We provide a set of classes with which you can embed the words in sentences in various ways. This tutorial explains how that works. We assume that you're familiar with the base types of this library.
All word embedding classes inherit from the TokenEmbeddings class and implement the embed() method which you need to
call to embed your text. This means that for most users of Flair, the complexity of different embeddings remains
hidden behind this interface. Simply instantiate the embedding class you require and call embed() to embed your text.
All embeddings produced with our methods are Pytorch vectors, so they can be immediately used for training and fine-tuning.
Classic word embeddings are static and word-level, meaning that each distinct word gets exactly one pre-computed embedding. Most embeddings fall under this class, including the popular GloVe or Komnios embeddings.
Simply instantiate the WordEmbeddings class and pass a string identifier of the embedding you wish to load. So, if you want to use GloVe embeddings, pass the string 'glove' to the constructor:
from flair.embeddings import WordEmbeddings
# init embedding
glove_embedding = WordEmbeddings('glove')Now, create an example sentence and call the embedding's embed() method. You can also pass a list of sentences to
this method since some embedding types make use of batching to increase speed.
# create sentence.
sentence = Sentence('The grass is green .')
# embed a sentence using glove.
glove_embedding.embed(sentence)
# now check out the embedded tokens.
for token in sentence:
print(token)
print(token.embedding)This prints out the tokens and their embeddings. GloVe embeddings are Pytorch vectors of dimensionality 100.
You choose which pre-trained embeddings you load by passing the appropriate
id string to the constructor of the WordEmbeddings class. Typically, you use
the two-letter language code to init an embedding, so 'en' for English and
'de' for German and so on. By default, this will initialize FastText embeddings trained over Wikipedia.
You can also always use FastText embeddings over Web crawls, by instantiating with '-crawl'. So 'de-crawl'
to use embeddings trained over German web crawls.
For English, we provide a few more options, so here you can choose between instantiating 'en-glove', 'en-extvec' and so on.
The following embeddings are currently supported:
| ID | Language | Embedding |
|---|---|---|
| 'en-glove' (or 'glove') | English | GloVe embeddings |
| 'en-extvec' (or 'extvec') | English | Komnios embeddings |
| 'en-crawl' (or 'crawl') | English | FastText embeddings over Web crawls |
| 'en-twitter' (or 'twitter') | English | Twitter embeddings |
| 'en-turian' (or 'turian') | English | Turian embeddings (small) |
| 'en' (or 'en-news' or 'news') | English | FastText embeddings over news and wikipedia data |
| 'de' | German | German FastText embeddings |
| 'nl' | Dutch | Dutch FastText embeddings |
| 'fr' | French | French FastText embeddings |
| 'it' | Italian | Italian FastText embeddings |
| 'es' | Spanish | Spanish FastText embeddings |
| 'pt' | Portuguese | Portuguese FastText embeddings |
| 'ro' | Romanian | Romanian FastText embeddings |
| 'ca' | Catalan | Catalan FastText embeddings |
| 'sv' | Swedish | Swedish FastText embeddings |
| 'da' | Danish | Danish FastText embeddings |
| 'no' | Norwegian | Norwegian FastText embeddings |
| 'fi' | Finnish | Finnish FastText embeddings |
| 'pl' | Polish | Polish FastText embeddings |
| 'cz' | Czech | Czech FastText embeddings |
| 'sk' | Slovak | Slovak FastText embeddings |
| 'pl' | Slovenian | Slovenian FastText embeddings |
| 'sr' | Serbian | Serbian FastText embeddings |
| 'hr' | Croatian | Croatian FastText embeddings |
| 'bg' | Bulgarian | CroatBulgarianian FastText embeddings |
| 'ru' | Russian | Russian FastText embeddings |
| 'ar' | Arabic | Arabic FastText embeddings |
| 'he' | Hebrew | Hebrew FastText embeddings |
| 'tr' | Turkish | Turkish FastText embeddings |
| 'pa' | Persian | Persian FastText embeddings |
| 'ja' | Japanese | Japanese FastText embeddings |
| 'ko' | Korean | Korean FastText embeddings |
| 'zh' | Chinese | Chinese FastText embeddings |
| 'hi' | Hindi | Hindi FastText embeddings |
| 'id' | Indonesian | Indonesian FastText embeddings |
| 'eu' | Basque | Basque FastText embeddings |
So, if you want to load German FastText embeddings, instantiate as follows:
german_embedding = WordEmbeddings('de')Alternatively, if you want to load German FastText embeddings trained over crawls, instantiate as follows:
german_embedding = WordEmbeddings('de-crawl')We generally recommend the FastText embeddings, or GloVe if you want a smaller model.
If you want to use any other embeddings (not listed in the list above), you can load those by calling
custom_embedding = WordEmbeddings('path/to/your/custom/embeddings.gensim')If you want to load custom embeddings you need to make sure, that the custom embeddings are correctly formatted to gensim.
You can, for example, convert FastText embeddings to gensim using the following code snippet:
import gensim
word_vectors = gensim.models.KeyedVectors.load_word2vec_format('/path/to/fasttext/embeddings.txt', binary=False)
word_vectors.save('/path/to/converted')Some embeddings - such as character-features - are not pre-trained but rather trained on the downstream task. Normally this requires you to implement a hierarchical embedding architecture.
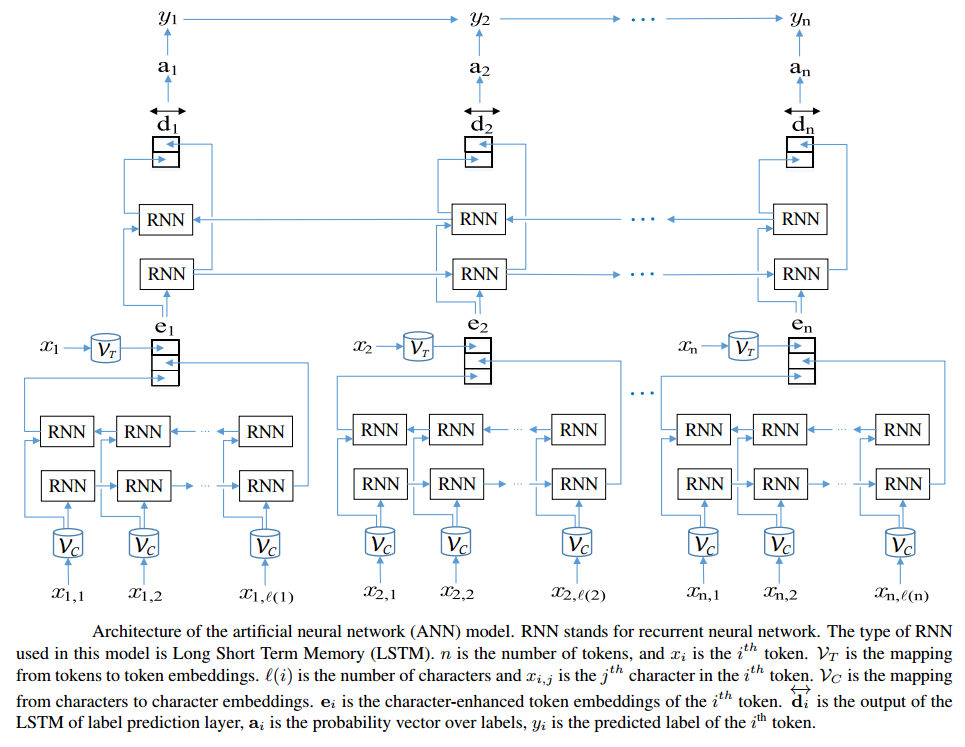{kind=link}
With Flair, you don't need to worry about such things. Just choose the appropriate embedding class and character features will then automatically train during downstream task training.
from flair.embeddings import CharacterEmbeddings
# init embedding
embedding = CharacterEmbeddings()
# create a sentence
sentence = Sentence('The grass is green .')
# embed words in sentence
embedding.embed(sentence)We now also include the byte pair embeddings calulated by @bheinzerling that segment words into subsequences.
This can dramatically reduce the model size vis-a-vis using normal word embeddings at nearly the same accuracy.
So, if you want to train small models try out the new BytePairEmbeddings class.
You initialize with a language code (275 languages supported), a number of 'syllables' (one of ) and a number of dimensions (one of 50, 100, 200 or 300). The following initializes and uses byte pair embeddings for English:
from flair.embeddings import BytePairEmbeddings
# init embedding
embedding = BytePairEmbeddings('en')
# create a sentence
sentence = Sentence('The grass is green .')
# embed words in sentence
embedding.embed(sentence)More information can be found on the byte pair embeddings web page. Given its memory advantages, we would be interested to hear from the community how well these embeddings work.
Stacked embeddings are one of the most important concepts of this library. You can use them to combine different embeddings together, for instance if you want to use both traditional embeddings together with contextual string embeddings (see next chapter). Stacked embeddings allow you to mix and match. We find that a combination of embeddings often gives best results.
All you need to do is use the StackedEmbeddings class and instantiate it by passing a list of embeddings that you wish
to combine. For instance, lets combine classic GloVe embeddings with character embeddings. This is effectively the architecture proposed in (Lample et al., 2016).
First, instantiate the two embeddings you wish to combine:
from flair.embeddings import WordEmbeddings, CharacterEmbeddings
# init standard GloVe embedding
glove_embedding = WordEmbeddings('glove')
# init standard character embeddings
character_embeddings = CharacterEmbeddings()Now instantiate the StackedEmbeddings class and pass it a list containing these two embeddings.
from flair.embeddings import StackedEmbeddings
# now create the StackedEmbedding object that combines all embeddings
stacked_embeddings = StackedEmbeddings(
embeddings=[glove_embedding, character_embeddings])That's it! Now just use this embedding like all the other embeddings, i.e. call the embed() method over your sentences.
sentence = Sentence('The grass is green .')
# just embed a sentence using the StackedEmbedding as you would with any single embedding.
stacked_embeddings.embed(sentence)
# now check out the embedded tokens.
for token in sentence:
print(token)
print(token.embedding)Words are now embedded using a concatenation of two different embeddings. This means that the resulting embedding vector is still a single PyTorch vector.
You can now either look into BERT, ELMo, and Flair embeddings, or go directly to the tutorial about loading your corpus, which is a pre-requirement for training your own models.