This is an implementation of ViT - Vision Transformer by Google Research Team through the paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale"
Please install PyTorch with CUDA support following this link
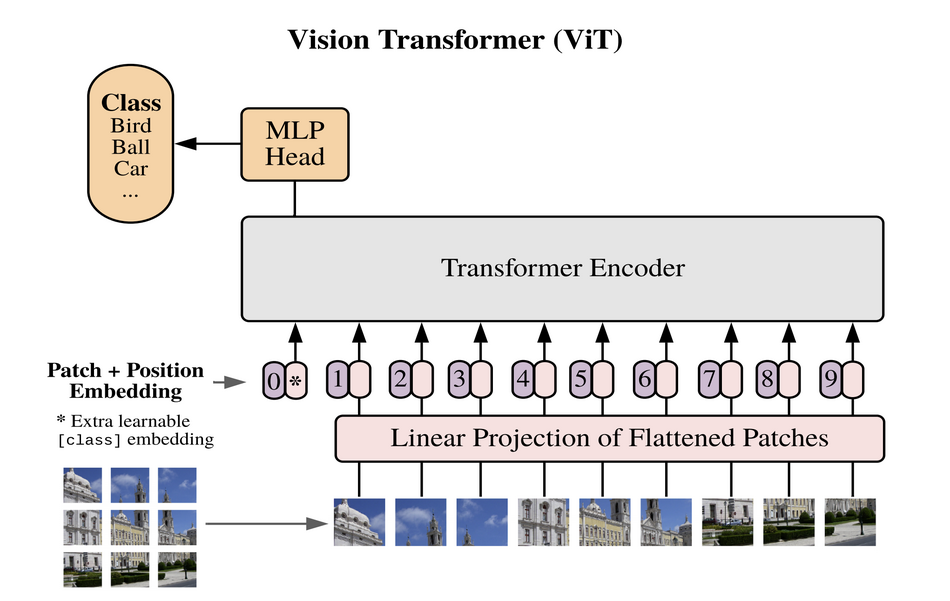
You can config the network by yourself through the config.txt file
128 #batch_size
500 #epoch
0.001 #learning_rate
0.0001 #gamma
224 #img_size
16 #patch_size
100 #num_class
768 #d_model
12 #n_head
12 #n_layers
3072 #d_mlp
3 #channels
0. #dropout
cls #pool
Currently, you can only train this model on CIFAR-100 with the following commands:
> git clone https://github.com/quanmario0311/ViT_PyTorch.git
> cd ViT_PyTorch
> pip3 install -r requirements.txt
> python3 train.py
Suppport for other dataset and custom datasets will be updated later