WhyDragonCN
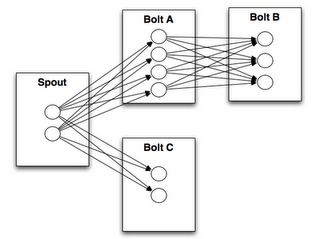
Storm是由Backtype公司开发的实时计算框架, 后面随着Backtype公司被Twitter收购,在Twitter得到大量应用和推广. 它的核心代码全部采用clojure语言编写,被收购后要在Twitter的其它业务线使用,所以加上了Java接口. 总体来说, Storm的架构是依照Hadoop的. 用户可以定义一道作业的数据流向拓扑结构, 然后向集群的Master服务器提交, 由Master将作业分解成小的Task, 每台机器运行一定量的Task数. 数据流向拓扑结构是一个DAG的结构, 其中数据源头叫做Spout, Spout取得数据后会给下游的Bolt处理.同一道Job的Spout和Bolt都会分布在集群的不同机器上运行,它们之间通过ZeroMQ传递数据. 如下图所示:
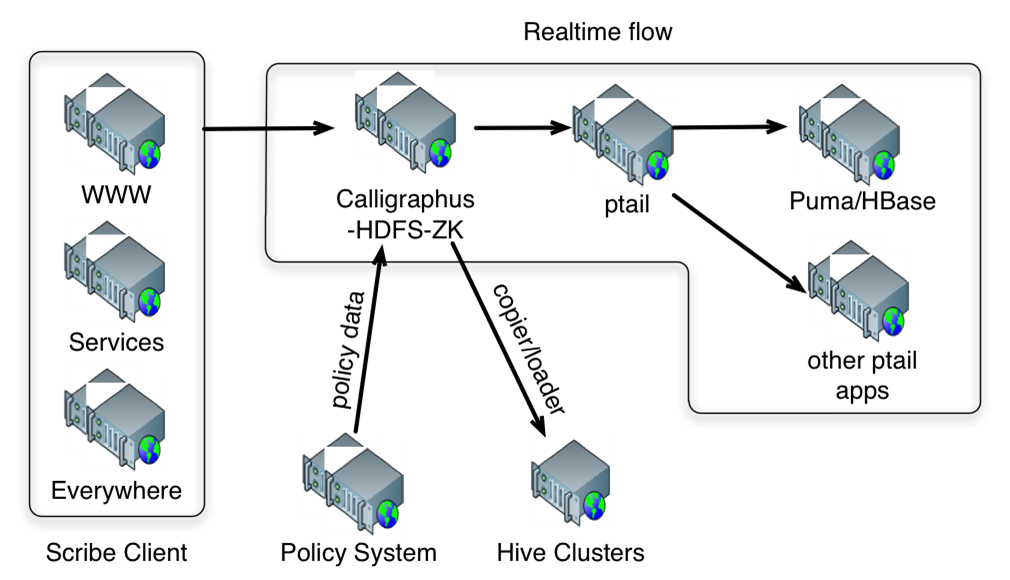
Puma是Facebook为了解决Hive用于实时数据分析的不足而开发的计算框架. 一个Puma部署能够每秒处理15GB数据, TPS为600,000条/秒, 最高延迟为10秒以下, 容忍0.01%的数据丢失(2011年6月数据). 目前Puma支持流的过滤, 分组统计操作, 流与HBase表的Join操作; 不支持流与流的Join操作. FaceBook的实时计算处理流程如下: Web服务器日志等数据由Scribe收集到HDFS集群上, 由Ptail(类似于linux tail命令)不停地轮询文件可件的结尾部分, 将这些数据交由Puma处理.
编写一道Storm作业和一道Hadoop MapReduce作业一样方便, 用户只需要定义Spout, Bolt和各处理节点的DAG结构, 就可以提交作业了. 用户无需关心,作业最终分配到集群的哪些节点之上, 也无需要关心子任务之前是如何通信的.
数据加工和分析经常会产生多道过程, 所以会产生大量的作业依赖. 上游的作业提供加工好的数据给下游作业作进一步地细化. 而Storm是一个纯粹的计算框架,没有提供存储方案,所以数据共享一般得依赖于外部的存储方案,例如消息中间件. 但如果不统一存储方案, 集群的各用户各自采用不同的中间件方案, Job之间的数据共享变得很困难.
即使所有用户都统一使用一种中间件方案, 多道作业经常会访问相同的数据(表)也会导致出现问题. 例如电子商务网站中用户数据, 交易数据和定单数据是三大类核心数据. 几乎所有的数据分析作业都需要访问这三类数据. Storm建议将这些数据放在中间件上共享, 但是每道作业都会向中间件拖大量数据, 更糟的是这些数据一般是按时间分区. 而实时计算往往集中取最近某一段时间的数据, 所以数据访问经常落在中间件的同一台broker服务器上. 这台服务器有可能被拖挂掉.即使不拖挂掉,它的磁盘吞吐量、网络带宽也会也为整道流式作业的瓶颈.
Storm采用两种机制保证消息的可靠转输和处理: ack机制和基于二阶段提交(2PC)的事务. Ack机制保证单条数据能够通过网络传递到下游节点并且处理完毕. 但是例如分组去重的操作, 消息传递到下游节点之后会放在内存中的HashMap里. 如果HashMap存储了一定数据后机器出现故障, 则前面已经处理完毕并且ack过的数据将全部丢失, ack机制对此无能为力. 以上就是Storm 0.7出现事务的原因. 事务能应付类似分组去重这种在内存里暂存数据的场景, 但是由于二阶段提交需要下游所有节点都确认可以提交,事务才能顺利提交. 只要其中的一个节点因为某些原因接收到数据后处理速度过慢, 将会导致整个事务的延迟. 并且下游处理节点越多, 整个事务被延迟的可能性越大, 这对于计算能力的线性扩展不利.
Storm没有用户的概念, 所以自然没有认证和权限管理的问题. 会造成以下问题:
- 只要能访问Storm Master节点的端口, 就能提交Storm作业. 一些恶意用户,可以随意地提交恶意作业.
- 用户可以随意地杀死另一个用户启动的作业,并且无证可查
- 用户可以提交一些非常大的作业,占用集群的大量资源
Storm是按slot的概念分配作业. 集群每台机器的slot数一般决定于CPU数, 比如slot数 = CPU数 * 2 之类的设置. 但是无法区分用户作业属于哪种类型, 用户提交的作业有一些是CPU密集型, 有一些是内存密集型,有一些是IO密集型.造成的后果是, 某些作业因为内存不够而失败; 某些作业因为集中在几台机器上做IO密集型操作, 导致这道作业延迟很高,但作业所在节点的CPU和内存都有可能比较空闲.
另外
Storm只能在本地调式作业, 但是本地开发机器很有可能连接不上中间件的数据源, 加之本地单机调试作业很难代表多机分布式作业的运行情况. 所以本地调式对于用户开发新作业作用不是很大. 如果将新开发的作业提交到Storm的分布式环境中运行, 那么用户将只能看到web界面上的一些运行数字(例如两节点之间10秒内传递了多少条数据), 不能查看到每个节点的worker运行日志. 从而一旦作业出现异常, 用户无从下手分析, 只能求助于集群管理员. 这样集群管理员的任务加重了. 当然, 实际部署中可以将所有节点的日志映射到一个NFS目录当中, 再启动一个Apache服务器, 让用户可以查看这些日志, 但是对于用户来说也不是很方便.
Puma由于采用ptail读取HDFS的数据, 所以只需要将当前处理数据在HDFS文件上的偏移量作为检查点. 就可以在故障发生后, seek到文件之前的偏量点重播即可. 它没有Storm对于分组统计支持不好的问题.
用户不能通过Puma自主地开发、提交作业, 它是一个静态的集群. 管理员负责将Puma从HDFS接入数据, 然后定义数据处理逻辑.
Dragon结合了Hadoop Yarn, Storm以及Puma三者的优势, 解决了以上问题.
Yarn是Hadoop MapReduce为了解决Master节点伸缩性、资源分配提出的一个资源管理框架.