Development Blog
Welcome to the retro-fuse development blog
This is intended to be an (infrequently updated) series of posts about development activities on retro-fuse.
Welcome to the first post in the new retro-fuse development blog. My name is Jay Logue, and I’m the author and (as of yet) sole contributor to the retro-fuse project.
Looking back, it seems I have been working on retro-fuse for over a year and a half now. During that time, my efforts have certainly come in fits and starts, but a lot of good things have been achieved. retro-fuse now supports filesystems from 4 pivotal versions of ancient Unix: version 6 research Unix, version 7 research Unix, 2.9BSD and 2.11BSD. Additionally, the project now includes a comprehensive testing framework that (among other checks) verifies the correctness of generated filesystems using the original filesystem diagnostic tools (icheck, fsck, etc.). This latter feature gives me great confidence in the reliability of retro-fuse, and is one I’m most proud of.
Despite these achievements, the past 6 months has seen a lull in work on retro-fuse. This is largely due to my focus on other personal projects, such as restoring a vintage memory extension box for use on my 1972 PDP-11/05 system. This has left me feeling like I have neglected the retro-fuse project.
So, to reinvigorate my efforts on retro-fuse, I’ve decided to enter the 2022 RetroChallenge contest. RetroChallenge is a low-key, "friendly competition" intended to encourage work on projects of interest to retro-computing enthusiasts. Contestants are asked to complete a self-defined retro-computing project over the course of a month, documenting their progress along the way. Contest prizes, such as they are, are equally low-key, with winners essentially receiving a hearty "Thank You" from event organizers.
My goal for the 2022 RetroChallenge is to add Xenix filesystem support to retro-fuse. This will be a somewhat unique task, in that, unlike the other versions of Unix supported, the original source code for Xenix is not readily available. Nonetheless, my (possibly naive) understanding is that Xenix filesystems are largely styled after their research Unix progenitors (e.g. v7 in the case of early Xenix versions). So my hope is to be able to repurpose existing ancient Unix code in support of this task. We’ll see if this pans out.
The first order of business, however, is to determine which versions of Xenix had distinct filesystem structures. Depending on how many there are, I will likely start with providing support for the earliest versions first.
Before tackling the job of writing a filesystem handler (or handlers) for Xenix, I really need to wrap my head around the different versions of Xenix, and which ones might have distinct filesystem formats. Although a lot of people remember Xenix, having used it back in its day, tracking down a definitive timeline of Xenix releases has proven to be more challenging than I expected.
My own relationship with Xenix began in the mid-80’s when I was loaned a copy of Xenix 286 for my IBM PC/AT. This was my first real introduction to Unix of any kind. Coming from the parallel worlds of Apple DOS and MS-DOS, the Xenix experience was arcane, opaque and frankly more than a little off-putting. I got it installed, played around a bit, but quickly set it aside to work in environments that felt more productive. Some years later, after having spent quite a bit of time learning and developing in 4.3BSD, I had the chance to use SCO Xenix on a 386 (with gnu tools) and found the experience much more comfortable.
I realize now that the 286 version of Xenix that I originally installed on my PC/AT was hardly the first version of Xenix ever. Unfortunately, the precise lineage of versions that preceded it is still somewhat mysterious to me. The most definite timeline for Xenix I have found comes from Rob Ferguson, who was a member of the Xenix group inside Microsoft in the late 80s. His A bit of XENIX history blog post contains a very informative, if somewhat figurative, depiction of Xenix versions produced over time for each of the major CPU architectures. Wikipedia has a more synoptic retelling of Xenix history, but this rendition is unfortunately light on precise version details. Finally, there is Nikolai Bezroukov’s XENIX — Microsoft Short-lived Love Affair with Unix, which has a rather strident anti-Linux tone, but contains some interesting historical links.
Complicating my understanding of Xenix history is the confusing progression of version numbers attached to variants at different points in time, and by different parties. Mainline versions were named simply XENIX V1.0, XENIX V2.0, XENIX V3.0. However some Xenix OEMs chose to issue their own version numbers which were unaligned with the main version numbers. Examples of this include Altos Xenix, IBM PC XENIX and Tandy’s TRS-XENIX. Furthermore, in later years Microsoft and SCO produced XENIX System V, which had version numbers of the form 2.x.x and 3.x.x. So often one will encounter files with shorthand names like “Xenix 2.1.3”, which are in fact variants of the later XENIX System V rather than the earlier XENIX V2.0.
For my purposes, which largely revolves around evolution of the filesystem structure, I break down the various iterations of Xenix into the following three groups:
Early Xenix – Based on 7th Edition Unix and targeted at PDP-11, Z-8000 and some 68000 systems. Although there are various first-hand accounts of these versions in the day, the actual bits seem to have been lost to time.
Xenix V3.0 variants – Based on Unix System III and targeted at a variety of hardware, including the IBM PC/AT, the Apple Lisa, the Tandy Models 16 and 6000, and a smattering of Altos machines. Installation media is available for most of these versions, and emulators capable of running Xenix exist for the PC/AT, Lisa and Tandy machines.
Xenix System V variants – Based on Unix System V and targeting various hardware, including the original IBM PC/XT as well as 386-based IBM compatibles. Installation media is available and should be runnable on emulators such as qemu, virtualbox and vmware.
Having sorted the various versions of Xenix in my head, it was time to get a live Xenix system running in emulation. I have selected IBM PC Xenix 1.0 as the initial candidate. This is a port of Xenix 3.0, and is one of the earliest versions of Xenix for which installation images exist (see here and here).
IBM PC Xenix 1.0 requires a true PC/AT (286) compatible system for installation. It will not work on the original PC or XT systems (8088) or on later 386 systems. Word on the street is that Microsoft played tricks with the 286 port of Xenix 3.0 that made it incompatible with later Intel processors. Unfortunately, this limits the range of available emulators. Although many people have reported success using qemu to boot Xenix, all of these were accomplished using the later System V variants, which appear to be more tolerant of 386 systems. (Others have shown success using VirtualBox, however these required patches to the Xenix binaries).
For this effort, I chose to use the excellent 86Box IBM PC Emulator package (v3.7.1, build 4032). 86Box contains a fairly accurate IBM PC AT emulation, with lots of support for emulating period PC hardware. Other emulators with true 286 emulation would likely work as well, such as PCem (a precursor of 86Box being developed in parallel).
Installing IBM PC Xenix 1.0 turned out to be relatively straightforward, with only a few gotchas. Helpfully, copies of the IBM PC Xenix 1.0 Installation Guide, which describes the installation process, are available online.
The gotchas I ran into mainly involved the choice of period-correct hardware. For example, this version of Xenix is sensitive to the type of display adapter chosen, requiring the use of an MDA video card, or a CGA card in 80 column mode. Using something more modern than this, such as an EGA or VGA card, will result in a kernel hang.
To aid others in following my path, I have created a wiki page describing the exact steps for Installing IBM PC XENIX 1.0 using 86Box.
Once the base operating system was installed, I was able to install the development system (available here).
This gave me access to the system header files. These header files will be the starting point for the next step of my journey, which is understanding the Xenix filesystem layout on disk and how it relates to 7th edition Unix and/or AT&T Unix System III…
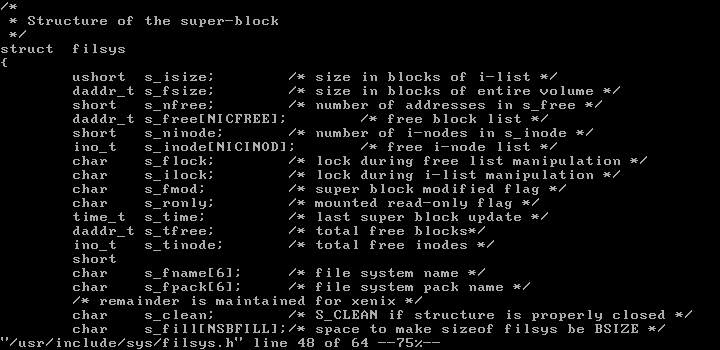
A necessary part of my task is understanding exactly how the Xenix filesystem is organized on disk. In the Unixes of this era, the filesystem structure was largely defined by a set of C structures and defines declared in system header files. Perhaps the most important of these is the filsys struct which defines the on-disk structure of the filesystem’s super block. Bell Labs evolved the C structures that define the Unix filesystem many times over the course of Unix history. Additionally, each time a particular release of Unix was ported to a new system there was an opportunity for those doing the porting to tweak the filesystem structure to their particular needs. Unsurprisingly, the Xenix filesystem shows exactly this sort of tweaking, with new, Xenix-specific fields being added to the filsys structure as compared to the base Unix source.
Complicating the picture further is the fact that, because C structures are used to define the format, the exact binary arrangement of the bytes on disk is ultimately determined by the system’s C compiler, and by the target processor architecture. For example, the count of free blocks stored in the superblock will have a different layout on disk depending on whether the target system is little or big-endian. From the point of view of retro-fuse, each one of these combinations (C structure definition, system endianness, custom filesystem tweaks) essentially constitutes a distinct filesystem type, requiring some amount of unique code in each case.
To make sense of the different versions, I’ve compiled a filesystem comparison document that shows the parameters and structures of the Xenix filesystem and compares them to their counterparts from the original AT&T Unix source. This information was gathered from the various versions of early Xenix (up to 3.0) I could find online.
In a nutshell, I have identified four distinct Xenix filesystem layouts:
-
7th Edition-based fileysystems, 512B blocks, big-endian (TRS-XENIX v1.x)
-
7th Edition-based fileysystems, 512B blocks, little-endian (Altos Xenix 2.x for ACS 8600)
-
System III-based filesystems, 512B blocks, big-endian (Tandy 68000 XENIX v3.x)
-
System III-based filesystems, 1KB blocks, little-endian format (IBM PC XENIX 1.0)
Next up, how best to organize the code to read and write these filesystems.
Well, with the ending of October, the 2022 RetroChallenge is now officially over. At this point, I think it’s pretty clear I’m not going to be winning any prizes for my retro-fuse work. Looking back at the month, I can rightfully claim that injury, illness and house repair have all conspired to limit my time on the project. Nonetheless I’m fairly happy with how things have progressed. The project is certainly more involved than I had anticipated. But I now believe I have a workable plan for completing it and have begun writing code based on that plan.
In a nutshell, my plan is to take the v7 Unix filesystem code and generalize it so that it can read and write any filesystem that largely conforms to the v7 layout. I’ll be starting with the lightly modernized copy of v7 code that I already have, which currently supports reading and writing PDP-11 v7 filesystems, and then teaching it a number of new tricks. These include such things as dealing with multiple superblock formats, handling differing filesystem block sizes, and reading and writing integer values with varying endianness. All of these actions were originally hard-coded in the v7 source, or inherent in the code generated by the compiler. In the new code, however, these will need to be implemented dynamically, with appropriate behaviors chosen at runtime.
One question that seems obvious to ask is: Why start with the v7 code? Why not write the code from scratch? Or start with code from another source that already supports Xenix filesystems, such as the linux sysv filesystem? The answer to that is authenticity. By starting with v7 code and selectively generalizing it to support what are essentially minor variations on a theme, I ensure the integrity of algorithms that affect the filesystem’s layout on disk. As the primary goal of this project is to create a tool that can not only read but also generate period-correct filesystems, this level of integrity is important. Of course the ideal starting point would be the original Xenix source code itself. But alas this is not available. And so v7, being the most relevant open-source ancestor, is the next best thing. A side benefit of this approach is that, in the future, the code can be leveraged to support other v7-related filesystems, such as System III on the PDP-11, some System V versions, or even Coherent (a Unix ‘clone’).