{kind=link}
Omost 项目致力于将大型语言模型(LLM)的编码能力转化为图像生成(更准确地说,是图像合成)的能力。
Omost 这个名字(发音:almost 几乎)蕴含双重含义:1)每次使用 Omost 后,您的图像几乎已经成型;2)"O" 代表 "omni"(全模态),而 "most" 则意味着我们致力于挖掘其最大潜力。
Omost 提供了一系列大型语言模型(LLM),这些模型能够编写代码,通过 Omost 的虚拟画布代理来合成图像视觉内容。该画布可以通过特定的图像生成器实现来渲染,进而生成实际的图像。
目前,我们提供了基于 Llama3 和 Phi3 变体的 3 个预训练的大型语言模型(详见页面底部的模型注释)。
所有模型均经过了以下混合数据的训练:(1) 包括 Open-Images 在内多个数据集的地面真实注释;(2) 通过自动图像注释提取的数据;(3) 来自 DPO(直接偏好优化,以 "代码是否能够被 Python 3.10 编译" 作为直接偏好)的强化;以及 (4) 来自 OpenAI GPT4o 的少量多模态能力调整数据。
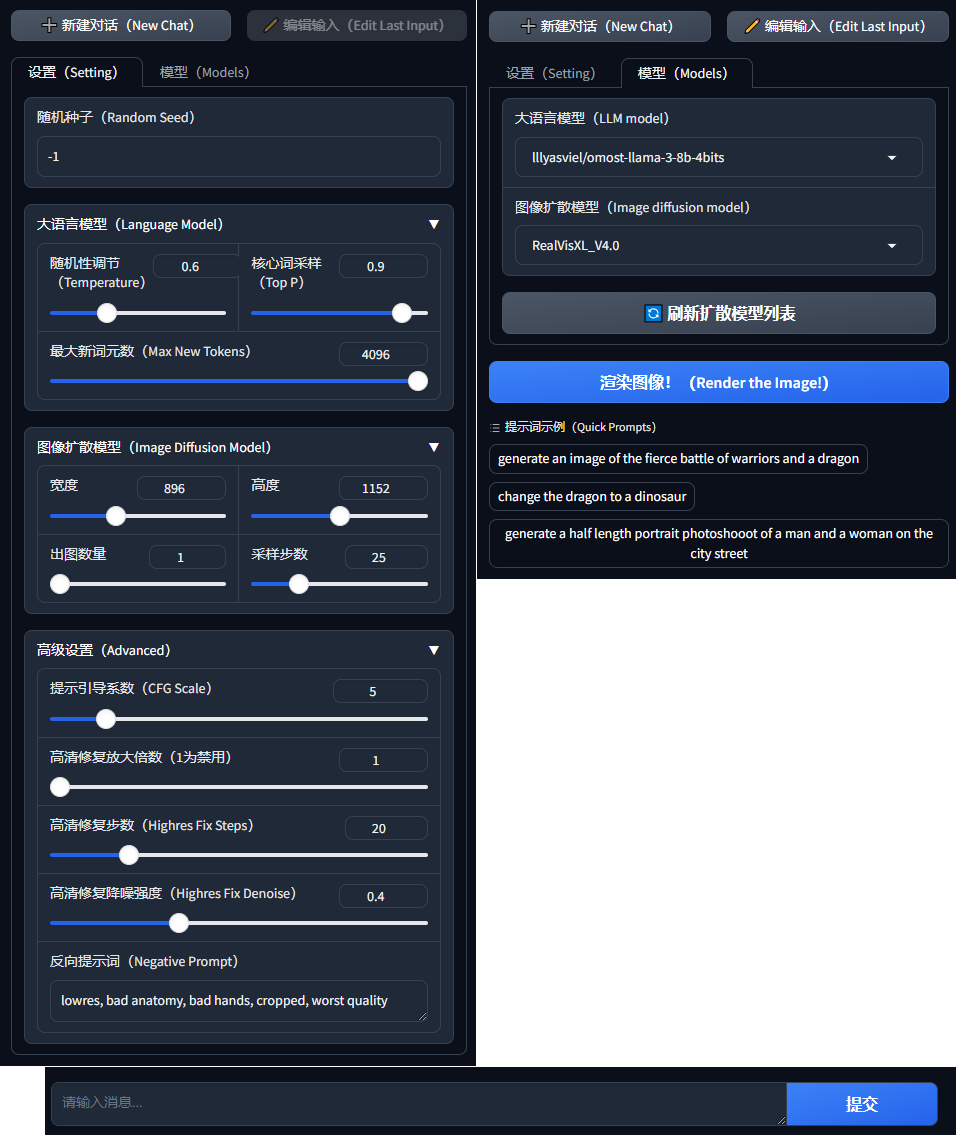
1、官方演示demo:你可以直接使用 官方的 HuggingFace 平台。
2、本地部署方法:
前提条件:(1) 对AI和图像生成概念有基本了解。(2) 本地电脑有至少 8GB 显存的 Nvidia 显卡。(3) 熟悉Python和命令行操作。
安装步骤:
1、安装 Conda,克隆 Omost 仓库(或者下载压缩包)。
2、创建 Conda 环境。
3、激活 Conda 环境。
4、安装 Omost 依赖项。
5、运行 gradio_app.py
git clone https://github.com/lllyasviel/Omost.git
cd Omost
conda create -n omost python=3.10
conda activate omost
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
python gradio_app.py
第一次安装成功启动后,下一次使用以下方法启动:
cd Omost
conda activate omost
python gradio_app.py
或者使用批处理文件启动 run_Omost.bat,会自动读取批处理文件当前目录下的Omost文件夹:
@echo off
cd /d "%~dp0Omost"
call conda activate omost
python gradio_app.py
pause
注意:量化的 LLM 需要 bitsandbytes 库。一些 9XX 系列、10XX 系列或 20XX 系列的 Nvidia GPU 在运行时可能会遇到问题。如果发生这种情况,请直接使用我们的官方 HuggingFace 平台。(我的 2070s-8G 可以运行。)
支持 huggingface 国内镜像站下载模型,支持读取本地 .safetensors 模型文件、列表选取、刷新列表,支持 LLM 模型列表选取(这个是huggingface缓存下载),支持图片保存按日期时间命名并保存到指定目录 outputs,-1 生成随机种子,在控制台打印各种信息包括加载的模型名称、使用的种子、对话和图像渲染的耗时等等。
Omost is a project to convert LLM's coding capability to image generation (or more accurately, image composing) capability.
The name Omost (pronunciation: almost) has two meanings: 1) everytime after you use Omost, your image is almost there; 2) the O mean "omni" (multi-modal) and most means we want to get the most out of it.
Omost provides LLMs models that will write codes to compose image visual contents with Omost's virtual Canvas agent. This Canvas can be rendered by specific implementations of image generators to actually generate images.
Currently, we provide 3 pretrained LLM models based on variations of Llama3 and Phi3 (see also the model notes at the end of this page).
All models are trained with mixed data of (1) ground-truth annotations of several datasets including Open-Images, (2) extracted data by automatically annotating images, (3) reinforcement from DPO (Direct Preference Optimization, "whether the codes can be compiled by python 3.10 or not" as a direct preference), and (4) a small amount of tuning data from OpenAI GPT4o's multi-modal capability.
You can just use the official HuggingFace space.
Or, you can use the below deployment (requires 8GB Nvidia VRAM):
git clone https://github.com/lllyasviel/Omost.git
cd Omost
conda create -n omost python=3.10
conda activate omost
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
python gradio_app.py
(Note that quant LLM requires bitsandbytes - some 9XX or 10XX or 20XX GPUs may have trouble in running it. If that happens, just use our official huggingface space.)
(All with random seed 12345)
a ragged man wearing a tattered jacket in the nineteenth century:


the greatest escape after the apocalypse, the hope of all humanity:


jurassic dinosaur battle:


the supreme ruler with endless magic on a gothic throne, with undead armies kneeling:


a funny cartoon batman fights joker:


(Below is a raw transcript from default model, with random seed 123456)
(If the GitHub's code block rendering is causing troubles to reading long lines, click here to read raw texts.)
generate an image of the fierce battle of warriors and the dragon
# Initialize the canvas
canvas = Canvas()
# Set a global description for the canvas
canvas.set_global_description(
description='A fierce battle between warriors and a dragon.',
detailed_descriptions=[
'In this intense scene, a group of fierce warriors is engaged in an epic battle with a mighty dragon.',
'The warriors, clad in armor and wielding swords and shields, are positioned on the left side of the image.',
'Their expressions are determined and focused, reflecting their resolve to defeat the dragon.',
'The dragon, with its massive wings spread wide and its fiery breath illuminating the scene, dominates the center of the image.',
'Its scales glisten with a metallic sheen, and its eyes burn with a fierce intensity.',
'The background is a dark, stormy sky with flashes of lightning, adding to the drama and tension of the battle.',
'The ground is littered with debris and the remnants of previous battles, enhancing the sense of a long and brutal conflict.',
'The overall atmosphere is one of chaos and intensity, with the warriors and the dragon locked in a fierce struggle for survival.',
],
tags='battle, warriors, dragon, fierce, armor, swords, shields, determined, focused, epic, intense, metallic, glistening, fiery breath, stormy sky, lightning, debris, conflict, struggle, survival, chaos, tension, drama, wings, scales, eyes, burning, illuminated',
HTML_web_color_name='darkslategray',
)
# Add a group of fierce warriors.
canvas.add_local_description(
location='on the left',
offset='no offset',
area='a large horizontal area',
distance_to_viewer=5.0,
description='A group of fierce warriors.',
detailed_descriptions=[
'The warriors, clad in gleaming armor, are positioned on the left side of the image.',
'They are armed with swords, shields, and spears, ready for battle.',
'Their faces are set with determination and focus, reflecting their resolve to defeat the dragon.',
'Some warriors are in mid-action, swinging their swords or shields, while others stand ready to strike.',
'The armor they wear is intricately designed, with symbols and patterns that signify their rank and bravery.',
'The ground beneath them is uneven and littered with debris, adding to the sense of a chaotic and intense battle.',
],
tags='warriors, armor, swords, shields, spears, determined, focused, mid-action, intricate design, symbols, patterns, rank, bravery, uneven ground, debris, chaotic, intense, battle',
atmosphere='Determined and focused, ready for the fierce battle.',
style='Highly detailed and dynamic, capturing the intensity of the warriors.',
quality_meta='High resolution with intricate details and dynamic poses.',
HTML_web_color_name='darkgoldenrod',
)
# Add a mighty dragon.
canvas.add_local_description(
location='in the center',
offset='no offset',
area='a large square area',
distance_to_viewer=7.0,
description='A mighty dragon.',
detailed_descriptions=[
'The dragon is a massive creature, dominating the center of the image with its wide-spread wings and fiery breath.',
'Its scales glisten with a metallic sheen, reflecting the light from its fiery breath.',
"The dragon's eyes burn with a fierce intensity, and its teeth are sharp and menacing.",
'The wings of the dragon are powerful and spread wide, casting shadows over the battlefield.',
'The dragon’s body is muscular and covered in protective scales, with a long, sinewy tail that adds to its formidable appearance.',
'The fiery breath of the dragon illuminates the scene, casting a reddish glow over the warriors and the battlefield.',
],
tags='dragon, massive, wings, fiery breath, glistening scales, metallic sheen, fierce eyes, sharp teeth, powerful wings, shadows, battlefield, muscular body, protective scales, sinewy tail, formidable, reddish glow, illumination',
atmosphere='Intense and menacing, with a powerful presence.',
style='Epic and dramatic, emphasizing the grandeur and danger of the dragon.',
quality_meta='High resolution with dramatic lighting and detailed textures.',
HTML_web_color_name='firebrick',
)
# Add a stormy sky with flashes of lightning.
canvas.add_local_description(
location='on the top',
offset='no offset',
area='a large horizontal area',
distance_to_viewer=10.0,
description='A stormy sky with flashes of lightning.',
detailed_descriptions=[
'The background of the image is a dark, stormy sky filled with swirling clouds and flashes of lightning.',
'The sky is turbulent, with clouds dark and foreboding, adding to the dramatic tension of the battle.',
'The lightning flashes illuminate the scene, casting sharp, brief lights over the warriors and the dragon.',
'The stormy sky creates a sense of chaos and unpredictability, heightening the intensity of the battle below.',
'The overall atmosphere is one of impending doom and relentless conflict, with the storm mirroring the fierce struggle between the warriors and the dragon.',
],
tags='stormy sky, dark clouds, lightning, turbulent, foreboding, dramatic tension, illumination, chaos, unpredictability, intensity, impending doom, relentless conflict, battle, warriors, dragon, swirling clouds, sharp lights, brief lights',
atmosphere='Chaotic and intense, mirroring the fierce battle below.',
style='Dramatic and turbulent, emphasizing the conflict and tension.',
quality_meta='High resolution with dynamic lighting and detailed cloud textures.',
HTML_web_color_name='midnightblue',
)
# Add a debris-covered battlefield.
canvas.add_local_description(
location='on the bottom',
offset='no offset',
area='a large horizontal area',
distance_to_viewer=5.0,
description='A debris-covered battlefield.',
detailed_descriptions=[
'The ground of the battlefield is littered with debris, remnants of previous battles.',
'Broken weapons, shattered shields, and scattered armor pieces are strewn across the battlefield.',
'The terrain is uneven, with patches of mud and dirt, adding to the sense of a long and brutal conflict.',
'The debris-covered battlefield enhances the chaotic and intense atmosphere of the scene, reflecting the ferocity and duration of the battle.',
'The overall appearance is one of destruction and turmoil, with the remnants of previous battles serving as a grim reminder of the ongoing struggle.',
],
tags='battlefield, debris, broken weapons, shattered shields, scattered armor, uneven terrain, mud, dirt, brutal conflict, chaos, intensity, destruction, turmoil, previous battles, ongoing struggle, remnants, ferocity, duration',
atmosphere='Chaotic and intense, reflecting the ferocity of the battle.',
style='Detailed and realistic, emphasizing the destruction and chaos.',
quality_meta='High resolution with detailed textures and realistic debris.',
HTML_web_color_name='darkolivegreen',
)change the dragon to a dinosaur
# Initialize the canvas
canvas = Canvas()
# Set a global description for the canvas
canvas.set_global_description(
description='A fierce battle between warriors and a dinosaur.',
detailed_descriptions=[
'In this intense scene, a group of fierce warriors is engaged in an epic battle with a mighty dinosaur.',
'The warriors, clad in armor and wielding swords and shields, are positioned on the left side of the image.',
'Their expressions are determined and focused, reflecting their resolve to defeat the dinosaur.',
'The dinosaur, with its massive body and powerful legs, dominates the center of the image.',
'Its scales glisten with a metallic sheen, and its eyes burn with a fierce intensity.',
'The background is a dark, stormy sky with flashes of lightning, adding to the drama and tension of the battle.',
'The ground is littered with debris and the remnants of previous battles, enhancing the sense of a long and brutal conflict.',
'The overall atmosphere is one of chaos and intensity, with the warriors and the dinosaur locked in a fierce struggle for survival.',
],
tags='battle, warriors, dinosaur, fierce, armor, swords, shields, determined, focused, epic, intense, metallic, glistening, stormy sky, lightning, debris, conflict, struggle, survival, chaos, tension, drama, powerful legs, scales, eyes, burning, illuminated',
HTML_web_color_name='darkslategray',
)
# Add a group of fierce warriors.
canvas.add_local_description(
location='on the left',
offset='no offset',
area='a large horizontal area',
distance_to_viewer=5.0,
description='A group of fierce warriors.',
detailed_descriptions=[
'The warriors, clad in gleaming armor, are positioned on the left side of the image.',
'They are armed with swords, shields, and spears, ready for battle.',
'Their faces are set with determination and focus, reflecting their resolve to defeat the dinosaur.',
'Some warriors are in mid-action, swinging their swords or shields, while others stand ready to strike.',
'The armor they wear is intricately designed, with symbols and patterns that signify their rank and bravery.',
'The ground beneath them is uneven and littered with debris, adding to the sense of a chaotic and intense battle.',
],
tags='warriors, armor, swords, shields, spears, determined, focused, mid-action, intricate design, symbols, patterns, rank, bravery, uneven ground, debris, chaotic, intense, battle',
atmosphere='Determined and focused, ready for the fierce battle.',
style='Highly detailed and dynamic, capturing the intensity of the warriors.',
quality_meta='High resolution with intricate details and dynamic poses.',
HTML_web_color_name='darkgoldenrod',
)
# Add a mighty dinosaur.
canvas.add_local_description(
location='in the center',
offset='no offset',
area='a large square area',
distance_to_viewer=7.0,
description='A mighty dinosaur.',
detailed_descriptions=[
'The dinosaur is a massive creature, dominating the center of the image with its powerful legs and fierce roar.',
'Its scales glisten with a metallic sheen, reflecting the light from the stormy sky.',
"The dinosaur's eyes burn with a fierce intensity, and its teeth are sharp and menacing.",
'The powerful legs of the dinosaur are muscular and add to its formidable appearance.',
'The ground shakes beneath its feet, enhancing the sense of a long and brutal conflict.',
'The overall appearance is one of destruction and turmoil, with the dinosaur adding to the chaotic atmosphere.',
],
tags='dinosaur, massive, powerful legs, fierce roar, glistening scales, metallic sheen, fierce eyes, sharp teeth, muscular legs, formidable, ground shaking, destruction, turmoil, chaos, battle',
atmosphere='Intense and menacing, with a powerful presence.',
style='Epic and dramatic, emphasizing the grandeur and danger of the dinosaur.',
quality_meta='High resolution with dramatic lighting and detailed textures.',
HTML_web_color_name='firebrick',
)
# Add a stormy sky with flashes of lightning.
canvas.add_local_description(
location='on the top',
offset='no offset',
area='a large horizontal area',
distance_to_viewer=10.0,
description='A stormy sky with flashes of lightning.',
detailed_descriptions=[
'The background of the image is a dark, stormy sky filled with swirling clouds and flashes of lightning.',
'The sky is turbulent, with clouds dark and foreboding, adding to the dramatic tension of the battle.',
'The lightning flashes illuminate the scene, casting sharp, brief lights over the warriors and the dinosaur.',
'The stormy sky creates a sense of chaos and unpredictability, heightening the intensity of the battle below.',
'The overall atmosphere is one of impending doom and relentless conflict, with the storm mirroring the fierce struggle between the warriors and the dinosaur.',
],
tags='stormy sky, dark clouds, lightning, turbulent, foreboding, dramatic tension, illumination, chaos, unpredictability, intensity, impending doom, relentless conflict, battle, warriors, dinosaur, swirling clouds, sharp lights, brief lights',
atmosphere='Chaotic and intense, mirroring the fierce battle below.',
style='Dramatic and turbulent, emphasizing the conflict and tension.',
quality_meta='High resolution with dynamic lighting and detailed cloud textures.',
HTML_web_color_name='midnightblue',
)
# Add a debris-covered battlefield.
canvas.add_local_description(
location='on the bottom',
offset='no offset',
area='a large horizontal area',
distance_to_viewer=5.0,
description='A debris-covered battlefield.',
detailed_descriptions=[
'The ground of the battlefield is littered with debris, remnants of previous battles.',
'Broken weapons, shattered shields, and scattered armor pieces are strewn across the battlefield.',
'The terrain is uneven, with patches of mud and dirt, adding to the sense of a long and brutal conflict.',
'The debris-covered battlefield enhances the chaotic and intense atmosphere of the scene, reflecting the ferocity and duration of the battle.',
'The overall appearance is one of destruction and turmoil, with the remnants of previous battles serving as a grim reminder of the ongoing struggle.',
],
tags='battlefield, debris, broken weapons, shattered shields, scattered armor, uneven terrain, mud, dirt, brutal conflict, chaos, intensity, destruction, turmoil, previous battles, ongoing struggle, remnants, ferocity, duration',
atmosphere='Chaotic and intense, reflecting the ferocity of the battle.',
style='Detailed and realistic, emphasizing the destruction and chaos.',
quality_meta='High resolution with detailed textures and realistic debris.',
HTML_web_color_name='darkolivegreen',
)(User can click the render button to actually render the image from any of those Canvas instances.)



All Omost LLMs are trained to obey the following symbols
class Canvas:
def set_global_description(
self,
description: str,
detailed_descriptions: list[str],
tags: str,
HTML_web_color_name: str
):
pass
def add_local_description(
self,
location: str,
offset: str,
area: str,
distance_to_viewer: float,
description: str,
detailed_descriptions: list[str],
tags: str,
atmosphere: str,
style: str,
quality_meta: str,
HTML_web_color_name: str
):
assert location in [
"in the center",
"on the left",
"on the right",
"on the top",
"on the bottom",
"on the top-left",
"on the top-right",
"on the bottom-left",
"on the bottom-right"
]
assert offset in [
"no offset",
"slightly to the left",
"slightly to the right",
"slightly to the upper",
"slightly to the lower",
"slightly to the upper-left",
"slightly to the upper-right",
"slightly to the lower-left",
"slightly to the lower-right"
]
assert area in [
"a small square area",
"a small vertical area",
"a small horizontal area",
"a medium-sized square area",
"a medium-sized vertical area",
"a medium-sized horizontal area",
"a large square area",
"a large vertical area",
"a large horizontal area"
]
assert distance_to_viewer > 0
passDuring training, the above symbols are associated with specific concepts and use cases related to image generation.
The design is to make those codes easy to learn for LLMs, but also easy to handle for diffusion models.
Lets breakdown each part:
They set descriptions to images. The meanings of the parameters are same for them, with add_local_description having more fields than set_global_description.
The set_global_description annotate entire image, while add_local_description annotates a part of image.
Let us introduce a concept called "sub-prompt". If a prompt is less than 75 tokens, and is self-supported to describe a thing without relying on other prompts, we call it a "sub-prompt".
The description is a sub-prompt, and the detailed_descriptions is a list of sub-prompts.
Note that each sub-prompt is strictly less than 75 tokens (and typically less than 40 tokens), you can safely encode them with any clip without worrying the truncation position affecting the semantics.
The design of sub-prompt also allows more satisfying text encoding based on greedy merge. For example, if you have
sub-prompt A: 25 tokens
sub-prompt B: 35 tokens
sub-prompt C: 5 tokens
sub-prompt D: 60 tokens
sub-prompt E: 15 tokens
sub-prompt F: 25 tokens
and since every sub-prompt is promised to be self-supported to describe a thing independently, we can use greedy method to merge them to bags like
bag 1 {A, B, C} : 65 tokens
bag 2 {D} : 60 tokens
bag 1 {E, F} : 40 tokens
where each bag is less than 75 tokens and can be encoded by any clip in one pass (and then concat them).
Encoding texts in this way will make sure that text-encoder will never make semantic truncation mistakes.
One may ask - if all sub-prompts are less than 75 tokens with independent semantics, why not just encode them without merge and then concat? This is mainly because we want the text embedding to be more coherent. For example, lets say sub-prompt A is "a man" while sub-prompt B is "handsome, professional", then merging them before encoding will give you a more mixed text embedding concept with coherent features of a handsome professional man.
All Omost LLMs are trained to give strictly well-defined sub-prompts. You can make use of these definitions to design lossless text encoding methods.
The three parameters defines a bounding box. Note that they must obey
assert location in [
"in the center",
"on the left",
"on the right",
"on the top",
"on the bottom",
"on the top-left",
"on the top-right",
"on the bottom-left",
"on the bottom-right"
]
assert offset in [
"no offset",
"slightly to the left",
"slightly to the right",
"slightly to the upper",
"slightly to the lower",
"slightly to the upper-left",
"slightly to the upper-right",
"slightly to the lower-left",
"slightly to the lower-right"
]
assert area in [
"a small square area",
"a small vertical area",
"a small horizontal area",
"a medium-sized square area",
"a medium-sized vertical area",
"a medium-sized horizontal area",
"a large square area",
"a large vertical area",
"a large horizontal area"
]First we divide a canvas into 3*3=9 locations:

Then we further divide each location to 3*3 offsets, resulting in 9*9=81 positions:

Using these positions as centers, we further define 9 types of bounding boxes:

We can see that this method allows 9*9*9=729 different bounding boxes, covering almost all common possible locations of an object in the image.
One may argue that why this is necessary - why not just let the LLMs to learn pixel index or x, y coordinates - and should that be much more accurate? Below is several of my notes:
- I have tried several representations, including pixel index like {x=32, y=16, w=58, h=99}, or margin pixels like {left=32, right=15, top=27, bottom=33}, or percentage pixel index like {x=0.124, y=0.65, w=0.335, h=0.251}, or percentage margin like {left=0.251, right=0.154, top=0.254, bottom=0.441}. The result is that opensource LLMs are really not very good at learning these representations even for Llama3 (perhaps GPT4o can learn it). Sometimes it works sometimes it gives completely random numbers. Note that our problem is very different from MLLM. The vision-LLM usually have image embedding as inputs and in that case estimating numeric position is like a look-up table problem and can somewhat be learned, but our case is where the LLM need to generate every composition from scratch without help of any image embedding to look-up.
- But the natural language like "on the right", "slightly to the top-right", "a small vertical area" etc, works very well. The model converges very fast and the learning is stable. It aligns to the pretrained knowledge of LLMs very well.
- I have also tried adding some special tokens to represent spatial locations and also train the embedding layers. But that model is very difficult to train and debug. Also, the token-embedding-based method needs many hyperparameter tuning everytime we change the LLM - for example when changing from Llama3 to Phi, if we use the token-embedding method, we need to design training parameters again.
- The number 9*9*9=729 is not really a small number from the perspective of bounding box proposals. This can also be called ROI (region of interest) and some old semantic segmentation tech uses (RPN) Region Proposal Network to produce a similar number (<1000) of regions.
- Most region-guided diffusion methods are coarse-level methods (like multi-diffusion and attention couple and gligen), and they do not need pixel-perfect regions.
- These are very personal results from me - if you are working on some similar multi-modal LLM research, using pixel indices is completely okay, worth trying, and probably other training methods can also achieve a robust system.
The distance_to_viewer can be viewed as relative depth. Note that this value's absolute number is not reliable at all (because opensource LLMs are not very good at producing image-space numbers) and it should only be used in sorting elements into background-to-foreground layers.
You can always use distance_to_viewer to sort all local elements before rendering them using a diffusion model. The global description can be always viewed as the most far away background layer.
The HTML_web_color_name is one of these:
possible_HTML_web_color_names = { # r, g, b
'aliceblue': (240, 248, 255), 'antiquewhite': (250, 235, 215), 'aqua': (0, 255, 255),
'aquamarine': (127, 255, 212), 'azure': (240, 255, 255), 'beige': (245, 245, 220),
'bisque': (255, 228, 196), 'black': (0, 0, 0), 'blanchedalmond': (255, 235, 205), 'blue': (0, 0, 255),
'blueviolet': (138, 43, 226), 'brown': (165, 42, 42), 'burlywood': (222, 184, 135),
'cadetblue': (95, 158, 160), 'chartreuse': (127, 255, 0), 'chocolate': (210, 105, 30),
'coral': (255, 127, 80), 'cornflowerblue': (100, 149, 237), 'cornsilk': (255, 248, 220),
'crimson': (220, 20, 60), 'cyan': (0, 255, 255), 'darkblue': (0, 0, 139), 'darkcyan': (0, 139, 139),
'darkgoldenrod': (184, 134, 11), 'darkgray': (169, 169, 169), 'darkgrey': (169, 169, 169),
'darkgreen': (0, 100, 0), 'darkkhaki': (189, 183, 107), 'darkmagenta': (139, 0, 139),
'darkolivegreen': (85, 107, 47), 'darkorange': (255, 140, 0), 'darkorchid': (153, 50, 204),
'darkred': (139, 0, 0), 'darksalmon': (233, 150, 122), 'darkseagreen': (143, 188, 143),
'darkslateblue': (72, 61, 139), 'darkslategray': (47, 79, 79), 'darkslategrey': (47, 79, 79),
'darkturquoise': (0, 206, 209), 'darkviolet': (148, 0, 211), 'deeppink': (255, 20, 147),
'deepskyblue': (0, 191, 255), 'dimgray': (105, 105, 105), 'dimgrey': (105, 105, 105),
'dodgerblue': (30, 144, 255), 'firebrick': (178, 34, 34), 'floralwhite': (255, 250, 240),
'forestgreen': (34, 139, 34), 'fuchsia': (255, 0, 255), 'gainsboro': (220, 220, 220),
'ghostwhite': (248, 248, 255), 'gold': (255, 215, 0), 'goldenrod': (218, 165, 32),
'gray': (128, 128, 128), 'grey': (128, 128, 128), 'green': (0, 128, 0), 'greenyellow': (173, 255, 47),
'honeydew': (240, 255, 240), 'hotpink': (255, 105, 180), 'indianred': (205, 92, 92),
'indigo': (75, 0, 130), 'ivory': (255, 255, 240), 'khaki': (240, 230, 140), 'lavender': (230, 230, 250),
'lavenderblush': (255, 240, 245), 'lawngreen': (124, 252, 0), 'lemonchiffon': (255, 250, 205),
'lightblue': (173, 216, 230), 'lightcoral': (240, 128, 128), 'lightcyan': (224, 255, 255),
'lightgoldenrodyellow': (250, 250, 210), 'lightgray': (211, 211, 211), 'lightgrey': (211, 211, 211),
'lightgreen': (144, 238, 144), 'lightpink': (255, 182, 193), 'lightsalmon': (255, 160, 122),
'lightseagreen': (32, 178, 170), 'lightskyblue': (135, 206, 250), 'lightslategray': (119, 136, 153),
'lightslategrey': (119, 136, 153), 'lightsteelblue': (176, 196, 222), 'lightyellow': (255, 255, 224),
'lime': (0, 255, 0), 'limegreen': (50, 205, 50), 'linen': (250, 240, 230), 'magenta': (255, 0, 255),
'maroon': (128, 0, 0), 'mediumaquamarine': (102, 205, 170), 'mediumblue': (0, 0, 205),
'mediumorchid': (186, 85, 211), 'mediumpurple': (147, 112, 219), 'mediumseagreen': (60, 179, 113),
'mediumslateblue': (123, 104, 238), 'mediumspringgreen': (0, 250, 154),
'mediumturquoise': (72, 209, 204), 'mediumvioletred': (199, 21, 133), 'midnightblue': (25, 25, 112),
'mintcream': (245, 255, 250), 'mistyrose': (255, 228, 225), 'moccasin': (255, 228, 181),
'navajowhite': (255, 222, 173), 'navy': (0, 0, 128), 'navyblue': (0, 0, 128),
'oldlace': (253, 245, 230), 'olive': (128, 128, 0), 'olivedrab': (107, 142, 35),
'orange': (255, 165, 0), 'orangered': (255, 69, 0), 'orchid': (218, 112, 214),
'palegoldenrod': (238, 232, 170), 'palegreen': (152, 251, 152), 'paleturquoise': (175, 238, 238),
'palevioletred': (219, 112, 147), 'papayawhip': (255, 239, 213), 'peachpuff': (255, 218, 185),
'peru': (205, 133, 63), 'pink': (255, 192, 203), 'plum': (221, 160, 221), 'powderblue': (176, 224, 230),
'purple': (128, 0, 128), 'rebeccapurple': (102, 51, 153), 'red': (255, 0, 0),
'rosybrown': (188, 143, 143), 'royalblue': (65, 105, 225), 'saddlebrown': (139, 69, 19),
'salmon': (250, 128, 114), 'sandybrown': (244, 164, 96), 'seagreen': (46, 139, 87),
'seashell': (255, 245, 238), 'sienna': (160, 82, 45), 'silver': (192, 192, 192),
'skyblue': (135, 206, 235), 'slateblue': (106, 90, 205), 'slategray': (112, 128, 144),
'slategrey': (112, 128, 144), 'snow': (255, 250, 250), 'springgreen': (0, 255, 127),
'steelblue': (70, 130, 180), 'tan': (210, 180, 140), 'teal': (0, 128, 128), 'thistle': (216, 191, 216),
'tomato': (255, 99, 71), 'turquoise': (64, 224, 208), 'violet': (238, 130, 238),
'wheat': (245, 222, 179), 'white': (255, 255, 255), 'whitesmoke': (245, 245, 245),
'yellow': (255, 255, 0), 'yellowgreen': (154, 205, 50)
}By combining distance_to_viewer and HTML_web_color_name, you can draw a very coarse image of the composition. For example, if the LLM works well, "a green bottle in front of a red bottle on a wood table in a dark room" should make it possible for you to compute an image like:

You can use this image as an initial latent and use denoise strength like 0.95 to 0.99 to generate the image.
Or if you do not like this and still prefer to let diffusion models to generate from zero-mean (even when you know that most diffusion models have tsnr problems), you can ignore this image and or just use this image as a debugger.
Besides, the layer sorting can also be useful in some very special attention formulation - we will discuss this later.
The tags is designed as a possible replacement for the description since many diffusion models prefer tags. If used with anime models, one may hard code some logics to replace all "girl" to "1girl". If used with Pony then probably always hard code adding "score_9, score_8 ..." to this.
The atmosphere and style and quality_meta are some experimental parameters without very specific use cases. Current we can just treat them as sub-prompts and involve them in the greedy merge of sub-prompt bags. This in my experiments will improve the atmosphere and quality a bit.
In this repo, we provide a baseline render for Omost LLMs based on attention manipulation.
As of 2024, if we want to achieve a region guided diffusion system, some possible options are:
- multi-diffusion / mixture-of-diffusers: these method run UNet on different locations, and then merge the estimated epsilon or x0 using weights or masks for different regions.
- attention decomposition: lets say attention is like
y=softmax(q@k)@v, then one can achieve attention decomposition likey=mask_A * softmax(q@k_A)@v_A + mask_B * softmax(q@k_B)@v_Bwhere mask_A, k_A, v_A are masks, k, v for region A; mask_B, k_B, v_B are masks, k, v for region B. This method usually yields image quality a bit better than (1) and some people call it Attention Couple or Region Prompter Attention Mode. But this method has a consideration: the mask only makes regional attention numerically possible, but it does not force the UNet to really attend its activations in those regions. That is to say, the attention is indeed masked, but there is no promise that the attention softmax will really be activated in the masked area, and there is also no promise that the attention softmax will never be activated outside the masked area. - attention score manipulation: this is a more advanced method compared to (2). It directly manipulates the attention scores to make sure that the activations in mask each area are encouraged and those outside the masks are discouraged. The formulation is like
y=softmax(modify(q@k))@vwheremodify()is a complicated non-linear function with many normalizations and tricks to change the score's distributions. This method goes beyond a simple masked attention to really make sure that those layers get wanted activations. A typical example is Dense Diffusion. - gradient optimization: since the attention can tell us where each part is corresponding to what prompts, we can split prompts into segments and then get attention activations to each prompt segment. Then we compare those activations with external masks to compute a loss function, and back propagate the gradients. Those methods are usually very high quality but VRAM hungry and very slow. Typical methods are BoxDiff and Attend-and-Excite.
- Use external control models like gligen and InstanceDiffusion. Those methods give the highest benchmark performance on region following but will also introduce some style offset to the base model since they are trained parameters. Also, those methods need to convert prompts to vectors and usually do not support prompts of arbitary length (but one can use them together with other attention methods to achieve arbitrary length).
- Some more possible layer options like layerdiffuse and mulan.
In this repo I wrote a baseline formulation based on (3). I consider this parameter-free formulation as a very standard baseline implementation that will almost introduce zero style offsets or quality degradation. In the future we may consider training some parametrized methods for Omost.
Lets consider an extremely simplified image with only 2*2=4 pixels:

Then we have three prompts "two cats", "a black cat", "a white cat", and we have their masks:

Then we can draw this attention score table:

where the upper arrow mean that we want to encourage the activation, while the lower arrow means we want to get rid of those activation.
This manipulation directly modify attention scores and compute all prompts conditions in one single SDP attention pass. (See also the codes for more details.)
In this repo, I also included another trick that I find out to improve prompt understanding a lot. Lets call it a Prompt Prefix Tree. The motivation is that, since now that all our prompts are sub-prompts that can be merged arbitrarily (recall that all sub-prompts are strictly less than 75 tokens and typically less than 40 tokens, describe independent concepts, and can be arbitrarily merged as common prompts for clip to encode), finding a better method to merge those sub-prompts may improve the results and prompt interpretation.
For example below is a tree structure of global/local overall/detailed descriptions.

The idea is that, since all sub-prompts can be merged arbitrarily, we can use the paths in this tree graph as prompts.
For example the below path will give a prompt "A cat and a dog. The cat on sofa."

Note that we can use this together with greedy subprompt bag merging when a path exceed 75 tokens. And, if a path has remaining place to contain more subprompts, the greedy subprompt bag merging will also take care of it. And again, since all sub prompts describe independent concepts, the greedy subprompt bag merging never makes semantic truncation mistakes. So satisfying!
Currently, we provide 3 models (you can get them by adding the prefix https://huggingface.co/lllyasviel/ to the below names):
omost-llama-3-8b
omost-dolphin-2.9-llama3-8b
omost-phi-3-mini-128k
And their quant versions:
omost-llama-3-8b-4bits
omost-dolphin-2.9-llama3-8b-4bits
omost-phi-3-mini-128k-8bits
Some notes:
- The recommended quant for
omost-llama-3-8bis 4bits, and foromost-phi-3-mini-128k(3.8B) is 8 bits. They all fit in 8GB VRAM without offloads. The performance degradation caused by quant is very minimal and I personally never observed any evidences of degradation. However, quantomost-phi-3-mini-128kinto 4 bits is not recommended since I noticed some obvious performance degradation. The 4bit inference ofomost-phi-3-mini-128kshould be viewed as a last method in extreme cases when you really do not have more capable GPUs. - My user study shows that
omost-llama-3-8b-4bits>omost-dolphin-2.9-llama3-8b-4bits>omost-phi-3-mini-128k-8bits. So in most cases one should just useomost-llama-3-8b-4bits. - The
omost-llama-3-8bandomost-phi-3-mini-128kare trained with filtered safe data without NSFW or inappropriate contents. See (4) if you need a different option. - The
omost-dolphin-2.9-llama3-8bis trained with all data WITHOUT any filtering. You must apply your own safety alignment methods if you expose any service ofomost-dolphin-2.9-llama3-8bto public. - Note that the filtering in (3) is not because of any policy - the reason is that I noticed slight instability in training gradients in those models since they are pretrained with instruct following regulated by safety alignment, causing the performance to degrade a bit. But the instruct following of
omost-dolphin-2.9-llama3-8bis pretrained with community efforts and do not have this problem. - The 128k context length of
omost-phi-3-mini-128kcannot be trusted. The performance of it will degrade a lot after the tokens reach about 8k. One should just view it as a model with about 8k content length. - A model of 8k context length can do about 5 to 6 rounds of conversational editing. If you are about to run out of token lengths, use the UI to modify your message and respond again (this can be done with infinite times).
- All models are fully trained with our H100 clusters at precision fp16 without any tricks like quant or Q-LoRA etc. The optimizer is Adam without any tricks.
- You must also follow the licenses of Llama-3 and Phi-3.
- You can request us to train on other LLMs if reasonable and necessary.
@Misc{omost,
author = {Omost Team},
title = {Omost GitHub Page},
year = {2024},
}
Also read ...
DOCCI: Descriptions of Connected and Contrasting Images
Ranni: Taming Text-to-Image Diffusion for Accurate Instruction Following
LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models and Self-correcting LLM-controlled Diffusion Models
MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
(please open issue or email me if you want to add more links here)