Scenario Specification
Two files are needed to describe an optimization scenario. A templated Cyclus input file and a scenario configuration file. The significance and details of each of these are described in the following sections.
This is a normal Cyclus input file (i.e. in xml format) with all the prototypes, recipes/compositions, etc. that are to be a part of the fuel cycle scenario being modeled. The main difference is that, instead of normal deployments or initial facilities being specified, a special placeholder is used. This allows the optimizer to fill in arbitrary combinations of deployments that it chooses as part of the optimization processes. To accomplish this, the optimizer is designed to use the :cycamore:DeployInst archetype.
A special DeployInst prototype is created for the optimizer, and one
instance of this facility is specified in the initially deployed facilities.
This can work with either the normal or flat Cyclus input file formats. For
the normal input file format, it looks like this:
...
...
<region>
<name>SingleRegion</name>
<config><NullRegion/></config>
<institution>
<name>optim_deployer</name>
<initialfacilitylist></initialfacilitylist>
<config>
<DeployInst>
<prototypes>{{range .Builds}}
<val>{{.Proto}}</val>{{end}}
</prototypes>
<build_times>{{range .Builds}}
<val>{{.Time}}</val>{{end}}
</build_times>
<n_build>{{range .Builds}}
<val>{{.N}}</val>{{end}}
</n_build>
<lifetimes>{{range .Builds}}
<val>{{.Lifetime}}</val>{{end}}
</lifetimes>
</DeployInst>
</config>
</institution>
</region>
...
...For the flat input file format it looks like this:
...
...
<prototype>
<name>optim_deployer</name>
<config>
<DeployInst>
<prototypes>{{range .Builds}}
<val>{{.Proto}}</val>{{end}}
</prototypes>
<build_times>{{range .Builds}}
<val>{{.Time}}</val>{{end}}
</build_times>
<n_build>{{range .Builds}}
<val>{{.N}}</val>{{end}}
</n_build>
<lifetimes>{{range .Builds}}
<val>{{.Lifetime}}</val>{{end}}
</lifetimes>
</DeployInst>
</config>
</prototype>
...
...
...
<agent> <name>deployer1</name> <prototype>optim_deployer</prototype> </agent>
...
...A full sample templated input file (using the flat schema) can be found here.
If other initial-condition or static/single build agents/facilities need to be
a part of the scenario, they should be specified in the scenario configuration
file rather than in the input file. The optimizer's special DeployInst
should be the only agent deployed in the input file. The optimizer's
DeployInst prototype and instance don't need to have any particular or
special names - their names are arbitrary.
You can also optionally put a "handle" placeholder in allowing each input file to be marked with the Handle field as specified in scenario configuration file(s):
<simulation>
<schematype>flat</schematype>
<control>
<simhandle>{{.Handle}}</simhandle>
<duration>2400</duration>
<startmonth>1</startmonth>
...
...This file is a JSON format human readable text file. All fields and their
usage are defined in below. A few sub-sections discussing details about
objective functions, optimization modes, and splicing are also provided. This
file can be named anything although some commands have a (changeable) default
assuming it is named scenario.json. A sample scenario configuration file
is provided here:
https://github.com/rwcarlsen/cloudlus/blob/master/example/optim/scenario.json.
Note that the C-style comments are not part of the file format itself (nor ar
they valid JSON) and are used only for documentation purposes here. Data
types in <type> form are placeholders for fundamental data types (e.g.
int, string, etc.). <int> should be replaced with e.g. 42,
<string> should be replaced with e.g. "42", etc. And don't forget to
be careful about (not) using commas appropriately for JSON.
{
// Handle (default: "none") can be set/used as a scenario label in the templated
// input file in i.e. the '<simhandle>' tag in the simulation control param
// section.
"Handle": <string>,
// SimDur is the simulation duration in time steps (e.g. months)
"SimDur": <int>,
// BuildOffset (default: 0) is the number of time steps after simulation
// start at which deployments actually begin. This allows facilities and
// other initial conditions to be set up and run before the deploying
// begins by the optimizer.
"BuildOffset": <int>,
// TrailingDur (default: 0) is the number of time steps of the simulation
// duration that are reserved for wind-down - i.e. no deployments will be
// made by the optimizer.
"TrailingDur": <int>,
// CyclusTmpl is the relative path from the scenario configuration file
// (i.e. this file) to the templated Cyclus input file.
"CyclusTmpl": <string>,
// BuildPeriod is the number of time steps between times at which new
// facilities are deployed (e.g. by the optimizer). For monthly time
// steps, a build period of 12 would indicate new deployments occur once
// per year.
"BuildPeriod": <int>,
// MinPower is a series of min deployed power capacity requirements that
// must be maintained for each build period. This must have at least as
// many entries as the SimDur divided by BuildPeriod.
"MinPower": [<float>, <float>, ...],
// MaxPower is a series of max deployed power capacity requirements that
// must be maintained for each build period. This must have at least as
// many entries as the SimDur divided by BuildPeriod.
"MaxPower": [<float>, <float>, ...],
// Facs is a list of all prototypes specified in the scenario (i.e. the
// Cyclus templated input file) with associated parameters relevant to the
// optimization.
"Facs": [
{
// Proto names a prototype from the input file.
"Proto": <string>,
// BuildAfter (default: 0) is the time step after which this
// facility type can be built. Use -1 for never available, and 0
// for always available.
"BuildAfter": <int>,
// Cap (default: 0) is the net/effective generation capacity of
// the facility which must include any non-unity capacity factor.
// Although this can represent power (in which case it must be
// consistent with power capacities in the Cyclus input file), it
// can be used to represent any arbitrary/general capacity.
"Cap": <float>,
// Life (default: infinite) is the lifetime prototype (in time
// steps). This value must be the same as the lifetime specified
// in the Cyclus input file.
"Life": <int>,
// FracOfProto (default: []) names a prototype that build
// fractions of this prototype are a portion of. This allows
// constraining build numbers of this prototype during the
// optimization process to be less than (i.e. some fraction of)
// the total number deployed of the prototypes listed here.
FracOfProtos [<string>, <string>, ...]
},
...
],
// StartBuilds holds the set of deployments for all agents
// initially or statically deployed in the scenario (i.e. not
// added/deployed by optimizer). All deployments that need to be made
// (not by the optimizer) should be listed here.
"StartBuilds": [
{
// Time is the time step on which to build the agent
"Time": <int>,
// Proto names the prototype to build
"Proto": <string>,
// N specifies the number of agents to build
"N": <int>,
// Life (default: prototype's) allows the prototype's
// input-file-specified lifetime to be optionally overridden.
"Life": <int>
},
...
],
// ObjFunc (default: "slowvfast") is the name of the objective function to
// be used for objective value calculations. This must be chosen from the
// list of supported objective functions described in the Objective
// Functions section below.
"ObjFunc": <string>,
// ObjMode (default: "single") identifies the way the overall objective
// value is computed for this scenario. It must be chosen from the list
// of supported modes (described below) The default (empty string) is to
// just run a single simulation and use the returned value of the chosen
// ObjFunc as the objective value. Other modes allow things like a
// scenario involving many sub-simulations whose objectives are combined
// to a single value. See the Modes section below for more details
"ObjMode": <string>,
// CustomConfig is to provide extra necessary details specific to
// particular optimization modes (i.e. ObjMode) such as disruption
// scenarios where each run or objective evaluation might consist of
// multiple simulations.
"CustomConfig": <see Modes section below>,
// SpliceVars (default: []) holds an optional complete set of variable
// values that can be spliced with the actual individual optimizer
// evaluation variable values. Times before the splice time use the
// SpliceVars values, and times after the splice time use the actual
// variable values passed chosen externally (e.g. by the optimizer). See
// the Splicing section below for more details.
"SpliceVars": [<float>, <float>, ...],
// SpliceTime (default: 0) is the time before which SpliceVars (if
// defined) are used instead of the actual passed variables for
// TransformVars. See the Splicing section below for more details.
"SpliceTime": <int>,
// Discount (default: 0) represents the nominal annual discount rate
// (including inflation) for the simulation. This is just information
// that can optionally be used by some objective functions.
"Discount": <float>,
// NuclideCost (default: {}) represents the waste cost per kg material per
// time step for each nuclide in the entire simulation (repository's
// exempt). This is just information that can optionally be used by some
// objective functions.
"NuclideCost": {
// nuclide-cost key-value pairs
"<string>": <float>,
...
}
}If the scenario objective ObjFunc is left blank, the default objective is used. Available objective functions are:
-
slowvfast: (the default)
This objective function computes the ratio of total energy produced over the entire simulation by all thermal reactors divided by total energy produced over the entire simulation by all reactors (including thermal reactors) - i.e.:
(thermal reactor energy) / (total energy)
'slow_reactor' and 'fast_reactor' must be the names of the thermal and fast reactor prototypes respectively (i.e. in the Cyclus input and scenario configuration files). It is assumed that there are no other reactor prototypes deployed in the simulation. This objective uses values from the TimeSeriesPower table, and so the reactor archetype(s) used must record into that table (e.g. the
:cycamore:Reactor). -
slowvfast-penalty:
This objective function is the same as "slowvfast" except it has an extra penalty factor added for unfueled reactors (i.e. sub-optimal capacity factors). Its equation is:
(thermal reactor energy) / (total energy) * (total installed MWe years) / (tot energy produced)
The same prototype nameing and archetype constraints from the "slowvfast" objective apply here.
-
slowvfast-penalty2:
This objective function is the same as "slowvfast-penalty" except the unfueled reactor penalty is squared:
(thermal reactor energy) / (total energy) * [(total installed MWe years) / (tot energy produced)]^2
The same prototype nameing and archetype constraints from the "slowvfast" objective apply here.
-
slowvfast-fueled: ObjSlowVsFastPowerFueled,
This objective function is similar to the other "slowvfast..." objectives:
[(thermal reactor energy) + (total reactor capacity)] / (total energy)The same prototype nameing and archetype constraints from the "slowvfast" objective apply here. This objective has the additional constraint in that it assumes 'slow_reactor' and 'fast_reactor' are the only two power-producing prototypes in the scenario.
-
ans2014: ObjANS2014,
This objective function is:
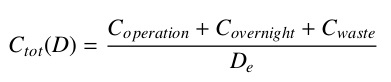
Where the sub-components are defined as:

The NuclideCost and Discount configuration parameters are required. Also the prototypes listed in the Facs configuration parameter must have additional fields defined (i.e. in addition to Proto, BuildAfter, Cap, etc.):
... { ... // OpCost represents the per time step operating cost for the facility "OpCost": <float>, // CapitalCost represents the over-night cost for building the facility "CapitalCost": <float>, // WasteDiscount represents the fractional discount from the waste cost // for this facility. "WasteDiscount": <float> }, ...
You can write/add your own custom objective functions too. This process is described here.
The optimization mode (i.e. ObjMode) represents an abstraction layer above calculating the actual objective function itself. Modes are primarily a mechanism for enabling objectives to be calculated from results of more than just a single simulation. For example, a mode might take a scenario, run two slightly different simulations based on scenario details and use both along with the objective function to calculate the objective.
Several of the build-in modes use the disruption specification defined here in their CustomConfig field.
{
// Time is the time step on which the disruption occurs (i.e. facility
// shutdown, facility construction, or objective change).
"Time": <int>,
// KillProto (default: <none>) is the prototype for which all
// facilities will be shut down on the given disruption time.
"KillProto": <string>,
// BuildProto (default: <none>) is the prototype for which to build
// a single new instance at the given disruption time.
"BuildProto": <string>,
// SwitchObjFunc (default: <no objective switch>) specifies a
// disruption where the objective function changes to the objective
// named here (from those described in the Objective Functions
// section). This can be used together with the KillProto and
// BuildProto components of the disruption, but has not been tested
// together with them.
"SwitchObjFunc": <string>,
// Prob (default: 0) holds the probability that the disruption will
// happen at a particular time. This is ignored in disrup-single
// mode. Note that the integral of linear interpolation between
// probabilities over the entire simulation duration must be less
// than or equal to 1; it must be equal to the probability that the
// disruption happens over the entire
// simulation. So for four samples and a 2400 time step simulation,
// each disruption should NOT have a 0.25 probability - they should
// have 1/2400 probability.
"Prob": <float>,
// Sample is true if this disruption time should be sampled for
// generation of the Obj vs Disrup approximation. KnownBests should
// generally be placed on Sample=true disruption points only.
"Sample": <bool>,
// KnownBest holds the objective value for the best known deployment
// schedule for the scenario for with a priori knowledge of this
// particular disruption always occuring. This is only used in
// disrup-multi-lin mode. Linear interpolation is performed between
// the KnownBests of disruption points with Sample=true.
"KnownBest": <float>
}This specification will be referred to as <disruption-spec>.
If the ObjMode is left blank, the default optimization mode is used. Optimization modes available for selection are:
-
single: (the default) Used for calculating a single-simulation, simple objective function for a scenario.
-
disrup-single: Used to compute a single-simulation objective function for the scenario but also inserting a disruption at the specified time. The disruption must be specified using the scenario's CustomConfig field:
... "CustomConfig": <disruption-spec>, ...The disruption Prob field is ignored.
-
disrup-single-lin: Is the same as
disrup-singleexcept objective is computed by using a linear combination of the normal calculated objective with the disruption-time-specific optimized objective value set via the 's KnownBest field. Weights are proportional to the fraction the simulation that was pre/post disruption. This uses the same CustomConfig as thedisrup-singlemode. -
disrup-multi: Used to compute a multi-simulation weighted average objective function for the scenario with a disruption (i.e. runs several single mode sub-scenario objective calculations. The sub-scenario simulations differ in their disruption time only. The scenario's CustomConfig field must be set like this:
... "CustomConfig": [ <disruption-spec>, <disruption-spec>, ... ], ...with one entry for each disruption time. Remember that integration over linear interpolation between the probabilities must sum up to 1.0. You can have fine-grained control over the disruption probability distribution by having many disruption entries but only marking
Sample=truefor the ones you want to sample via running simulations during optimization -
disrup-multi-lin: Is the same as
disrup-multiexcept sub objectives are computed by using a linear combination of the normal calculated sub objective with the disruption-time-specific optimized objective value. Weights are proportional to the fraction the simulation that was pre/post disruption. This uses the same CustomConfig as thedisrup-multimode, except KnownBest values must be set for each disruption that hasSample=true.
You can write/add your own custom objective/optimization modes too. This process is described here.
Splicing is useful if you want to fix a leading portion of the deployment schedule and only let the optimizer explore the tail portion of possible deployments. Note that splicing is specified in terms of optimizer variables, not in terms of the actual deployments themselves. Deployments after SpliceTime specified in SpliceVars are ignored. Deployments before SpliceTime chosen by the optimizer are ignored.
The primary (historical) usage of splicing has been to evaluate deployment
schedules as hedging strategies. Place the variable values corresponding to a
particular candidate hedging strategy into SpliceVars. Then several
single-disrup mode optimization runs can be done with varying
SpliceTime's. The end result is a set of best achievable objective values for
different disruption times using the initial hedging strategy pre-disruption
and diverging from it with optimal deployments post-disruption.