Evaluation strategy & performance metrics
Ideal train-validation-test split will look like:
- each subset has different patients
- training only on normal images
- ideally: the same nuber of positives/negatives in validation/test dataset
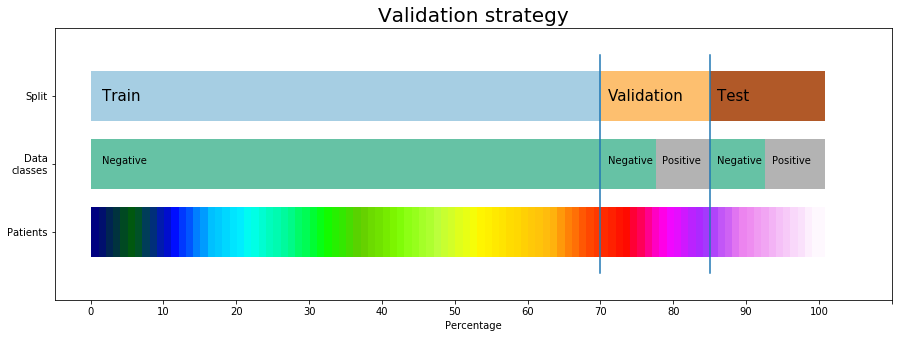
But if we want balanced number of labels in validation-test subset, the train set will be really small (50% only). Remember the distribution of labels:
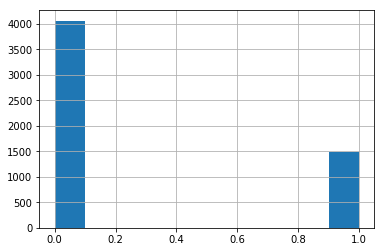
-
Train subset.
- Size: 3012
- Percentage from original data: 0.5145199863341305
- Percentage of negative samples in subset: 1.00. So that we train on normal images.
- Number of patients in subset: 1017
-
Validation subset.
- Size: 1419
- Percentage from original data: 0.2423983600956611
- Percentage of negative samples in subset: 0.485553206483439
- Number of patients in subset: 473
-
Test subset
- Size: 1423
- Percentage from original data: 0.24308165357020842
- Percentage of negative samples in subset: 0.4195361911454673
- Number of patients in subset: 474
- In validation/test subset - sort all images by outlier score values (different models have outlier scores).
- Define threshold by ROC analysis, calculate AUC.
- Calculate F1-score: