Adding Delta Table Format to OpenHouse, a proof-of-concept #40
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
8 tasks
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Summary
Delta is an open-source table format that brings enterprise-grade capabilities to data lakes. It manages large datasets in data lakes efficiently and ensures data integrity through ACID transactions and enables historical data exploration with time travel features.
In this PR we replace OH's current Iceberg Table Format with Delta Format.
Guiding principles for coding this PR:
Details
Overall architecture is the same as before for Iceberg, except for three crucial pieces:
OH Client will use LogStore Plug for commits: Delta protocol doesn't provide doRefresh(), doCommit() plugs like Iceberg. This is because of fundamental difference in Delta vs Iceberg. Instead the client will use LogStore plug for any kind of writes.
OH Server will use FileSystem as source of truth (not HTS): Again, because of protocol difference in Delta vs Iceberg. Now, the OH server commits using
DeltaLog.forTable(/tablePath).getTransaction().commit()and keeps a record in HTS just for record keeping.Directory layout is bit different than Iceberg: But protecting namespace should still be supported.
New Features
Testing
Easy way: Just run the unit test
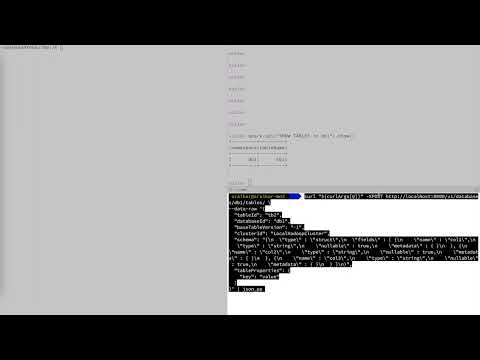
./gradlew buildopen > ROOT/build.gradle:spark-delta-clientcom.linkedin.openhouse.delta.tests.SimpleTest#basicSQLCatalog()This will run the E2E flow in form of unit test, place debugger anywhere and have a fun time!
Production way: Run the docker setup
./gradlew buildcd /infra/recipe/docker-compose/oh-hadoop-sparkdocker compose up -ddocker exec -it local.spark-master /bin/bash6:
7:
8:
See following demo for in-depth production test