Faster and more memory efficient implementation of the Partial Convolution 2D layer in PyTorch equivalent to the standard Nvidia implementation.
This implementation has numerous advantages:
- It is strictly equivalent in computation to the reference implementation by Nvidia . I made unit tests to assess that all throughout development.
- It's commented and more readable
- It's faster and more memory efficient, which means you can use more layers on smaller GPUs. It's a good thing considering today's GPU prices.
- It's a PyPI-published library. You can
pipinstall it instead of copy/pasting source code, and get the benefit of ( free) bugfixes when someone notice a bug in the implementation.
pip3 install torch_pconvimport torch
from torch_pconv import PConv2d
images = torch.rand(32, 3, 256, 256)
masks = (torch.rand(32, 256, 256) > 0.5).to(torch.float32)
pconv = PConv2d(
in_channels=3,
out_channels=64,
kernel_size=7,
stride=1,
padding=2,
dilation=2,
bias=True
)
output, shrunk_masks = pconv(images, masks)You can find the reference implementation by Nvidia here .
I tested their implementation vs mine one the following configuration:
| Parameter | Value |
|---|---|
| in_channels | 64 |
| out_channels | 128 |
| kernel_size | 9 |
| stride | 1 |
| padding | 3 |
| bias | True |
| input height/width | 256 |
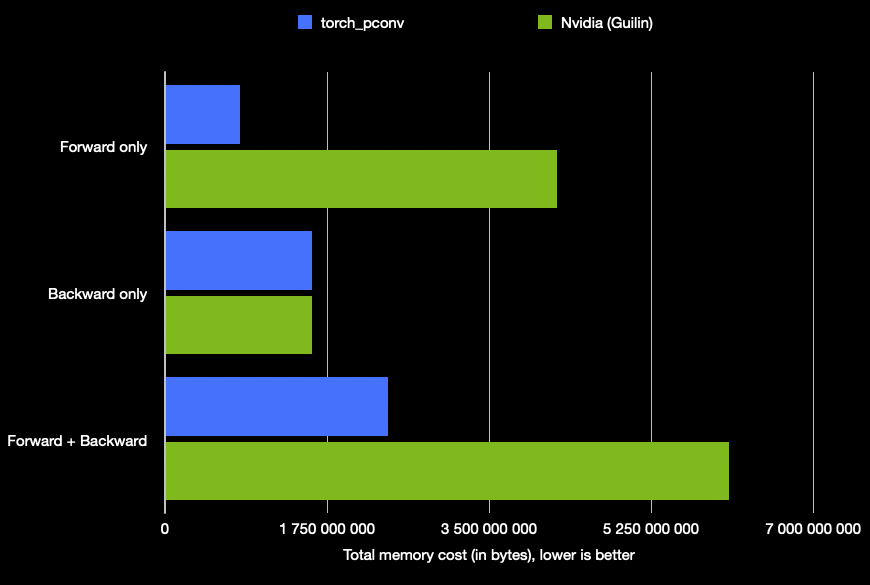
The goal here was to produce the most computationally expensive partial convolution operator so that the performance difference is displayed better.
I compute both the forward and the backward pass, in case one consumes more memory than the other.
torch_pconv | Nvidia® (Guilin) | |
|---|---|---|
| Forward only | 813 466 624 | 4 228 120 576 |
| Backward only | 1 588 201 480 | 1 588 201 480 |
| Forward + Backward | 2 405 797 640 | 6 084 757 512 |
To install the latest version from Github, run:
git clone [email protected]:DesignStripe/torch_pconv.git torch_pconv
cd torch_pconv
pip3 install -U .