A tool for evaluating RAG pipelines
![]()
The RAGulate currently reports 4 relevancy metrics: Answer Correctness, Answer Relevance, Context Relevance, and Groundedness.
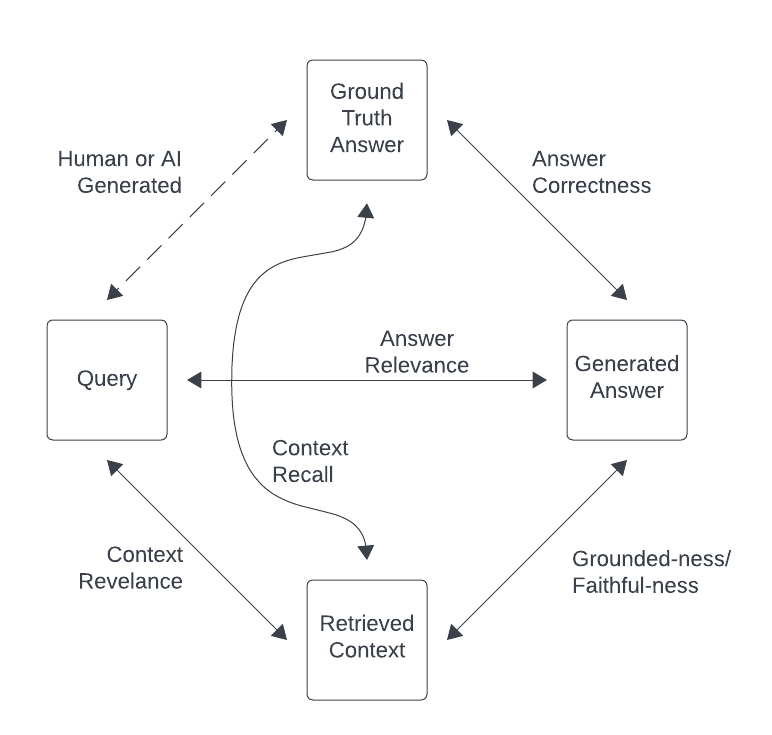
- Answer Correctness
- How well does the generated answer match the ground-truth answer?
- This confirms how well the full system performed.
- Answer Relevance
- Is the generated answer relevant to the query?
- This shows if the LLM is responding in a way that is helpful to answer the query.
- Context Relevance:
- Does the retrieved context contain information to answer the query?
- This shows how well the retrieval part of the process is performing.
- Groundedness:
- Is the generated response supported by the context?
- Low scores here indicate that the LLM is hallucinating.
The tool outputs results as images like this:
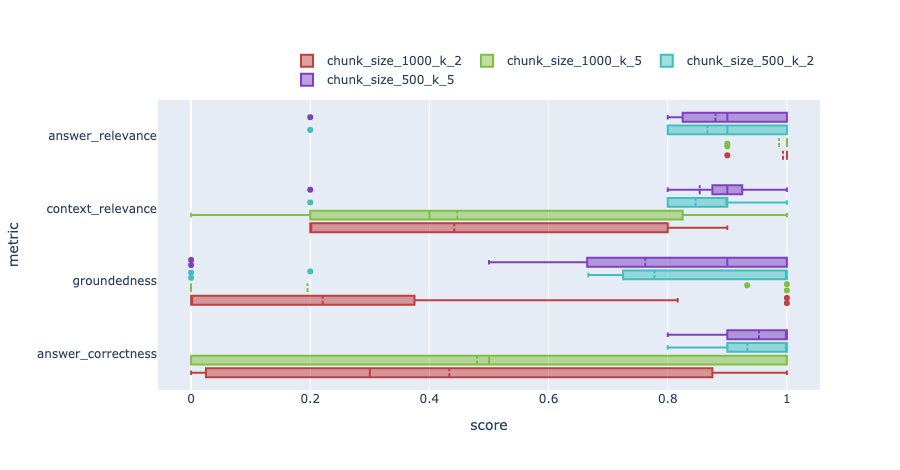
These images show distribution box plots of the metrics for different test runs.
pip install ragulate-
Set your environment variables or create a
.envfile. You will need to setOPENAI_API_KEYand any other environment variables needed by your ingest and query pipelines. -
Wrap your ingest pipeline in a single python method. The method should take a
file_pathparameter and any other variables that you will pass during your experimentation. The method should ingest the passed file into your vector store.See the
ingest()method in open_ai_chunk_size_and_k.py as an example. This method configures an ingest pipeline using the parameterchunk_sizeand ingests the file passed. -
Wrap your query pipeline in a single python method, and return it. The method should have parameters for any variables that you will pass during your experimentation. Currently only LangChain LCEL query pipelines are supported.
See the
query()method in open_ai_chunk_size_and_k.py as an example. This method returns a LangChain LCEL pipeline configured by the parameterschunk_sizeandk.
Note: It is helpful to have a **kwargs param in your pipeline method definitions, so that if extra params
are passed, they can be safely ignored.
usage: ragulate [-h] {download,ingest,query,compare} ...
RAGu-late CLI tool.
options:
-h, --help show this help message and exit
commands:
download Download a dataset
ingest Run an ingest pipeline
query Run an query pipeline
compare Compare results from 2 (or more) recipes
run Run an experiment from a config fileFor the examples below, we will use the example experiment open_ai_chunk_size_and_k.py
and see how the RAG metrics change for changes in chunk_size and k (number of documents retrieved).
There are two ways to run Ragulate to run an experiment. Either define an experiment with a config file or execute it manually step by step.
Note: Running via config file is a new feature and it is not as stable as running manually.
-
Create a yaml config file with a similar format to the example config: example_config.yaml. This defines the same test as shown manually below.
-
Execute it with a single command:
ragulate run example_config.yamlThis will:
- Download the test datasets
- Run the ingest pipelines
- Run the query pipelines
- Output an analysis of the results.
- Download a dataset. See available datasets here: https://llamahub.ai/?tab=llama_datasets
-
If you are unsure where to start, recommended datasets are:
BraintrustCodaHelpDeskBlockchainSolana
Examples:
ragulate download -k llama BraintrustCodaHelpDeskragulate download -k llama BlockchainSolana
-
Ingest the datasets using different methods:
Examples:
- Ingest with
chunk_size=200:ragulate ingest -n chunk_size_200 -s open_ai_chunk_size_and_k.py -m ingest \ --var-name chunk_size --var-value 200 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana - Ingest with
chunk_size=100:ragulate ingest -n chunk_size_100 -s open_ai_chunk_size_and_k.py -m ingest \ --var-name chunk_size --var-value 100 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana
- Ingest with
-
Run query and evaluations on the datasets using methods:
Examples:
-
Query with
chunk_size=200andk=2ragulate query -n chunk_size_200_k_2 -s open_ai_chunk_size_and_k.py -m query_pipeline \ --var-name chunk_size --var-value 200 --var-name k --var-value 2 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana -
Query with
chunk_size=100andk=2ragulate query -n chunk_size_100_k_2 -s open_ai_chunk_size_and_k.py -m query_pipeline \ --var-name chunk_size --var-value 100 --var-name k --var-value 2 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana -
Query with
chunk_size=200andk=5ragulate query -n chunk_size_200_k_5 -s open_ai_chunk_size_and_k.py -m query_pipeline \ --var-name chunk_size --var-value 200 --var-name k --var-value 5 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana -
Query with
chunk_size=100andk=5ragulate query -n chunk_size_100_k_5 -s open_ai_chunk_size_and_k.py -m query_pipeline \ --var-name chunk_size --var-value 100 --var-name k --var-value 5 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana
-
-
Run a compare to get the results:
Example:
ragulate compare -r chunk_size_100_k_2 -r chunk_size_200_k_2 -r chunk_size_100_k_5 -r chunk_size_200_k_5This will output 2 png files. one for each dataset.
- The evaluation model is locked to OpenAI gpt3.5
- Only LangChain query pipelines are supported
- Only LlamaIndex datasets are supported
- There is no way to specify which metrics to evaluate.