
by Emery Berger, Sam Stern, and Juan Altmayer Pizzorno.





(tweet from Ian Ozsvald, author of High Performance Python)
Scalene is a high-performance CPU, GPU and memory profiler for Python that does a number of things that other Python profilers do not and cannot do. It runs orders of magnitude faster than other profilers while delivering far more detailed information.
pip install -U scaleneScalene has a new web-based GUI (demo here).
Once Scalene has profiled your program, it will launch a web browser with an interactive user interface (all processing is done locally). Hover over bars to see breakdowns of CPU and memory consumption, and click on underlined column headers to sort the columns.
Commonly used options:
scalene your_prog.py # full profile (outputs to web interface)
python3 -m scalene your_prog.py # equivalent alternative
scalene --cli your_prog.py # use the command-line only (no web interface)
scalene --cpu-only your_prog.py # only CPU/GPU
scalene --reduced-profile your_prog.py # only profile lines with significant usage
scalene --profile-interval 5.0 your_prog.py. # output a new profile every five seconds
scalene --help # lists all optionsTo use Scalene programmatically in your code, invoke using scalene as above and then:
from scalene import scalene_profiler
# Turn profiling on
scalene_profiler.start()
# Turn profiling off
scalene_profiler.stop()To use Scalene to profile specific functions, just use the @profile decorator and run it with Scalene:
@profile
def slow_function():
import time
time.sleep(3)This talk presented at PyCon 2021 walks through Scalene's advantages and how to use it to debug the performance of an application (and provides some technical details on its internals). We highly recommend watching this video!
- Scalene is fast. It uses sampling instead of instrumentation or relying on Python's tracing facilities. Its overhead is typically no more than 10-20% (and often less).
- Scalene performs profiling at the line level and per function, pointing to the functions and the specific lines of code responsible for the execution time in your program.
- Scalene separates out time spent in Python from time in native code (including libraries). Most Python programmers aren't going to optimize the performance of native code (which is usually either in the Python implementation or external libraries), so this helps developers focus their optimization efforts on the code they can actually improve.
- Scalene highlights hotspots (code accounting for significant percentages of CPU time or memory allocation) in red, making them even easier to spot.
- Scalene also separates out system time, making it easy to find I/O bottlenecks.
- Scalene reports GPU time (currently limited to NVIDIA-based systems).
- Scalene profiles memory usage. In addition to tracking CPU usage, Scalene also points to the specific lines of code responsible for memory growth. It accomplishes this via an included specialized memory allocator.
- Scalene separates out the percentage of memory consumed by Python code vs. native code.
- Scalene produces per-line memory profiles.
- Scalene identifies lines with likely memory leaks.
- Scalene profiles copying volume, making it easy to spot inadvertent copying, especially due to crossing Python/library boundaries (e.g., accidentally converting
numpyarrays into Python arrays, and vice versa).
- Scalene can produce reduced profiles (via
--reduced-profile) that only report lines that consume more than 1% of CPU or perform at least 100 allocations. - Scalene supports
@profiledecorators to profile only specific functions. - When Scalene is profiling a program launched in the background (via
&), you can suspend and resume profiling.
Below is a table comparing the performance and features of various profilers to Scalene.
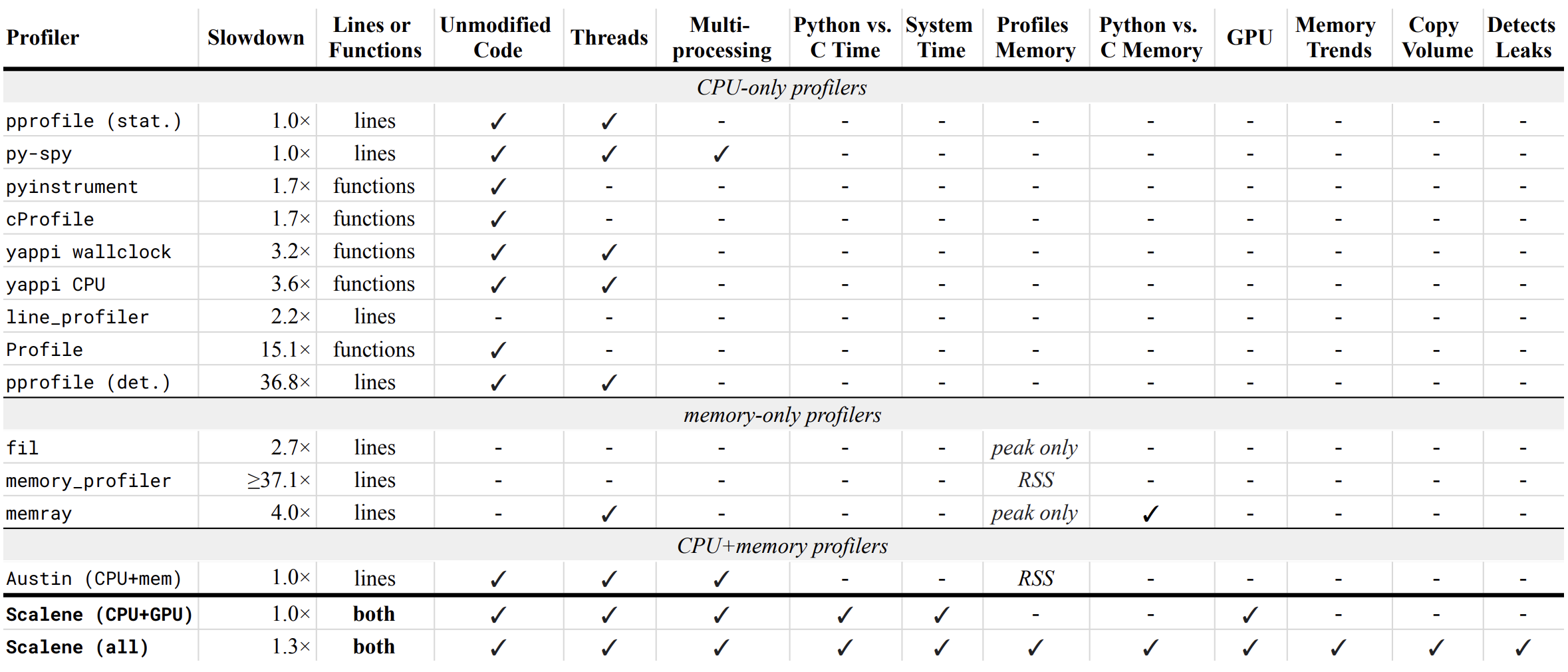
- Slowdown: the slowdown when running a benchmark from the Pyperformance suite. Green means less than 2x overhead. Scalene's overhead is just a 20% slowdown.
Scalene has all of the following features, many of which only Scalene supports:
- Lines or functions: does the profiler report information only for entire functions, or for every line -- Scalene does both.
- Unmodified Code: works on unmodified code.
- Threads: supports Python threads.
- Multiprocessing: supports use of the
multiprocessinglibrary -- Scalene only - Python vs. C time: breaks out time spent in Python vs. native code (e.g., libraries) -- Scalene only
- System time: breaks out system time (e.g., sleeping or performing I/O) -- Scalene only
- Profiles memory: reports memory consumption per line / function
- GPU: reports time spent on an NVIDIA GPU (if present) -- Scalene only
- Memory trends: reports memory use over time per line / function -- Scalene only
- Copy volume: reports megabytes being copied per second -- Scalene only
- Detects leaks: automatically pinpoints lines responsible for likely memory leaks -- Scalene only
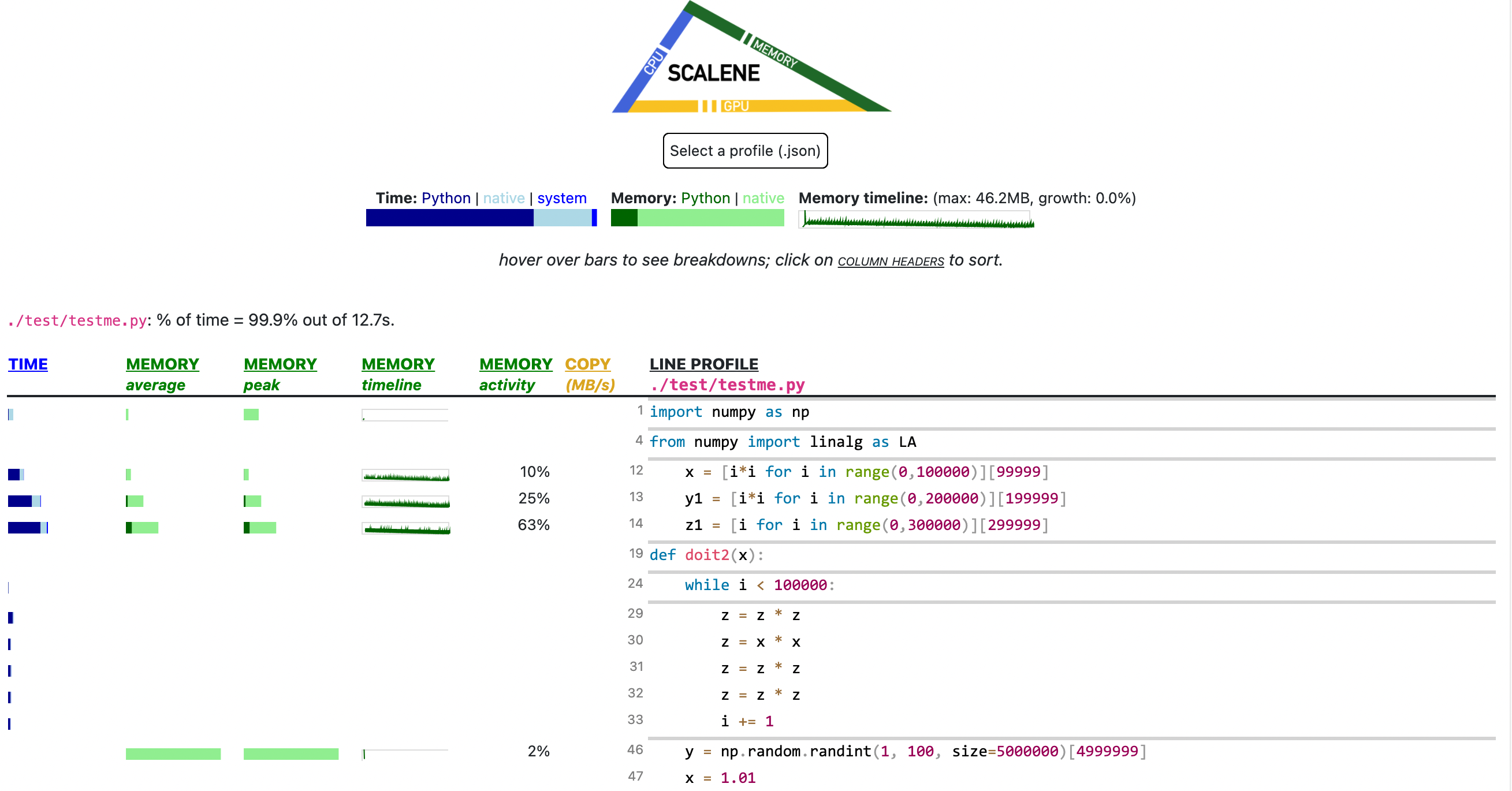
If you include the --cli option, Scalene prints annotated source code for the program being profiled
(as text, JSON (--json), or HTML (--html)) and any modules it
uses in the same directory or subdirectories (you can optionally have
it --profile-all and only include files with at least a
--cpu-percent-threshold of time). Here is a snippet from
pystone.py.
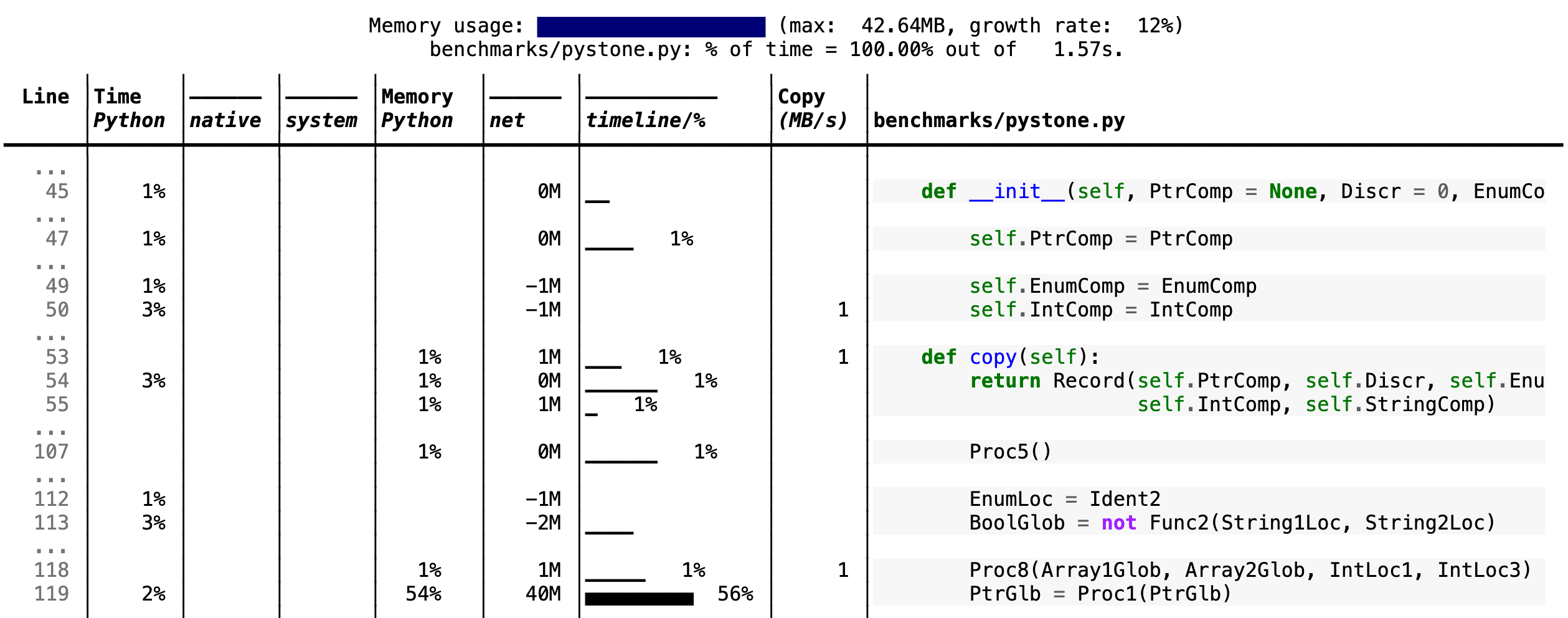
- Memory usage at the top: Visualized by "sparklines", memory consumption over the runtime of the profiled code.
- "Time Python": How much time was spent in Python code.
- "native": How much time was spent in non-Python code (e.g., libraries written in C/C++).
- "system": How much time was spent in the system (e.g., I/O).
- "GPU": (not shown here) How much time spent on the GPU, if your system has an NVIDIA GPU installed.
- "Memory Python": How much of the memory allocation happened on the Python side of the code, as opposed to in non-Python code (e.g., libraries written in C/C++).
- "net": Positive net memory numbers indicate total memory allocation in megabytes; negative net memory numbers indicate memory reclamation.
- "timeline / %": Visualized by "sparklines", memory consumption generated by this line over the program runtime, and the percentages of total memory activity this line represents.
- "Copy (MB/s)": The amount of megabytes being copied per second (see "About Scalene").
The following command runs Scalene on a provided example program.
scalene test/testme.py
Click to see all Scalene's options (available by running with --help)
% scalene --help
usage: scalene [-h] [--outfile OUTFILE] [--html] [--reduced-profile]
[--profile-interval PROFILE_INTERVAL] [--cpu-only]
[--profile-all] [--profile-only PROFILE_ONLY]
[--use-virtual-time]
[--cpu-percent-threshold CPU_PERCENT_THRESHOLD]
[--cpu-sampling-rate CPU_SAMPLING_RATE]
[--malloc-threshold MALLOC_THRESHOLD]
Scalene: a high-precision CPU and memory profiler.
https://github.com/plasma-umass/scalene
command-line:
% scalene [options] yourprogram.py
or
% python3 -m scalene [options] yourprogram.py
in Jupyter, line mode:
%scrun [options] statement
in Jupyter, cell mode:
%%scalene [options]
code...
code...
optional arguments:
-h, --help show this help message and exit
--outfile OUTFILE file to hold profiler output (default: stdout)
--html output as HTML (default: text)
--reduced-profile generate a reduced profile, with non-zero lines only (default: False)
--profile-interval PROFILE_INTERVAL
output profiles every so many seconds (default: inf)
--cpu-only only profile CPU time (default: profile CPU, memory, and copying)
--profile-all profile all executed code, not just the target program (default: only the target program)
--profile-only PROFILE_ONLY
profile only code in filenames that contain the given strings, separated by commas (default: no restrictions)
--use-virtual-time measure only CPU time, not time spent in I/O or blocking (default: False)
--cpu-percent-threshold CPU_PERCENT_THRESHOLD
only report profiles with at least this percent of CPU time (default: 1%)
--cpu-sampling-rate CPU_SAMPLING_RATE
CPU sampling rate (default: every 0.01s)
--malloc-threshold MALLOC_THRESHOLD
only report profiles with at least this many allocations (default: 100)
When running Scalene in the background, you can suspend/resume profiling
for the process ID that Scalene reports. For example:
% python3 -m scalene [options] yourprogram.py &
Scalene now profiling process 12345
to suspend profiling: python3 -m scalene.profile --off --pid 12345
to resume profiling: python3 -m scalene.profile --on --pid 12345Instructions for installing and using Scalene with Jupyter notebooks
This notebook illustrates the use of Scalene in Jupyter.
Installation:
!pip install scalene
%load_ext scaleneLine mode:
%scrun [options] statementCell mode:
%%scalene [options]
code...
code...Using pip (Mac OS X, Linux, Windows, and WSL2)
Scalene is distributed as a pip package and works on Mac OS X, Linux (including Ubuntu in Windows WSL2) and (with limitations) Windows platforms. (Note: the Windows version isn't yet complete; it requires Python 3.8 or later and currently only supports CPU profiling.)
You can install it as follows:
% pip install -U scaleneor
% python3 -m pip install -U scaleneYou may need to install some packages first.
See https://stackoverflow.com/a/19344978/4954434 for full instructions for all Linux flavors.
For Ubuntu/Debian:
% sudo apt install git python3-all-devUsing Homebrew (Mac OS X)
As an alternative to pip, you can use Homebrew to install the current version of Scalene from this repository:
% brew tap plasma-umass/scalene
% brew install --head plasma-umass/scalene/scaleneOn ArchLinux
You can install Scalene on Arch Linux via the AUR
package. Use your favorite AUR helper, or
manually download the PKGBUILD and run makepkg -cirs to build. Note that this will place
libscalene.so in /usr/lib; modify the below usage instructions accordingly.
Q: Is there any way to get shorter profiles or do more targeted profiling?
A: Yes! There are several options:
- Use
--reduced-profileto include only lines and files with memory/CPU/GPU activity. - Use
--profile-onlyto include only filenames containing specific strings (as in,--profile-only foo,bar,baz). - Decorate functions of interest with
@profileto have Scalene report only those functions. - Turn profiling on and off programmatically by importing Scalene (
import scalene) and then turning profiling on and off viascalene_profiler.start()andscalene_profiler.stop(). By default, Scalene runs with profiling on, so to delay profiling until desired, use the--offcommand-line option (python3 -m scalene --off yourprogram.py).
Q: How do I run Scalene in PyCharm?
A: In PyCharm, you can run Scalene at the command line by opening the terminal at the bottom of the IDE and running a Scalene command (e.g., python -m scalene <your program>). Use the options --cli, --html, and --outfile <your output.html> to generate an HTML file that you can then view in the IDE.
Q: How do I use Scalene with Django?
A: Pass in the --noreload option (see plasma-umass#178).
Q: How do I use Scalene with PyTorch on the Mac?
A: Scalene works with PyTorch version 1.5.1 on Mac OS X. There's a bug in newer versions of PyTorch (pytorch/pytorch#57185) that interferes with Scalene (discussion here: plasma-umass#110), but only on Macs.
For technical details on Scalene, please see the following paper: Scalene: Scripting-Language Aware Profiling for Python (arXiv link).
If you use Scalene to successfully debug a performance problem, please add a comment to this issue!
Logo created by Sophia Berger.
This material is based upon work supported by the National Science Foundation under Grant No. 1955610. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.