{kind=link}
Implementation of Paraboth: Evaluating Paraphrastic Similarity in ASR Output. Unlike the original approach, this version:
- Handles entire corpora by splitting into sentences and aligning them.
- Uses a Large Language Model API for paraphrasing instead of the PRISM model.
Paraboth is especially useful for ASR systems where the transcription is also a translation at the same time, such as transcribing Swiss-German to Standard-German. Instead of comparing 1:1, it compares the paraphrases of the transcriptions to the paraphrases of the ground truth.
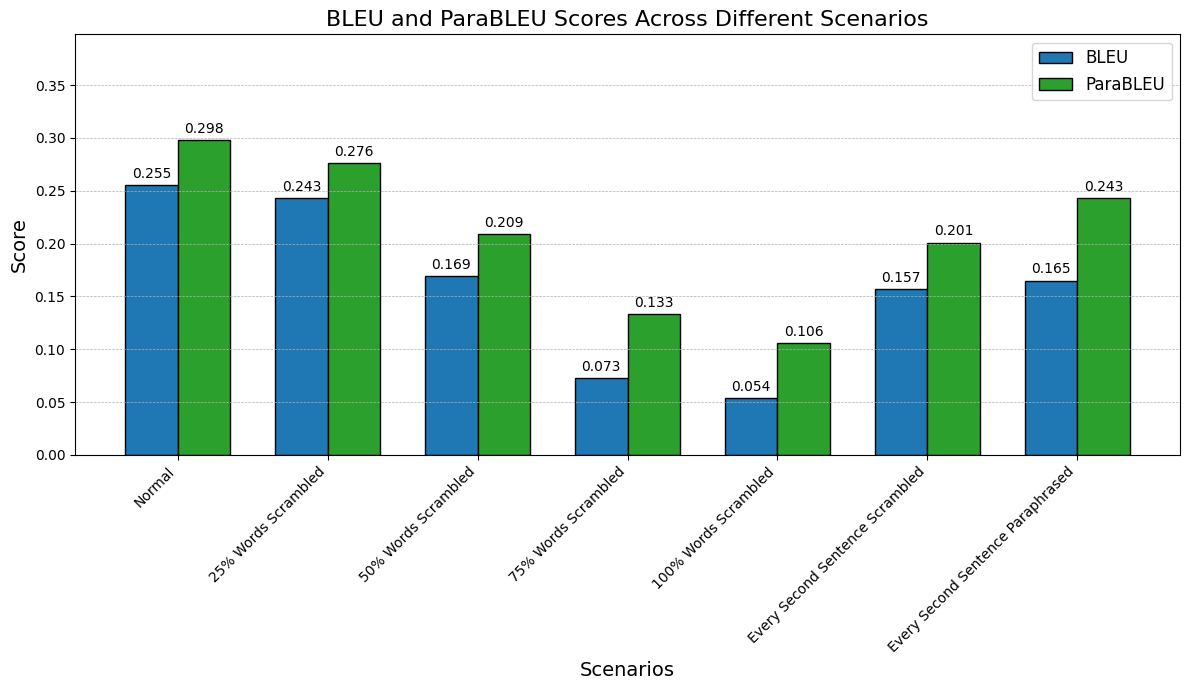
To evaluate the performance on ParabothCorpus, we scrambled randomly X% of a corpus and then calculated ParaBleu and Bleu scores. Both metrics go down when the predicted text is being scrambled (which is wanted). When instead of scrambling we paraphrase 50% of the sentences, ParaBleu is less affected than Bleu. This is because ParaBoth is able to detect paraphrases and not just exact matches.
pip install parabothThe alignment process leverages a dynamic programming approach, similar to sequence alignment techniques, ensuring that sentences are matched optimally based on their embedding similarities. By computing embeddings for both ground truth and predicted sentences, we construct a similarity matrix that quantifies how closely each predicted sentence corresponds to each ground truth sentence. With these similarity scores, we apply a dynamic programming algorithm to find the sequence of matches (pairs of sentence indices) that yields the highest total similarity score.
Key steps:
- Embedding: Each sentence in both ground truth and predictions is turned into an embedding vector using the configured
Embedder. - Similarity Matrix: We compute a similarity matrix where each cell represents the similarity between a predicted sentence embedding and a ground truth sentence embedding.
- Dynamic Programming Alignment: Using a
SentenceAligner(from dtwsa), the algorithm:- Iterates through the similarity matrix to find the best possible alignment.
- Matches sentences only if their similarity score meets a minimum threshold, ensuring low-quality matches are avoided.
- Employs a dynamic programming approach to find the highest-scoring path through the matrix, resulting in optimal sentence-to-sentence alignments.
- Sliding Window (Corpus-Level): For corpora where sentences differ in length or segmentation, a sliding window mechanism is used before alignment to allow flexible matching. This approach mitigates heavy penalties when sentence counts differ, enabling more robust, context-aware alignment.
This combined approach ensures that the final alignment between predicted and ground truth texts is both meaningful and robust, providing an accurate foundation for evaluating paraphrastic similarity.
python paraboth_corpus.py \ # Corpus-level comparison.
--gt path/to/gt_corpus.txt \
--pred path/to/pred_corpus.txt \
--n_paraphrases 6 \ # Number of paraphrases to generate for each sentence.
--paraphrase_gt True \ # Whether to paraphrase the ground truth sentences.
--paraphrase_pred True \ # Whether to paraphrase the predicted sentences.
--window_size 3 \ # Size of the sliding window for corpus-level comparison.
--base_output_dir results \ # Directory to save the results.
--min_matching_value 0.5 # Minimum similarity score for an alignment to even happen (see DTWSA documentation).python paraboth_sentences.py \ # Sentence-level comparison.
--gt path/to/gt_sentences.txt \
--pred path/to/pred_sentences.txt \
--n_paraphrases 6 \ # Number of paraphrases to generate for each sentence.
--paraphrase_gt True \ # Whether to paraphrase the ground truth sentences.
--paraphrase_pred True \ # Whether to paraphrase the predicted sentences.
--base_output_dir results \ # Directory to save the results.By default, Embedder and Paraphraser use Azure OpenAI and a given paraphrasing prompt. If you want to integrate your own embeddings or paraphrasing logic, extend the following base classes and implement the required methods. Then, bass the initialized class to the paraboth or paraboth_corpus functions.
class BaseEmbedder:
def embed_chunks(self, text_chunks, batch_size=100):
raise NotImplementedError("Implement this method.")
def get_embeddings(self):
raise NotImplementedError("Implement this method.")
def save_embeddings(self, file_path):
raise NotImplementedError("Implement this method.")
def load_embeddings(self, file_path):
raise NotImplementedError("Implement this method.")class BaseParaphraser:
def paraphrase(self, sentence: str, n_sentences: int = 6):
raise NotImplementedError("Implement this method.")
def paraphrase_list(self, sentences: list, n_sentences=6, min_words=3):
raise NotImplementedError("Implement this method.")