{kind=link}
Caitlin Dreisbach (cnd2y)
Elizabeth Homan (eih2nn)
Morgan Wall (mkw5ck)
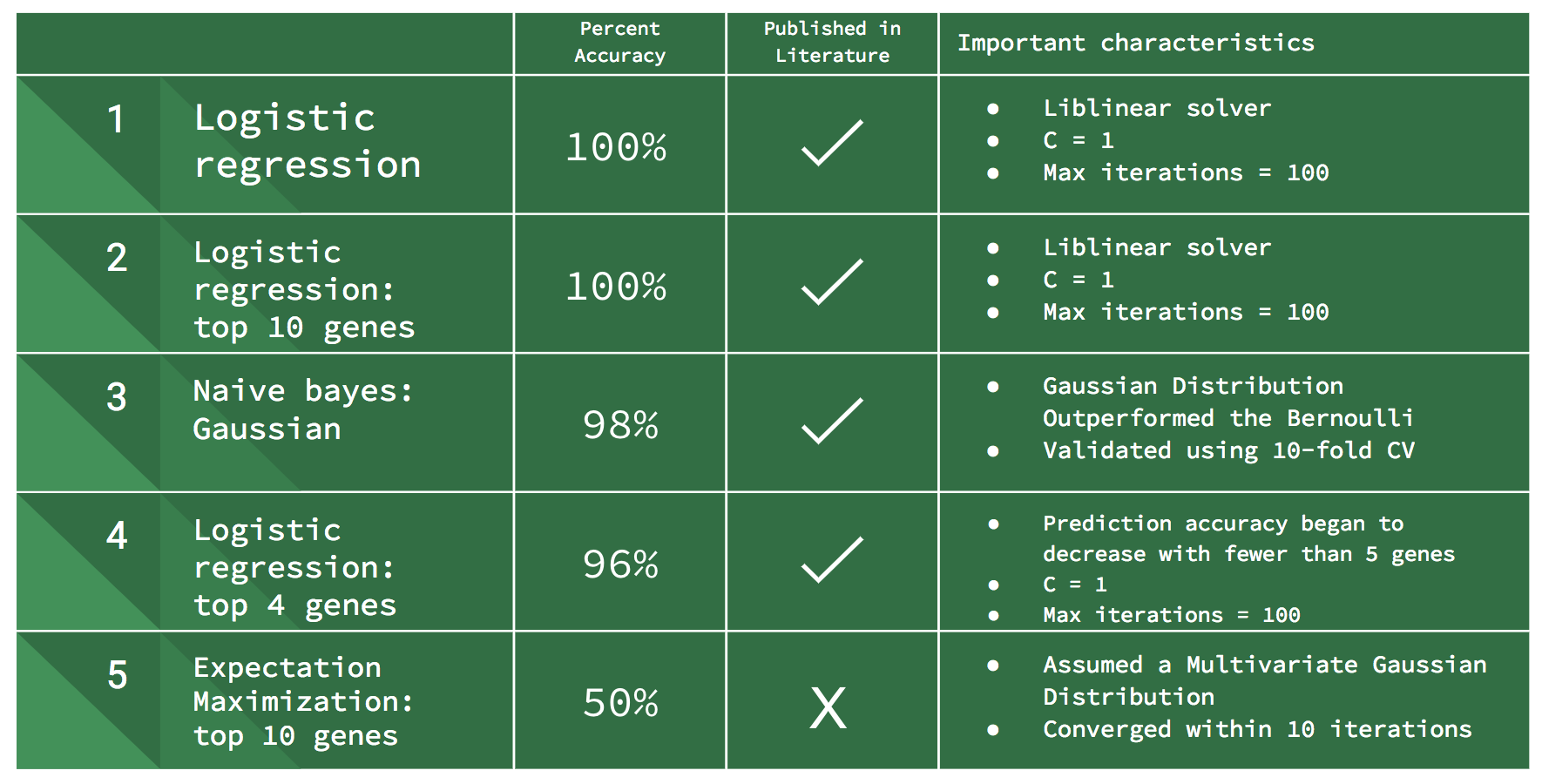
We explored this dataset using multiple approaches. First, to establish a baseline, we used logistic regression with all genes as regressors. Next, we used recursive feature elimination to decrease the number of features/genes from over 20,000 to 100 or fewer. We then created multiple logistic regression models using smaller and smaller subsets of genes (until the accuracy of predictions began to drop). Our second major modeling approach used Expectation Maximization with the top ten ranked genes in the dataset. Our third modeling approach used Naive Bayes with both Gaussian and Bernoulli distributions. For the Naive Bayes models, maximum likelihood was used to estimate the parameters and 10-fold cross validation was used to measure accuracy.
C.D. Manning, P. Raghavan and H. Schuetze (2008). Introduction to Information Retrieval. Cambridge University Press, pp. 234-265. http://nlp.stanford.edu/IR-book/html/htmledition/the-bernoulli-model-1.html
Dua, D. and Karra Taniskidou, E. (2017). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Ekström, A, Signorello, L., Hansson, L., Bergström, R., Lindgren, A., & O. Nyrén. (1999). Evaluating gastric cancer misclassification: a potential explanation for the rise in cardia cancer incidence. J Natl Cancer Inst, 5, 91(9), 786-90.
Goldoni, C., Bonora, K., Ciatto, S., Giovannetti, L., Patriarca, S., Sapino, A., . . . The IMPACT Working Group. (2009). Misclassification of Breast Cancer as Cause of Death in a Service Screening Area. Cancer Causes & Control, 20(5), 533-538. Retrieved from http://www.jstor.org/stable/40272018
Golub TR, Slonim DK, Tamayo P, Huard C, Gaasenbeek M, Mesirov JP, Coller H, Loh ML, Downing JR, Caligiuri MA, et al. (1999). Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science, 286(5439), 531–7.
Jiang, H., An, L., Baladandayuthapani, V., & Auer, P. L. (2014). Classification, Predictive Modelling, and Statistical Analysis of Cancer Data (A). Cancer Informatics, 13(Suppl 2), 1–3. http://doi.org/10.4137/CIN.S19328
Li, Y., Kang, K., Krahn, J. M., Croutwater, N., Lee, K., Umbach, D. M., & Li, L. (2017). A comprehensive genomic pan-cancer classification using The Cancer Genome Atlas gene expression data. BMC Genomics, 18, 508. http://doi.org/10.1186/s12864-017-3906-0
National Cancer Institute (NCI) (a). Cancer Classification. Retrieved March 9, 2018 from https://training.seer.cancer.gov/disease/categories/classification.html
National Cancer Institute (NCI) (b). Cancer Statistics. Retrieved March 9, 2018 from https://www.cancer.gov/about-cancer/understanding/statistics
Perou CM, Sorlie T, Eisen MB, van de Rijn M, Jeffrey SS, Rees CA, Pollack JR, Ross DT, Johnsen H, Akslen LA, et al. (2000). Molecular portraits of human breast tumours. Nature, 406(6797), 747–52.
Reis-Filho JS, Pusztai L. (2011). Gene expression profiling in breast cancer: classification, prognostication, and prediction. Lancet, 378(9805), 1812–23.
ScikitLearn. (2018). 1.9. Naive Bayes. Retirved from http://scikit-learn.org/stable/modules/naive_bayes.html.
Sotiriou C, Neo SY, McShane LM, Korn EL, Long PM, Jazaeri A, Martiat P, Fox SB, Harris AL, Liu ET. (2003). Breast cancer classification and prognosis based on gene expression profiles from a population-based study. Proc Natl Acad Sci, 100(18), 10393–8.
Weinstein, J. N., Collisson, E. A., Mills, G. B., Shaw, K. M., Ozenberger, B. A., Ellrott, K., … Cancer Genome Atlas Research Network. (2013). The Cancer Genome Atlas Pan-Cancer Analysis Project. Nature Genetics, 45(10), 1113–1120. http://doi.org/10.1038/ng.2764
Table 1: Selected Literature Review of Data Science Methods for Tumor Classification Article Title & Author | Data Science Method | Results
“A comprehensive genomic pan-cancer classification...”, Li et al, 2017. | KNN classification, k was set to 5 with a majority rule | Correctly classified on average 87.6% in test set.
“A comprehensive genomic pan-cancer classification...”, Li et al, 2017. | Gradient boosting-based classifier, XGBoost | Correctly classified on average 90.2%.
“Analysis of k-means clustering approach on the breast cancer…”, Dubey et al., 2016. | K-means algorithm | 92% average positive prediction accuracy
“Support vector machine classification and validation of cancer tissue…” | SVM with Leave-One-Out cross validation | 95.8% average positive prediction accuracy
Table 2: Outline of Datasets Dataset | Corresponding CSV file Labels | Labels.csv Gene Expression Data | Data.csv