Begynne med å klone imaget til ønsket mappe lokalt:
git clone https://github.com/Kantega/pgexplain.git
Navigere til repoet lokalt, og kjøre kommandoen
docker compose up
Imaget inneholder en database med testdata som vi skal kjøre noen spørringer mot. Her anbefaler jeg at dersom man allerede har en foretrukken databaseklient installert, så bør man bruke den. Under finner man tilkoblingsinformasjonen dersom man ønsker å bruke egen klient
Dersom man ikke har en klient installert, så er den andre delen av imaget en web basert versjon av pgAdmin, som kan brukes for å kjøre spørringer. Dersom man ønsker å bruke pgAdmin klienten er det bare å åpne localhost:7777
Host: localhost
Port: 5544
Username: postgres
Password: postgres
Database name: postgres
Tilgjengelig på localhost:7777 i nettleseren
På venstresiden kan man se tilkoblede databaser
Her kan man ekspandere å finne tabellene som ligger i databasen
For å utføre spørringer mot databasen åpner man 'Query Tool', som kan nås ved å trykke på følgende knapp
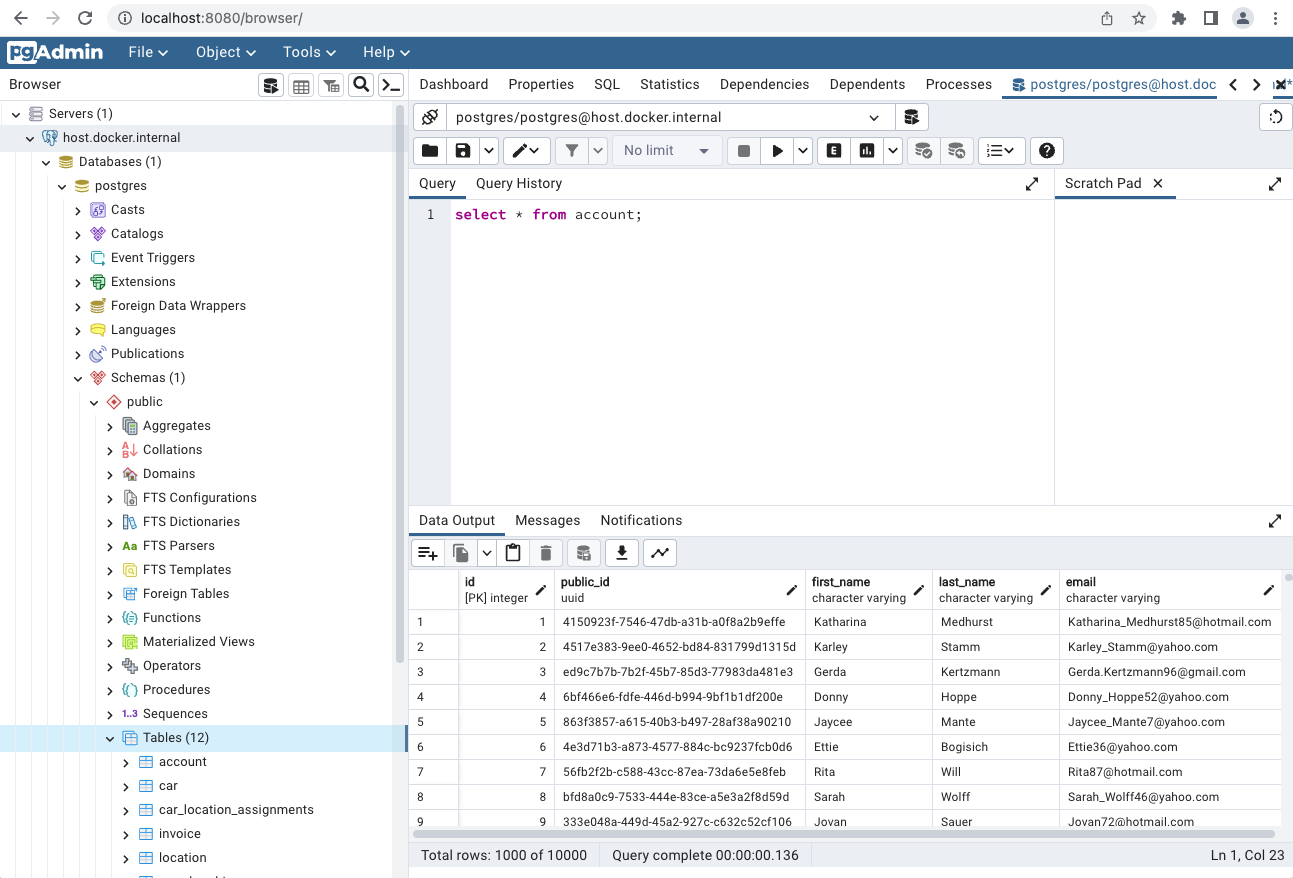
Man kan deretter skrive spørringer, og utføre dem ved å trykke F5. Her er det greit å være klar over at dersom man trykker F5 uten å markere en spørring, vil den kjøre alle spørringene som ligger i vinduet. For å kjøre en individuell spørring bør man derfor markere den før man trykker F5
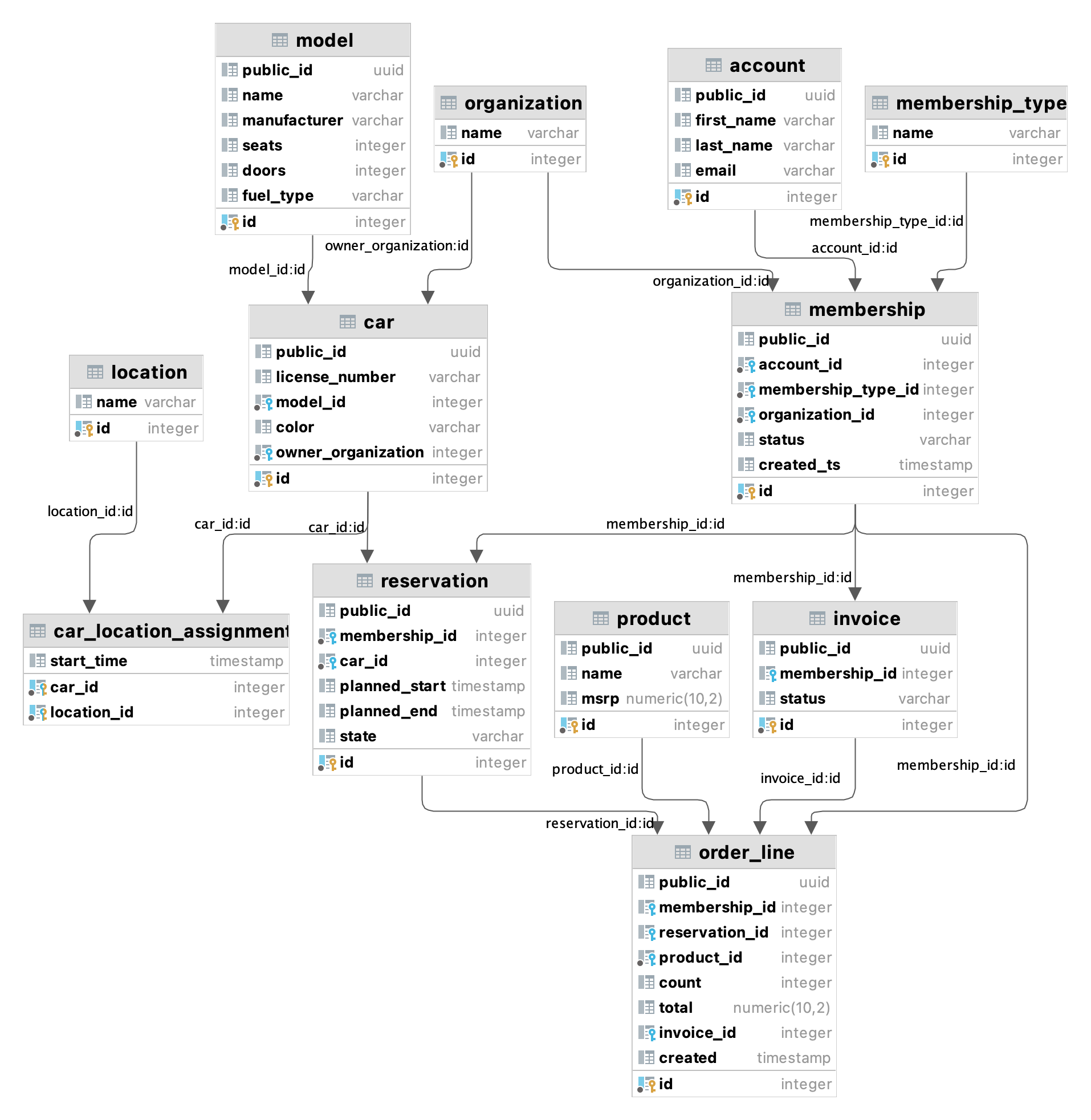
Dataene i databasen er relatert i henhold til dette diagrammet. Det kan være greit å sjekke dette for hjelp i enkelte av oppgavene
La oss foreta en prøvekjøring av EXPLAIN funksjonen. Den kan kjøres ved å legge til explain foran en vanlig SQL spørring.
Kjør følgende eksempel i databaseklienten, og se resultatet
3.1
explain select a.first_name, a.last_name, m.id, m.status from membership m left join account a on a.id = m.account_id
Postgres samler statistikk om alle tabellene i en felles tabell som heter pg_statistic, vi kan se innholdet i denne ved å kjøre
4.1
select * from pg_statistic;
Dessverre er ikke denne tabellen så lett for mennesker å forholde seg til, så derfor eksisterer det også et view som heter pg_stats, hvor dataene er aggregert på en litt enklere måte. Man kan se dette ved å kjøre
4.2
select * from pg_stats;
Man kan også spesifisere tabellnavn (tablename) og kolonnenavn (attname) om ønskelig:
4.3
select * from pg_stats where tablename = 'account' and attname = 'first_name';
For å gå fra esitmerte data til empiriske, så kan vi benytte ANALYZE opsjonen til EXPLAIN, dette gjøres ved å legge den til etter explain kallet, slik som dette
5.1
explain analyze select a.first_name, a.last_name, m.id, m.status from membership m left join account a on a.id = m.account_id;
Sequence scaner den enkleste formen å hente ut data fra databasen. Den går sekvensielt gjennom alle pagene fra databasen og leser radene fra dem Vi kan teste den ved å kjøre
6.1.1
explain analyze select * from account;
Seq scan er en av flere nodetyper som støtter å ha et filter. Dette kan benyttes ved å legge til en where klausul i spørringen vår
6.1.2
explain analyze select * from account where first_name = 'John';
Oppsummering:
- Den enkleste formen å lese data fra tabell
- Leser rad for rad gjennom hele tabellen
- Alltid tilgjengelig
- Ikke alltid den raskeste måten å lese data
- Kan ha et filter
- Dersom en Seq Scan node har et filter og bruker lang tid, vurder indeksering
Index scan benyttes dersom Postgres anser det som raskere å finne radene gjennom en opprettet indekseringsstruktur, enn å lete gjennom alle radene sekvensielt. Den oppstår bare dersom man har et filter på spørringen, men kan da gi en dramatisk forbedring i ytelse.
La oss gjøre et eksperiment. Kjør følgende spørring og noter deg tiden spørringen tok å utføre
6.2.1
explain analyze select * from order_line where product_id = 4;
Lage deretter en index på kolonnen man filtrerer på
6.2.2
-- oppretter index create index idx_order_line_product_id on order_line(product_id); -- kjører spørringen fra 6.2.1 på nytt explain analyze select * from order_line where product_id = 4;
Oppsummering:
- Kan benyttes dersom dataene man leter etter er indekserte
- Kan gi vesentlig raskere datauthenting i forhold til Seq Scan
- Dersom spørringen resulterer i at nesten alle radene fra en tabell returneres, vil Postgres uansett foretrekke å bruke Seq Scan
- Kan også forekomme fremfor en Sort node, dersom dataene man skal sortere på er indeksert
Bitmap Index Scan / Bitmap Heap Scan er en spesiell index scan node som benyttes dersom Postgres anser dataene er for kaotisk plassert på disk til at det er effektivt å bruke Index Scan.
Bitmap Index Scan vil lage et bitmap over hvilke pager den antar inneholder rader som tilfredstiller kriteriene våre. Sorterer disse etter hvor de er i på disk, og returnerer dem til Bitmap Heap Scan, som sekvensielt går gjennom dem og henter data
For å se et eksempel på dette kan vi gjøre følgende
6.3.1
create index idx_order_line_membership_id on order_line(membership_id); explain analyze select * from order_line where membership_id = 273;
Bitmap Index Scan kan kombinere aggregere data fra flere indekser. La os lage en spørring som benytter vår nye indeks, og i tillegg benytter indeksen vi opprettet i 6.2.2
6.3.2
explain analyze select * from order_line where product_id = 4 and membership_id = 273;
Man vil da set hvordan det endelige bitmap'et (samlingen av pages) kan aggregeres i en BitmapAnd før det returneres til Bitmap Heap Scan
Oppsummering:
- En node som gjør indeksoppslag på kaotisk plasserte data
- Man kan finne informasjon om dette som
correlationipg_stats
- Man kan finne informasjon om dette som
- Består av to steg
- Flagge og sortere pages som kan inneholde data
- Sekvensielt gå gjennom disse sidene og hente rader
- Kan aggregere flere indekser gjennom en BitmapAnd node
Sort er et resultat av å gjøre ORDER BY, og vil sortere resultatet fra child noden sin etter sortkriteriet den får oppgitt. Vi kan demonstrere den ved å kjøre
7.1.1
explain analyze select * from membership order by created_ts;
La oss deretter nedjustere work_mem instillingen ved å kjøre
7.1.2
set work_mem = '500kB'; explain analyze select * from membership order by created_ts;
Sett så work_mem tilbake til 4 MB
7.1.3
set work_mem = '4MB';
Oppsummering:
- Resultat av ORDER BY
- Foretrekker å utføre quicksort i minnet
- Påvirket av work_mem
- Dersom det ikke er tilstrekkelig minne, må den bruke disk merge
- Kan påvirke ytelse negativt
- Må motta alle rader fra child node, før den kan begynne å returnere rader til parent
HashAggregate vil blandt annet bli brukt dersom man bruker GROUP BY i spørringer.
Her har vi en spørring som teller hvor mange ganger hvert fornavn blir brukt i account tabellen
7.2.1
explain analyze select first_name, count(*) from account group by first_name;
Den vil også i en del tilfeller bli brukt dersom man ber om unike data. Som for eksempel dersom vi spør om alle distinkte fornavn brukt i account tabellen
7.2.2
explain analyze select distinct first_name from account;
Oppsummering:
- Resultat av bl.a. GROUP BY eller DISTINCT
- Ønsker å utføre hashing i minnet
- Påvirket av work_mem
- Kan ende opp med å måtte benytte disk
- Kan påvirke ytelse negativt
- Batches > 1 dersom man har brukt midlertidig disklagring
Ved å bruke det vi har gått igjennom så langt, se om du kan forså hva som skjer i disse planene.
8.1
HashAggregate (cost=244.08..265.51 rows=2143 width=6) Group Key: first_name -> Seq Scan on account (cost=0.00..236.00 rows=3232 width=6) Filter: ((email)::text ~~ '%gmail.com'::text)
Hint: ((email)::text ~~ '%gmail.com'::text) betyr at email slutter på 'gmail.com'
8.2
Sort (cost=251.54..256.33 rows=1916 width=47) Sort Key: created_ts -> Bitmap Heap Scan on membership (cost=27.13..147.08 rows=1916 width=47) Recheck Cond: ((status)::text = 'CANCELLED'::text) -> Bitmap Index Scan on idx_membership_status (cost=0.00..26.66 rows=1916 width=0) Index Cond: ((status)::text = 'CANCELLED'::text)
De neste nodene vi skal se på har potensiale for å skape langt mer komplekse trestrukturer. Av den grunn kan det være til god hjelp å ha et visualiseringsverktøy for å lettere få overblikk over hva som skjer. Et visualiseringsverktøy vil også gi et raskt overblikk over hvor tiden går i utførelsen.
Her er en liste av mulige visualiseringsverktøy. I denne workshopen kommer vi til å benytte oss av Dalibo visualiseringsverktøyet.
Online:
Intellij:
Her er en plan man kan teste i f.eks. Dalibo, vi vil snart snakke om hva de nye nodene betyr
9.1
Sort (cost=305669.47..308919.47 rows=1300000 width=99) (actual time=919.752..1062.581 rows=1303003 loops=1) Sort Key: r.planned_start Sort Method: external merge Disk: 148464kB -> Hash Right Join (cost=321.00..31462.95 rows=1300000 width=99) (actual time=9.123..318.887 rows=1303003 loops=1) Hash Cond: (r.membership_id = m.id) -> Seq Scan on reservation r (cost=0.00..27728.00 rows=1300000 width=52) (actual time=0.014..63.703 rows=1300000 loops=1) -> Hash (cost=196.00..196.00 rows=10000 width=47) (actual time=9.040..9.041 rows=10000 loops=1) Buckets: 16384 Batches: 1 Memory Usage: 925kB -> Seq Scan on membership m (cost=0.00..196.00 rows=10000 width=47) (actual time=0.022..0.575 rows=10000 loops=1) Planning Time: 0.393 ms JIT: Functions: 10 " Options: Inlining false, Optimization false, Expressions true, Deforming true" " Timing: Generation 2.218 ms, Inlining 0.000 ms, Optimization 0.536 ms, Emission 6.620 ms, Total 9.374 ms" Execution Time: 1122.844 ms
Ta gjerne å teste Dalibo med de kommende planene.
Hash Join og dens varianter er det man vanligvis får når man gjør joins i SQL spørringene. Variantene som kan oppstå er:
10.1.1 Hash Left Join
explain analyze select * from reservation r left join membership m on r.membership_id = m.id;
10.1.2 Hash Right Join
explain analyze select * from organization o left join membership m on o.id = m.organization_id;
10.1.3 Hash Join
explain analyze select * from order_line o inner join membership m on o.membership_id = m.id where m.status = 'CANCELLED';
Faktisk er det unødvendig eksplisitt å spesifisere at man ønsker inner join i 10.3, om du hadde spesifisert left join der, så hadde det fortsatt resultert i en Hash Join
Oppsummert:
- Resultat av joins
- Typen hash join er ikke nødvendigvis 1:1 med hva man spesifiserer i SQL spørringen
- Består av to child noder
- Ett inner table, hvor joinkriteriene hashes (noden i seg selv heter Hash)
- Ett outer table, hvor som man sjekker om hver rad har en match blandt de hashede verdiene fra inner table
- Kan forekomme i flere vaianter, de vanligste er:
- Hash Left Join
- Alle rader fra outer table returneres, joinet sammen med dataene fra inner table dersom det finnes en hash match
- Hash Right Join
- Alle radene fra inner table returneres, joinet sammen med dataene fra outer table dersom det finnes en hash match
- Hash Join
- Rader fra outer table joines med dataene fra inner table og returneres kun dersom det er en hash match
- Hash Left Join
- Ønsker å utføre hashing i minnet
- Påvirket av work_mem
- Kan ende opp med å måtte benytte disk
- Kan påvirke ytelse negativt
- Batches > 1 dersom man har brukt disk
Nested loop er som navnet tilsier, en to nøstede for-løkker, hvor den innerste løkken kjøres i sin helhet for hver rad i den ytterste løkken
Nested Join er ikke like vanlig som Hash Join, men den kan oppstå i noen tilfeller, et av dem er ved å gjøre en cross join. (CROSS JOIN lager et kryssprodukt av de to tabellene man oppgir).
10.2.1
explain analyze select * from organization o cross join account a;
Her vil man også se noden Materialize oppstå. Det vil si at den har lagret resultatet fra child noden sin i minnet, så man ikke trenger å lese alle dataene fra disk ved hver iterasjon av inner løkken.
Oppsummering:
- Består av to nøstede for-løkker
- Medfører en kjøretid på O(M*N)
- Vil prøve å lagre resultatet av inner løkken i minnet for å redusere disk reads
11.1 Undersøk de følgende spørringene med explain analyze og se om du kan resonnere hvor potensielle svakheter eller problemer ligger
I denne spørringen skal vi finne alle ordrelinjer som er på mer enn 20 kr (total i order_line) for avsluttede reservasjoner (state i reservation).
Klarer du å forbedre ytelsen på spørringen?
11.1.1
explain analyze select * from reservation r left join order_line ol on r.id = ol.reservation_id where r.state = 'FINISHED' and ol.total < 20;
La oss si at du skal gjøre et case insensitivt søk på alle ordrelinjer for account med eposten [email protected]. En måte å gjøre dette på er å sørge for at begge verdiene man sammenligner er i lowercase eller uppercase.
Klarer du å se noe snodig ved utføringen av denne spørringen?
11.1.2
create index idx_account_email on account(email); select * from order_line o inner join reservation r on o.reservation_id = r.id inner join membership m on r.membership_id = m.id inner join account a on m.account_id = a.id where lower(a.email) = lower('[email protected]');
NB: public_id representerer et felt man kan dele fritt med frontenden, uten å avsløre noe om intern datalagring.
La oss si at vi har et medlemskap med public_id 4c94e5c8-5820-46cc-be23-eb1e55ad2f01. Dette medlemskapet har gjennomført en reservasjon som har fått public id cd883c8a-3e12-4de7-a6d5-2fb4fcd71d60.
Vi ønsker å liste alle ordrelinjer som går direkte mot medlemskapet (altså er membership_id satt på order_line, men reservation_id er da null). Dette er ordrelinjer som f.eks. 'Medlemskapsavgift'.
I tillegg ønsker vi at dette resultatet skal inneholde ordrelinjer for denne spesifikke reservasjonen (da er både membership_id og reservation_id satt på order_line)
Klarer du å identifisere en svakhet i denne spørringen, og potensielt fikse den?
11.1.3
select * from order_line o left join reservation r on o.reservation_id = r.id left join membership m on o.membership_id = m.id where (r.public_id = 'cd883c8a-3e12-4de7-a6d5-2fb4fcd71d60' or (m.public_id = '4c94e5c8-5820-46cc-be23-eb1e55ad2f01' and o.reservation_id is null));
11.2 Prøv å komme frem til hva den opprinnelige spørringen var for de følgende planene
11.2.1
Sort (cost=209.92..214.92 rows=2000 width=58) Sort Key: cla.start_time -> Hash Right Join (cost=64.00..100.26 rows=2000 width=58) Hash Cond: (cla.car_id = c.id) -> Seq Scan on car_location_assignment cla (cost=0.00..31.00 rows=2000 width=16) -> Hash (cost=39.00..39.00 rows=2000 width=42) -> Seq Scan on car c (cost=0.00..39.00 rows=2000 width=42)
11.2.2
HashAggregate (cost=231588.15..231659.08 rows=7093 width=12) Group Key: o.membership_id -> Hash Join (cost=52155.96..212618.82 rows=3793866 width=4) Hash Cond: (o.reservation_id = r.id) -> Hash Join (cost=322.05..115340.41 rows=3877888 width=8) Hash Cond: (o.membership_id = m.id) -> Seq Scan on order_line o (cost=0.00..102420.92 rows=4796992 width=8) -> Hash (cost=221.00..221.00 rows=8084 width=4) -> Seq Scan on membership m (cost=0.00..221.00 rows=8084 width=4) Filter: ((status)::text = 'ACTIVE'::text) -> Hash (cost=30967.00..30967.00 rows=1271833 width=4) -> Seq Scan on reservation r (cost=0.00..30967.00 rows=1271833 width=4) Filter: ((state)::text = 'FINISHED'::text)
11.2.3
Hash Join (cost=595.69..830.19 rows=100 width=103) Hash Cond: (m.account_id = account.id) -> Seq Scan on membership m (cost=0.00..196.00 rows=10000 width=47) -> Hash (cost=594.44..594.44 rows=100 width=56) -> Limit (cost=593.19..593.44 rows=100 width=56) -> Sort (cost=593.19..618.19 rows=10000 width=56) Sort Key: account.first_name -> Seq Scan on account (cost=0.00..211.00 rows=10000 width=56) -- Hint: Limit er en nodetype som bare returnerer de N første radene fra child noden