-
Notifications
You must be signed in to change notification settings - Fork 39
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #405 from afuetterer/python-311
chore: drop support for python < 3.11
- Loading branch information
Showing
5 changed files
with
75 additions
and
25 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,5 +1,5 @@ | ||
| # syntax=docker/dockerfile:1.5 | ||
| FROM python:3.8-slim | ||
| FROM python:3.11-slim | ||
|
|
||
| WORKDIR /usr/src/app | ||
|
|
||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -8,8 +8,8 @@ Developers: [Robert Huber](mailto:[email protected]), [Anusuriya Devaraju](mailto: | |
|
|
||
| ## Overview | ||
|
|
||
| F-UJI is a web service to programatically assess FAIRness of research data objects based on [metrics](https://doi.org/10.5281/zenodo.3775793) developed by the [FAIRsFAIR](https://www.fairsfair.eu/) project. | ||
| The service will be applied to demostrate the evaluation of objects in repositories selected for in-depth collaboration with the project. | ||
| F-UJI is a web service to programatically assess FAIRness of research data objects based on [metrics](https://doi.org/10.5281/zenodo.3775793) developed by the [FAIRsFAIR](https://www.fairsfair.eu/) project. | ||
| The service will be applied to demostrate the evaluation of objects in repositories selected for in-depth collaboration with the project. | ||
|
|
||
| The '__F__' stands for FAIR (of course) and '__UJI__' means 'Test' in Malay. So __F-UJI__ is a FAIR testing tool. | ||
|
|
||
|
|
@@ -26,28 +26,24 @@ An R client package that was generated from the F-UJI OpenAPI definition is avai | |
| An open source web client for F-UJI is available at https://github.com/MaastrichtU-IDS/fairificator. | ||
|
|
||
| ## Assessment Scope, Constraint and Limitation | ||
| The service is **in development** and its assessment depends on several factors. | ||
| - In the FAIR ecosystem, FAIR assessment must go beyond the object itself. FAIR enabling services and repositories are vital to ensure that research data objects remain FAIR over time. Importantly, machine-readable services (e.g., registries) and documents (e.g., policies) are required to enable automated tests. | ||
| - In addition to repository and services requirements, automated testing depends on clear machine assessable criteria. Some aspects (rich, plurality, accurate, relevant) specified in FAIR principles still require human mediation and interpretation. | ||
| The service is **in development** and its assessment depends on several factors. | ||
| - In the FAIR ecosystem, FAIR assessment must go beyond the object itself. FAIR enabling services and repositories are vital to ensure that research data objects remain FAIR over time. Importantly, machine-readable services (e.g., registries) and documents (e.g., policies) are required to enable automated tests. | ||
| - In addition to repository and services requirements, automated testing depends on clear machine assessable criteria. Some aspects (rich, plurality, accurate, relevant) specified in FAIR principles still require human mediation and interpretation. | ||
| - The tests must focus on generally applicable data/metadata characteristics until domain/community-driven criteria have been agreed (e.g., appropriate schemas and required elements for usage/access control, etc.). For example, for some of the metrics (i.e., on I and R principles), the automated tests we proposed only inspect the ‘surface’ of criteria to be evaluated. Therefore, tests are designed in consideration of generic cross-domain metadata standards such as dublin core, dcat, datacite, schema.org, etc. | ||
| - FAIR assessment is performed based on aggregated metadata; this includes metadata embedded in the data (landing) page, metadata retrieved from a PID provider (e.g., Datacite content negotiation) and other services (e.g., re3data). | ||
|
|
||
| 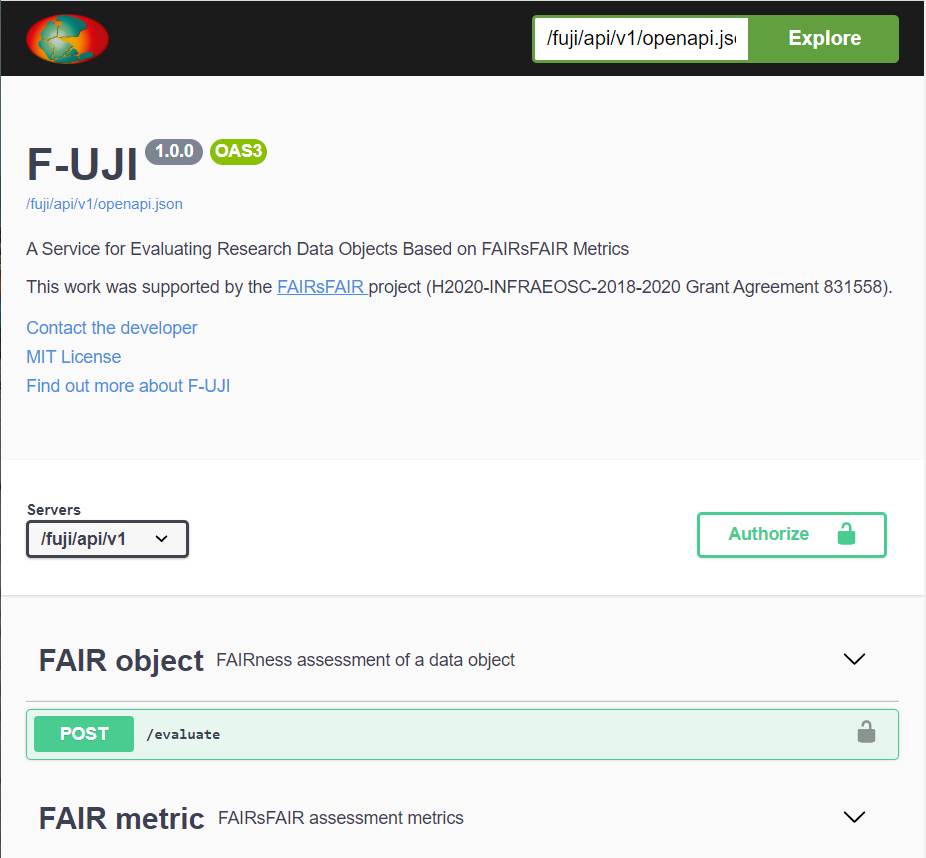 | ||
|
|
||
| ## Requirements | ||
| Python 3.8+ | ||
|
|
||
| ### 308 redirects | ||
| In order to deal with 308 redirects, the following patch has to be applied on urrlib: | ||
| https://github.com/python/cpython/pull/19588/commits | ||
| [Python](https://www.python.org/downloads/) `3.11+` | ||
|
|
||
| ### Google Dataset Search | ||
| * Download the latest Dataset Search corpus file from: https://www.kaggle.com/googleai/dataset-search-metadata-for-datasets | ||
| * Open file fuji_server/helper/create_google_cache_db.py and set variable 'google_file_location' according to the file location of the corpus file | ||
| * Run create_google_cache_db.py which creates a SQLite database in the data directory. From root directory run `python3 -m fuji_server.helper.create_google_cache_db`. | ||
|
|
||
| The service was generated by the [swagger-codegen](https://github.com/swagger-api/swagger-codegen) project. By using the | ||
| [OpenAPI-Spec](https://github.com/swagger-api/swagger-core/wiki) from a remote server, you can easily generate a server stub. | ||
| [OpenAPI-Spec](https://github.com/swagger-api/swagger-core/wiki) from a remote server, you can easily generate a server stub. | ||
| The service uses the [Connexion](https://github.com/spec-first/connexion) library on top of Flask. | ||
|
|
||
| ## Usage | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.