Different weather and lighting conditions affect the performance of Image Processing tasks in Roadside Images. It is crucial to enhance these images in tasks like:
- Vehicle Detection
- Traffic Sign Detection
- Autonomous Driving etc.
Our goal is to remove different inclement weather conditions affecting road-side images for example -
- Rain
- Snow
- Haze
CURE-TSD (Challenging Unreal and Real Environment for Traffic Sign Detection)

The dataset contains video from 49 different sequences under different challenging condition. For example -
- Decolorization
- Lens Blur
- Codec Error
- Darkening
- Dirty Lens
- Exposure
- Gaussian Blur
- Noise
- Rain
- Shadow
- Haze etc.
The main dataset contains over a thousand video sequences under different challenge levels and conditions. Subsets of original dataset were used to train the enhancement networks. Substes of data selected from the original dataset is as follows:
- Derain Network: Real Data, Challenge Type - Rain, Challenge Level - 1
- De-Snow Network: Real Data, Challenge Type - Snow, Challenge Level - 2
- Dehaze Network: Real Data, Challenge Type - Haze, Challenge Level - 3
The following parts were considered for the preprocessing step:
- Frame Extraction
- Cropping of Patches
- Dataset Creation
- Each video sequence:
- Resolution: 1628 x 1236
- Sequence Length: 30 seconds
- Frame rate: 10 fps
- Each video sequence generated 300 frames
- Total no. of frames generated per challenge:
- 300*49 = 14,700

- Instead of enhancing the whole image at once, we aim at cropping random patches from the image and separately enhance them.
- The patch is 128 x 128
- 8 random patches are taken from each extracted video frame.
- 8 Random patches are taken from each frame extracted from video sequences
- 49 Video sequences with 400 frames each
- Total number of random patches for training: 498300 = 1,176,000
- The patches are stored in hdf5 data files for faster training
- Each data file is around 6GB.
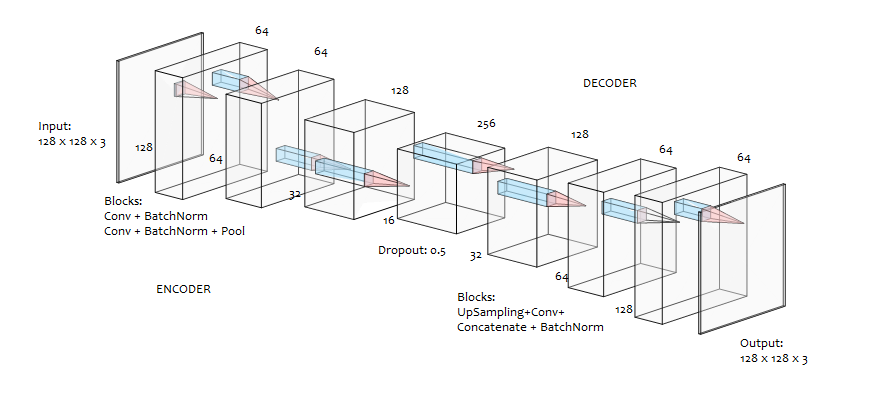
- Framework: Tensoflow/Keras
- Loss: L1 Loss (Mean Absolute Error)
- Metrics: SSIM(Structural Similarity), PSNR (Peak Signal-to-Noise Ratio)
- Optimizer: Adam
- Epochs = 10

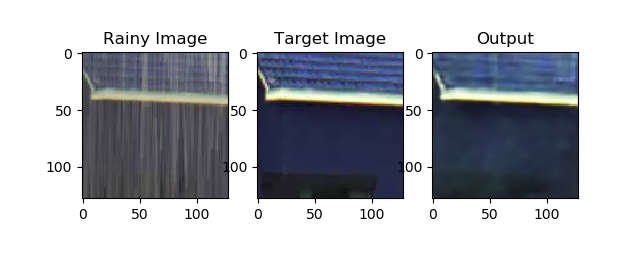


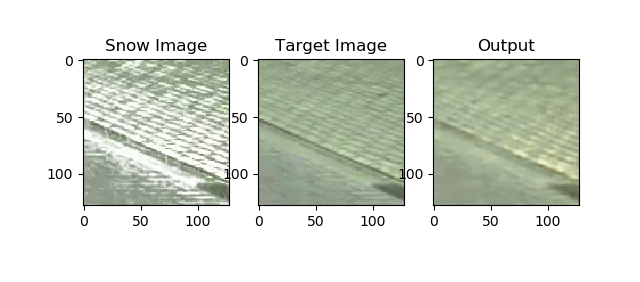




- Full size frames have a resolution of 1628 x 1236 pixels
- The full frame is split into multiple patches of 128 x 128 pixels
- The patches are passed through the network to enhance the image
- Enhanced patches are stitched together to produce final image
- Drawback: Checkerboard pattern at output, can be postprocessed and removed using filters.


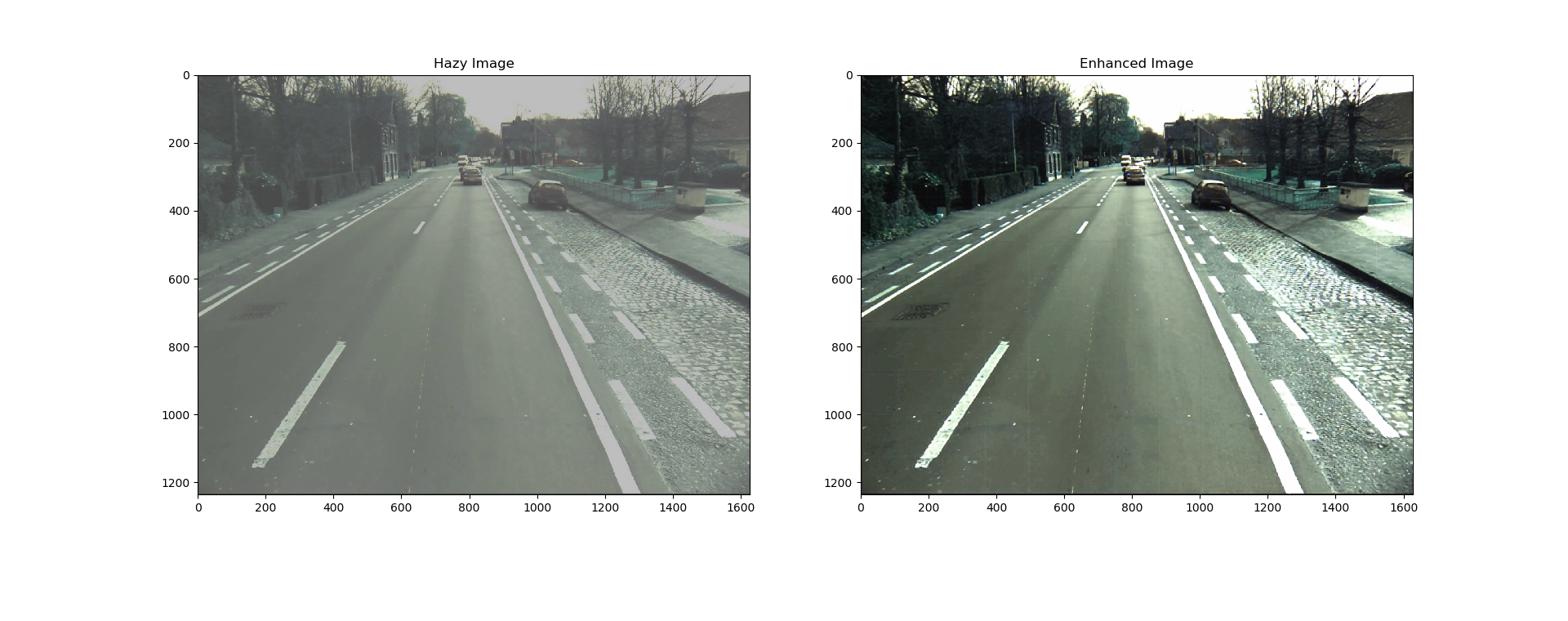
- The simple model already performs convincingly to remove Rain, Snow & Haze
- This might have real world applications to improve the performance of computer vision techniques with vehicles
- The model might perform well on other artifacts as well such as dirty lens, exposure correction, noise, codec error etc.
- The effect of adding skip connections, recurrent blocks and/or residual blocks to the architecture might be studied.
- Incorporating time-domain information might greatly improve performance (i.e. we can take more than 1 frame for prediction)