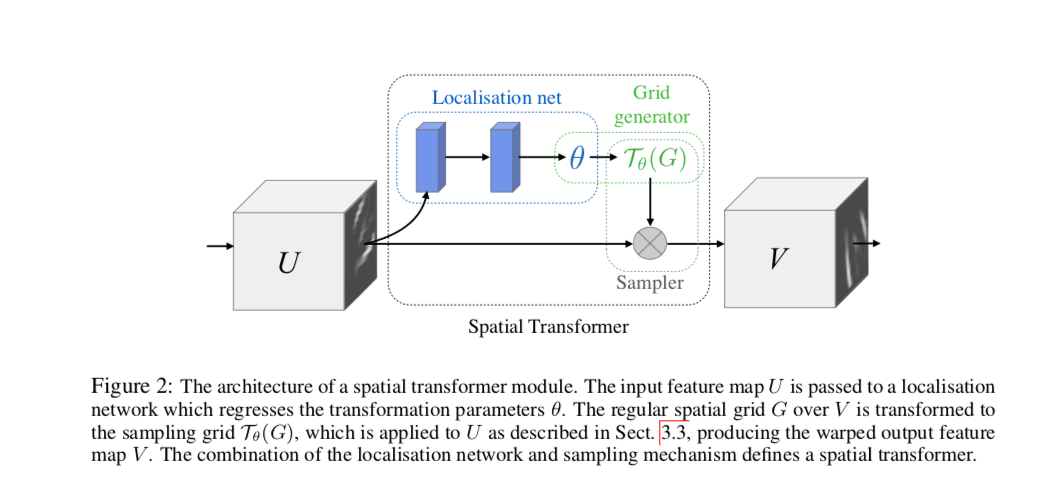
Spatial Transformers
- SPATIAL TRANSFORMER NETWORKS TUTORIAL
- ConvNets Series. Spatial Transformer Networks
- Part 3.1, page 8 Augmentation Deforming autoencoders (with Spatial Transformers used)
- "First, we introduce the Deforming Autoencoder architecture, bringing to- gether the deformable modeling paradigm with unsupervised deep learning. We treat the template-to-image correspondence task as that of predicting a smooth and invertible transformation. As shown in Fig. 1, our network first predicts a transformation field in tandem with a template-aligned appearance field. It subsequently deforms the synthesized appearance to generate an image similar to its input. This allows us to disentangle shape and appearance by explicitly modelling the effects of image deformation during decoding.
Second, we explore different ways in which deformations can be represented and predicted by the decoder. Instead of building a generic deformation model, we compose a global, affine deformation field, with a non-rigid field that is syn- thesized as a convolutional decoder network. We develop a method that prevents self-crossings in the synthesized deformation field and show that it simplifies training and improves accuracy. We also show that class-related information can be exploited, when available, to learn better deformation models: this yields sharper images and can be used to learn models that jointly account for multiple classes - e.g. all MNIST digits."
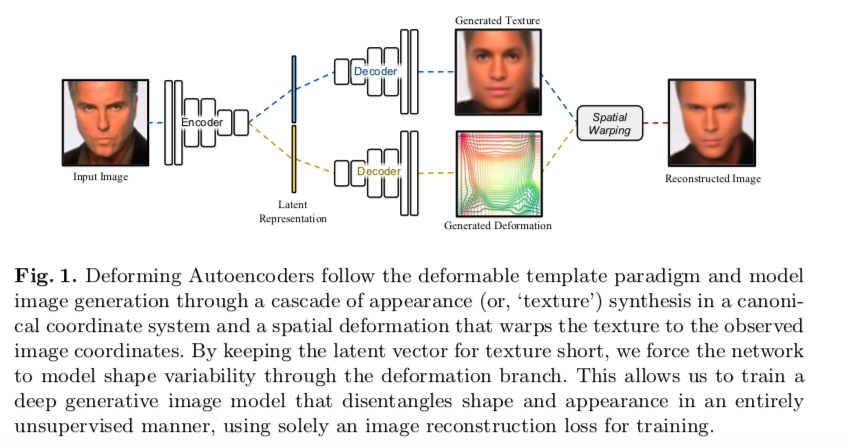
- "First, we introduce the Deforming Autoencoder architecture, bringing to- gether the deformable modeling paradigm with unsupervised deep learning. We treat the template-to-image correspondence task as that of predicting a smooth and invertible transformation. As shown in Fig. 1, our network first predicts a transformation field in tandem with a template-aligned appearance field. It subsequently deforms the synthesized appearance to generate an image similar to its input. This allows us to disentangle shape and appearance by explicitly modelling the effects of image deformation during decoding.
Second, we explore different ways in which deformations can be represented and predicted by the decoder. Instead of building a generic deformation model, we compose a global, affine deformation field, with a non-rigid field that is syn- thesized as a convolutional decoder network. We develop a method that prevents self-crossings in the synthesized deformation field and show that it simplifies training and improves accuracy. We also show that class-related information can be exploited, when available, to learn better deformation models: this yields sharper images and can be used to learn models that jointly account for multiple classes - e.g. all MNIST digits."
-
Spatial Transformer Networks
- Works with CNN
- Can be plugged into a network to handle spacial invariants. This network does something like this
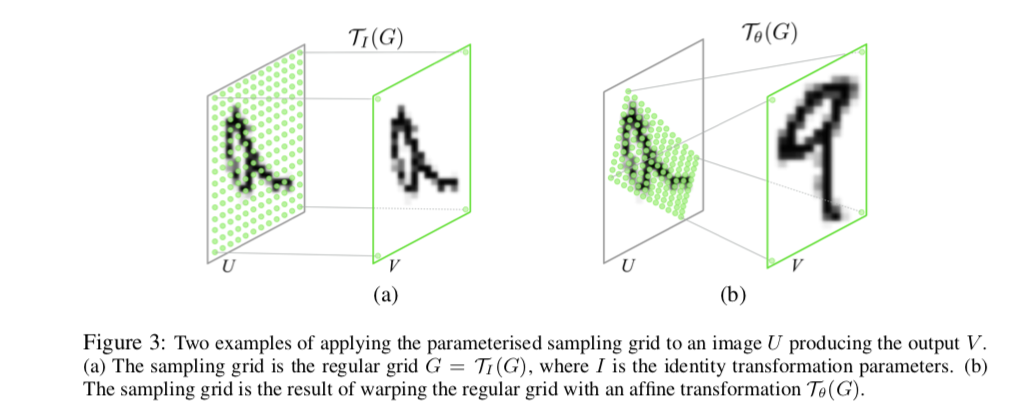
- "However, due to the typically small spatial support for max-pooling (e.g. 2 × 2 pixels) this spatial invariance is only realised over a deep hierarchy of max-pooling and convolutions, and the intermediate feature maps (convolutional layer activations) in a CNN are not actually invariant to large transformations of the input data "
- "In this work we introduce a Spatial Transformer module, that can be included into a standard neural network architecture to provide spatial transformation capabilities ."
- Architecture: