Hardware-accelerated, deep learned model support for object detection including DetectNet.


Isaac ROS Object Detection contains an ROS 2 package to perform object
detection. isaac_ros_detectnet provides a method for spatial
classification using bounding boxes with an input image. Classification
is performed by a GPU-accelerated
DetectNet
model. The output prediction can be used by perception functions to
understand the presence and spatial location of an object in an image.
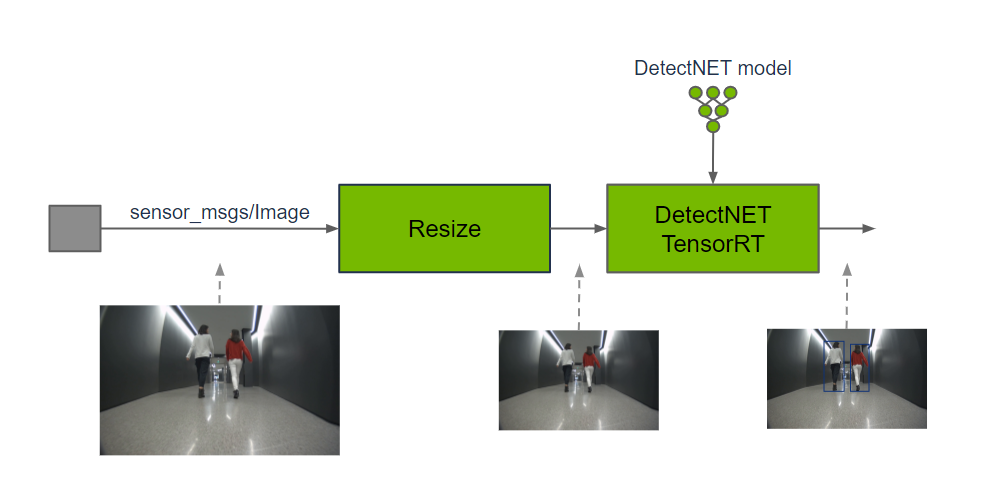
isaac_ros_detectnet is used in a graph of nodes to provide a
bounding box detection array with object classes from an input image. A
DetectNet
model is required to produce the detection array. Input images may need
to be cropped and resized to maintain the aspect ratio and match the
input resolution of DetectNet; image resolution may be reduced to
improve DNN inference performance, which typically scales directly with
the number of pixels in the image. isaac_ros_dnn_image_encoder
provides a DNN encoder to process the input image into Tensors for the
DetectNet model. Prediction results are clustered in the DNN decoder to
group multiple detections on the same object. Output is provided as a
detection array with object classes.
DNNs have a minimum number of pixels that need to be visible on the object to provide a classification prediction. If a person cannot see the object in the image, it’s unlikely the DNN will. Reducing input resolution to reduce compute may reduce what is detected in the image. For example, a 1920x1080 image containing a distant person occupying 1k pixels (64x16) would have 0.25K pixels (32x8) when downscaled by 1/2 in both X and Y. The DNN may detect the person with the original input image, which provides 1K pixels for the person, and fail to detect the same person in the downscaled resolution, which only provides 0.25K pixels for the person.
Note
DetectNet is similar to other popular object detection models such as YOLOV3, FasterRCNN, and SSD, while being efficient at detecting multiple object classes in large images.

Object detection classifies a rectangle of pixels as containing an object, whereas image segmentation provides more information and uses more compute to produce a classification per pixel. Object detection is used to know if, and where in a 2D image, the object exists. If a 3D spacial understanding or size of an object in pixels is required, use image segmentation.
This package is powered by NVIDIA Isaac Transport for ROS (NITROS), which leverages type adaptation and negotiation to optimize message formats and dramatically accelerate communication between participating nodes.
| Sample Graph |
Input Size |
AGX Orin |
Orin NX |
Orin Nano 8GB |
x86_64 w/ RTX 4060 Ti |
|---|---|---|---|---|---|
| DetectNet Object Detection Graph |
544p |
232 fps 11 ms |
105 fps 15 ms |
74.2 fps 22 ms |
644 fps 5.6 ms |
Please visit the Isaac ROS Documentation to learn how to use this repository.
Update 2023-10-18: Adding NITROS YOLOv8 decoder.