Andreas Finger :: @mediafinger
How a message broker architecture will get you up to speed with (micro) services.
This talk will
- explain what a message broker is
- explain what makes RabbitMQ special
- explain challenges of a service-oriented-architecture (SOA)
- explain how those can be solved with one tool
- and give valuable tips how to configure it

I promised cute bunnies!
Message brokers are central services that route messages between senders (publishers) and receivers (consumers)
- brokers understand multiple protocols and translate between them
- brokers provide security layers
- brokers aggregate messages
- brokers replicate messages
- brokers support different ways of sending messages like pub/sub, queues and mixtures of both
- brokers often support remote procedure calls (RPC) a request-response protocol
The publish / subscribe model decouples publishers and subscribers
- publishers send messages to channels without knowing who will receive those messages
- subscribers listen to channels without knowing who sends messages
- no more polling (and no callbacks or webhooks) needed
- one message can be delivered to multiple subscribers (broadcasting / fan-out)
- this allows for great scalability like RSS and Atom demonstrate
Queues are an asynchronous point-to-point communication system
- queues can be filled by many publishers
- queues have typically only one consumer
- when a message was consumed, it will be deleted
- message queues can ensure each message is processed
- the order of the messages is not guaranteed
- background workers rely on queues, they are a subset of messaging systems
The architecture described here is called event-driven
- when a change happens, an event is fired (a message is send)
- other services can react to this event
- once an event is processed, it will be deleted
- event-sourcing describes similar functionality, but stores all events
Event-driven contrasts with synchronous, blocking requests

RabbitMQ is a high performance message broker based on AMQP.
Using the broker architecture it can be scaled independently.
Applications interact with RabbitMQ over lightweight client libraries.
AMQP was defined and implemented for the first time over ten years ago. Since then it expanded beyond the finance and banking sector it originated in, into many different industries.
RabbitMQ features a full implementation of AMQP 0.9.1 as well as several custom additions over it.
While this how-to focuses on RabbitMQ's AMQP implementation only, RabbitMQ also features implementations of a few other messaging protocols that can be used for special use cases.
- MQTT a lightweight protocol often used to implement pub-sub patterns with high latency mobile devices
- STOMP a text-based protocol creates compatibility with ApacheMQ
- statelessd / Hare for high velocity fire and forget messaging
- general purpose message broker
- open source, maintained by Pivotal Software Inc
- written in Erlang
- lightweight, but powerful
- layers of security
- clients libraries for most modern languages exist
- very flexible in controlling trade-offs between reliable message throughput and performance
- plugins to extend core-functionality
- it is fast: 20k+/sec messages can be handled on a single queue
- clustering for redundancy is simple to setup
- Kafka is a different tool
- specialized on event-sourcing (storing all events)
- less flexible
- very high throughput (100k/sec)
When you need event sourcing and replayability, use Kafka.
For most other message broker use cases RabbitMQ might be the better choice.

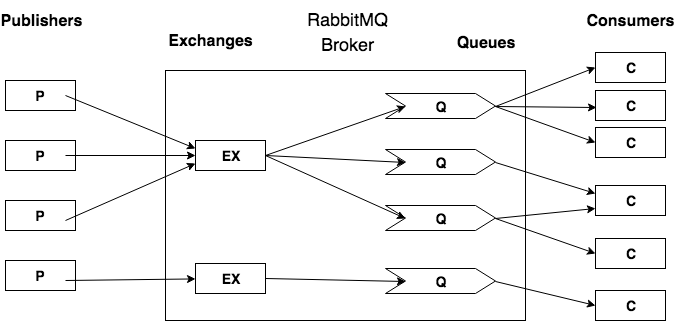
- messages are published to exchanges and include a routing_key
- the broker routes the messages from an exchange to the queues
- one message can be routed to multiple queues
- the broker pushes message from queues to consumers
- a queue can have multiple consumers to improve performance
- load balancing is done via round robbin without overloading consumers
- consuming multiple queues can be done to aggregate data
- every publisher can also be a consumer

When you extract services from a monolith
or start with a microservice setup
you have to solve some new challenges. These are intensified by the use of VMs and containers.
- Service Discovery / Service Registry
- Communication between services
- Load Balancing
- Resilient services
Typical solution: Consul from HashiCorp or Zookeeper from Apache
With RabbitMQ:
- services register with the broker
- other services don't need to know of each other
- services publish to exchanges of the broker
- services consume from queues of the broker
Typical solution: synchronous REST API
With RabbitMQ:
- services publish and consume messages
- it's asynchronous!
- removing and adding services becomes simpler through decoupling
Typical solution: configure a software or hardware load-balancer. (Spoiler: it's tricky!)
With RabbitMQ:
- asynchronous handling to soften spikes: messages can stay in queue till consumed
- each queue can be consumed by multiple consumers: just add another machine for a special task
Typical solution: a few retries and then error logging. When thousands of calls fail, your system might lose important data. Hard to recover / rerun later.
With RabbitMQ:
- pub / sub decouples the services
- Message brokers use queues where timeouts are less of an issue
- retry logic can be individualized for every queue or even for every message type
- when the other failing service is available again, messages in queues can be delivered as if nothing happened
- Service Discovery / Service Registry
- services register with the broker
- Communication between services
- decoupled over asynchronous queues
- Load Balancing
- multiple consumers
- Resilient services
- decoupling, re-queue messages, deliver later

Typical solution: in not-so-concurrent languages you will use extra services to handle jobs asynchronously in the background. In the Ruby world the combination of Resque and Redis is often used and SideKiq is popular as well.
With RabbitMQ:
- as background workers are a subset of messaging systems, they come included in RabbitMQ
- no need to setup, configure and learn to use an additional system
- Decoupling services
- Scale and extend systems
- Handling high volumes of messages
- Broadcasting and replicating messages
In many service oriented architecture, the system triggering an event (or receiving it from an external service), might manage large parts of the logic needed to react to this event. It could make calls to different services and endpoints to create or update records.
Doing this in a resilient way, involves usually background workers in each application that handles asynchronous processing and retries.
Using a message broker architecture means to inform other systems about events and those implement the logic if and how to react.
Decoupling services by introducing an asynchronous messaging system between them, allows to change and scale systems independently.
Adding additional consumers in peak times is as simple as spinning up a new instance.
Extending the system by adding new services can be done independently.
The message broker distributes messages and can in this process throttle the load towards the message receiving systems.
This can reduce failure rate in peak times and at the same time speed up the systems sending messages, as they are no longer blocked by waiting for an answer of a potentially slow system.
This can go as far as decoupling your database writes.
The message broker can inform multiple systems about changes and events. This allows to add new functionality seamlessly.
It can replicate data and events to data centers in other regions to achieve high availability.
This raises the guarantees of message delivery and better performing front end apps for customers around the globe.
Using RabbitMQ as the central broker between your services
- simplifies architecture, only your services and a message broker
- simplifies setup - don't need to maintain many different tools
Starting fast with a service based architecture, while avoiding:
- complexity
- multitude of tools
- tight coupling
- domino effects
- high latency
- pain in general

-
single point of failure
I bet most SOA have multiple points of failures
ヽ༼ ಠ益ಠ ༽ノ

Detailed information which configuration options for publishing, routing and consuming messages with RabbitMQ exist and which tradeoffs between speed and guarantees can be made.
When publishing messages, RabbitMQ offers multiple methods to pick from. Each choice is a trade-off between speed and security that messages have really been delivered. All options can be combined to find the sweet spot for the type of messages being send on a specific queue.
This list skips the Transaction pattern RabbitMQ implements (AMQP TX), as the alternatives offer more lightweight and less complex methods to achieve the same goals.
- fire and forget, messages might get lost, without informing the publisher about it
- set
mandatory=trueto get messages returned when they are not routable, returned messages have to be handled - set
immediate=trueto get messages returned when no queue is ready to consume them, returned messages have to be handled
- lightweight and quick way to ensure a message can be routed and the broker has processed it
- an unroutable mandatory or an undeliverable immediate message is confirmed right after the
basic.return - a transient message is confirmed the moment it is enqueued
- a persistent message is confirmed when it is persisted to disk
- confirmation is send asynchronously
- the publisher should make no assumptions about the exact time a message is confirmed
- if the broker runs into issues, it will
basic.nackmessages
- a cluster is mandatory to use HA queues
- messages will be handled on all nodes of the cluster that handle the HA queue
- if a node goes down, the message does still exist on the other nodes
- this can replace slow persistence to disk in many cases
- once a message is consumed from any node in the cluster, all copies will be removed
- clusters can be connected in different ways, this is a topic of its own
- set
delivery-mode=2to persist every message before queueing it - messages will survive restarts of the whole system
- define the queues and the exchanges as
durable - when the system goes down, messages that have not been persisted yet, might still get lost
- I/O performance of the system must be high, to not slow message handling down
- use lazy queues when you expect extremely long queues, or suffer from unpredictable performance
- _lazy queues_® are slower, as they remove the messages from RAM
When consuming messages, RabbitMQ offers multiple methods to pick from. Each choice is a trade-off between speed and security that messages have really been consumed.
This list skips the Transaction pattern RabbitMQ implements (AMQP TX), as the alternatives offer more lightweight and less complex methods to achieve the same goals.
It also skips the get pattern, as the performance is worse compared to consuming messages. At the same time it does not offer benefits over the available alternatives.
- messages are consumed, but
no_ackis sent - no guarantee if a message was delivered or successfully processed
- the consumer might be overloaded and crash with an unknown number of buffered messages
- set a QoS level, to determine how many messages to prefetch, before sending an
ack - consumer counts the number of messages before sending an
ackwhen theprefetch_countwas reached - when connection dies, all messages of the current batch are re-queued
- reject a batch of
multiplemessages by sending abasic.nack®, they will be re-queued - this can result in messages being send multiple times
- lightweight system that allows for high throughput rates
- needs benchmarking to find the perfect prefect_count per queue
- the default setting is to send an automatic
ackafter a message was sent - change it to
manual_ack=trueto send theackafter processing the message - send a
basic.nackorbasic.rejectto reject and delete a message - reject a message with
requeue=trueto redeliver it
Real world use cases and some thoughts about which publishing and which consumption methods to chose.
Typical fire and forget use case. Losing some of the many millions of messages won't affect the system, but slow message handling would. Choose the fastest publishing and consumption methods without guarantees.
Publishing confirmation can be set to ensure the message has been routed. In case you are sending many notifications per client per day, this might be the only guarantee you opt in to. You expect the delivery to succeed in almost all cases. And you are aware that there will never be a guarantee that a recipient will really receive an email is his inbox or a text message on this phone.
If you need the guarantee that your SMS or email system is processing the messages, setting a QoS level and receiving an ack after multiple messages have been processed is a reasonable choice.
If it's not about pure notifications, but information that has to reach the customer, dead-letter queues should be used to handle failures.
A customer changes his personal data on one system and it has to inform other application about it. In this case the choice of methods depends heavily on how important it is for the other applications to have the latest data.
An invoicing tool that sends out emails, might be ok with eventual consistency of the real world address of the customer.
The service informing about the data change could send messages with publishing confirmation and no further guarantees.
However you will need a strategy to create consistency eventually. Maybe a job that sends messages every night for each customer whose data changed in the last 24h. As you might have less system load at night, using a QoS level might give you the guarantees you need.
Nevertheless the same tool might expect to always be immediately informed about changes in the payment data or email address. In this case you would need to pick more secure messaging strategies like a HA queue and manual ack after message delivery.
When a redundant cluster is available, using HA queues with delivery confirmation and dead-letter exchanges is a secure choice.
As money transfers need all possible guarantees, you will want to add persistence of messages to disk into the mix. This ensures all messages can be recovered even in the case of catastrophic failure.
- to connect publishers and consumers at least one exchange has to be declared
- exchange names consist of letters, digits, hyphen, underscore, period, or colon
[A-Za-z0-9-_.:] - a default direct exchange with the name
''(empty string) exists - RabbitMQ allows to bind exchanges to exchanges for extra flexibility, which comes with extra complexity and overhead, you most probably won't need this feature
- after declaring an exchange,
bindat least one queue to it - queue names consist of letters, digits, hyphen, underscore, period, or colon
[A-Za-z0-9-_.:] - the empty string
''is a valid queue name - has the queue name been omitted on declaration, a new queue with a generated unique name will be created
- queues can be declared to be
exclusiveand will be deleted when the connection closes - to enhance performance, multiple consumers can subscribe to a queue, messages are then distributed in a round robin way, so that each consumer will process a part of all messages, which helps to keep queues short
- match the
routing_keyof messages to the binding key of queues - the string is matched for equality, no pattern matching
[A-Za-z0-9-_.:]are the only valid characters forrouting_keys(TODO: validate this!)- multiple queues can be bound to the same
routing_key - a queue can be bound to multiple
routing_keys - every queue will receive all messages matching the binding key
- direct exchanges are a good choice for routing reply messages
- all messages published are delivered to all queues bound to the exchange
- no routing keys are necessary
- faster routing, as not matching has to be performed
- all applications consuming from a fanout exchange need to handle all kinds of messages delivered through it
routing.keysare dot separated, queues define a binding key- pattern matching is used to route messages to queues
- an asterisk
*matches any characters up to the next dot. - the pound
#matches any characters including dots. [A-Za-z0-9]are the only valid characters besides the dot.- emulate direct exchange queues by binding to the exact
routing.key - emulate fanout exchange queues by binding to any routing.key through
# - topic exchanges are very flexible and a good future-proof choice
- inspects the
headershash of the messagepropertiesto route the message - no routing keys are necessary
bindaccepts an array ofkey-valuepairs as parameter- the
x-matchargument determines ifanykey-value pair has to be included in the properties headers, or ifallhave to match - additional key-value pairs included in the headers property do not influence the routing
RabbitMQ provides other types of exchanges through plugins to enable special use cases. For example the _consistent-hashing_® exchange to load-balance the number of messages sent to queues in a cluster.
- retries and final failure
- dead-letter boxes and poisonous messages https://derickbailey.com/2016/03/28/dealing-with-dead-letters-and-poison-messages-in-rabbitmq/
When a published message can not be routed by the broker.
- define an
alternate-exchangeto route the message to, when the actual is unable to route it - a
mandatory=truemessage would be re-routed instead of being returned - publishers won't have to handle returned messages
- declare an exchange and
bindat least one queue to it - messages stay in the
alternate-exchangequeue(s) for inspection, unless a consumer is defined
When a queued message expires or is rejected by the consumer.
- define an
x-dead-letter-exchangewhen declaring the queue - messages stay in the dead-letter queue for inspection, unless it they expire or handled by a consumer
- handling processing failure with dead-letter queues is simpler and safer than burdening the consumer client with it
- having only messages of one type in the queue makes error handling easier
- the message headers will be changed
- could be combined with a delayed retry strategy: https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
In a fanout exchange all queues will receive all messages. This burdens the consumers of this queues with handling differnt kind of messages.
In a direct exchange every queue bound to an exact routing_key of a message, will receive this message. When multiple queues are bound to the same routing_key the message will be routed to all of these queues. A message will only be removed from the system, when it was delivered in all bound queues.
A headers exchange allows for very flexible routing. It matches key-value pairs of the headers property of messages.
Very flexible routing can be implemented through the topic exchange. Pattern matching allows queues to handle all, some or only very specific messages. This way it is capable to emulate the direct and the fanout exchange.
The parts of routing keys are separated by dots .
The binding keys implement pattern matching by including asterisk * or pound # characters.
Let's assume we have a service that connects tech communities all over the world. Our routing keys have usually three parts:
a city, a topic and a category:
| City | Topic | Category |
|---|---|---|
| barcelona | android | event |
| berlin | elixir | job |
| london | ruby | news |
| madrid | testing | question |
| vancouver | wwcode | tutorial |
The above list would allow for routing.keys like the following:
barcelona.ruby.eventbarcelona.ruby.jobbarcelona.testing.jobberlin.testing.jobvancouver.wwcode.event
Queues are bound to the exchange by a binding key which is a pattern or the exact string.
Messages can be delivered to multiple queues that can have one or more consumers each.
| Binding key | Explanation |
|---|---|
barcelona.# |
every message for Barcelona |
barcelona.*.event |
matches all events in Barcelona |
barcelona.ruby.* |
matches everything about Ruby in Barcelona |
barcelona.ruby.event |
matches the exact routing.key |
*.ruby.* |
matches everything about Ruby everywhere |
#.job |
matches all messages about Jobs |
# |
all messages |
When discussing publishing, routing and consumption of messages, parameters like the routing key have been mentioned. The routing information and arguments, are part of the method frame. The content header frame contains the size and the properties of a message. The payload is contained in the body frame.
Together the three frames represent a full AMQP message.
| Property | Type | Used by | Use case |
|---|---|---|---|
app_id |
String | Application | use it to describe the publisher |
content-encoding |
String | Application | in case compression is used gzip, zlib or encoded content Base64 |
content-type |
String | Application | mime-type of the message body application/json |
message_id |
String | Application | typically a UUID |
timestamp |
timestamp | Application | Unix epoch timestamp in seconds, use Time.now.utc.to_i |
type |
String | Application | use it to describe message or payload |
| Property | Type | Used by | Use case |
|---|---|---|---|
correlation_id |
String | Application | typically used to reference a request or message when sending a response |
delivery-mode |
1 or 2 | RabbitMQ | 1 = keep message in memory, 2 = persist to disk |
expiration |
String | RabbitMQ | one way to set an expiration date, a timestamp in seconds but as String |
headers |
Hash | Rabbit & App | key-value table to store any additional metadata, can be used for routing |
reply_to |
String | RabbitMQ | commonly used to name a callback queue |
| Property | Type | Used by | Use case |
|---|---|---|---|
priority |
0..9 | RabbitMQ | 0 has highest priority, usage is a bit tricky |
user_id |
String | RabbitMQ | identify message was sent by logged-in user, don't manipulate it |
They payload is contained in the body frame. When the size of the payload exceeds the maximum size of a message frame, it will be split over multiple body frames. The form of the payload is described by the content-type and content-encoding header properties.
Consumers clients should decode and deserialize the message body, to make it easier for the application to handle messages.
To try those examples you'll need a running RabbitMQ broker. The examples are written in Ruby and require "bunny". You can always use RabbitMQ's management UI to check the status of your broker and queues:
http://localhost:15672/ (user: guest, password: guest)
Instead of using bunny directly, I would recommend to use a framework like:
This repo includes a demo app (in Ruby) with detailed setup instructions:
https://github.com/mediafinger/rabbitmq_presentation/tree/master/demo_app_with_hutch
The following code snippets will:
- open a connection and create a channel for the publisher
- declare a topic exchange and a queue
- bind the queue to the topic exchange
- publish messages to the topic exchange
- open a connection and create a channel for the consumer
- create a consumer for the queue
- bind the consumer to the queue
url = "amqp://guest:guest@localhost:5672/%2F"
connection = Bunny.new(url)
connection.start
channel = connection.create_channelexchange = Bunny::Exchange.new(
channel,
:topic,
"first_topic_exchange"
)
queue = channel.queue(
"handle_it",
auto_delete: false,
durable: true
)
queue.bind(exchange, "example.routing.key")12.times do |i|
exchange.publish(
"hello-#{i}",
routing_key: "example.routing.key",
message_id: "m-#{i}",
timestamp: Time.now.utc.to_i
)
endurl = "amqp://guest:guest@localhost:5672/%2F"
connection = Bunny.new(url)
connection.start
channel = connection.create_channelqueue = channel.queue("handle_it")
queue.bind(channel.exchange("first_topic_exchange", type: :topic), routing_key: "example.*.key")
consumer = Bunny::Consumer.new(
channel,
queue,
channel.generate_consumer_tag,
false, # no_ack == no automatic ack == manual ack
false, # exclusive
{} # arguments
)consumer.on_delivery do |delivery_info, properties, payload|
puts properties.timestamp
puts properties.message_id
puts delivery_info.routing_key
puts delivery_info.exchange
puts payload
end
queue.subscribe_with(consumer)channel.basic_cancel(consumer_tag)
queue.subscribe_with(consumer)
channel.basic_cancel(consumer_tag)
channel.close- Publishing messages with different guarantees (TODO)
- Consuming messages with different guarantees (TODO)
- Handling errors (TODO)
- publisher confirmation
- persistence
- ack
- prefetch_count
- delivery failure
- processing failure
- retries
- final failure
- Monitoring and Alerting (TODO)
- Cluster setup (TODO)
- Best Practices (TODO)
rabbitmqctl list_queuesalert on queue length threshold- use API to compare current queue setup with expected configuration
- multiple nodes with low-maintenance / automatic synchronous replication
- high availability (HA) queues
- federated exchanges
- benefits
- drawbacks
- configuration options
- load JSON config file over API
- use one connection per process
- use one channel for each thread
- use separate connections for publish and consume
- reuse connections, keep connection:channel count low
- keep queues short, if not possible use lazy queues

It's a kangaroo!
To comfortably use AMQP with the RabbitMQ extensions, there are clients for basically all modern languages.
A list of the most popular clients for a few popular languages:
The bunny gem
Instead of using bunny directly, you could implement a framework like:
Example code: https://github.com/mediafinger/rabbitmq_presentation/tree/master/demo_app_with_hutch
The Net::AMQP::RabbitMQ module
Interact with RabbitMQ over AMQP using librabbitmq
The amqp hex package
The amqp library
https://github.com/streadway/amqp
The JMS client
https://github.com/rabbitmq/rabbitmq-jms-client
The amqp.node library
https://github.com/squaremo/amqp.node
The rust-amqp library
https://github.com/Antti/rust-amqp
-
AMQP 0-9-1 reference: https://www.rabbitmq.com/amqp-0-9-1-reference.html (keep in mind that RabbitMQ implements more features on top of the official AMQP standard)
-
RabbitMQ download https://www.rabbitmq.com/download.html
-
Managed hosting https://www.cloudamqp.com/ (available in many different clouds and regions)
-
RabbitMQ in Depth by Gavin M. Roy: https://www.manning.com/books/rabbitmq-in-depth (this book inspired me to summarize the information above - it's a great read, buy it yourself!)

I've gotta go
Created by Andreas Finger 2018 & 2019 in Barcelona
This presentation and code examples: https://github.com/mediafinger/rabbitmq_presentation