{kind=link}
{kind=link}
{kind=link}
{kind=link}
- What is Apache Spark
- Use Cases
- Batch and Streaming API's
- Architecture
- Directed Acyclic Graph (DAG)
- Example With Last.fm Data
- Distributed data processing engine
- Best suited for big data but not limited to it
- Fast and resillient
- Supports both batch and streaming
- Scala, Java, Python, R, SQL
- Machine learning with MLlib
- Process big data that cannot fit into memory
- Extract, transform, load (ETL)
- Dashboards from streaming data (like sales on an ecommerce)
- Basically any use case where you need to process data and do it fast.
- Low level API's like RDD and Dstreams
- High level Structured API's like DataFrame and Dataset
- RDD and Dataset are typesafe.
- DataFrame is not typesafe but has the highest performance.
- Easy to switch between API's.
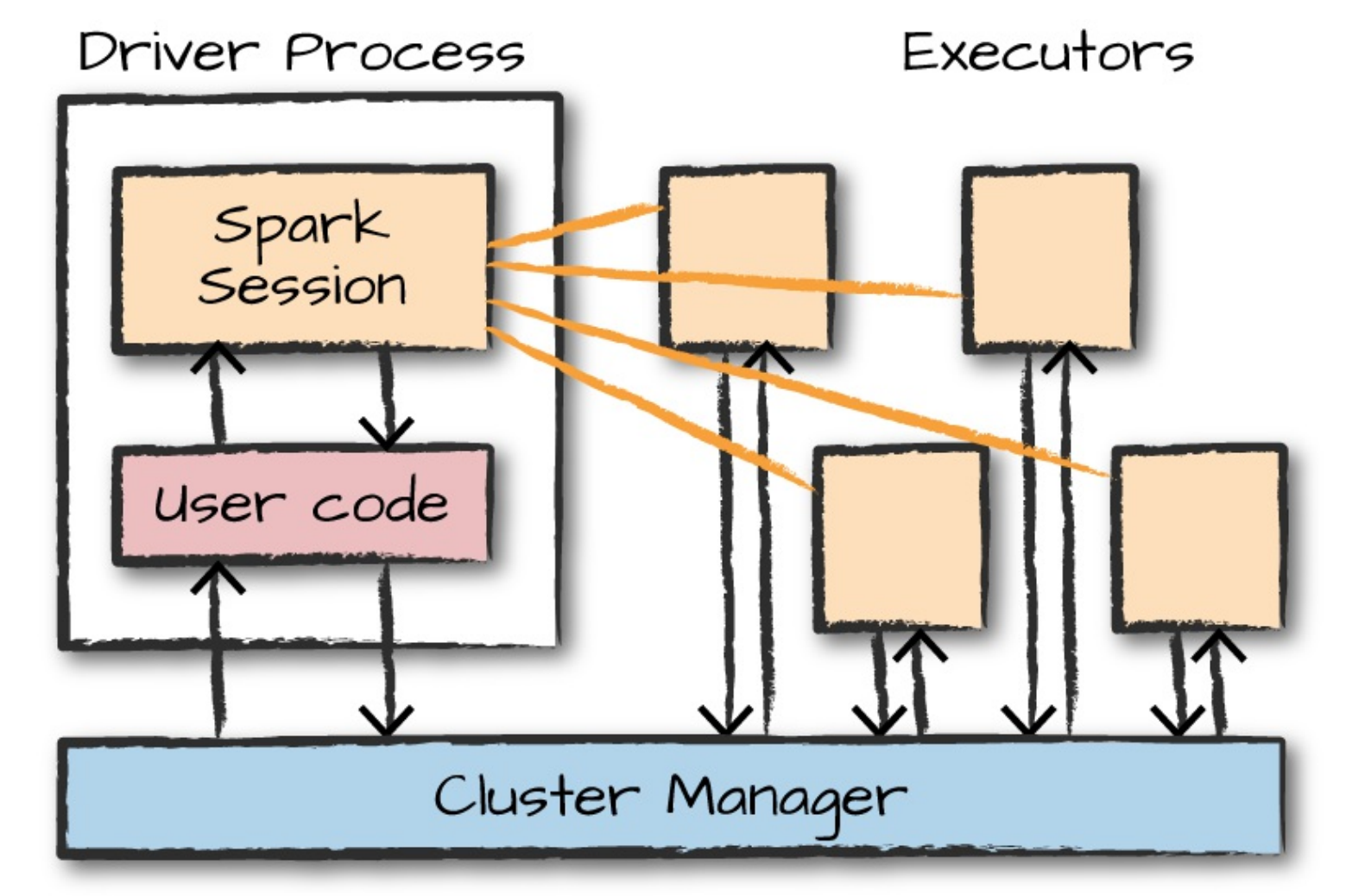
- Spark runs on a distributed cluster
- Driver controls the Spark Job and distributes tasks to executors.
- Cluster manager provides resources to executors and the driver.
- Spark can run on standalone mode, YARN, Mesos.
- Experimental Kubernetes support.
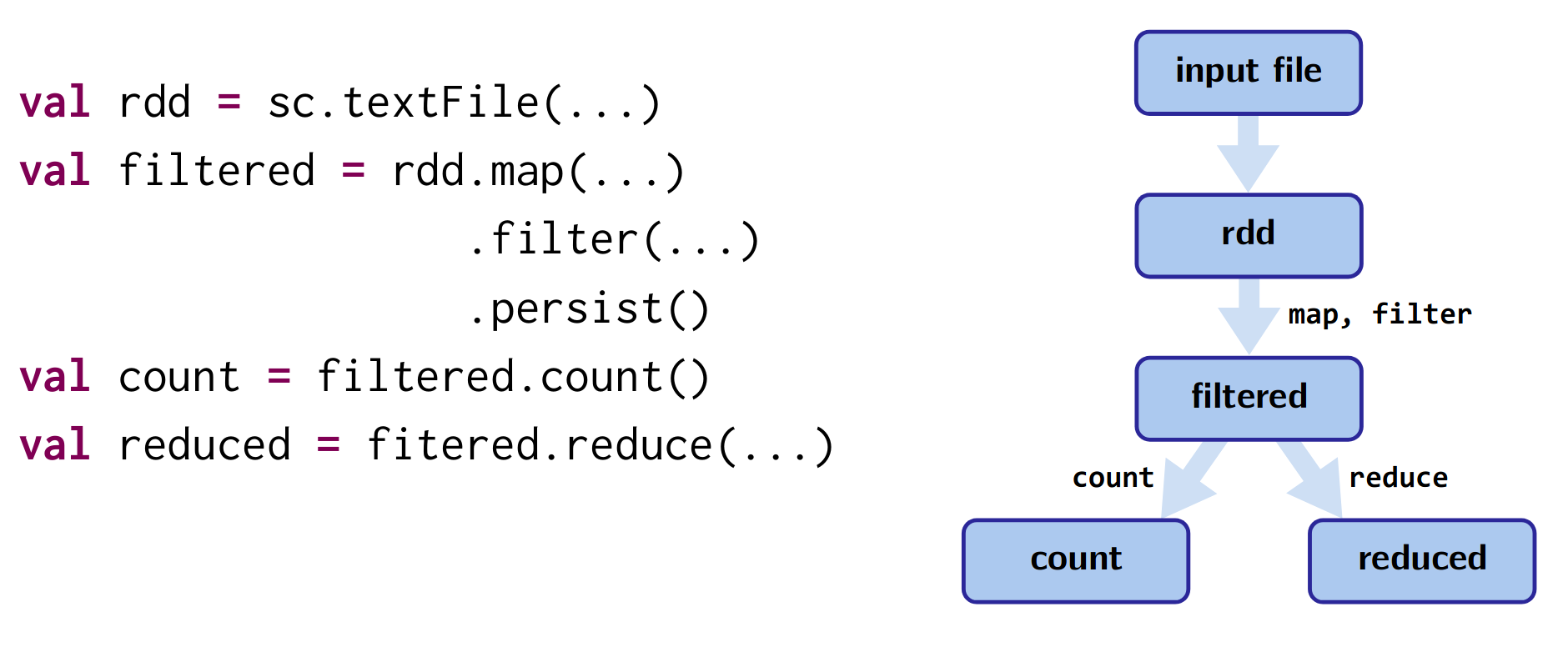
- Spark represents the flow as a Directed Acyclic Graph (DAG)
- When a step fails, Spark re-runs steps before the failed one to regenerate the loss.
- Analyze 2018 data and find top 10 artists
- Get recommendations for each artist using MusicBrainz API