state
- ReqTx:
- Wait for tx on the confirmed ledger
- Confirms tx directly (no intermediate 'seen' ledger)
- Init:
-
Revisiting "story board"
- greening some stuff around contracts writing
- we are not green on tx observing because we want to really wire it in the HN
- interleaved dependencies between Plutus and us, because if we want to support contracts in Heads, we need:
- to be able to validate those txs
- expose an API for clients to submit txs w/ contracts, possibly in a way that they believe it's a cardano node
- still unsure about how to validate UTXO sets on-chain -> we need to write a fan-out contract/validator
- we might want to limit the size of the state in the head and reject TXs that make it grow too large
- Networking?
- Using Ouroboros/cardano-node directly to channel txs between nodes?
- Use PTP using simple "sockets"
- Minutes from Plutus Q&A developers meeting: https://docs.google.com/document/d/1pxDwuFfAHBsd9BKGm0sILHASXVHqGL1uZjlOyh73qnw/edit
- Implemented basic CI based on GitHub actions
-
This gist seems promising as it referenced
haskell.nixand IOHK's infrastructure, but it's a bit outdatted. Workflow failed at nix installation and referenced some issues aboutACTIONS_ALLOW_UNSECURE_COMMANDS, which led to this page but this is caused by the versions of actions used being old- Upgraded cachix action: https://github.com/marketplace/actions/cachix
- Tried defining
default.nixto be able to runnix-build -A hydra-pocbut it built way too much stuff, I reverted to usenix-shell --run ...just like I do in Dev VM - Generated a new auth token for https://hydra-node.cachix.org to be used by Github, then set the secret in the repository's
secretssection: https://github.com/input-output-hk/hydra-poc/settings/secrets/actions - Using https://markkarpov.com/post/github-actions-for-haskell-ci.html for configuring Haskell cache, also https://github.com/actions/cache/blob/main/examples.md#haskell---cabal is useful as reference on how to setup cache for Haskell
- With cabal caching setup, build time dropped from 40 to 5-6 minutes
-
This gist seems promising as it referenced
What did the team achieve this week?
- Explore the code architecture and how we would write the prototype business logic
- Draft some command line interface (REPL) to play with it
- Discuss ledger integration in the engineering meeting
- Create a smoke test using a MaryTest ledger
What are the main goals to achieve next week?
- Reflect on the three approaches in writing Hydra logic and pick one for the prototype
- Discuss multi-sig cryptography (incl. next steps on that) in the engineering meeting
- Have a walking skeleton executable with stubbed / simulated communication paths
- Started "mobbing" on ledger-test branch following some cleanup work by SN
- the goal was to write tests (and code) to expose the ledger's interface from the POV of the Hydra Node, as client requests (and possibly other messages) come in and requires interaction with the ledger for validating/applying TXs
- We started with
newTxwhich is the "first" place where we need to validate/apply a TX- First test was fine as we did not need a concrete TX representation
- Second test led us into a compiler errors fixing rabbit hole once we realised we needed to parameterize the Head with the transaction or ledger type and only make it concrete at the last moment, eg. in the
mainor in the tests. - Turned out sprinkling
txall over the place and having some handle to hide the concretevalidateTxhidden in theHeadStatewas not good
- After 2 overran cuckoos, we stopped and reflected:
- We should have stopped when the tests need changes because of missing
ShowEqhandles - It's easy to lose track of timn when piloting and in a rabbit hole
- Questioning mocking strategy when it comes to the ledger as it seemed to have adversarial effects
- We should have stopped when the tests need changes because of missing
- Some interesting takeaways:
- We need to take smaller steps and rotate the keyboard more often to give everyone the opportunity to take a step back and think about what's going on
- Actually, the "best" and "most important" position in an Ensemble (or Mob) programming setting is the Navigator role: One does not have the keyboard so is free to focus on the meaning and the big picture. Having the navigator(s) get lost in the weeds of details of typing and fixing compiler errors is a smell
- When in Pilot role it's very easy to get lost and frantically try to fix things
- We should probably stick to smaller coding slices, eg. 15 minutes instead of 25
- Also, discussing design from gathered insights while coding together:
- We don't want the
handleNextEventfunction, or top-level "reactor" to be tied to a queue, abstracting away from the various "handles" it depends on to do its job, this function should really just beEvent -> m [Result] - There will be some queuing at the limits of the system, eg. to handle received messages from other Nodes or Mainchain
- The client will access the
handleEventfunction directly and retrieves some feedback about what's been done - The inner "pure" core will really express what needs to be done given some state and some event, and the outer "inmpure" shell will act on this by eg. dispatching messages to relevant interfaces
- We don't want the
Made the tests compile and run without too much changes from what we did together:
- reverted back to using
EventQueuein thehandleNextEventfunction - sprinkling Show and Eq worked fine
- Kept the
Ledgerhandle which probably is not super useful - Use
MockLedgerandMockTxto mock the ledger's interface from the Hydra head/node
- Matthias introduces the new component diagram and kicks off some of our questions
- Quick discussion about the setup logic component separation interleaved
- Ledger being a black box / parameterized by Ledger?
- Consensus is also done that way
- Caution: If not easy, maybe not worth it.
- We abstract it away, maybe using parametric polymorphism or just by discipline -> to keep it replacable.
- Benefit: Be explicit what we require (from the ledger, from txs, ...)
- Consistency between chain and the ledger
- Run hydra in hydra / inception note
- Be able to run same contract on hydra as on chain
- Make sure the logic matches
- Does the hydra node (or contracts validated in it!) need to introspect transactions?
- 95% no, but some exceptions
- time -> validity ranges
- fees? killing isomorphism?
- Could create synthetic fee inputs in the ledger state?
- Related: check whether scripts see fee inputs.
- Have different fees via protocol parameters? - does this not cause a problem with the PP hash?
- Related to the plutus cost model
- Do we want to hide anything to plutus scripts to make Hydra possible?
- Shall we merge inputs to plutus?
- -> Talk to michael
- 95% no, but some exceptions
- What subset of ledger rules applies in a Hydra head?
- No Certificates
- No governance operations
- No withdrawals
- (Transaction metadata needs to be preserved)
- (Minting: should be possible, but maybe a protocol problem? maybe not all monetary policies? similar to contract not commit-able limitation)
- How should we integrate the ledger into our project?
- Ledger provides an API we should use
- Similar to the Mempool API
- Responsibility that it's consistent with main chain is on the ledger side
- Observation: Transactions are in more validation states in a hydra head -> different to the ledger on the main chain
- Ordering is not total / not fully sequentialized -> sets of transactions vs. contiguous
- Ledger relies on ordering (mempool is ordered)
- Mempool does revalidate and is re-filtered occasionally
- Conflict resolution
- Obituary set based on validity ranges (easter protocol)
- (None of these is affecting the coordinated protocol variant; But maybe already relevant architecturally)
- Ordering is not total / not fully sequentialized -> sets of transactions vs. contiguous
- Finishing writing a proper
README.mdfor Haskell Dev VM machine on IOHK's GCP project - Started implementing a
HydraModelfollowing Plutus tutorial from: https://docs.cardano.org/projects/plutus/en/latest/plutus/tutorials/contract-testing.html-
ContractInstanceSpecis a data family that's used to build the list of contract instances that will be part of the test. In our case, all parties are supposed to be equivalent so we need a single type that will use a single schema andContractendpoints - Rest of the code seems relatively straightforward: define valid transitions, provide
preconditionfor uninteresting actions - There is
Specmonad whose name unfortunately conflates with hspec's ownSpecthing -
nextStatemethod is used to provide specification for transitions (actions) at some state
-
- Coding with MB to complete Hydra SM:
- We could have 2 endpoints for committing:
- 1 endpoint
committhat takes a UTXO - 1 endpoint
commitSomeValuethat takes a value and creates the needed UTXO
- 1 endpoint
- How to extend the
Openstate to contain the UTXO set. See https://input-output-rnd.slack.com/archives/C21UF2WVC/p1618327948196800 for a discussion on the topic in#plutusSlack's channel. The issue is more at a testing level: How can we observe the changed Open state from the "outside", e.g once theEmulatorTracegot executed? - Answer is that one needs to:
- use
assertAccumStateto be able to check some part of the Observable state of a contract's instance (contract + wallet) - This "state" can be updated in a
Contractby usingtelleffect (Writermonad). The type of the writer is the first argument toContract - It's straightforward to set to a
[HydraState](we need a monoid) and then usetellin a client after we observe the confirmation of a transaction to have the state observable off-chain from the emulator's trace (and possibly from clients too)
- use
- We could have 2 endpoints for committing:
collectCom ::
(AsContractError e) =>
MonetaryPolicy ->
[PubKeyHash] ->
Contract [OnChain.HydraState] Schema e ()
collectCom policy vks = do
...
tell [mkOpenState committed]
-
Call between AB and SN to discuss what we created the last two days
- Reconsidering the "client commands as events" approach as it would force us more into supporting that asynchronous interaction model (which may be good?)
- Discussing how the client would "query" the head state using a "whatnext" example (which eventually would present possible client commands?)
- Drafted a
HydraHeadQuerysub-handle to have a more constraint functionwhatNextwhich needs access to theHydraStatebut obviously should not modify it - Verdict: It's more about how we want to structure our business logic -> let's have a full-team discussion on this
-
SN: re-visited some exception handling resources and draft an error handling coding standard -> to be discussed
- Plutus Q&A Dev Call #019 (Jimmy and Colin Hobbins from Obsidian)
- Talked about Plutus pioneers, producing lectures
- https://github.com/input-output-hk/plutus-starter provides a starter kit containers to isntall and configure stuff, others prefer nix
- In case of pbs, people should post issues in plutus main repo (https://github.com/input-output-hk/plutus)
- Plutus is a moving target, engineers are busy working on it
- Marlowe -> making use of PAB
- "Haskell is the best imperative programming language" ???
- "Why Haskell?"
- SCs have access to limited information, constrained interactions with the world => good match for pure FP language dealing with money -> take that pretty seriously, learning is steep but seems to payoff
- Haskell community is happy to answer questions
- Haskell is different, but once it's structured correctly it does eliminate certain kinds of bugs ??
- https://github.com/input-output-hk/plutus-pioneer-program has links to training and showcases videos
- Marlowe is made for financial engineers, not good for arbitrary apps
- "Alternatives to Haskell?"
- Plutus does not requrie the SCs to be written in Haskell, nothing Haskell specific in the VM
- one can write a new plutus compiler IELE VM running on sidechain, similar to LLVM: https://developers.cardano.org/en/virtual-machines/iele/about/the-iele-virtual-machine/
- Q: On-chain vs. off-chain activity?
-
Exploring a bit further the overall Hydra node application architecture. The original idea was to model every interaction with the outside world as events (client commands, on chain events, hydra events). However, I (Matthias) felt a bit uneasy with having client commands as events: having an extra indirection and queue felt wrong and makes error handling unpractical / difficult. Client commands are very much more of the request/response kind, and clients would expect to know whether a command succeeded or failed. Unlike other events from on-chain transactions or, from Hydra peers for which not responding (at least immediately) isn't a problem. The latter are observable by peers (and the user) through events generated as result and application state changes. So even though modelling everything as events is appealing from an external perspective (makes testing more uniform), it feels awkward when writing the actual application logic and it makes error handling difficult.
-
We've tried therefore to keep the core logic "pure pure", and moved the client commands as actions using the various handles to drive the application. This creates a top-level interface for driving the Hydra application which can be used by various type of clients (command-line, http server, etc ...) that is also relatively easy to test (by mocking the handles). Still remains however another logical unit to process events from the hydra network or from the chain.
-
For more fun, we've also attempted to consider error handling in this setup and distinguished between two types of errors:
- Business logic / client errors (i.e. when a client try to make an action that is impossible in the given state)
- Outside-world effects errors (e.g. failing to broadcast a transaction because of network connectivity issues)
For the former, we want explicit error handling and error passing using Either / MonadError / ExceptT. For the latter, we opted for using exceptions, thrown directly in the code creating the handle so that consumer downstream do not have to worry about those exceptions. For some errors, it would be possible to define handles on top of handles to provide additional exception handling behavior (e.g. retrying on network error), without having to change anything in the business logic.
- AB is off today
- After a quick discussion, we started to detail the
runHydraProtocolfunction of theHydra.Model - We identify a similarity to the Elm architecture
- Some parts of our logic might not lead to any outputs, but only a subset of its
- We name the former
Outputs asEffects - We pick the Head protocol itself as such a subset and try to enumerate the
State,EventandEffecttypes of this "sub-module" using the pseudo code of the paper ->Hydra.Logic.SimpleHeadmodule-
requireleads to "stopping execution" of a routine -> can dropEvent - but
waitrequires some kind of "re-schedule" until a condition holds -> interesting to model that into our pure function
-
- Copy types and create an overall
Hydra.Logicmodule with the centralupdate :: State -> Event -> (State, [Effect])function - We discuss that there likely is more "context" required, i.e. an additional
Envargument (like a Reader) - We try-out and debate about various ways of composing the main logic, especially when interleaving the "head logic" with "overal opening / closing logic"
- AB presented some architectural drawings based on C4 Model of Software Architecture, then "heated" discussions ensued. Some takeaways from the discussion:
- System View highlights the fact the roles for operating a Hydra system, operating a Head and using a Head to do some transactions are different, even though of course they could be fulfilled by a single entity
-
Containers View
- Having additional containers beyond
Hydra Nodeseems YAGNI. There is no convincing argument to build those now so we'll let those emerge from incremental evolution of the Hydra node, if need be - Even having PAB as a separate container is debatable. It probably makes sense right now as it is the way it's packaged but it could as well be embeded inside the node itself
- Messaging Middleware technology is unknown, but we would like the Hydra node to be pretty much agnostic about which messaging platform it uses to talk to other Hydra nodes as long as it provides pub/sub and PTP capabilities
- Having additional containers beyond
- We updated Components view merging things that seemed relevant from the proposed one, which lead to the following insights:
-
Ledgershould be an opaque component that's used for validating TX -
Setup logicis separate fromHead Protocollogic, as it really allows the latter to create a Head instance. It could also be provided externally, by another tool, and does not need to be built up-front -
LoggingandMonitoringare cross-cutting concerns that are pervasive in all components - The
Cryptographycomponent has a shared dependency with theCardano nodeon cryptography primitives
-
- Archived our old Components View of Hydra node following architectural discussion
- We did an impromptu retrospective
- Where do UTXOs to be committed are coming from?
- Your own pay-to-pub-key UTxO
- A Daedalus extension for Hydra with "Commit to Head" or "Pay to Head" comes to mind
- Generally speaking you cannot push any arbitrary ongoing contract, because it would change the datum.
- In some special cases, for example, if a contract involves all the members of the head and have the ability to be somewhat committed to the head may be committed to the head.
- Where the funds come from is however really a product / user question which is yet to define. Some use-cases:
- A large exchange or bank for internal operations.
- A consortium of financial institutions which don't necessarily fully trust each others.
- Custodians managing funds on the behalf of some users.
- Typically, when using the PAB the UTxO to commit will belong to the wallet attached to the PAB.
- Having a "Hydra wallet" (e.g. in daedalus) to which funds need to be moved for use with hydra was given as example
- Manuel: "You are going to have a wallet anyway, so why not use it?"
- Script UTXOs could be given as parameters to commit (the system would need to figure out how to unlock them then?)
- What about external handling, "finalizing" commit txs externally?
- Ex- and import of unbalanced txs thinkable
- But, in order to have committed funds usable in the hydra contract, the "external party" would need to know the script's address and update the datum accordingly, i.e. involves Hydra-specific knowledge -> infeasible
- Instead, locking funds up-front (using whatever wallet) into a staging script which may then commit those funds into a hydra head (may time out) -> side-loading
- A custodian contract could be built upon the side-loading concept
Some simulation results for various configurations. All nodes are located in same DC so internode latency is minimal.
| # nodes | # tx/node | Bandwidth (kbp/s) | Avg. confirmation (s) | tps | Simulation time |
|---|---|---|---|---|---|
| 5 | 500 | 800 | 0.88 | 279 | |
| 10 | 200 | 800 | 1.9 | 255 | |
| 20 | 100 | 800 | 3.5 | 241 | |
| 20 | 200 | 2000 | 1.58 | 563 | |
| 50 | 100 | 800 | 9.7 | 228 | |
| 100 | 200 | 2000 | 8.6 | 522 | 175 min |
- Definitely the bandwidth has an impact on confirmation time. Is the simulation realistic in having the same bandwidth limitation per node whatever the topology of the network may be?
- The contention in the network at each node is taken into account in the hydra-sim model: For each message sent or received, there is an additional delay that's dependent on the
mpWriteCapacityormpReadCapacityof the node, which is configured by theNode'snodeNetworkCapacity.
- The contention in the network at each node is taken into account in the hydra-sim model: For each message sent or received, there is an additional delay that's dependent on the
- Within a single DC nodes are interconnected through switches which have a limited bandwidth, which is different depending on the location of the nodes (See https://arxiv.org/pdf/1712.03530.pdf for a thorough overview of network traffic in DCs):
- Top-of-Rack switches connect all nodes in the same rack
- Aggregation switches interconnect some racks
- Core or Spine switches interconnect a group of Aggregation switches This means the overall available bandwidth in a network of nodes is capped somewhere in the network.
- However, 20 nodes x 2Mb/s = 40 Mb/s traffic maximum which is way below the capacities of a ToR (several 10s of Gb/s), so from a practical standpoint, it seems like the bandwitdh needs of even a large number of Hydra heads will be modest when compared to modern DCs capabilities.
- Would be interesting however to compute and factor in the inter-DCs bandwidth as some limitations in the model?
- Noticed the execution time for the 100 nodes simulation is huge. Simulation code is run in
IOSimpure monad so it's single-threaded. We can get multithreaded code by running the simulation in IO but then we lose the trace recording. Could we run it usingIOand still get a recording of the traces? This would require a specific interpreter, possibly usingParmonad to distribute pure computations across cores, which seems kind of odd as IOSim is simulating concurrent execution of multiple threads.
- Set off by looking into the ledger specs, finding a function which could be used for our
validateTx/applyTx: The type classShelley.Spec.Ledger.API.Mempool.ApplyTxand more specificallyapplyTxsTransitionseems suitable - Created a new module in
hydra-nodeand try to implementvalidateTxusing theLedger.applyTxsTransition - Wrestled with cabal dependencies and picking source-repository hashes
- Pulled in Nicholas Clarke the the call from #ledger
- Quickly introduced Hydra and that we should have him on a future Engineering Meeting
- Roughly discussed some likely limitations of the ledger when used in Hydra, e.g. Delegation certs, Withdrawals
- Depending on whether we need a "custom subset" of the ledger, a Hydra-specific API (similar to that
Mempoolmodule) would be possible - 2-phase validation as used for Alonzo will likely change the interface; isValidated flag; who is setting this? "when is the smart contract run?" needs to be defined for Hydra
- We used the cardano-node tag
1.26.1and all its dependency hashes and madeHydra.Ledgercompile - Next step: write tests for
validateTxand obviously parameterize it; Where to get theTxfrom? - Also, we reduced scariness of tx validation without Plutus to orange
- Completed my own personal experiment with Plutus and baking the Init/Commits/CollectCom dance into contracts
- I went down the route of having 2 contracts/validators:
- one representing the
ν_comvalidator from the paper which is used to discriminate the transactions of interest thatcollectComwill indeed collect - the other one for the whole Hydra OCV state machine
- one representing the
- It's pretty hard to wrap one's head around the programming model, and to keep clear what should be posted and where, what to verify...
- Managed to work around the SM's limitation preventing adding
ScriptLookupselement to the transition being posted. This is necessary to make sure the transaction can consume other outputs and "run" validator scripts - Plutus has proper support for model-based testing using QC which is great. Next step would be to start writing a proper model of the OCV part of the Hydra head and use that to drive the tests and the development. Could be actually relevant to use the hydra-sim for that, and write the model there for proper validation from the R&D Team.
- Code is available on a personal branch https://github.com/input-output-hk/hydra-poc/tree/abailly-iohk/commit-collectCom
- Discuss the Plutus Application Backend / Framework, when will it be available?
- There are two things, the EUTXO (Alonzo) Cardano node and the Plutus framework
- The former is a hard dependency, while around the latter we could work around in the worst case
- Start discussing commit user experience / usecase (UML) diagrams
- First dive into comitting script outputs, how this would work
- Any component really which can spend a script output (wallet, plutus client?) would need to add that input + witness (redeemer) to "our" commit tx draft
- Observation: At least
Plutus.Statemachinescript outputs would not be able to be committed to a head, because they restrict the address used for tx outputs.
- When focusing back onto the two depicted scenarios, we struggle with the viewpoint of such diagrams; maybe a more concrete example use case (not to confuse with the diagram name) would help
- First dive into comitting script outputs, how this would work
- We reach out to Charles and product management about product guidance and opening a stage for discussing expectations on how hydra would be used
- Updated story map
- Constructing protocol transactions per se is well understood now (given we would use the PAB) -> managed/internal scenario; This would also go well with the sequential committing on-chain state machine
- Added a postit for constructing unmanaged/external commit transactions
- Increased risk of the off-chain tx validation / ledger integration as we want to explore this area next (but do not expect too much problems)
- Started working on the implementation of the sequential version of the
committransactions - We stopped at the point of setting up the transactions in such a way the poster defines which UTxOs are committed to the Hydra head
- A heated debate ensued on how to create and define those
committransactions - We parted ways with the goal of spending time on Monday together to settle the debate, based on individual experiments and elements:
- Possible use cases we can imagine
- Coding trials
- Design proposals
- Still figuring out how to spin up Dev VMs on IOG's GCP instance. I am missing some permissions related to service accounts and storage access, notably. Requested them from Charles Morgan
- Started scribbling some boxes-and-arrows diagrams and coding Hydra SM with commits separated from the main SM
- Idea is to provide a specific contract and endpoint to create 2 (or possibly more) transactions: 1 to inject some value from the wallet and create a UTxO, the other to create the commit transaction itself
- It seems the PTs are not actually necessary, but there must be a way to uniquely identify the Head instance in order for the SM to make progress with the right set of transactions
-
Continued our discussion about what 'instances' are and whether and how the Game contract is flawed
-
Added
setupandinitendpoints to ourContractStatemachineto investigate how the participation tokens could be forged -
Created test cases to inspect tx's values and assert number of participation tokens being present
-
When trying to satisy the test, it seems like the
StateMachineabstraction does not allow to emitTxConstraintwhich result in forging of new tokens- After a quick discussion with Manuel, we came to the conclusion that extending the library to cater for the general concept of concurrent transitions / transactions is likely required for a holistic take on this
- Just doing the commit in a sequential fashion is likely also something we can do (to start with)
-
Discussed state of the Hydra roadmap:
- Assuming Plutus and PAB means more stuff on the board is less scary: HN to CN communications, reacting to TX
- Also, PAB assumes some deployment environment and available resources, eg. a wallet, a connection to a node, chain indexa nad metadata services... This simplifies other things we thought we would need like TX signing and balancing, fees payment (at least the actual payment, not the policy or reward scheme)
- Some stuff we are going to experiment with on our own (yellow stickies on the board):
- Coordinated protocol in simulator
- plumbing of the PAB inside an application
- Enhacing Plutus SM framework with MP creation or even parallel transitions
How could we embed PAB in another system/application?
- Jann provided an example for Marlowe: https://github.com/input-output-hk/plutus/pull/2889/commits/7cc843bc7d17bfe95a54a372155d3f4560d7bb5b
We can probably embed it, ie. use it as a library and call haskell functions and not expose the API: The
runServerfunction is just anEffect, or rather a stack of effects. - It would also make sense to keep it as a separate service or component and have the
hydra-nodetalk to it through a REST API. In the long run, this will ensure we keep both "contexts" decoupled: The context of the Hydra (Head or other) protocols, and the context of On-chain state machine handling.
Started discussion and work to recreate my development VM on IOG's GCP account:
- Infra admins created project
iog-hydraon IOHK's organisational account in GCP to which I have some limited access Currently stuck because of the lack of permissions... waiting for the admins to unlock access to next level
- Ad-hoc reschedule in our Agenda because Jann is running late
- We showed our Contract experiments in plutus playground and test suites
- Touched on some questions around PlutusTx and how to find out about max size
- cost model is still in flux
- relative comparison with e.g. Marlow examples as a baseline would make sense though
- tx size is likely not changing much, maybe 2x
- Jann joined and we gave a quick overview about the architecture and the Hydra head protocol
- Question: Use the Plutus Application Backend for our "Chain client" component or not? (Option a, b from agenda)
- rather use whats there, but only if it fits our requirements
- Plutus team is currently creating a way to run the PAB in a specialized way, i.e. running a single contract
- Marlow is in a similar situation
- The PAB would provide an HTTP+Websockets API which we could use
- Option c from agenda is likely infeasible
- rollbacks, keeping state in sync between offchain/onchain is hard
- Each contract instance is connected to a wallet, e.g. to balance transactions
- Continued discussion about wallets
- dedicated Hydra wallet
- not wanting to depend on a wallet
- ability to pay fees "from a hydra head"
- fees need to be payed by public key UTXOs?
-
Looking into the source code for Plutus' State-machine, noting a few interesting points:
- Seems like a given state machine can only be run once at a time. This conclusion is drawn from three aspects:
- There's a default 'stateChooser' which determines in which state is the SM. That chooser is quite naive and only succeeds when there's only one state to chose from.
- To determine states to chose from, the code does lookup all UTxO at the contract address, which it then pass on to the state chooser.
- Since there are no parameters to the SM contract, the script address is 'constant' and therefore, all state machines running via this contract share the same address.
- Also, the implementation forces all state-machine transaction to be single-output transactions only.
- Rest of the code is mostly about boilerplate, but doesn't really do anything complicated. Somewhat useful yet also easily done.
- Seems like a given state machine can only be run once at a time. This conclusion is drawn from three aspects:
-
Looking into how tx looks like in Alonzo
- TxOut are exended to now contain a datum hash. That is, an output is a product type: (Addr, Value, Datum hash)
- Transaction witnesses can now include new types of witnesses:
- Datum
- Contract Script
- Redeemer pointers (?)
- Some notes from the alonzo specifications:
- "Scripts and datum objects are referred to explicitly via their hashes, which are included in the UTxO or the transaction. Thus, they can be looked up in the transaction without any key in the data structure."
- "We use a reverse pointer approach and index the redeemer by a pointer to the item for which it will be used."
-
I've asked on slack some clarification about what the heck are redeemer pointers ^.^ https://input-output-rnd.slack.com/archives/CCRB7BU8Y/p1617810165239200
Investigating Plutus, "How to get our hands on a tx?", Two avenues:
-
test predicates can assert txs:
- assertions are done on a folded stream of
EmulatorEvents -
validatedTransactionsdoes extractTxnValidate :: ChainEvent - wallet emulator creates such events when processing blocks from a tx pool
-
handleChaindoes add txs to that pool onQueueTx :: ChainEffect - where are
PublishTxeffects emitted?
- assertions are done on a folded stream of
-
plutus application backend does send txs to wallet/node:
- mocked and real chain client implementations for
PublishTx :: NodeClientEffectusequeueTx -
makeEffect ''NodeClientEffectgenerates apublishTx(this TH function is used in multiple places) -
handleWalletre-interpretsSubmitTxnusingpublishTx -
submitTxnis used bysignTxAndSubmit, fromhandleTx, fromhandlePendingTransactions - that function is ultimately used from either the
Plutus.Contract.Trace.handlePendingTransactionsor from thePAB.Core.ContractInstance.processWriteTxRequests
- mocked and real chain client implementations for
Both scenarios kind of handle the WriteTx contract effect, which is somehow
provided by the Contract using some row-type black magic (HasWriteTx)
generic input/output facility
-
Michael provided some answer to our issue with contract's types not being compiled correctly: We need to add
-fno-strictnessas a GHC options to prevent strictness analysis of the code. As I understand it from Michael's explanations, strictness analysis leads the compiler toturn some of your tuples into unboxed tuples for you if it can prove they're used strictly It should probably be enabled selectively and globally on the project as I did it.
-
Extracted
Hydra.Contract.Typesto its own module inplutuspackage, but it should probably move up the dependency chain and be part of ahydra-corepackage or something as it exposes types which are relevant for both on- and off-chain parts of Hydra protocol. -
Just discovered one can expand TH splices using lsp-mode which provides some insights in the errors given by the plugin: In Emacs:
(use-package lsp-treemacs :ensure t)then type
s-l g eet voilà -
Had a look at the
IOSimmonad from io-sim which maintains a state of all the threads and concurrency related stuff (like TVar, MVar and the like) andrecords a trace of this state changes over time, as IO actions are evaluated.
- Discussed next Engineering meeting's agenda which will be focused on Plutus and how to structure Hydra node in order to take most advantage of it.
- How can we integrate Plutus contracts into our system? i.e. how can we post hydra (mainchain statemachine) txs onto the chain?
- use the plutus application backend "as a client"
- use plutus as a library to construct txs (like the playground) and submit them on our own
- construct txs by hand and just use plutus to compile scripts
- Would it make sense of us being Plutus Pioneers?
- What factors are relevant to what can be computed "in a contract" or when is a "builtin" required?
- What's possible to implement, what's impossible?
- How can we find out the size and cost of a transaction is?
- Our computing examples: Multi-signature verification, merkle-patricia trees, UTXO processing
- How to represent the hydra UTXO set to process it reasonably efficient (e.g. in the "fanout" transaction)? -> Is the Merkle-Patricia-Trees magic efficient enough to use in the fanout validator?
- How can we use other modules in contract code? We failed to move type definitions (for sharing with offchain code).
- (Is there a way to emulate a plutus-enabled ledger until there is a plutus-enabled cardano node?)
- How can we integrate Plutus contracts into our system? i.e. how can we post hydra (mainchain statemachine) txs onto the chain?
- Discussion about how to deal with work done by a single dev, and how to keep everyone in the team aligned?
- Rule 1: Code can go directly into "production" repository when produced by at least 2/3rd of the team
- Rule 2: It's fine to code and experiment on one's own, but this code should be presented and reviewed by the team in a mob session before integration into "production"
We plan to continue investigating how to build a valid Init transaction, following up on yesterday's work:
-
Verify the State token UTxO. This implies checking the contract's address and the well-formedness of the
Datum -
Verify there is an input that's consumed to produce the monetary policy id
-
There is a dependency on the Plutus contract's code as we want to ensure we encode the right script reference, which means building an address from the script's address
-
We tried to avoid depending directly on
Plutustypes and build our own simpler structures forTransaction,TransactionOutput,MonetaryPolicyId... We provide conversion functions to translate from one layer to the other -
The
OnChainTransactionmodule and logic should probably not depend on Plutus-specific types and build an "abstract" transaction that will be made concrete in the module responsible for actually posting the transaction on the wire.- Idea for next week: Provide this "concrete" mainchain handler in the form of a handle that we can stub/mock, and test one that generates realistic alonzo transactions (using Plutus infrastructure to build/check it?)
- Did some refactoring from the morning session:
- Extracted various modules to have a somewhat cleaner and clearer dependency structure (still not perfect as Plutus is still used where it shouldn't)
- Separated transaction building test from the node's ETE tests
- Turn those tests into a QuickCheck property in order to cover more parameters (even though those are quite dummy right now)
- I tried to generate coverage information from the tests execution but failed, will have a look next week
Goal:
-
"Start" a node with list of peer's public keys
-
Send Init command from "client"
-
Check we create Init transaction with PTs and outputs for peers to post their commit transactions
-
The explanations about the SM in the Hydra paper is quite unclear or awkwardly explained in the paper: The "output" corresponding to the CEM execution is always left implicit in the transactions description. Perhaps we should find a better way to visualise those?
-
We should not care about the complications of the ledger, like certifications, or withdrawals, or specific structure of transaction for backward compatibility with Cardano network eras. Plus, some stuff is simply impossible inside Hydra Head protocol like withdrawals. This implies having our own
Transactiontype and own UTXO -
While checking the details of outputs for peers, we stumble upon the issue of where does the
cidcomes from? This leads to quick discussion with research team (see below) -
We managed to write a test case validating uniqueness of PTs and this lead us to interesting insights on the on-chain behaviou: there is some "Step 0" transaction to be posted that initialises the MP script with a unique value by creating a dedicated UTXO
- We don't know exactly what the monetary policy shoudl contain, we don't have enough experience with Plutus smart contracts yet
There is an example in Plutus use cases for forging currency
- the
Currencyparameter is not passed in the transaction that forges the tokens, but is used to create theContractitself - the contract does not implement burning of tokens forged
- There are 2 steps in the forging: one step where we create a unique UTXO which is consumable by the monetary script, another step to actual forge the currency, consuming the unique UTXO. There can be multipe pairs of txs to instantiate contract
- Each validation script gets a
TxInfowhich contains allDatums from all UTXOs consumed by the transaction which the input is part of
- the
- The SM should do automatically the handling of the MP script
- Some constraints on MP script from the paper:
- there is a new MP for every head, so probably makes sense to have hash of a nonce
- we could hash the pub keys of members but they might reuse keys across head instances
- Forging only can happen on the Initial transaction, hence: There must be a hardcoded UTXO to be spent/consumed by the Initial tx and validated by MP script (see
Currencyexample)- no 2 UTXOs with same TX hash can happen, so the CID can be the Transaction Id of the consumed UTXO
- SM token is also forged in this initial transaction and its behaviour is similar to how MP is used to forge participant tokens
- There was a decision to keep PT and ST separate but we could use the same MP, forge n+1 PTs where the first one is used as ST for the SM
- Concept of Forwarding MP script: The SM validator could do everything the MP script does
- But: MP would be more involved in the future as we could forge new PTs for adding members
- Haskell types are slightly different for both scripts in Plutus: A MP script does not have a redeemer argument whereas validator has one
- We could use same script for both, with different arguments passed -> if redeemer is
Nothingwe are in MP mode - This is all contingent on decisions from ledger team which are still being discussed
- We could use same script for both, with different arguments passed -> if redeemer is
- Burning should also control it's part of the correct SM
- Created a first property test in hydra-sim to assert all transactions are confirmed in the Simple protocol
- I tried to express a property for snapshots but there are not guarantees in this case, so it's hard to express something interesting.
However, asserting all transactions are confirmed in snapshots could be an interesting property for hte
Coordinated protocolcase, which I plan to tackle tomorrow afternoon.
- Quickly going over the protocol flow examples, mainly discussion the coordinated flavor
- Does the snapshot leader / coordinator rotate? -> yes
- Coordinated protocol is less performant, but still much faster than main chain
- The leader sends hashes of picked transactions to all other parties
- They then do apply them to a local state
- And only keep valid transactions (but check whether things are really conflicting if not included in Sn)
- How do (honest) conflicts result? Two common classes
- Put funds in an output where the pre-image is guessed (Game example)
- State machine with multiple drivers / possible transitions
- Is conflict resolution just to avoid closing heads?
- Yes, but it's not a rare event (see above)
- Manuel: conflict resolution is more important than speed
- Matthias: it better fulfills the claim of "what you can run on the mainchain, you can run in hydra"
- The "easter" protocol is likely also a required for conflict resolution
- All of the specified protocols are safe, it's only a matter of liveness!
- Matthias: Will there be a specification?
- We are making ad-hoc changes
- How will be able to re-prove the properties by researchers?
- Implementing it as clear as possible, and also in the hydra sim can provide a basis for the researchers' formalism.
Did some refactoring on hydra-sim in order to prepare implementation of more protocols:
- The trace records all "events" happening on all nodes, would be interesting to visualise what's happening in the nodes and threads using something like splot. It's unfortunate the library is not maintained anymore but there are probably useful replacements
- Separated library code and executable, exposing a
runSimulationfunction that runs list of nodes according to someOptions - Wrote a first "integtration" test checking all transactions are actually confirmed, which is just a scaffolding for more interesting tests and potentially generating various inputs in order to assert useful properties
Having a quick look at Marlowe DSL for financial contracts. I am a bit disappointed as it seems the language is less powerful than the one from Composing Contracts.
- Discussing versions of the Head protocol as pictured on Miro
- Some questions for next engineering meeting:
- What are the variations and what are the security implications?
- What version to include in our first prototype?
- Details about the protocols: Rotating leader? Sensitivity to time between snaps/txs?
- Names of (versions of) Head protocol are confusing, how about:
- Vanilla
- Vanilla with Conflict Resolution
- Coordinated
- It could be a good idea to use the existing hydra-sim codebase to implement various versions of the protocol in the simulation, and check which ones are "bettter" for various use cases, varying parameters like TX size, UTXO size...
- Continuing yesterday's work on implementing our (simple) contracts using Plutus' StateMachine framework
- When extracting common types and functions to own module, we got hit with Plutus compilation error:
GHC Core to PLC plugin: E042:Error: Unsupported feature: Kind: * -> * -> TYPE ('GHC.Types.TupleRep '[ 'GHC.Types.LiftedRep, 'GHC.Types.LiftedRep]) - Trying to add more pragmas as per Troubleshooting section did not help
- We ended copying the types inside both contract modules
- We had the same tests passing for both the plain and the SM version, and it also worked in the playground with some adjustments. We spent some time trying to log the transactions "run" by the framework's emulator in our unit tests, trying to use
txpredicate but it did not work: The predicate failed even though our filtering function always returnedTrue.
Wrapping-up:
- We implemented the state machine for a simple transition and it's better than the default implementation of contracts, in the sense that it maps nicely to our model
- Current SM model in Plutus does not work for "parallel" execution, so won't work for our
committransactions We could do it round-robin for now - We can try implementing the
Collectcomtransaction and the commmit sequence - We also could check how to actually implement the fanout
-
SN: Written the monthly report and put on confluence here
-
Looked up some information about Merkle trees, Patricia tries and Merkle-Patricia trees
- References
- Merkle Trees
- A data-structure for efficiently storing a tree-like hierarchy of hashes. Each node contains a hash of its children (consequently, changing one bit of data in a children changes also all parent hashes). In essence, a key-value store with an integrity check.
- Allows for efficiently storing values where keys are hashes (with a potentially large / infinite domain). The tree-like approach allows for only allocating space for values that need to be stored in a quite efficient manner (the more keys are added, the more efficient the structure becomes)
- Hashes represent paths in the tree. Typically, each digit (base16) corresponds to a branch in the node, thus the number of steps to find a value associated with a key is constant and fully deterministic. Such paths are called radix.
- Patricia Tries
- Patricia comes from: Practical Algorithm to Retrieve Information Coded in Alphanumeric
- Comes to solve mainly two issues with Merkle trees:
- a) Hashes are often quite large (e.g. 256 bits) which make Merkle trees' radix quite inefficient
- b) Hashes are sparse (by construction / essence of a hashing function). Which makes tree-like structure like Merkle trees often inefficient as most nodes tend to have only one descendant.
- Patricia tries leverage common parts in hashes to group keys together that wouldn't normally be grouped together. That is, a trie typically uses every part of a key whereas patricia tries instead store the position of the first bit which differentiate two sub-trees.
- One interesting properties of Patricia Tries: inserting a new key only require the creation of one node (unlike standard binary tries which require a node for every new bits below a common prefix) -- which makes them very compact.
- Interactions between Hydra, Plutus and mainchain: @michaelpj being off this week, this is postponed
- Protocols clarification: Clarifying our understanding of versions of Head protocol, and checking what would be feasible and reasonably secure to implement:
- Coordinated protocol
- Optimistic head closure
- Conflict resolution
- Incremental de-/commit
- React to (mainchain) protocol parameter changes: How will Hydra handle changes in the underlying mainchain that could affect running heads? This verges on the broader topic of Hydra nodes and protocol updates
- Fees/rewards handling
- Don't know which
Preludeto use, as there's theCardano.Prelude, thePlutusTx.Prelude, the basePrelude... For things like basic typeclasses and derivations I need standard Prelude or Cardano's one - Wrote predicate
datumAtAddressthat checks some address contains someDatumHashwhich is an indirect way of checking the resulting state of a sequence of transactions. I had to crawl through the complex data structures exposed by plutus library but this was relatively straightforward thanks to HLS enabling quick navigation to definition of types! I could not check the actual state, because the UTXO does not contain it, only the hash (or ratherDatumHash). It is the responsibility of the consumer of UTXO to post a transaction that contains a witness for this hash, eg. the actualIsDatato provide to the script for validation of the transaction. - We don't want to invent a "diffferent" protocol to cope with the limitations of existing nodes and Cardano tech, but we could use the existing multisig implemented in Shelley, doing ephemeral key exchanges, it might still be viable for Hydra head protocol and product
- Exploring the Plutus StateMachine abstraction. We'll try to wrap the validator we have into the StateMachine abstraction, writing the
transitionfunction. Now just making sure we can compile a minimal SM definitino, detached from existing code. -> leads to a 730KB large IR contract - Why do we need to "loop" on the definition of a contract? like:
contract = (lock `select` guess) >> contract
We did some "coloring" of the storymap, going through the comments and resolving them
- networking: Orange is fine
- commit/de-commit: We'll have experience form previous transactions and contracts
- E2E tests: automating tests is easy, but E2E tests are notoriously flaky and it's hard to figure out why they fail It's hard to have reliable E2E tests
- Updates/Upgrades: Need to be dealt with early, and could be done in conjunction with E2E tests and naive at first
- Submit txs: It's not as clear as before, how HN will interact with the mainchain We could use Plutus backend instaed of directly interacting with the chain, or use Plutus to craft transactions and post them directly.
- Coordinated protocol: Is it really simpler to build? We should flesh it out to understand whether it's valuable or not to start with Goals for the morning:
- Have a single step of Hydra SM working in playground, namely closing a Head
- Investigate Plutus State Machine library
After some fiddling around and staring at example applications (Game), we managed to play a Sequence of
collectCom/closetransaction in the playground: - Trying to have
validatereturnsFalseshowed the function was never invoked - We added some traces to have insights from the simulator
- It turned out the
endpointfunction was not evaluated because it did not have an argument. Adding()as argument to thecloseendpoint did the trick. - Note there was an error in the
closescript's boolean logic! This was written without any test... -
TxConstraintsis a monoid so we accumulate both acollectFromScriptandpayToScriptin theClosein order to enact the SM transition - In the simulator, Green denotes wallets and Orange denotes scripts
What's next?
- looking at the
TODOsin the plutus contract, ie. everything we need to have a concrete validator working The primitives need to be known early in order to be embedded earlier in the nodes and Plutus evaluator Also we need to check we have access to the datatypes to manipulateTxandUTXOas this is needed by OCV scripts - Plutus State Machine: implement
transitionfunction as perGameStateMachine - Local machinery to run contracts and tests
- Connecting to the mainchain
Next stuff:
- (AB) make local dev environment works, and have a first test case
- (SN) prepare monthly report
- (MB) investigate SM, perhaps having a look at MPT
- Project compiles and (dummy) test is run, going to write a "real" test
- Switching to use tasty instead of hspec as it's what's supported by Plutus'
Testframework: It provides predicates and utility functions to define Emulator based tests - Defined 3 tests following what's done in
Crowdfundingproject:- A simple test checking the endpoints are correctly defined
- A golden test to check the compiled plutus contract did not change, which is pretty useful to have in order to catch any kind of change that would break the script's definition hence its hashed value and address in the ledger
- An emulator based test checking all transactions validate (note I witnessed the test being red when validator returns
False!)
- Hitting a plutus compiler error while trying to compile the tests containing a call to
plutusCompile:Looking at https://github.com/input-output-hk/plutus/blob/master/doc/tutorials/troubleshooting.rst for potential solutionsGHC Core to PLC plugin: E043:Error: Reference to a name which is not a local, a builtin, or an external INLINABLE function: Variable Hydra.Contract.$s$fFoldable[]_$cfoldMap No unfolding Context: Compiling expr: Hydra.Contract.$s$fFoldable[]_$cfoldMap Context: Compiling expr: Hydra.Contract.$s$fFoldable[]_$cfoldMap @ Hydra.Contract.TransactionObject Context: Compiling expr: Hydra.Contract.$s$fFoldable[]_$cfoldMap @ Hydra.Contract.TransactionObject - It would now be interesting to check the outputs or the state of the ledger at the end of the tests execution.
(AB) How are Plutus scripts actually "published" for use by cardano nodes to validate transactions?
- The Alonzo specifications says the scripts are part of the
TxWitnessstructure which is part of the whole transaction. The transaction creator provides them in the form of a map fromScriptHashtoScriptwhich implies every transaction includes every script needed to validate inputs. This seems pretty inefficient in the long run but not a concern for us.
SN: Read the EUTXO paper (finally), my notes
- being more expressive, by supporting state machines seems to be a concrete goal of the extension
- two things are needed:
- something to maintain state -> datum
- enforcing the same contract code is used -> validator ensures tx output is again the same contract (or final) -> this is called contract continuitiy
- "validator implements the state transition diagram [..] by using the redeemer of the spending input to determine the transition that needs to be taken"
- every (non-function) type in the scripting language needs to be serializable
- the validity interval bounds time and allows full simulation -> to get an upper bound on script costs?
- outputs only contain hashes of validator and data to allow for constant size outputs -> nodes keep the whole UTXO in memory
- actual data and validator script is part of the spending transaction
-
TxInfoderives some more info for convenience, like equality checks and identifying "own inputs" - constraint emitting machines (CEM)
- no initial state -> contract "should first establish some initial trust"
- final state will not appear in the UTXO set
- validator is derived from constraints the CEM transition "emits", which need to be satisfied and the goal state needs to be in the tx output
- weak bisimulation
- models equivalencey of CEM semantic model and transactions on the chain
- weak means that unrelated transactions are admitted
- was also done in Agda here
- can we use something like this for the Hydra protocol (a concrete CEM state machine)?
- Started using the Plutus Playground to experiment writing part of the OCV code, namely the
Closefunction - We made good progress fleshing out its on-chain contract, basically paraphrasing in code what's in the code
- Using plutus playground is still rough on the edges:
- copy/pasting code to/from editor is painful (vim bindings didn't work)
- Trying to reuse "native"
TxorUTXOfrom Plutus does not seem to work. although we would like to: It requires instances ofIsDataandLiftand trying to define those leads us into rabbit hole to define instances for everything inside the structure - Interpreter errors are somewhat daunting
- Some functions (beyond complexity threshold?) require explicit
INLINABLEannotation
- We identified some more primitives we need from Plutus library:
- Serialise/hash any type for signatures verifications
- Applying transaction to a set of UTXO and get a new UTXO or nothing back, eg. checking validity of transaction against some UTXO
- Multisignature crypto primitives of course
- We attempted to write endpoints for CollectCom and Close in order to simulate a first transition of the state machine but did not succeed
It seems like in the way endpoints are defined using
selectthen the first one does not get invoked and does not generate a transaction, perhaps some form of optimisation? - Follow-up before continuing tomorrow morning:
- investigate local development and automated testing?
- understand what's underneath the Plutus playground
Meta-Remark:
- SN noticed that leaving the mob session and coming back is tough, it's easy to lose track of what's going on
- (AB) It's fine to go slower when you rescind with the rest of the mob, and it usually helps clarifying things that were unclear, or ill defined, or hastily written, by challenging them.
- Walk through the example and checking our understanding of UTxO set being locked and transactions in the head are the same
- U_n is always describing the whole state
- Where is U_n stored?
- Needs to go into a tx, without merkle trees this is likely big, but would be viable -> require decommit before it grows too big
- Security: Not being able to fit is a security concern and MPT's are likely required for an MVP
- Redeemer refers to the hash of UTxO set
- UTxO is the "pre-image"?
- Plutus is also doing this "under the hood", i.e. only keeping hashes in the UTxO
- Datums and validators are just hashes
- Why are PT threaded through and not burned in collectCom?
- State thread token ST is basically all the PT together
- Theoretically identical to burning PT in collectCom and minting a ST there
- However: PT are also used in concurrent paths of more complicated protocol variants!
- Concurrent txs like the commits are likely not yet provided by Plutus library (it's StateMachine abstraction)
- Also: A round-robin commit protocol variant is possible, which does not require PTs.
- Has somebody ever tried to model things as validators and redeemers yet? -> No, this would be responsible by the "statemachine library"
- Additional resources
- Two papers + Agda source code
- Statemachine module / library in Plutus
- Trying to draw the evolution of Hydra node state as transactions and snapshots are sent/received/processed
- There's a dissymetry in the protocol between TX and SN:
-
reqTxandackTxcan all be broadcasted with confirmation happending locally at each node when it receives allackTxfrom other nodes - in the SN case, while
ackSncan be broadcasted, it's only processable by the slot leader which implies theconfSnis still needed - It Looks like it should not be the case, but what if an
ackSnis received before the correspondingreqSn? This is possible if all nodes broadcast there ackSn to all other nodes upon receiving reqSn It's not a problem for transactions because when we receive anackTxfor a transaction we did not receivereqTxfor, we can still proceed with signing as it's only the hash of the transaction we sign and we have it in theackTxmessage It's unclear yet whether we can proceed in the same way for snapshots but it's probably the case
-
- Trying to understand the Head protocol with conflicts (section B.1 from Hydra paper)
- The conditions are slightly different in the
reqTxcase: What if a node getsackTxbeforereqTxfor a given conflicting transaction, which is possible if theackTxare broadcasted from all nodes? - the conflict resolution process in the paper is slightly obfuscated by the notations used, but the basic process is relatively straightforward: The snapshot leader discards all transactions he has seen that conflicted with transactions he has signed (and seen) and include the latter in the new snapshot. This implies followers might change their views of with transactions are seen/conflicting, replacing the ones they locally have with the leader's
- The conditions are slightly different in the
- Couple of visual notes taken can be found here: https://miro.com/app/board/o9J_lP7xko0=/?moveToWidget=3074457356199967027&cot=14
- Today we explored the problem domain using a "denotational design" inspired approach
- We went through diagrams and our current mind model of the problem domain by naming entities and giving / denoting a meaning to them using Haskell types and functions (signatures only)
- This worked great for the "pure logic" parts of the system, namely the hydra head protocol and it's input / output messages, as well as the ledger parts
- However, we may have dived to deep when we added drafts for monadic interfaces and how the protocol would be "driven" from the hydra network side etc.
- The result can be found in this module
- We set off to share two pieces of information that were not already shared across the team
- First part of the session was to confirm we all understood what on-chain and off-chain transactions contained, going through a concrete example:
- https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3074457355789464390&cot=14 details the on-chain transactions
- https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3074457355793582624&cot=14 details the off-chain (eg. within Hydra head) transactions
- The question of fees (or rewards) surfaced again. It seems there are several possible ways of paying fees to ensure Hydra head makes on-chain progress
- Fees could be applied to the initial set of UTXOs committed
- Fees could be payed using some other sources (eg. preexisting addresses) by each node as they submit on-chain transactions
- The Hydra paper's appendix, section D.1, suggest incentivising Head parties by defining an amount of reward as a parameter of the Head to be provided as part of initial commits
- MB noted that transactions must preserve monetary mass, eg.
inputs = outpus + feesso the total amount of the commit transactions must be carried over across all subsequent on-chain transactions - The Merkle-Patricia Tree provides a compact way of carrying over the state machine state until the final fanout transactions, which is needed for Hydra Head protocol to scale beyond a few dozen UTXOs
- Second part of the session was going over a draft Storymap
There are multiple ways to go about this in varying abstraction levels:
- cardano-node / cardano-cli level using this guide
- using cardano-wallet / adrestia and the HTTP api
- using cardano-address, cardanox-tx and cardano-wallet CLI tools
I opted for the first one as a start, also because I had the cardano-cli already
built and a cardano-node running (but no cardano-wallet) server.
First, I created two key pairs for Alice and Bob, derived the payment address and checked utxo balances with:
mkdir alice
cd alice
cardano-cli address key-gen --verification-key-file payment.vkey --signing-key-file payment.skey
cardano-cli address build --testnet-magic 1097911063 --payment-verification-key-file payment.vkey > payment.addr
cardano-cli query utxo --testnet-magic 1097911063 --address $(cat alice/payment.addr)
After requesting funds from the testnet faucet with an API key (shared via slack), assets showed up on the ledger:
TxHash TxIx Amount
--------------------------------------------------------------------------------------
84723d3033d03e4a0088dcc96d3db308bfe67b12a46bd351caa0958196917c2c 0 1407406 lovelace + 2 6b8d07d69639e9413dd637a1a815a7323c69c86abbafb66dbfdb1aa7
f8f2eeaa0a90c43eb55882d39ea770a49c028e2ee99e05b86a5945728464ab9c 0 1407406 lovelace + 2 6b8d07d69639e9413dd637a1a815a7323c69c86abbafb66dbfdb1aa7
Following the guide, I then set off to create a transaction to transfer 1 ADA = 1000000 Lovelace from Alice to Bob. This was a bit tricky because the faucet
only distributes ~1.4 ADA in one tx, thus requiring two tx inputs, and the
native tokens need to be preserved as well. So after some trial and error I came up with this transaction draft:
cardano-cli transaction build-raw \
--tx-in f8f2eeaa0a90c43eb55882d39ea770a49c028e2ee99e05b86a5945728464ab9c#0 \
--tx-in 84723d3033d03e4a0088dcc96d3db308bfe67b12a46bd351caa0958196917c2c#0 \
--tx-out $(cat bob/payment.addr)+1000000 \
--tx-out "$(cat alice/payment.addr) $((1407406+1407406-1000000-179845)) lovelace + 4 6b8d07d69639e9413dd637a1a815a7323c69c86abbafb66dbfdb1aa7" \
--invalid-hereafter $((22040320+200)) \
--fee 179845 \
--out-file tx.raw
cardano-cli transaction sign \
--testnet-magic $(cat db-testnet/protocolMagicId) \
--tx-body-file tx.raw \
--signing-key-file alice/payment.skey \
--out-file tx.signed
cardano-cli transaction submit --testnet-magic $(cat db-testnet/protocolMagicId) --tx-file tx.signed
- Initial goal was to integrate our
ourobouros-network-frameworkexplorations intohydra-node, to explore how messages would flow between nodes, or at least between nodes - I (AB) started trying to write a high-level (acceptance) test in
hydra-nodeto express the behavior we wanted to implement, namely that:- Given two Hydra nodes HN1 and HN2 are connected
- When a client post a "new transaction" (for now a simple string message) to HN1
- Then the new "transaction" can be observed on HN2
- By writing such an acceptance test, the intent was to start exploring the system in an outside-in approach, discovering or inventing the needed interfaces while the system become more and more complex and we add features
- While discussing the approach it became clear we were not aligned on the overall structure of the system hence we backed out from coding and went back to the drawing board sketching how such a simple "transaction" would flow through the system
- This lead us to this architecture diagram: https://miro.com/app/board/o9J_lRyWcSY=/?moveToWidget=3074457356049646378&cot=14
- It's focused on the components' interaction when a head is in
openstate. This highlights the fact the protocol handler evolves when the head's state changes according to the overall (on-chain) State Machine - While designing the head with a central event queue from which protocol handler threads pull events, it occured to us it might be more robust to let the server components (both at the HN-to-HN and client interface) handle the complexity of managing thread pools and queues, and have the Head expose event handler as a "callback" with some synchronization mechanism (STM?) to update Head state
- While obviously servers handle multiple concurrent connections, it's not clear how we can have our HN-to-HN server (or is it responder?) handle messages concurrently. Perhaps we can start single threaded and increasing messages handling concurrency later on?
- It's focused on the components' interaction when a head is in
- We explored the
ourobouros-network-frameworkandtyped-protocolsby adapting the ping-pong example with our very ownFireForgetprotocol. - A client would just send messages at will in this setting and the server always receive anything what is sent to him (without producing an answer).
- We also made the example use duplex communication, i.e. both parties are initiators and responders (client and server)
- Next step: Define an interface as used by the "higher-level" logic (the "head protocol" itself) and which does not really care how things are broadcast.
- We started by going through communication examples, clarifications:
- Ack is not a broadcast? Yes, it's rather a response to the request
- NewTx is initiated by a client
- "Central coordinator" (protocol mode?):
- a central coordinator does collect txs and gets them signed in batches
- Aims to simplify protocol concurrency
- Duncan's intuition:
- Broadcast everything is likely simplest
- TxSubmission broadcast is resembling this the closest
- Why not local tx submission:
- resource use
- better throughput with high latency -> sliding window-based -> pipelining
- Keep track of pending Acks in the application logic
- Point-to-Point is not suiting relayed network topology (because of the signing key)
-
If we broadcast everything we could skip the confTx / each node does it on their own
- Paper just assumed that we have point-to-point connections
- Doing it this way is also mentioned in paper (ePrint version, footnote 4 (page 21))
- What if we have two / multiple heads?
- Multi-tenancy / re-using connections
- Multicast vs. broadcast
- Manuel: more complicated logic on "Hydra head protocol" level incoming, and maybe not representable in a type-level modelling
- Duncan: Nothing in cardano right now is using addressing -> that could get complicated
- Tail protocol maybe gives rise to a different networking anyways (because it's highly asymmetric)
- Snapshotting can be seen as a (storage) optimization and an early prototype could work without it?
- Matthias Fitzi: Will put together a draft on the coordinated variant and also what we know of the tail protocol.
- Some notes on formalising Hydra node's behaviour using process calculi ie. π-calculus.
- Some notes on Constraint Emitting Machines
- reading through Shelley presentation forwarded by RP :https://docs.google.com/presentation/d/1B3oMvI_fsp91W4zDo8lQKhAI48z0MkM4-ual89IjMUM/edit#slide=id.g720136a3f9_0_136
- reading about EVM-as-a-Service on Cardano blockchain, RP identified it as potential use case for Hydra
Also linked to https://eprint.iacr.org/2018/1239.pdf (Sidechains PoS)
I don't get all the details esp, when it comes to ETH and ERC20 stuff, but I think I got the gist of it as it relates to Hydra:
- The side-chain control committee could be made of Hydra nodes
- The Hydra protocol would be used to pin-down some ADA/assets on one side, and transfer them on the other side
- This must be done in both directions
- The whole init/collectCom/close/fanOut protocol dance can be run on either chain if they both use (E)UTxO model
- this implies the core Hydra protocol handler should be abstracted away from the details of the chain the transactions are built for
- this means decoupling dependency to cardano-node libs for ledger representation and validation -> expose it through an API? have dedicated node running only for validation purpose on a single node network?
- we need an abstract notion of UTxO and Tx, and Addresses., and....
TIL how to determine closure size of a store path and how to get the store path for a mkShell derivation
λ nix-build --no-out-link shell.nix -A inputDerivation | xargs nix path-info -Sh
[...]
/nix/store/8mhi8q39mcv2sv5aqq3irki3r96864bl-hydra-node-env 2.9G
- We went through the ping-pong.hs example as copied into this repo. Discussed
connectTo, codecs, theMuxand eventually went off talking about suitability of this network (protocol) stack and how "our" typed-protocol would look like. - We came up with two more examples of messaging sequences on our Miro board here
- We continued discussion about whether and how the
ourobouros-network-frameworkand more specificallytyped-protocolscould help in facilitating this kind of communications. - Verdict: We are not entirely sure, but the "full" communication flow can not
be realized on the "protocol-level" as the
confTxmessage shall only be sent when allackTxhave been seen (from multiple peers) -> this is likely in the "upper logic" layer. However we can imagine an "arbitrary message" protocol (on board) to side-step on the statefulness of typed-protocols, or use the Request-Response protocol forreqTx/ackTxand a Fire-Forget protocol for the singleconfTxmessage.
(AB) Sketching happy path for the lifecycle of a Hydra node: https://miro.com/app/board/o9J_lP7xko0=/, to be discussed with the team later on once we have a better understanding of some foundational issues like networking or crypto? Today's stuff:
- Living documentation reading group
- Short intro to some personal assistant tool
- More reading/fiddling with network stack
Just discovered the Haskell way of encoding impossible cases:
exclusionLemma_ClientAndServerHaveAgency :: State -> a -> Void
exclusionLemma_ClientAndServerHaveAgency TokIdle tok = case tok of {}
SN: Had a look on nix flakes because it was mentioned as maybe relevant for our CI setup on slack
- This blog series and the Nix wiki are good starting points
- In a nutshell: Flakes allows nix projects to refer to each other while keeping version pinning and bumping simple (using a lock file). Also it provides a (more) pure representation of what the project provides, which can be cached (no dependency on the current system etc.) aggressively. For example, this allows for a faster nix shell (which is called
nix developin the flakes capablenixpre-release). - Also added a
flake.nixto the hydra project to test things out. Partly following the haskell.nix getting started for flakes. Building and a basic development shell work, but failed to re-use cardano-node expressions (the irony.. but they also don't have aflake.nixso..)
We had a fruitful discussion and drawing session that lead us to clarify our understanding of how transactions and UTxOs from the mainchain and Hydra head where related (see frame 1 and frame 2)
Also, sketching out what to talk about on Wednesday?
- networking stuff
- out of the 3 head messages, one is "addressed", there's not hurt in broadcasting it too
- same requirements than cardano nodes? signing, transmission, diffusion
- privacy is conflicting with relaying, implies no TLS is possible if relaying through another node
- privacy then means encryption of messages themselves, using some shared secret
- what if we need to address another specific party in the Hydra protocol?
- scheme for addressing other peers
- a given Head defines a specific set of parties which is a subset of hydra nodes running
- not the same "diffusion" scheme as a blockchain
- Wednesday goal: What ourobouros-network can do for Hydra nodes?
(AB): goals for today:
- reading in progress on Living Documentation
- more reading on typed-protocols and ourobouros network stack. also looking at Duncan's videos
- Notes from watching Duncan's talk
- having a look at https://hydra.iohk.io/build/5657770/download/2/network-spec.pdf which is a semi formal presentation of the network layer details
- having a look also at https://github.com/input-output-hk/ouroboros-high-assurance while the VM is building :) The syntax in Haskell seem pretty straightforward but most of the work happen in Isabelle with executable code to be generated to Haskell
- scaffolding of hydra-node if time permits
- Also want to write an Astonishment report about my first 2 weeks at IOG
- trying to speedup VM deployment by using cachix for nix-shell boot
- added suggestions from https://github.com/cachix/cachix/issues/52#issuecomment-409515133 to update cache after nix-shell but the effect is minimal
- still fiddling with yubikey/gpg-agent
- not a very productive day, lots of interruptions from environment
Mob session on building our initial backlog:
- 5 minutes writing stickies on things we want/need/expect
- Round-robin explanations of stickies, grouping them together, possibly refining them
- group stickies
- add missing points?
- trying to identify actionable items
We create a storymap with "features" on one dimension and MoSCoW on the other:
- first putting features with dependencies on other teams/components, to identify potential needs, with a level of "scariness"
- eg: multisignature is confusing, can be different things, Plutus contracts seems a big beast to tame, what about Alonzo transaction format, how much reuse can we have on Ourobouros Node-to-Node network machinery...
- then more features to flesh out the HN itself
- we'll maintain the map overtime, refining it as we learn more
wrapping up: selecting a ticket to do in next mobbing sessions:
- experiment with ourobouros
- write Plutus contracts
- write Alonzo transactions
- scaffold HN executable
Next:
-
MB off Friday and Monday
-
SN partly off on Friday, will do some reading and coding
-
AB: reading on ourobouros and scaffolding HN executable
- Discussing the need of authenticated communication channels between Hydra peers.
- From Hydra: Head Protocol, page 10:
Each party [...] establishes pairwise authenticated channels to all other parties [...]. The parties then exchange, via the pairwise authenticated channels, some public-key material. This public-key material is used both for the authentication of head-related on-chain transactions that are restricted to head members [...] and for multisignature-based event confirmation in the head. The initiator then establishes the head by submitting an initial transaction to the mainchain [...].
- To which extend to members have to "know" each others beforehand?
- Could the chain be used to establish the authenticated channels?
- Does it matter to ensure with whom we're communicating? TLS could ensure that channels are end-to-end encrypted, but can't enforce the other end of a TLS channel is one of the "expected" participant without central authority and TLS only.
- Some similarities with multi-party wallets and multisig coordination servers, except that in the context of the wallet, sessions are very short-lived, and the coordination server is used as a middle-man.
- Seems like many scenarios are possible, but understanding the use-cases is crucial here to conclude on what needs to be done.
- From Hydra: Head Protocol, page 10:
How much of Plutus do we need to run Hydra? What cryptographic primitives are needed, and are they available on Plutus?
- Aggregate Multi-Signatures need to be validatable on the main chain (e.g. in the decommit phase). Is this possible in "non-native scripts"?
- Align release plans! Whatever is needed from Plutus would have to be stated and planned early in case any hard-fork is needed to bring new primitives. Next step: list requirements / crypto we need
- There's a new cryptographer starting soon and dedicated to Cardano which we may bother to get some of the multisig implementation done. Duncan and Philipp are good points of contact.
- We definitely need Alonzo for realising the onchain part of Hydra. The full power of EUTxO with redeemers and validators is needed. In particular, we need Plutus contracts to be able to validate aggregated multi-signatures (which implies crypto primitives available in Plutus).
- The idea of a special-purpose on-chain language (e.g. monetary scripts) was mentioned, but getting such a special purpose language ready would actually take more time than getting Plutus out. Using a special purpose language may be a good, or not so good idea. We may start with Plutus to identify requirements for special purpose language.
- The question of privacy is quite important here because, the node-to-node protocols do not need privacy and do not need identity. So if needed, a lot of the networking stack would need to be re-implemented.
- Generic over "bearer" (could be encrypted e.g. over TLS)
- Confidentiality is a nice-to-have (not vital / minimum viable?)
- Privacy also suggests that there's no adversarial node in the group. Plus, the Hydra protocol wasn't thought with privacy in mind initially, so it may be risky to start introducing it now only to discover holes later.
- Ouroboros-network does already solve many problems w.r.t to broadcasting with non trivial broadcast strategy (i.e. not fully connected point-to-point broadcast). Leveraging this for Hydra could be beneficial. (edited)
- Connecting everybody with everybody is fragile but we could start with that? i.e. it can't hurt to overly connect to all peers, but think about have store/relay capabilities (as already solved in cardano node)
- Also: relaying
- Head protocol = small group of parties
- Inter-bank communication / clearing
- Frequent B2B transactions
- We need a technical product manager.
- Using the chain for this is plausible but slow-ish / expensive.
- The protocol itself is "fool proof" w.r.t to the channel establishment (every party must check the initial transaction). So there's a lot of freedom in how the initial phase is done and how the initial key material is exchanged.
- Detail discussion on re-use networking layer of Cardano Node
- Testing strategy as used on consensus layer
SN: Review ledger-spec documents in search for tx validation
- started with the shelley spec
- uses small-step structured operational semantics (SOS) rules in (labelled?) transition systems
- multi-signature scripts -> early (shelley) validation logic: single key, all, any, m of; recursive
- key evolving signatures (KES) -> static public key, but private key changes; is indexed by a number
- tx body: delegation certificates somhow related to Hydra cert
ξ? - property: preservation of value; needs to hold for ledger and actually "any part of cardano"
- thought: possible to re-use (multi-) signed tx-body / signature from Hydra on
the main chain => isomorphism? (i.e. does the fully signed snapshot apply on
main chain?)
- What is the secret behind that
ξcert? maybe a shared key? - Who can finalize the head / fanout the funds on main chain?
- is the fan-out tx already prepared (and signed by all parties) before starting head interaction?
- What is the secret behind that
AB:
- started writing some notes on networking design document. TIL about pipelining in the networking layer as an optimisation for a client to send several requests without waiting for each one's answer if the answer is implied by the protocol
- spent time fixing my gpg key configuration fiddling with publication on servers, subkeys revocation, gpg-agent forwardinv to remote host, yubikey, signing commits and emails. Might be worth a short blog post to summarize things
- MB shared some insights on tx validation:
- looking at Alonzo code for validation script, not much different from MAry, Plutus support is not there yet and not feature addition to validation scripts.
- we cannot define redeemer and validator in Mary. We could use Alonzo body in Hydra but there are irrelevant parts,. However the binary format leaves room for optional key/value pairs (see https://tools.ietf.org/html/rfc8610 for the CDDL specification)
- mob session:
- got test passing by fixing the path to socket node when querying cli
- improved the test to check the network is making progress which means getting the tip at different point in time (between slots)
- ended up in a rabbit hole chasing dependencies when trying to use existing
ChainTiptype from cardano-api - we simply defined our own
Tiptype deserialised from JSON representation cardano-cli gives us back - tests were not working for SN and AB because we were using different cardano-cli, ie. the one from nix-shell while MB was using his local one: One point towards using nix-shell to provide uniform and consistent tooling across environments
- it happense there was a change in the tip output format recently which explains the failure changing our representation working. Q: Is the cardano-api not versioned?
- ended the day discussing coding standard for records and datatypes codecs
- Discussion about research / engineering, splitting meetings, technical kick-off tomorrow creates precedent for an additional meeting
- Use #rnd-hydra slack channel to share things even though we might have two (weekly) meetings
- What is the tail protocol?
- While in the head protocol every participant needs to be online and responsive, within the tail protocol there is an asymmetry where some parties are online (servers) and others may be partly offline (clients).
- More dynamic, parties can join and leave
- Might use threshold crypto (for what?)
- Various discussions points about research topics, formalizing things, possible increments and milestones for the implementation, how to approach it, MVP and "minimal viable protocol"
- Is multi-sig crypto available? "Has been done" .. but they seemed not so sure.
(AB): managed to get my mu4e for IOHK working, the issue with SMTP was:
- the communication was done in plain and then switcehd to STartTLS on port 587
- but the server only supports direct SSL communication on port 465
- Sebastian showed me the
smtpmail-stream-typevariable that must be set tosslfor proper channel to be setup - need to set up/clean up PGP keys and configuring email signature: https://input-output.atlassian.net/wiki/spaces/HR/pages/824639571/Review+Setting+Up+Your+Work+Environment
We used the same Miro board as before, focusing on detailing the content of the hydra-node: https://miro.com/app/board/o9J_lRyWcSY=/
cardano-node is assumed to provide valid tx for HN to observe: => use node to client protocol
multisignatures:
- no implementation in cardano-node?
- we know it's doable even though we don't know pratically how to do it
- describe an interface for multisig and provide concrete implementation later on
isomorphism property:
- posting txs to the mainchain or posting txs inside a hydra head should be identical
- result (utxo, snapshots) should be identical
stating it somewhat more formally would be:
- given a set of parties A,B,C...
- a set of UTxOs pertaining to UA, UB, UC,...
- when parties produce a set of txs consuming those UTxOs U resulting in UTxOs U'
- and doing those txs through a Hydra head with commit U leads to U''
- then U' = U''
what are the requirements from mainchain to have hydra working?
-
init=> needs multiasset (to create non-fungible tokens and multiasset transactions) -
collectCom=> creates new UTxOs attached to a particular script - needs to check 6.3.1 section of the paper:
- need to write Plutus SC for Close/Contest/Final
- can we do that in Plutus?
- current validation scripts in cardano are very primitve: look for keys, time constraints wrt to slots
- can we do early validations without Plutus? e.g Shelley only
- we can put the mainchain tx validation logic in the client
- could even be possible using existing validation scripts?
wrapping up:
- SN: we should focus on what's most risky, get an architecture spike. Get some feedback from Wednesday meeting with Manuel/Philipp target mob session in that direction
- MB: getting something running as quickly possible we have 1-2 months of leeway to experiment and explore later on more people will have a look, and want to see outcome
- AB: same
- SN: but we have the ability to define what our goals would be -> drive rather than be driven
2 main discoveries today:
- stating isomorphism property to drive our tests and development
- questions about mainchain readiness to handle verification requirements from Hydra txs
getting from evidence based to High-assurance engineering
- important question for the whole indutry
- goals:
- 1.000.000.000 users
- 1.000.000 daps
- 1000 businesses
- 1 country using ADA as finance backend general purpose platform for DeFi
- DSLs -> Marlowe
- playgrounds -> full SDKs
- sound cost model (tx fees, lots of debate in community)
- need Dist DB, dist storage, networking (with privacy preserving)
- AI models integrated w/in ecosystem Goal: The SOcial FInancial operating system of the world
- Catalyst effort, extending Cardano community
- Ouroboros Omega => unified PoS protocol (winning the PoS battle)
- Tokenomicon
- decentralization economics design space
- reward sharing schemes ---> full economics for custom projects
- stablecoins
- Global Identity : One stop shop for identity services
- Democracy 4.0 => using Cardano as a service for affiliated systems using the tools Cardano provides
- Hydra: expand suite of protocols around Hydra
- C/S applications can run on Internet --> can run over Cardano
- Hydra head, tail around the corner
- mantra: if it runs on the internet, it runs on cardano
- provide the right dev env
- Inter-chain: trustless integration, side chains, transfer of value across chains
- Post-quantum readiness
- extend crypto primitives
SN shows us 2 proposals:
- commit message proposal
- blank line -> use formatter's rule SN presenting what he did on Nix to fetch HLS from haskell.nix
- provide a way to maximize caching use from IOHK nix tool
- https://input-output.atlassian.net/wiki/spaces/EN/pages/718962750/IOHK+Research+Engineering+Seminar is where we should look at to get more information about nix MB: we should configure hlint to define default qualified abbrvs
Coding session:
- fleshing out the test writing an action that
assertClusterIsUpneeds to talk to one node through its socket file, which means we need to have it available inRunningNodeconfiguration - closing in on having a cluster up and running, and checking one of the nodes is up we already wrote/stole a lot of code just to get that simple test running but it's certainly valuable as we are scaffolding the whole machinery to be able to run ETE tests
- test is running and we can see the nodes are up but it is failing!
- we have an issue with configuration of log scribes from iohk monitoring fwk. Note that configuration is JSON which is easy to have wrong at runtime
wrapping up this morning's session:
- agreeing on using code formatting tool to stop discussions and bikeshedding on formatting
- reviewing the day
- AB: more reading this afternoon, session was good
- MB: questions about time allocation b/w the project and wallet
- SN: good to have mobbing at the beginning esp. to lay the ground for teamwork
- building something tangible
- focus on whitboarding early next week to have something to show on Wednesday
- Friday is also a not-disturb day so good opportunity to write/think/experiment
- seems like everyone has good feeling about the team, the what/where/how
(AB): spent some time Friday afternoon tagging along in the weekly seminar about Þ-calculus where Wolfgang Jeltsch gave me a quick intro on the calculus: It's a process-calculus inspired by π-calculus but without replication and embedded using HOAS into a host language (eg. Haskell). Work is being done on formalising it in Isabelle/HOL, see https://github.com/input-output-hk/ouroboros-high-assurance/tree/thorn-calculus-preliminary for more details.
- Process calculi in general are interesting as a way to formalise distributed systems, and could be used in practice to define processes that would be used to generate traces for QuickCheck and then later on for formal proof.
-
We had another mob programming session where we added a test suite and started to reproduce the cardano cluster orchestration
-
We also discussed the mob session itself and came up with something that could resemble our first development process in the current, exploratory stage / discovery phase of the project:
- We want to have a 3hour block every day where we are at least in the same room, or even program in this rotating driver pattern as a mob
- Any substantial progress or decisions we want to keep in the 3h block for now
- The remaining day (before and after) is about individual tasks, exploration and knowledge gathering
- We also discuss what each of us does in the individual time until the next session, i.e. we start and close the session with a daily stand-up
-
(AB) some notes on today's and possibly other mob sessions' rule:
- use http://cuckoo.team/hydra-team as timekeeper, using 25' driving slots and rotating the keyboard
- code should compile before end of slot so that we can push for the other driver to pull
- code that's written but does not compile is simply reverted or stashed, waiting for next round
- when next driver starts, he/she pulls changes, possibly stashing/rebasing local changes from previous round
-
interaction between
cabal.projectandhaskell.nixinfrastructure is confusing, we ended up ditching the latter atm for a directshell.nixbut this means we can no longernix-build -A local-cluster -
we had some discussions about logging, there is a iohk-monitoring-framework which is highly configurable and useful, if somewhat a bit complicated to use. wallet team wrote some wrapper code that simplifies things.
-
setting some default-extensions and more ghc configs to simplify file
- it's annoying cabal does not let you have a toplevel configuration for these things as
hpackdoes - have a look at cabal-fmt project for possible solutions to this issue?
- it's annoying cabal does not let you have a toplevel configuration for these things as
-
stealing also ports allocation code from wallet too, but it would be useful to factor that out for reuse across projects
- note: let's discuss with Prelude people to see if we can add standard stuff for assigning ports
-
now needing to implement withBFT which is the interesting part: we need a genesis file and a bunch of configuration stuff about keys, consensus partameters and the like. going to generate a static file first and then later on implement that generation in Haskell code -> another thing that could be useful for reuse in other projects
- we will fork cardano-node using basic process. typed-process looks cool but let's keep things simple_
- Matthias tells us there's an "interesting" issue with process handling on Windows: The thread wrapping the process needs to be diffrerent from the main thread for interruption/terminiation to work. At the moment this fine as we will only run the cluster on linux even though we need to make hydra-node runnable on "any" OS
-
Minor task to explore: how do we get the cardano-node executable for tests execution available in nix shell?
- We discovered and quickly discussed existing Coding Standards and Development Process documents of the cardano-wallet/adrestia team; We will also create something like that (SN: but the process document rather in Confluence to have it visible to PM/PO?)
- SN proposed to have the logbook as a single page and use a table of contents to quickly jump to months instead of multiple pages -> accepted
- SN: I am reading up on extreme programming methods and practices as a potential lightweight agile process for our team
- Matthias gave us a tour of running local cluster as it's done in the wallet, going through various interesting configuration aspects
- started hacking on https://github.com/input-output-hk/hydra-node repository
- bootstrapped project from existing skeleton but it's way too complicated, esp. when it comes to nix
- Slack discussions
- idea of a team log: related to zettelkasten, roam research principles (knowledge sharing, linking) -> positive reponse, let's do it
- where to document? confluence vs. github wiki; online, collaborative editing vs. proper markup + editor support -> Decision: We will use github wiki for the log for now as it's something we will edit / write often and that's easier from an editor.
- monorepo vs. multiple repos? Decision: mono-repo all the way
- argued on the rationale behind the
waitclose in theon (ReqTx, tx)handler of the head protocol => allows for parties to wait for in-flight transactions which may happen due to the very concurrent nature of the protocol. - challenging the idea of representing the hydra head protocol as state machines. The protocol feels more like an event machine with event handlers reacting to specific messages.
- SN: research into node-to-node IPC of the cardano-node
- Design documents: network-design and network-spec
- outlines requirements and design decisions; a lot related to hard real-time and adversarial behavior of nodes (e.g. DoS)
- as for code,
txSubmissionOutboundlooks related to what we will be doing in Hydra, i.e. it retrieves tx from a mempool and responds with them in thetxSubmissionprotocol
(AB) went through the hydra paper again to refresh my memories (read it 2 months ago): The outline is relatively straightforward:
- a node initiate a head with some other parties by posting a tx with private tokens
- each participant commit some UTxO
- each participant post a tx "committing" some UTxO to be part of the head protocol's transactions
- leader node post a "collecting" transaction to consume the output of commit transactions and thus freeze the committed UTxOs for use in hydra
- nodes exchange txs using head protocol, acking and confirming them
- one node decides to close the head, posting a tx to the main chain with current (confirmed) state
- for some time, other nodes can post contest tx that incrementally add more (confirmed) state
- when timeout expires, initiator posts a fanout transaction consuming the committed UTxOs
start reading about cardano networking stuff, Duncan pointed me at what could be interesting for us: Network docs: https://github.com/input-output-hk/ouroboros-network/#ouroboros-network-documentation Consensus docs: https://github.com/input-output-hk/ouroboros-network/#ouroboros-consensus-documentation
miro board for today's whiteboarding session: https://miro.com/app/board/o9J_lRyWcSY=/
- defining I/O state machine from the point of view of various components of the system
- what about the OCV code? How is it implemented? It's already there in the mainchain
- snapshotting compresses the graph of UTxO, allows some form of privacy
- we don't validate TX in Hydra, we should make sure we keep isomorphic relationship between Hydra/Cardano processes; NOTE(SN): we do validate txs, but we should not re-implement the logic, but re-use; via library or IPC was quickly discussed
- what would be the kind of relationship between nodes and hydra
discussion about documentation. we all agree a lot of documentation explaining the hows of a code is a smell.
- how about using annotation plugins?
- linking haddock test modules to source modules
plan for tomorrow afternoon:
- see what the wallet is doing
- introduction to how everything is connected
- write a scenario that would be relevant to hydra
- "import" some code into our repo to start with
- bonus point: understand how to run that in CI?
- https://github.com/input-output-hk/cardano-wallet/blob/master/lib/shelley/exe/local-cluster.hs#L87 is the executable used to start a local cardano cluster
- need to test that, it's part of the cardano-wallet repository.
- going to spin up a dev vm for testing this stuff
silly issue when trying to clone hydra-node repository: ssh picked up the key loaded in the agent which is my private key, even though I explicitly set a key to use for iohk repos
needed to run ssh -v [email protected] and see the following transcript to understand what was going on:
OpenSSH_8.1p1, LibreSSL 2.7.3
debug1: Reading configuration data /Users/arnaud/.ssh/config
debug1: /Users/arnaud/.ssh/config line 12: Applying options for iohk.github.com
...
debug1: Will attempt key: /Users/arnaud/.ssh/id_rsa RSA SHA256:XE1CloHF1Nn3DXAgu7lyS/e9VK/sLF8icp+GrwLCYD4 agent
debug1: Will attempt key: /Users/arnaud/.ssh/id_rsa RSA agent
debug1: Will attempt key: /Users/arnaud/.ssh/id_rsa_iohk ED25519 explicit
...
debug1: Offering public key: /Users/arnaud/.ssh/id_rsa RSA SHA256:XE1CloHF1Nn3DXAgu7lyS/e9VK/sLF8icp+GrwLCYD4 agent
debug1: Server accepts key: /Users/arnaud/.ssh/id_rsa RSA SHA256:XE1CloHF1Nn3DXAgu7lyS/e9VK/sLF8icp+GrwLCYD4 agent
...
IOHK is using buildkite for CI: https://buildkite.com/input-output-hk
-
Meetings with the extended “team”: Had a discussion with Philipp Kant and then daily check-in with @Sebastian Nagel and @Matthias Benkort, mostly high level discussions about the project, what would be our first steps, what short-term goals would look like.
- discussing “competition”,
- https://lightning.network/
- https://docs.ethhub.io/ethereum-roadmap/layer-2-scaling/plasma/ : seems more like a framework than a protocol as the actual consensus is defined upon communications initiation
- discussing “competition”,
-
AB: Created IOHK specific handle on Github, abailly-iohk and joined private repos for hydra
-
AB: Going through the Hydra paper again, trying to build a somewhat detailed view of the various steps of the protocol in order to try to map that to future components/services/actors/things focusing on “simple” protocol first should be way enough to get us plenty of work in the next months
-
AB: Thoughts on things we could start working on soonish:
- Setting up a dedicated testnet of “hydra” nodes: Could be as simple as starting up with a bunch of plain cardano nodes with random TXs generators, the important thing being that we set up a running network early on and then deploy whatever implementation we build on this always-on network
- Reap out a “model” from Hydra simulator code and use it as a generator and oracle to test our implementation
- Setup a way for hydra nodes to talk to each other directly
-
SN: reviewed hydra-sim protocol logic
-
handleMessageis the central part which does aState -> Message -> Decision/Statetransformation - mixes Node state (e.g. confirmed utxo) with protocol state (i.e. message responses)
- also: "invalid" tx vs. invalid protocol state transitions
- many guards, remind me of structured operations semantics (SOS) rules -> ledger rules are also done that way?
-