-
Notifications
You must be signed in to change notification settings - Fork 163
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
0 parents
commit 4eb1c8d
Showing
29 changed files
with
1,087 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,13 @@ | ||
| venv | ||
| .idea | ||
| build | ||
| dist | ||
| pretrained_models/2stems | ||
| pretrained_models/4stems | ||
| pretrained_models/5stems | ||
| pretrained_models/models-all.7z | ||
| *.log | ||
| *.wav | ||
| *.mp3 | ||
| *.spec | ||
| *.exe |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,94 @@ | ||
| [English README](./README_EN.md) / [Discord](https://discord.gg/TMCM2PfHzQ) / QQ群 902124277 | ||
|
|
||
| # 音乐人声分离工具 | ||
|
|
||
| 这是一个极简的人声和背景音乐分离工具,完全本地化网页操作,无需连接外网,使用 2stems/4stems/5stems 模型。 | ||
|
|
||
| > | ||
| > 将一首歌曲或者含有背景音乐的音视频文件,拖拽到本地网页中,即可将其中的人声和音乐声分离为单独的音频wav文件,可选单独分离“钢琴声”、“贝斯声”、“鼓声”等 | ||
| > | ||
| > 自动调用本地浏览器打开本地网页,模型已内置,无需连接外网下载。 | ||
| > | ||
| > 支持视频(mp4/mov/mkv/avi/mpeg)和音频(mp3/wav)格式 | ||
| > | ||
| > 只需点两下鼠标,一选择音视频文件,二启动处理。 | ||
| > | ||
|
|
||
| # 视频演示 | ||
|
|
||
|
|
||
| https://github.com/jianchang512/clone-voice/assets/3378335/4e63f2ac-cc68-4324-a4d9-ecf4d4f81acd | ||
|
|
||
|
|
||
|
|
||
|  | ||
|
|
||
|
|
||
|
|
||
| # 预编译版使用方法/linux和nac源码部署 | ||
|
|
||
| 1. 右侧[Releases](https://github.com/jianchang512/vocal-separate/releases)中下载预编译文件 | ||
|
|
||
| 2. 下载后解压到某处,比如 E:/vocal-separate | ||
|
|
||
| 3. 双击 start.exe ,等待自动打开浏览器窗口即可 | ||
|
|
||
| 4. 点击页面中的上传区域,在弹窗中找到想分离的音视频文件,或直接拖拽音频文件到上传区域,然后点击“立即分离”,稍等片刻,底部会显示每个分离文件以及播放控件,点击播放。 | ||
|
|
||
| 5. 如果机器拥有英伟达GPU,并正确配置了CUDA环境,将自动使用CUDA加速 | ||
|
|
||
|
|
||
| # 源码部署(linux/mac/window) | ||
|
|
||
| 0. 要求 python 3.9->3.11 | ||
|
|
||
| 1. 创建空目录,比如 E:/vocal-separate, 在这个目录下打开 cmd 窗口,方法是地址栏中输入 `cmd`, 然后回车。 | ||
|
|
||
| 使用git拉取源码到当前目录 ` git clone [email protected]:jianchang512/vocal-separate.git . ` | ||
|
|
||
| 2. 创建虚拟环境 `python -m venv venv` | ||
|
|
||
| 3. 激活环境,win下命令 `%cd%/venv/scripts/activate`,linux和Mac下命令 `source ./venv/bin/activate` | ||
|
|
||
| 4. 安装依赖: `pip install -r requirements.txt` | ||
|
|
||
| 5. win下解压 ffmpeg.7z,将其中的`ffmpeg.exe`和`ffprobe.exe`放在项目目录下, linux和mac 到 [ffmpeg官网](https://ffmpeg.org/download.html)下载对应版本ffmpeg,解压其中的`ffmpeg`和`ffprobe`二进制程序放到项目根目录下 | ||
|
|
||
| 6. 下载模型压缩包,在项目根目录下的 `pretrained_models` 文件夹中解压,解压后,`pretrained_models`中将有3个文件夹,分别是`2stems`/`3stems`/`5stems` | ||
|
|
||
| 7. 执行 `python start.py `,等待自动打开本地浏览器窗口。 | ||
|
|
||
|
|
||
|
|
||
| # CUDA 加速支持 | ||
|
|
||
| **安装CUDA工具** | ||
|
|
||
| 如果你的电脑拥有 Nvidia 显卡,先升级显卡驱动到最新,然后去安装对应的 | ||
| [CUDA Toolkit 11.8](https://developer.nvidia.com/cuda-downloads) 和 [cudnn for CUDA11.X](https://developer.nvidia.com/rdp/cudnn-archive)。 | ||
|
|
||
| 安装完成成,按`Win + R`,输入 `cmd`然后回车,在弹出的窗口中输入`nvcc --version`,确认有版本信息显示,类似该图 | ||
|  | ||
|
|
||
| 然后继续输入`nvidia-smi`,确认有输出信息,并且能看到cuda版本号,类似该图 | ||
|  | ||
|
|
||
|
|
||
|
|
||
| # 注意事项 | ||
|
|
||
| 0. 中文音乐或中式乐器,建议选择使用`2stems`模型,其他模型对“钢琴、贝斯、鼓”可单独分离出文件 | ||
| 1. 如果电脑没有NVIDIA显卡或未配置cuda环境,不要选择 4stems和5stems模型,尤其是处理较长时长的音频时, 否则很可能耗尽内存 | ||
|
|
||
|
|
||
|
|
||
| # 致谢 | ||
|
|
||
| 本项目主要依赖的其他项目 | ||
|
|
||
| 1. https://github.com/deezer/spleeter | ||
| 2. https://github.com/pallets/flask | ||
| 3. https://ffmpeg.org/ | ||
| 4. https://layui.dev | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,93 @@ | ||
| [English README](./README_EN.md) / [Discord](https://discord.gg/TMCM2PfHzQ) / QQ群 902124277 | ||
|
|
||
| # Music Vocal Separation Tool | ||
|
|
||
| This is an extremely simple tool for separating vocals and background music, completely localized for web operation, using 2stems/4stems/5stems models. | ||
|
|
||
| > | ||
| > Drag and drop a song or an audio/video file with background music into the local web page, and you can separate the vocals and music into separate audio wav files. You can choose to separate "piano sound," "bass sound," "drum sound," etc. | ||
| > | ||
| > Automatically invoke the local browser to open the local web page, and the model is built-in, no need to connect to the external network to download. | ||
| > | ||
| > Supports video (mp4/mov/mkv/avi/mpeg) and audio (mp3/wav) formats | ||
| > | ||
| > Just two clicks of the mouse, one to select the audio/video file, and two to start processing. | ||
| > | ||
|
|
||
| # Video Demo | ||
|
|
||
|
|
||
| https://github.com/jianchang512/clone-voice/assets/3378335/4e63f2ac-cc68-4324-a4d9-ecf4d4f81acd | ||
|
|
||
|
|
||
|
|
||
|  | ||
|
|
||
|
|
||
|
|
||
| # Precompiled Version Usage Instructions / Linux and Mac Source Deployment | ||
|
|
||
| 1. Download the precompiled file from [Releases](https://github.com/jianchang512/vocal-separate/releases) on the right side. | ||
|
|
||
| 2. After downloading, unzip it to a certain location, such as E:/vocal-separate. | ||
|
|
||
| 3. Double-click `start.exe`, wait for the browser window to open automatically. | ||
|
|
||
| 4. Click on the upload area on the page, find the audio/video file you want to separate in the pop-up window, or drag the audio file directly to the upload area, and then click "Separate Now." Wait a moment, and at the bottom, each separated file and the playback control will be displayed. Click to play. | ||
|
|
||
| 5. If the machine has an NVIDIA GPU and the CUDA environment is configured correctly, CUDA acceleration will be used automatically. | ||
|
|
||
|
|
||
| # Source Code Deployment (Linux/Mac/Windows) | ||
|
|
||
| 0. Requires python 3.9->3.11 | ||
|
|
||
| 1. Create an empty directory, such as E:/vocal-separate. Open a cmd window in this directory, the method is to enter `cmd` in the address bar, and then press Enter. | ||
|
|
||
| Use git to pull the source code to the current directory ` git clone [email protected]:jianchang512/vocal-separate.git . ` | ||
|
|
||
| 2. Create a virtual environment `python -m venv venv` | ||
|
|
||
| 3. Activate the environment. On Windows, the command is `%cd%/venv/scripts/activate`, and on Linux and Mac, the command is `source ./venv/bin/activate` | ||
|
|
||
| 4. Install dependencies: `pip install -r requirements.txt` | ||
|
|
||
| 5. On Windows, unzip ffmpeg.7z and place `ffmpeg.exe` and `ffprobe.exe` in the project directory. On Linux and Mac, download the corresponding version of ffmpeg from [ffmpeg official website](https://ffmpeg.org/download.html), unzip it, and place the `ffmpeg` and `ffprobe` binary programs in the project root directory. | ||
|
|
||
| 6. 下载模型压缩包,在项目根目录下的 `pretrained_models` 文件夹中解压,解压后,`pretrained_models`中将有3个文件夹,分别是`2stems`/`3stems`/`5stems` | ||
|
|
||
| 6. Execute `python start.py`, and wait for the local browser window to open automatically. | ||
|
|
||
|
|
||
|
|
||
| # CUDA Acceleration Support | ||
|
|
||
| **Install CUDA Toolkit** | ||
|
|
||
| If your computer has an Nvidia graphics card, upgrade the graphics card driver to the latest version, and then go to install the corresponding | ||
| [CUDA Toolkit 11.8](https://developer.nvidia.com/cuda-downloads) and [cudnn for CUDA11.X](https://developer.nvidia.com/rdp/cudnn-archive). | ||
|
|
||
| After the installation is complete, press `Win + R`, enter `cmd`, and then press Enter. In the popped up window, enter `nvcc --version` to confirm that there is version information displayed, similar to the picture | ||
|  | ||
|
|
||
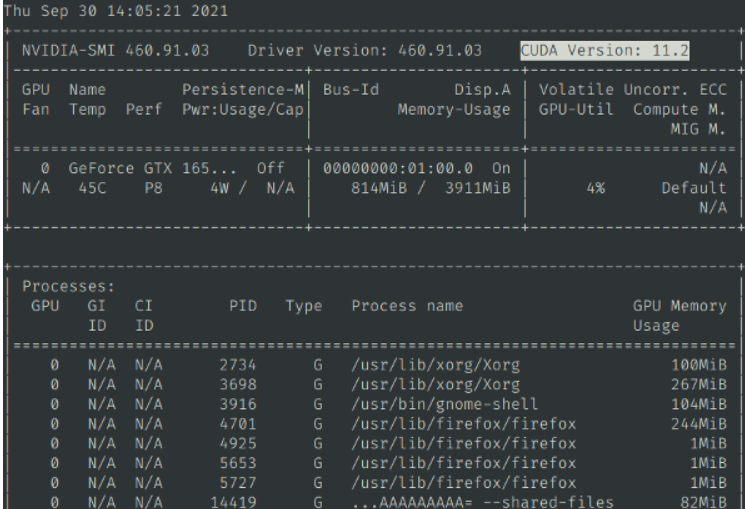
| Then continue to enter `nvidia-smi`, confirm that there is output information, and you can see the CUDA version number, similar to the picture | ||
|  | ||
|
|
||
|
|
||
|
|
||
| # Notes | ||
|
|
||
| 0. For Chinese music or Chinese musical instruments, it is recommended to choose the `2stems` model. Other models can separately extract files for "piano, bass, and drums." | ||
| 1. If the computer does not have an NVIDIA graphics card or has not configured the CUDA environment, do not choose the 4stems and 5stems models, especially when processing long-duration audio, otherwise, it may run out of memory. | ||
|
|
||
|
|
||
|
|
||
| # Acknowledgments | ||
|
|
||
| This project mainly relies on other projects | ||
|
|
||
| 1. https://github.com/deezer/spleeter | ||
| 2. https://github.com/pallets/flask | ||
| 3. https://ffmpeg.org/ | ||
| 4. https://layui |
Binary file not shown.
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Empty file.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,5 @@ | ||
| flask | ||
| requests | ||
| gevent | ||
| tensorflow | ||
| spleeter |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,140 @@ | ||
| import logging | ||
| import threading | ||
| import sys | ||
| from flask import Flask, request, render_template, jsonify, send_from_directory | ||
| import os | ||
| from gevent.pywsgi import WSGIServer | ||
| from logging.handlers import RotatingFileHandler | ||
| from vocal import cfg, tool | ||
| from vocal.cfg import ROOT_DIR | ||
|
|
||
| from spleeter.separator import Separator | ||
|
|
||
|
|
||
| app = Flask(__name__, static_folder=os.path.join(ROOT_DIR, 'static'), static_url_path='/static', | ||
| template_folder=os.path.join(ROOT_DIR, 'templates')) | ||
| # 配置日志 | ||
| app.logger.setLevel(logging.INFO) # 设置日志级别为 INFO | ||
| # 创建 RotatingFileHandler 对象,设置写入的文件路径和大小限制 | ||
| file_handler = RotatingFileHandler(os.path.join(ROOT_DIR, 'vocal.log'), maxBytes=1024 * 1024, backupCount=5) | ||
| # 创建日志的格式 | ||
| formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') | ||
| # 设置文件处理器的级别和格式 | ||
| file_handler.setLevel(logging.INFO) | ||
| file_handler.setFormatter(formatter) | ||
| # 将文件处理器添加到日志记录器中 | ||
| app.logger.addHandler(file_handler) | ||
|
|
||
|
|
||
| @app.route('/static/<path:filename>') | ||
| def static_files(filename): | ||
| return send_from_directory(app.config['STATIC_FOLDER'], filename) | ||
|
|
||
| @app.route('/') | ||
| def index(): | ||
| return render_template("index.html",cuda=cfg.cuda, language=cfg.LANG,root_dir=ROOT_DIR.replace('\\', '/')) | ||
|
|
||
|
|
||
| # 上传音频 | ||
| @app.route('/upload', methods=['POST']) | ||
| def upload(): | ||
| try: | ||
| # 获取上传的文件 | ||
| audio_file = request.files['audio'] | ||
| # 如果是mp4 | ||
| noextname, ext = os.path.splitext(audio_file.filename) | ||
| ext = ext.lower() | ||
| # 如果是视频,先分离 | ||
| wav_file = os.path.join(cfg.TMP_DIR, f'{noextname}.wav') | ||
| if os.path.exists(wav_file) and os.path.getsize(wav_file) > 0: | ||
| return jsonify({'code': 0, 'msg': cfg.transobj['lang1'], "data": os.path.basename(wav_file)}) | ||
| msg="" | ||
| if ext in ['.mp4', '.mov', '.avi', '.mkv', '.mpeg', '.mp3']: | ||
| video_file = os.path.join(cfg.TMP_DIR, f'{noextname}{ext}') | ||
| audio_file.save(video_file) | ||
| params = [ | ||
| "-i", | ||
| video_file, | ||
| ] | ||
| if ext != '.mp3': | ||
| params.append('-vn') | ||
| params.append(wav_file) | ||
| rs = tool.runffmpeg(params) | ||
| if rs != 'ok': | ||
| return jsonify({"code": 1, "msg": rs}) | ||
| msg=","+cfg.transobj['lang9'] | ||
| elif ext == '.wav': | ||
| audio_file.save(wav_file) | ||
| else: | ||
| return jsonify({"code": 1, "msg": f"{cfg.transobj['lang3']} {ext}"}) | ||
|
|
||
| # 返回成功的响应 | ||
| return jsonify({'code': 0, 'msg': cfg.transobj['lang1']+msg, "data": os.path.basename(wav_file)}) | ||
| except Exception as e: | ||
| app.logger.error(f'[upload]error: {e}') | ||
| return jsonify({'code': 2, 'msg': cfg.transobj['lang2']}) | ||
|
|
||
|
|
||
| # 根据文本返回tts结果,返回 name=文件名字,filename=文件绝对路径 | ||
| # 请求端根据需要自行选择使用哪个 | ||
| # params | ||
| # wav_name:tmp下的wav文件 | ||
| # model 模型名称 | ||
| @app.route('/process', methods=['GET', 'POST']) | ||
| def process(): | ||
| # 原始字符串 | ||
| wav_name = request.form.get("wav_name").strip() | ||
| model = request.form.get("model") | ||
| wav_file = os.path.join(cfg.TMP_DIR, wav_name) | ||
| noextname = wav_name[:-4] | ||
| if not os.path.exists(wav_file): | ||
| return jsonify({"code": 1, "msg": f"{wav_file} {cfg.langlist['lang5']}"}) | ||
| if not os.path.exists(os.path.join(cfg.MODEL_DIR, model, 'model.meta')): | ||
| return jsonify({"code": 1, "msg": f"{model} {cfg.transobj['lang4']}"}) | ||
|
|
||
| separator = Separator(f'spleeter:{model}', multiprocess=False) | ||
| dirname = os.path.join(cfg.FILES_DIR, noextname) | ||
| try: | ||
| separator.separate_to_file(wav_file, destination=dirname, filename_format="{instrument}.{codec}") | ||
| except Exception as e: | ||
| return jsonify({"code": 1, "msg": str(e)}) | ||
| status={ | ||
| "accompaniment":"伴奏", | ||
| "bass":"低音", | ||
| "drums":"鼓", | ||
| "piano":"琴", | ||
| "vocals":"人声", | ||
| "other":"其他" | ||
| } | ||
| data = [] | ||
| urllist = [] | ||
| for it in os.listdir(dirname): | ||
| if it.endswith('.wav'): | ||
| data.append( status[it[:-4]] if cfg.LANG=='zh' else it[:-4]) | ||
| urllist.append(f'http://{cfg.web_address}/static/files/{noextname}/{it}') | ||
|
|
||
| return jsonify({"code": 0, "msg": cfg.transobj['lang6'], "data": data, "urllist": urllist,"dirname":dirname}) | ||
|
|
||
|
|
||
| @app.route('/checkupdate', methods=['GET', 'POST']) | ||
| def checkupdate(): | ||
| return jsonify({'code': 0, "msg": cfg.updatetips}) | ||
|
|
||
|
|
||
| if __name__ == '__main__': | ||
| try: | ||
| threading.Thread(target=tool.checkupdate).start() | ||
| http_server = None | ||
| try: | ||
| host = cfg.web_address.split(':') | ||
| http_server = WSGIServer((host[0], int(host[1])), app) | ||
| threading.Thread(target=tool.openweb, args=(cfg.web_address,)).start() | ||
| http_server.serve_forever() | ||
| finally: | ||
| if http_server: | ||
| http_server.stop() | ||
| except Exception as e: | ||
| if http_server: | ||
| http_server.stop() | ||
| print("error:" + str(e)) | ||
| app.logger.error(f"[app]start error:{str(e)}") |
Large diffs are not rendered by default.
Oops, something went wrong.
Binary file not shown.
Oops, something went wrong.