爬取的数据重置时间索引为逐小时
-
能正常打开以下两个网站,打不开的自己想办法:
-
一点耐心
Wunderground.com是一个提供本地和长期天气预报、天气报告、地图和热带气象条件的网站。它还提供了一个交互式天气地图和雷达。如果您想查看某个地区的历史天气,该网站提供了一个表格形式的历史天气记录,其中包含主要要素的取整数据,有小时数据。
by New Bing
wunderground.com包含历史气象数据,优点是时间颗粒度为逐半小时,缺点是站点并不是很多,大部分为机场数据。
因为需要进行气象因素的时间序列研究,写了一段爬虫,这里顺便分享给大家。
以白云机场为例,在搜索框搜索 “baiyun”, 第一个搜索结果便是。
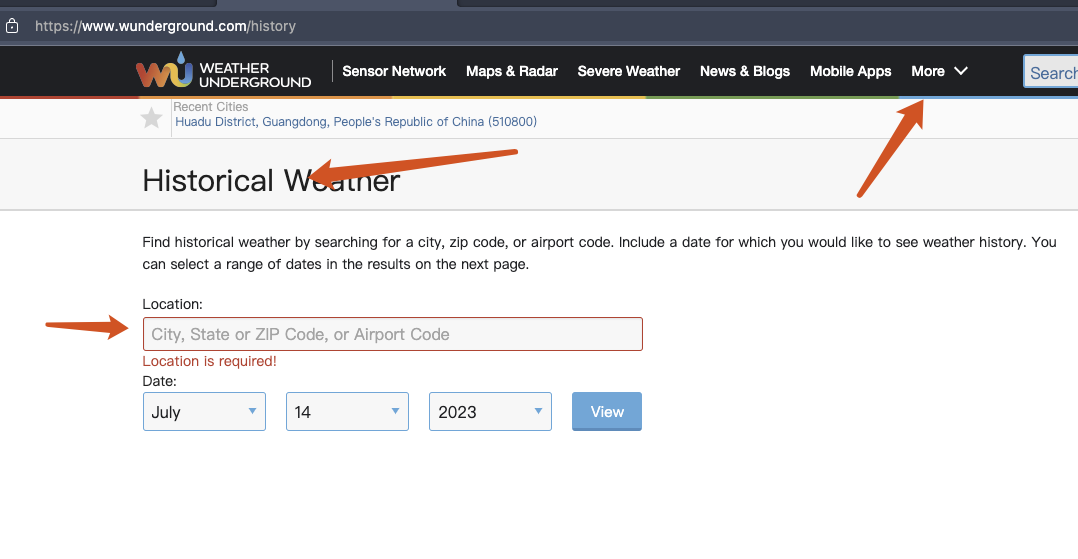
由于数据是异步加载,一开始可能显示没有数据,要等一小会。

按 F12 打开浏览器的开发者工具,在搜素框搜索 "https://api.weather.com/v1/location/",这一网站是从该api服务中调用数据。
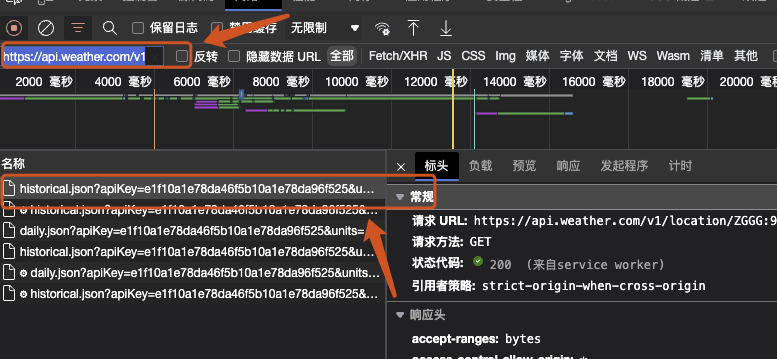
但这里会显示很多个相关结果,需要找到下面这个
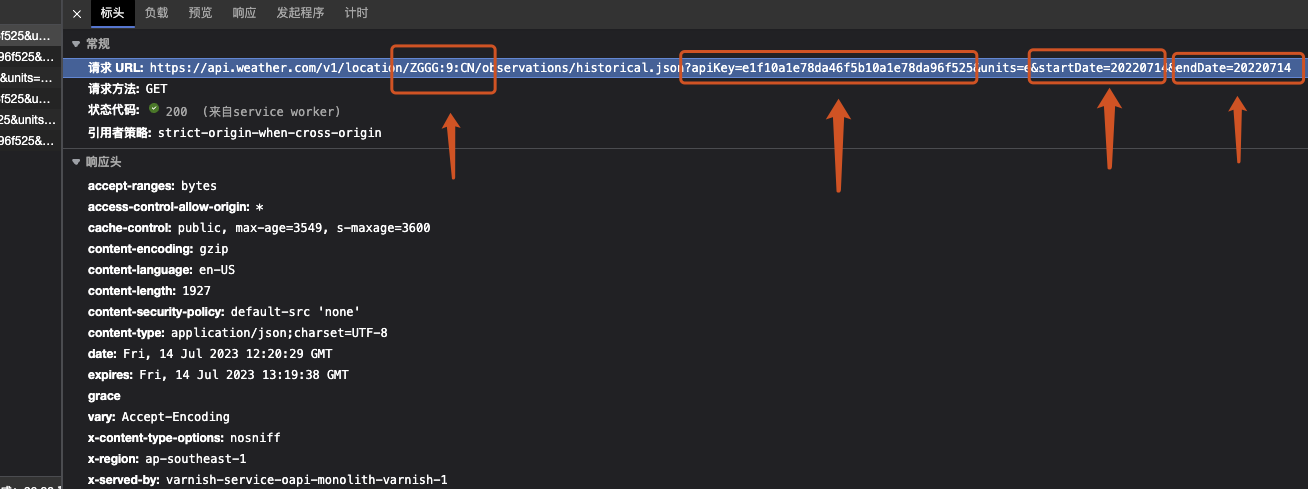
包括四个东西:
-
location/ZGGG:9:CN:白云机场的标识
-
apikey
-
start_date:开始日期
-
end_data:结束日期
开始日期和结束日期为同一天表示获取这一天的所有数据
图中的 请求URL 就是我们要获取的东西,但不是直接复制过来就可以用。
需要将 units=e后面的东西去掉,也就是去掉 start_date 和 end_date 这两个请求参数
然后将得到的url复制到 wundergroundSpider.py 文件的 req_url 中。
我的代码中已经有了对应的url,替换掉即可:
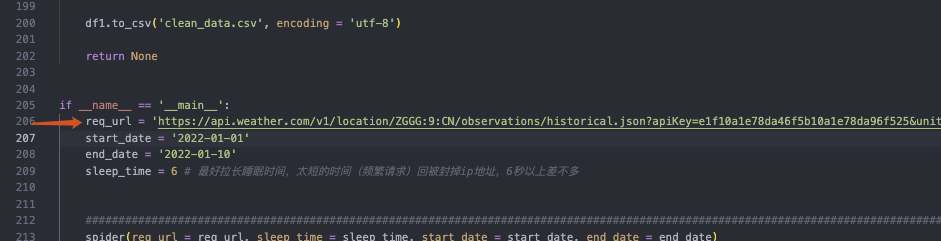
上图中的 start_date 和 end_date 则是我们要爬取的时间范围。
sleep_time则是每次爬取之间的间隔时间,是为了防止爬取过于频繁而被封ip地址。
wundergroundSpider.py:cleanData模块用与清洗数据
data.csv:wunderground爬虫数据
error.txt:因网络问题没有成功获取的数据
append_data.csv:对data数据的补充,因网络问题部分地区没有爬到
clean_data.csv:使用cleanData模块清洗后的数据,包括:
- 温度,华氏度转为摄氏度
- 时间,从GMT (格林尼治) 转为东八区时间
被注释掉的代码实现以下功能:
- 对数值变量计算日均、日最大、日最小
- 对类型变量按日计算众数
- 根据紫外线强度计算当日日照时长