

目前接入hera的公司(点我接入):
- 杭州二维火科技有限公司
- 杭州涂鸦科技有限公司
- 北京高因科技(居理新房)有限公司
- 盈亚科技有限公司
- 持续更新中。。欢迎大家自荐
个人微信(已满99人,需要我拉你进去)
在大数据平台,随着业务发展,每天承载着成千上万的ETL任务调度,这些任务集中在hive,shell脚本调度。怎么样让大量的ETL任务准确的完成调度而不出现问题,甚至在任务调度执行中出现错误的情况下,任务能够完成自我恢复甚至执行错误告警与完整的日志查询。hera任务调度系统就是在这种背景下衍生的一款分布式调度系统。随着hera集群动态扩展,可以承载成千上万的任务调度。它是一款原生的分布式任务调度,可以快速的添加部署wokrer节点,动态扩展集群规模。支持shell,hive,spark脚本调度,可以动态的扩展支持python等服务器端脚本调度。
hera分布式任务调度系统是根据前阿里开源调度系统(
zeus)进行的二次开发,其中zeus大概在2014年开源,开源后却并未进行维护。我公司(二维火)2015年引进了zeus任务调度系统,一直使用至今年11月份,在我们部门乃至整个公司发挥着不可替代的作用。在我使用zeus的这一年多,不得不承认它的强大,只要集群规模于配置适度,他可以承担数万乃至十万甚至更高的数量级的任务调度。但是由于zeus代码是未维护的,前端更是使用GWT技术,难于在zeus上面进行维护。我与另外一个小伙伴(花名:凌霄,现在阿里淘宝部门)于今年三月份开始重写zeus,改名赫拉(hera)
***项目地址:[email protected]:scxwhite/hera.git ***
hera系统只是负责调度以及辅助的系统,具体的计算还是要落在hadoop、hive、yarn、spark等集群中去。所以此时又一个硬性要求,如果要执行hadoop,hive,spark等任务,我们的hera系统的worker一定要部署在这些集群某些机器之上。如果仅仅是shell,那么也至少需要linux系统。对于windows系统,可以把自己作为master进行调试。
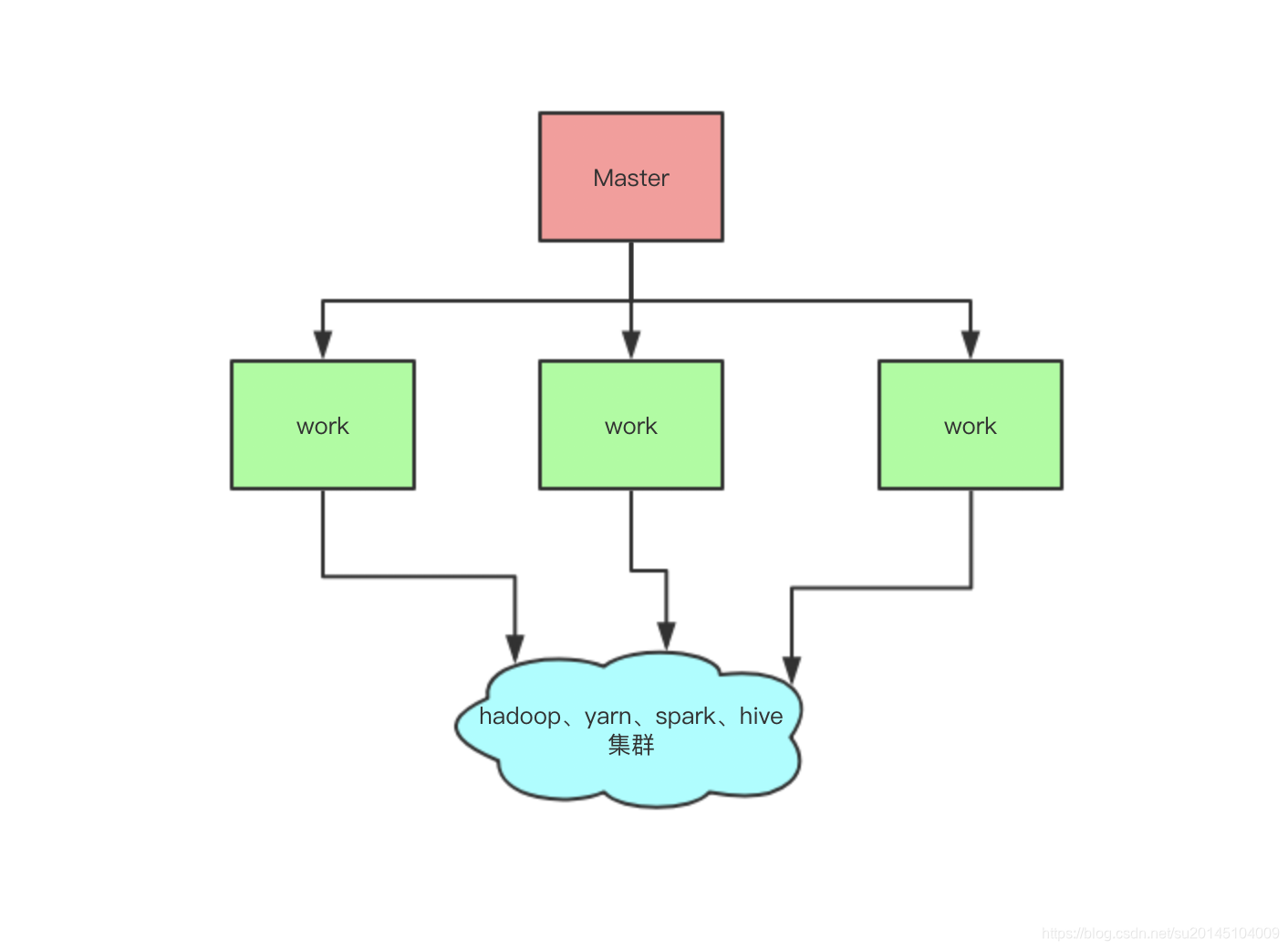
hera系统本身严格的遵从主从架构模式,由主节点充当着任务调度触发与任务分发器,从节点作为具体的任务执行器.架构图如下:
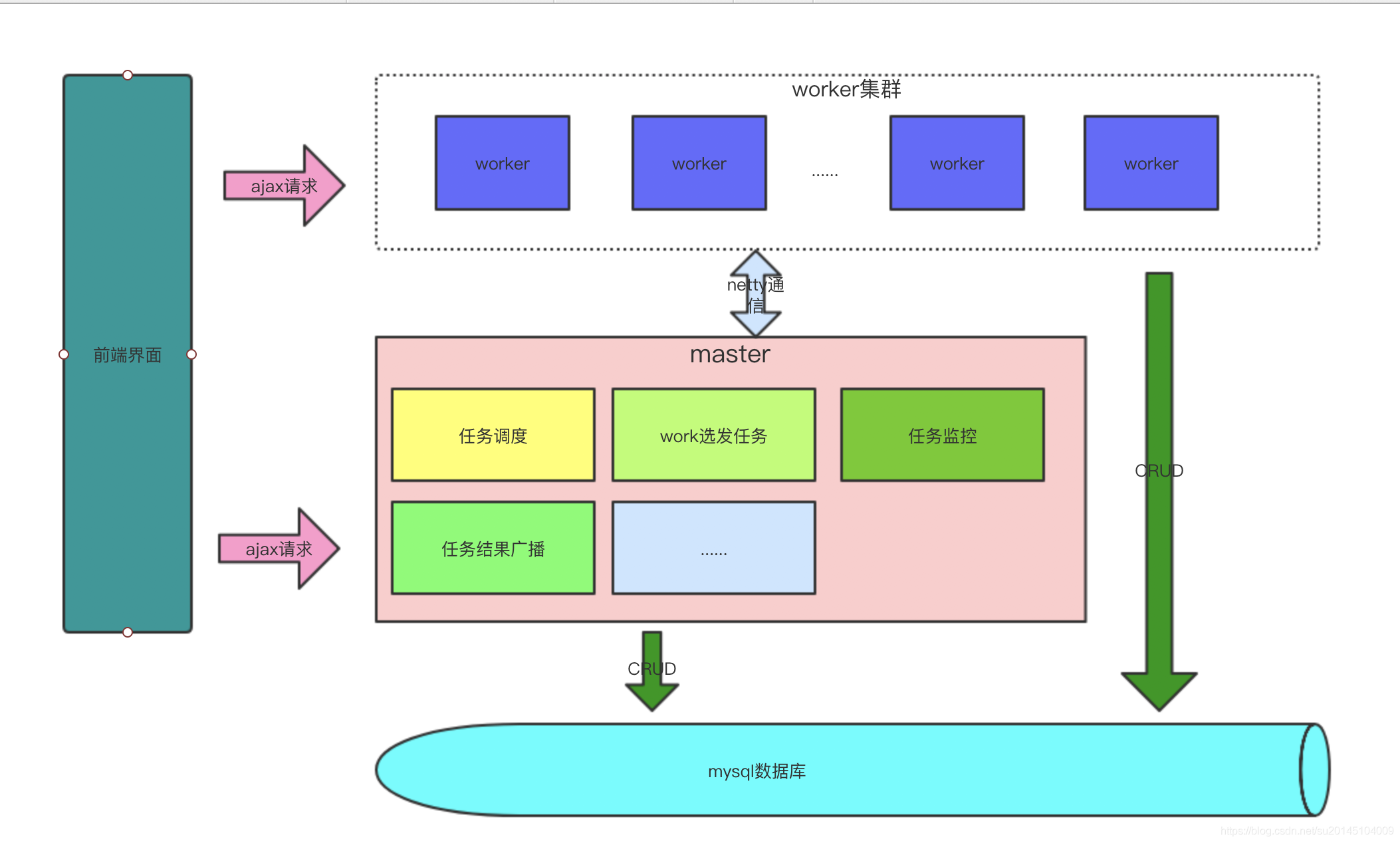
hera分布式任务调度系统的设计目标首先是要完成zeus大部分核心功能,并能够根据自己公司的需求进行扩展。大致目标有以下几点
- 支持任务的定时调度、依赖调度、手动调度、手动恢复
- 支持丰富的任务类型:
shell,hive,python,spark-sql,java - 可视化的任务
DAG图展示,任务的执行严格按照任务的依赖关系执行 - 某个任务的上、下游执行状况查看,通过任务依赖图可以清楚的判断当前任务为何还未执行,删除该任务会影响那些任务。
- 支持上传文件到
hdfs,支持使用hdfs文件资源 - 支持日志的实时滚动
- 支持任务失败自动恢复
- 实现集群HA,机器宕机环境实现机器断线重连与心跳恢复与
hera集群HA,节点单点故障环境下任务自动恢复,master断开,worker抢占master - 支持对
master/work负载,内存,进程,cpu信息的可视化查看 - 支持正在等待执行的任务,每个
worker上正在执行的任务信息的可视化查看 - 支持实时运行的任务,失败任务,成功任务,任务耗时
top10的可视化查看 - 支持历史执行任务信息的折线图查看 具体到某天的总运行次数,总失败次数,总成功次数,总任务数,总失败任务数,总成功任务数
- 支持关注自己的任务,自动调度执行失败时会向负责人发送邮件
- 对外提供
API,开放系统任务调度触发接口,便于对接其它需要使用hera的系统 - 组下任务总览、组下任务失败、组下任务正在运行
- 支持
map-reduce任务和yarn任务的实时取消。 - (还有更多,等待大家探索)
- 定时调度
主要是根据cron表达式来解析该任务的执行时间,在达到触发时间时将该任务加入任务队列
为了进行测试我新建了一个shell任务 在15:40执行 ,在配置项里输入我们自己的配置,在脚本中使用${}进行替换,其中的继承配置项,即任务继承的所在组的配置信息,如果有重复以最近的为准
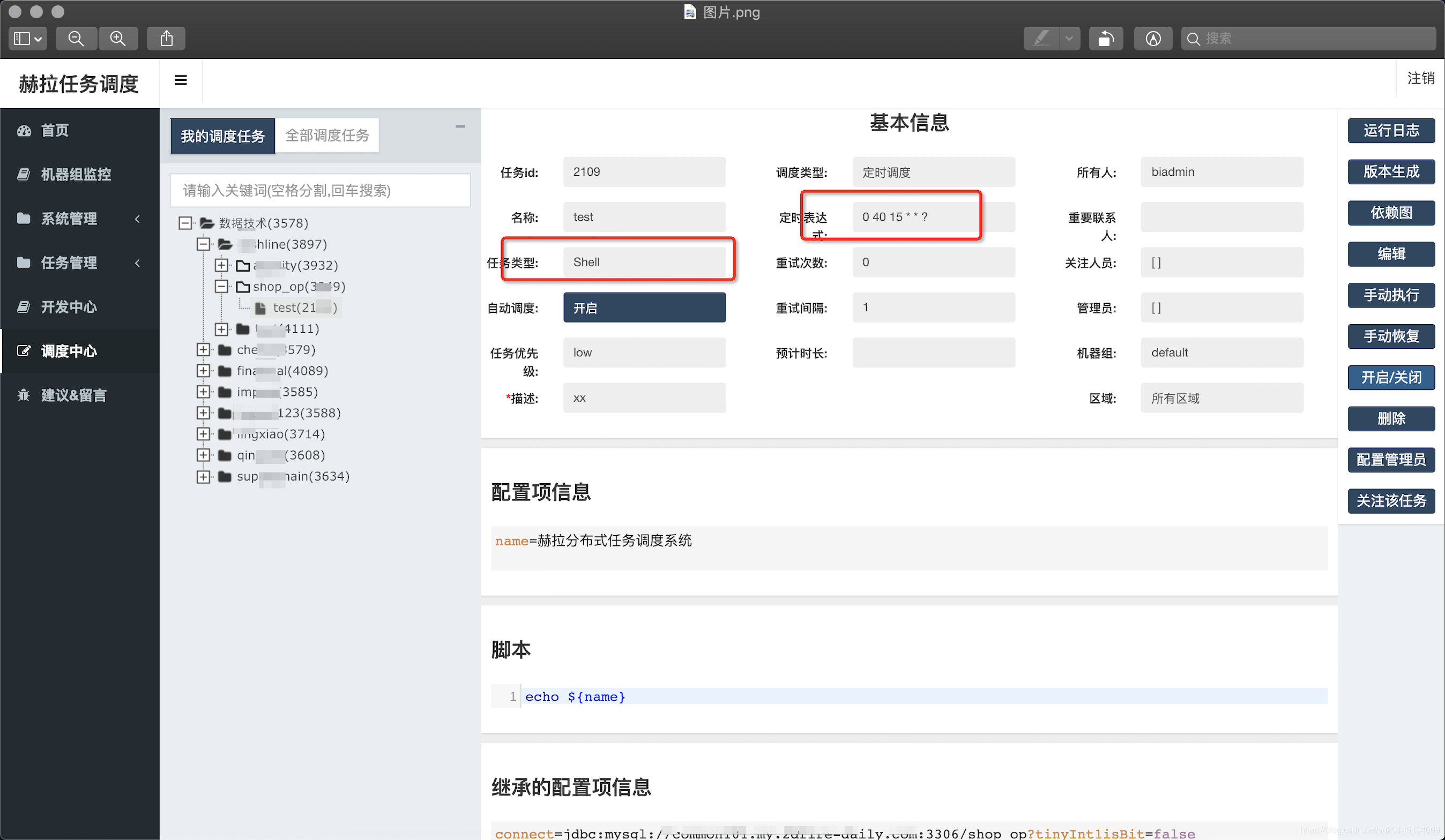
当任务达到时间开始执行,输出我们想要的结果:赫然分布式任务调度系统
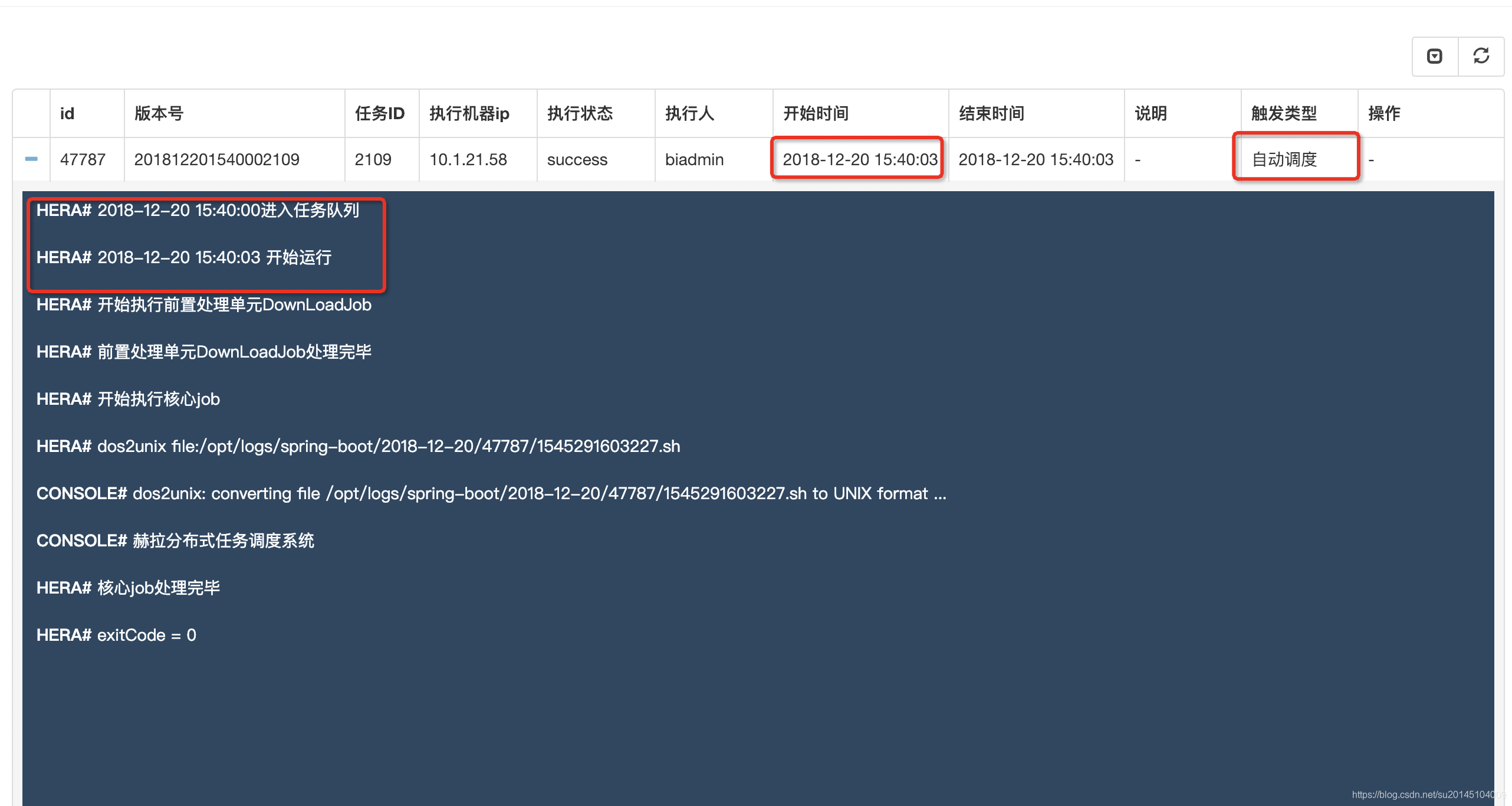
- 依赖调度
我们的任务大部分都有依赖关系,只有在上一个任务计算出结果后才能进行下一步的执行。我们的依赖任务会在所有的依赖任务都执行完成之后才会被触发加入任务队列
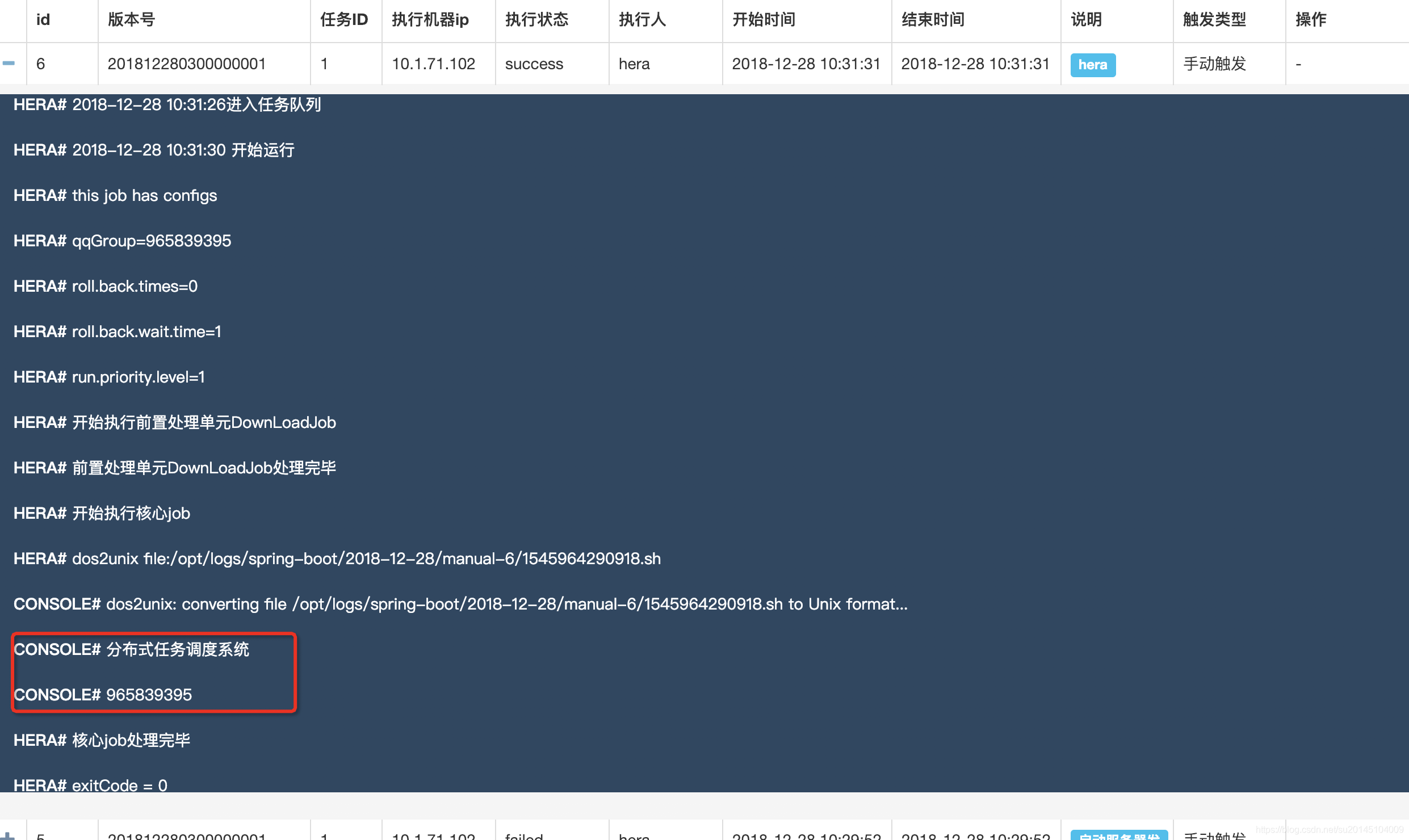
贴一个已有的任务执行信息
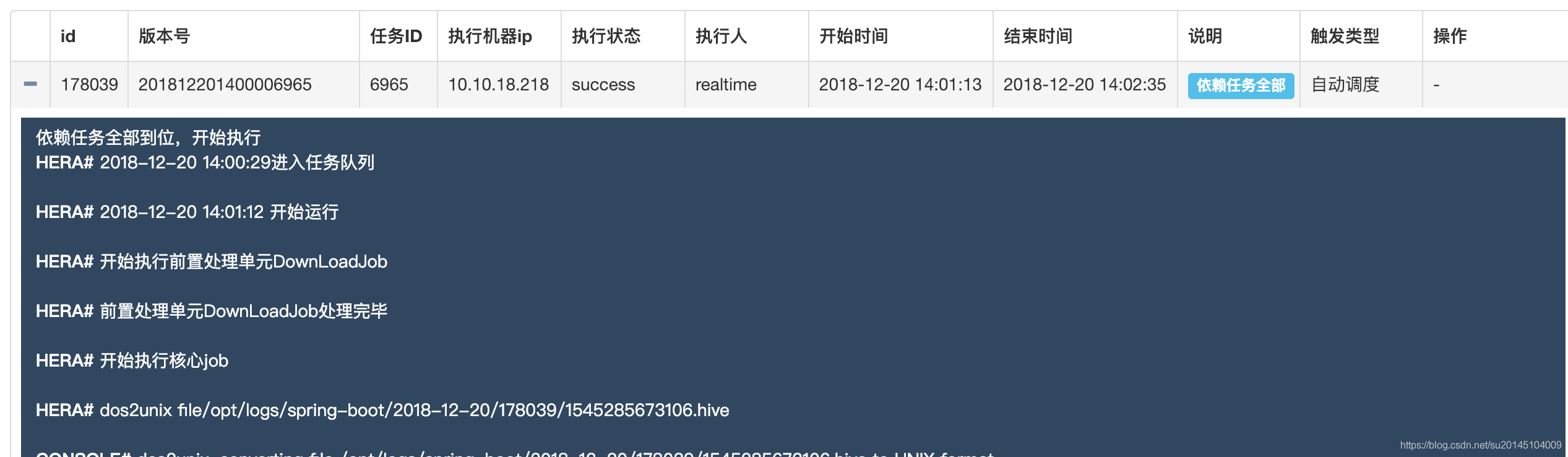
- 手动调度
手动调度即为手动执行的任务,手动执行后自动加入任务队列,请注意,手动任务执行成功后不会通知下游任务(即:依赖于该任务的任务)该任务已经执行完成
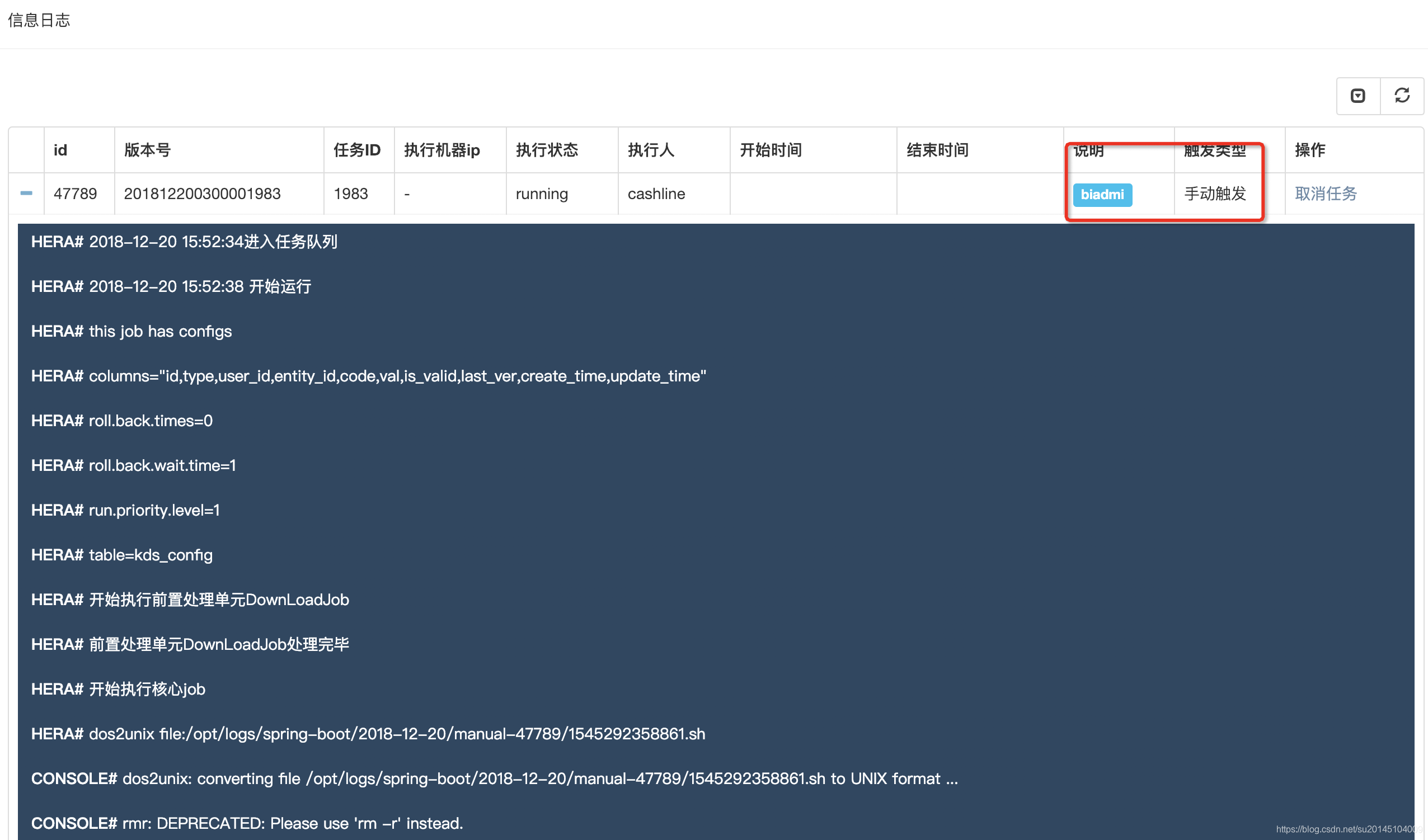
- 手动恢复
手动恢复类似于手动调度,于手动调度的区别为此时如果该任务执行成功,会通知下游任务该任务已经执行完成
hera分布式任务调度系统依赖于jdk原生的ProcessBuilder 通过该工具向work/master以shell命令的方式执行任务。
比如python任务
我们可以首先写一个python脚本hello.py(这里随便贴个图片),然后把该脚本上传到hdfs
在执行的时候我们可以通过
download[hdfs:///hera/hello.py hello.py];
python hello.py;
来执行该脚本
这样一个完整的pyhton脚本就能通过方式实现shell方式调用执行,通过hera内部实现的job执行封装,脚本的文法解析,实现pyhton任务执行。实际上,通过这种方式甚至可以实现java,scala,hive-udf等服务器端语言的脚本任务执行。
- hive spark-sql 脚本的执行
对于hive脚本和spark-sql脚本 都是通过-f 命令来执行一个文件
当任务数量过多,依赖错综复杂时就需要一个DAG图来查看任务之间的关系。
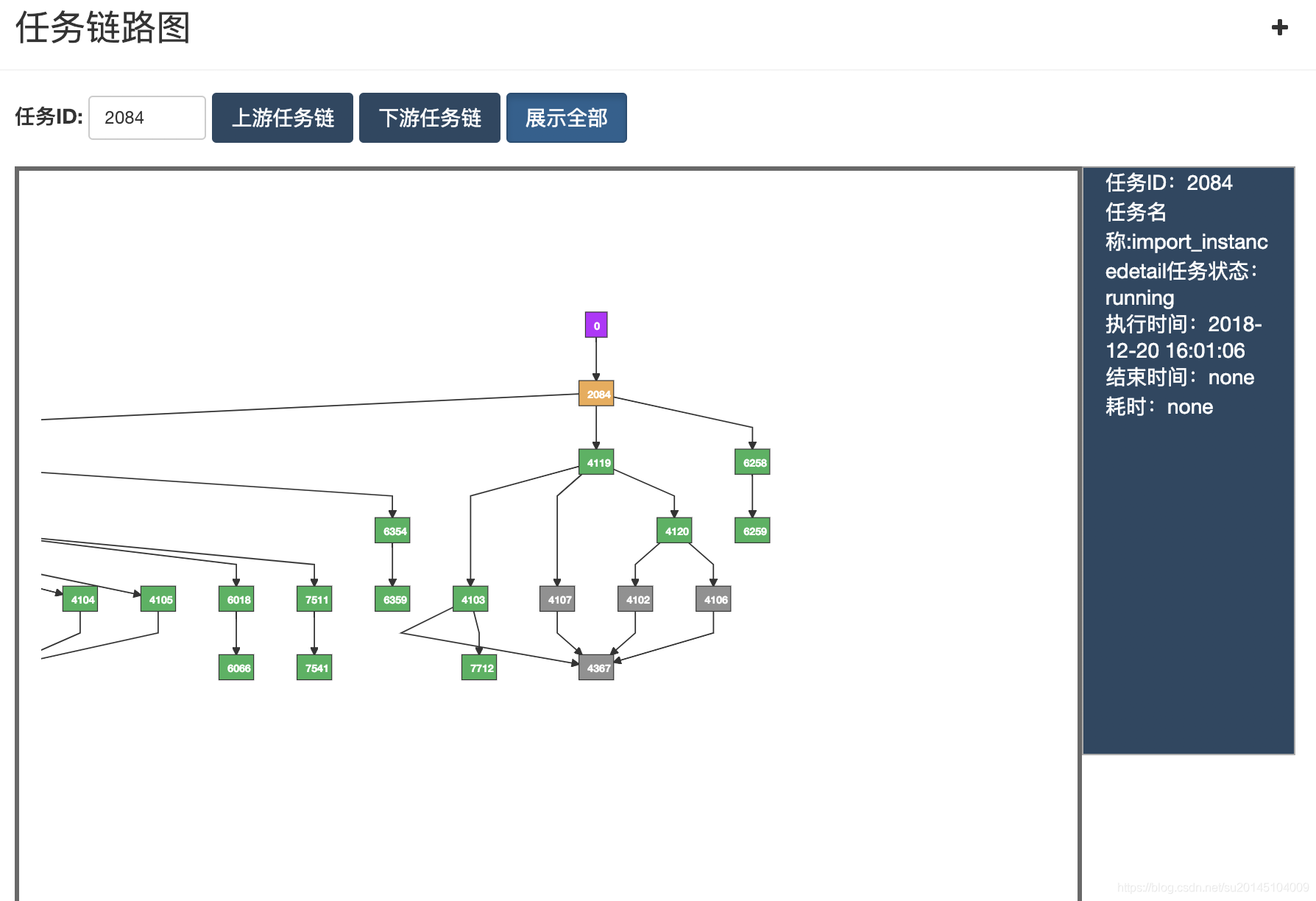
黄色表示正在执行,灰色表示关闭的任务,红色表示失败的任务,绿色表示执行成功的任务。右侧会显示该任务的详细信息。 当然在这里既支持全部查看也支持点击查看,当点击某个任务时会展示出依赖这个任务的所有任务。
这个在上面 的 支持丰富的任务类型:shell,hive,python,spark-sql,java 已经说过,不再赘述。
当执行任务时,可以通过查看日志的方式查看实时滚动的日志
当然,某些情况下任务可能会失败,比如网络闪断,可能下一秒就好了。建议对于非常重要的任务一定要开启任务失败重试,设置自定义的重试次数于重试时间间隔,设置后master会根据配置进行失败任务重试调度。
比如设置重试次数3,重试间隔10分钟
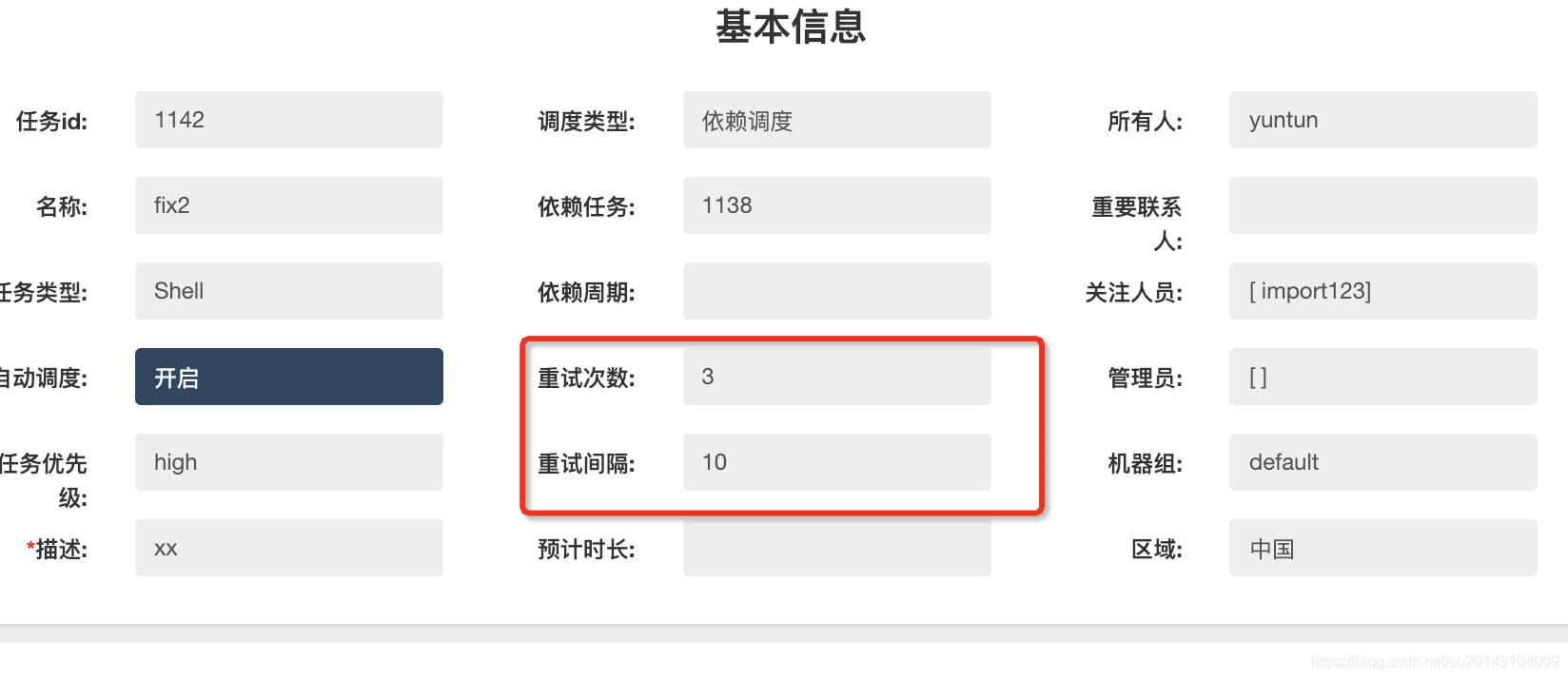
任务在执行失败后进行三次重试,可以看上次失败的结束时间与开始时间间隔为10分钟。
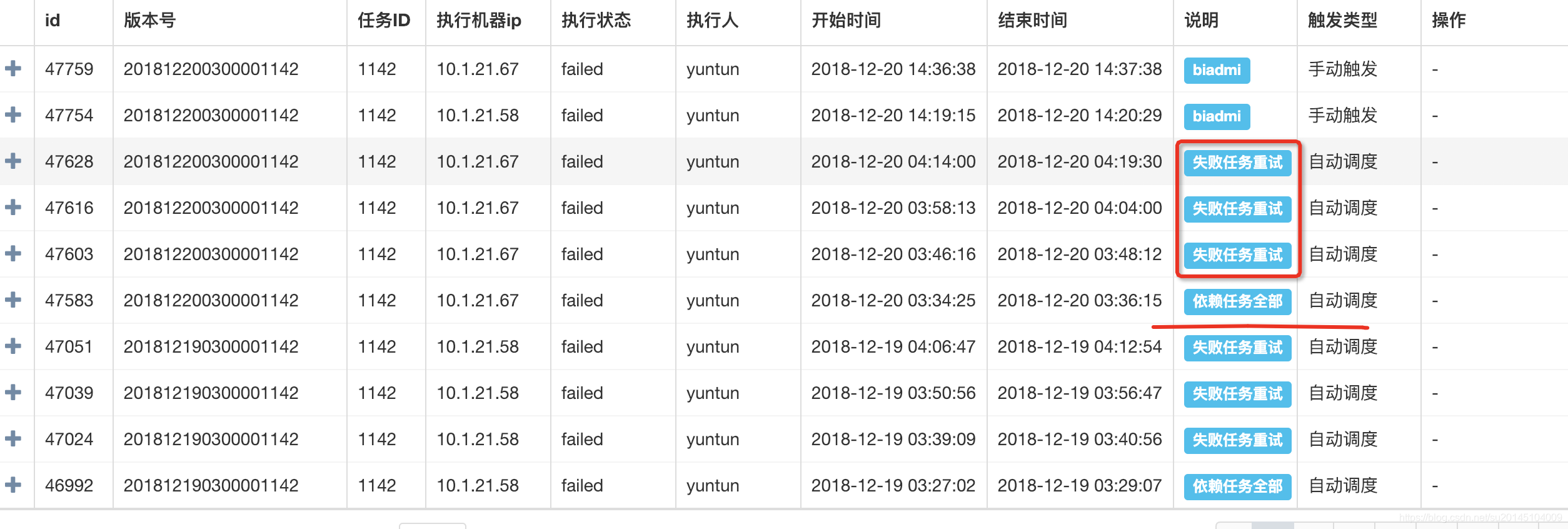
构建分布式系统,无法避免的就是需要做集群容灾。在出现服务器宕机与网络闪断的情况下要做到集群实现自动通信恢复,在此基础上,要做到实现任务在通信恢复后任务重新恢复执行等。 这个就无法展示了,等待大家以后去体验。
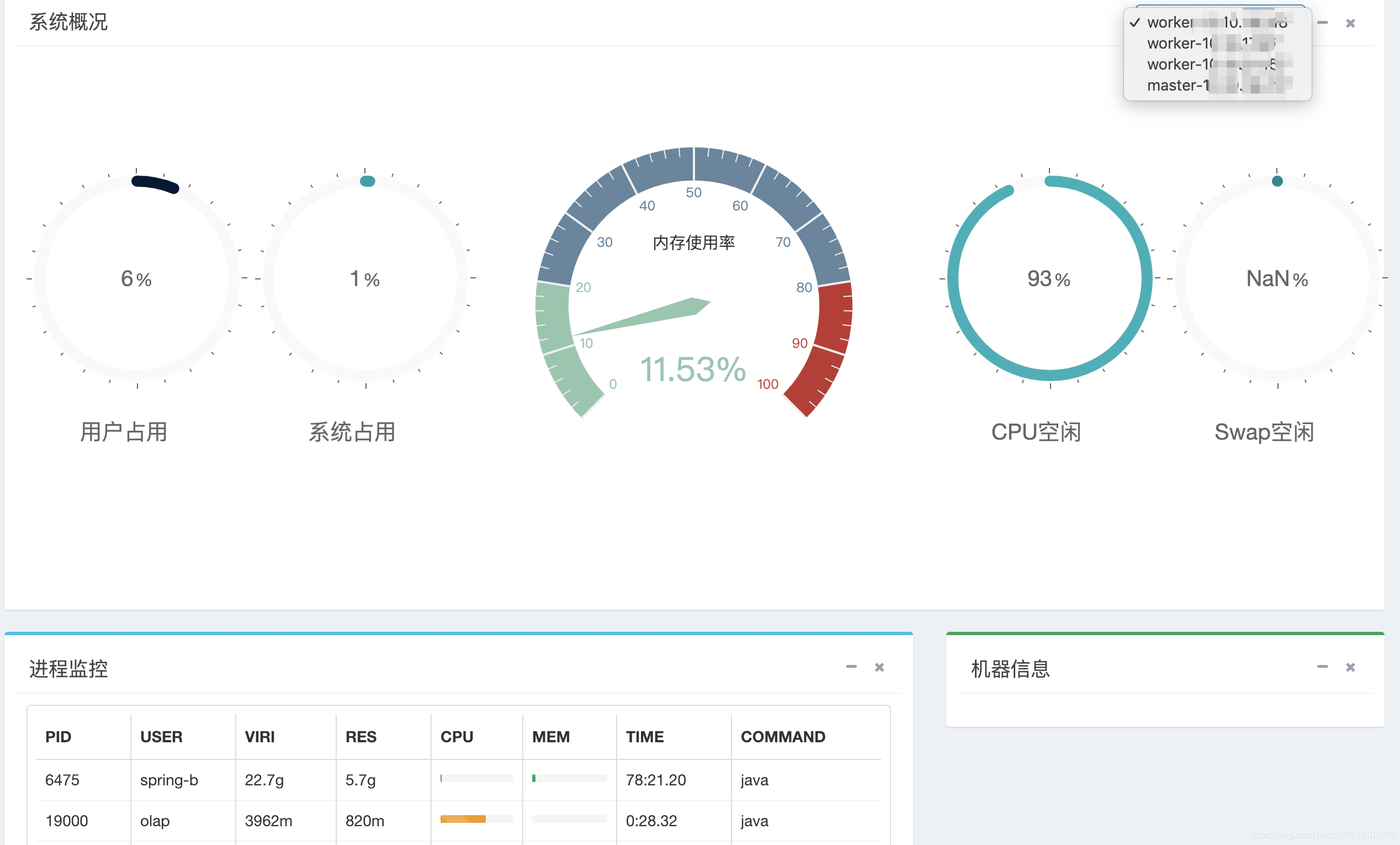
这里可以看机器的用户cpu占用百分比,系统cpu占用百分比,cpu空闲,进行信息 等等。。
首先上图
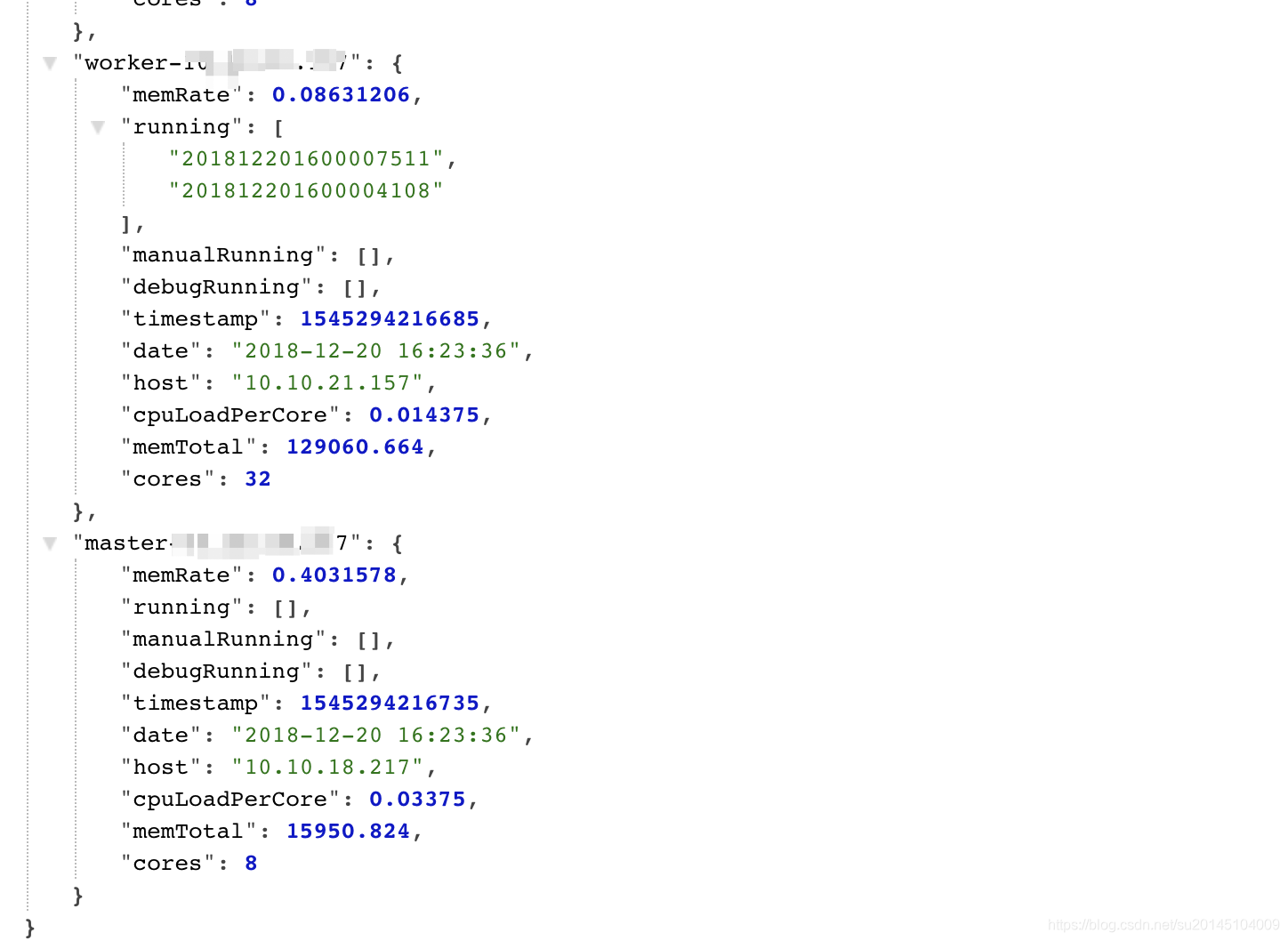
哈哈,有点简陋,只是提供了api接口,无奈没前端,现在就我一个人在开发。等吧。
里面的信息有机器内存使用百分比,平均每个核的负载,机器总内存,统计的时间。其中有三个队列,分别是running,manualRunning,debugRunning 在master开头的机器上表示等待执行的任务,在work开头的机器上表示正在执行的任务。分别对应自动调度&依赖任务 、手动执行任务、开发任务(另外一个开发界面)
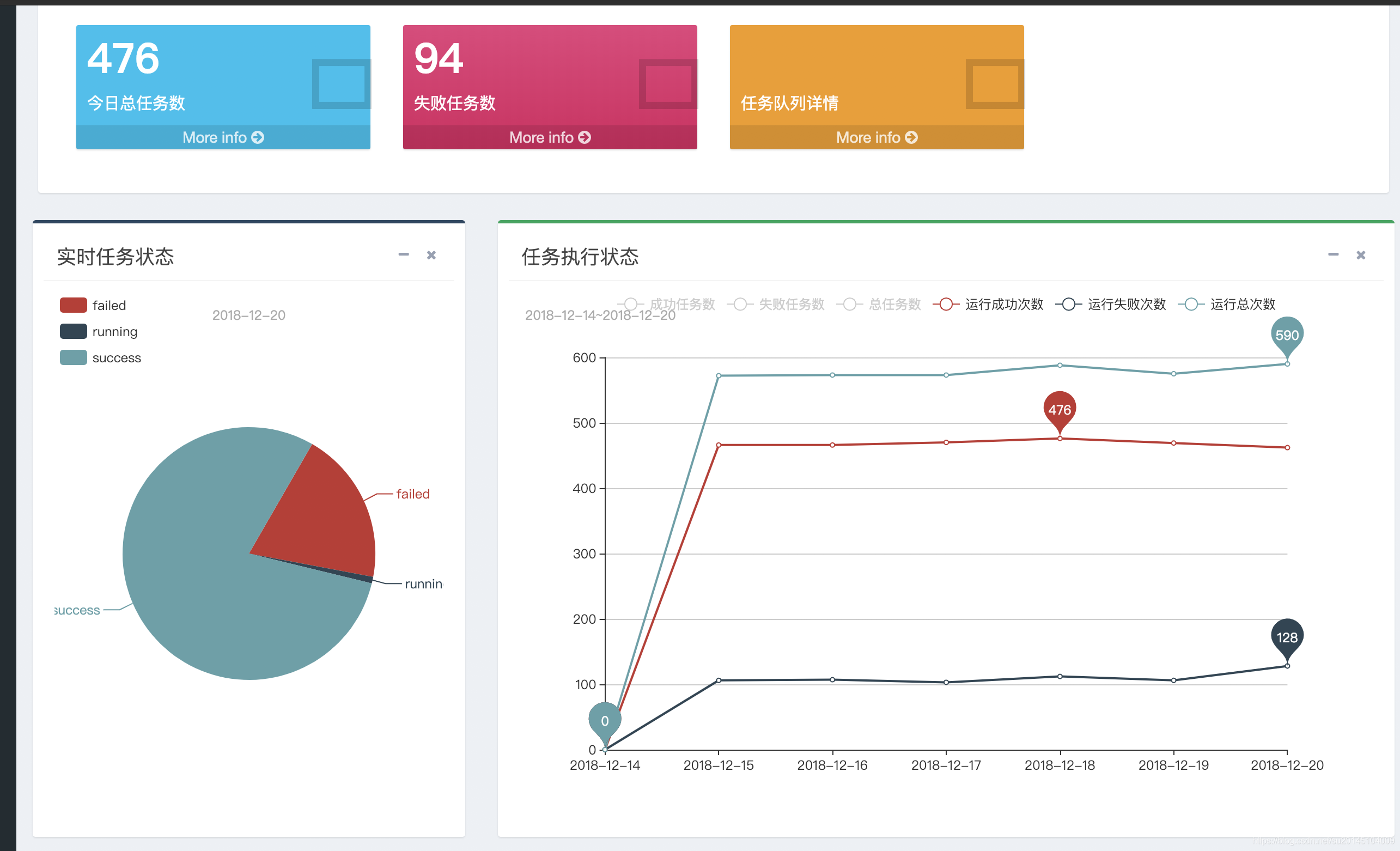
其中饼图可以通过点击进去查看具体的详细任务信息

当我们需要关注某些任务时可以通过关注任务来接收任务失败的信息
虽然在首页我们看到失败的任务,但是有时候我们并不想关注别人的任务。我们就可以通过创建属于我们自己的组,然后在组下创建任务。这时候就可以通过组下任务预览来查看任务状态
比如点了任务总览
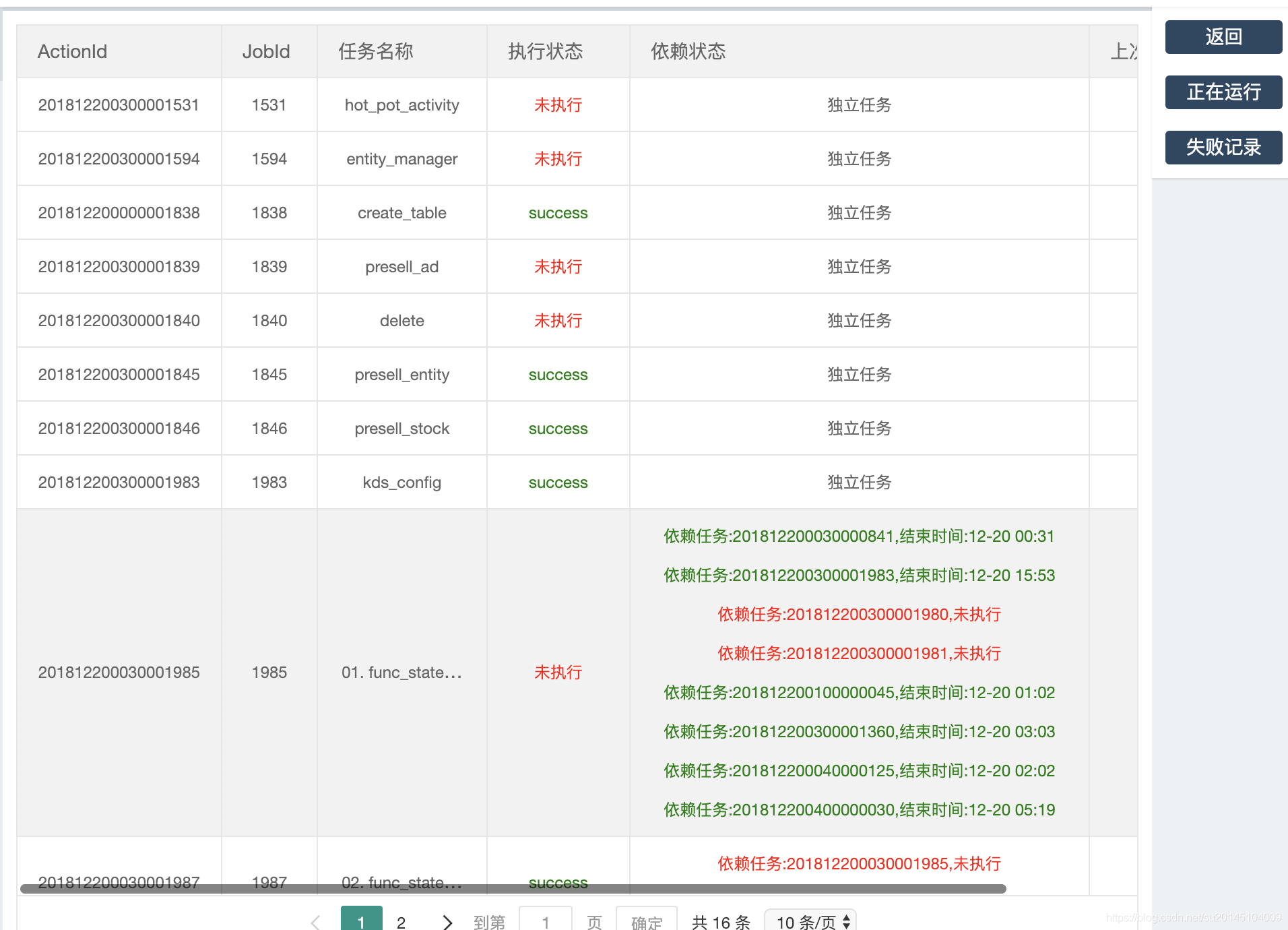
此时可以看到任务的所有信息,无论是执行,未执行,执行失败,执行成功还是运行中,如果任务未执行还会提示某些依赖任务未执行,如果依赖任务执行, 会展示任务的执行时间等等。右侧还可以再对内容进行筛选,比如查看失败,运行的任务。
其实我们也做了许多其它功能,删除任务判断是否有任务依赖,关闭任务是否有任务依赖等。之外我们也做了hive sql血缘解析,字段解析,任务执行日志解析等等,由于在其它项目上面,后面会考虑继承到hera里面。
准备在12月开源吧。最近把项目整理整理。
附上凌霄的博客地址:https://blog.csdn.net/pengjx2014/article/details/81276874 以上所有信息均为线下测试信息
***项目地址:[email protected]:scxwhite/hera.git ***
当使用git把hera克隆到本地之后,首先在hera/hera-admin/resources目录下找到hera.sql文件,在自己的数据库中新建这些必要的表,并插入初始化的数据。
此时可以在hera/hera-admin/resources目录下找到application.yml文件。在文件里修改数据源hera的数据源(修改druid.datasource下的配置)即可进行下面的操作。
spring:
profiles:
active: @env@ ##当前环境 打包时通过-P来指定
http:
multipart:
max-file-size: 100Mb #允许上传文件的最大大小
max-request-size: 100Mb #允许上传文件的最大大小
freemarker:
allow-request-override: true
cache: false
check-template-location: true
charset: utf-8
content-type: text/html
expose-request-attributes: false
expose-session-attributes: false
expose-spring-macro-helpers: false
suffix: .ftl
template-loader-path: classpath:/templates/
request-context-attribute: request
druid:
datasource:
username: root #数据库用户名
password: XIAOSUDA #数据库密码
driver-class-name: com.mysql.jdbc.Driver #数据库驱动
url: jdbc:mysql://localhost:3306/hera?characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&autoReconnect=true&allowMultiQueries=true
initial-size: 5 #初始化连接池数量
min-idle: 1 #最小生存连接数
max-active: 16 #最大连接池数量
max-wait: 5000 #获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
time-between-connect-error-millis: 60000 # Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接,单位是毫秒
min-evictable-idle-time-millis: 300000 # 连接保持空闲而不被驱逐的最长时间,单位是毫秒
test-while-idle: true #申请连接的时候,如果检测到连接空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效
test-on-borrow: true #申请连接时执行validationQuery检测连接是否有效
test-on-return: false # 归还连接时执行validationQuery检测连接是否有效
connection-init-sqls: set names utf8mb4
validation-query: select 1 #用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。
validation-query-timeout: 1 #单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法
log-abandoned: true
stat-mergeSql: true
filters: stat,wall,log4j
connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
server:
port: 8080
context-path: /hera
clean:
path: ${server.context-path}
#hera全局配置
hera:
defaultWorkerGroup : 1 #默认worker的host组id
preemptionMasterGroup : 1 #抢占master的host组id
excludeFile: jar;war
maxMemRate : 0.80 #已使用内存占总内存的最大比例,默认0.80。当worker内存使用达到此值时将不会再向此work发任务
maxCpuLoadPerCore : 1.0 #cpu load per core等于最近1分钟系统的平均cpu负载÷cpu核心数量,默认1.0。当worker平均负载使用达到此值时将不会再向此work发任务
scanRate : 1000 #任务队列扫描频率(毫秒)
systemMemUsed : 4000 # 系统占用内存
perTaskUseMem : 500 # 假设每个任务使用内存500M
requestTimeout: 10000 # 异步请求超时时间
channelTimeout: 1000 # netty请求超时时间
heartBeat : 3 # 心跳传递时间频率
downloadDir : /opt/logs/spring-boot
hdfsLibPath : /hera/hdfs-upload-dir #此处必须是hdfs路径,所有的上传附件都会存放在下面路径上
schedule-group : online
maxParallelNum: 2000 #master 允许的最大并行任务 当大于此数值 将会放在阻塞队列中
connectPort : 9887 #netty通信的端口
admin: biadmin # admin用户
taskTimeout: 12 #单个任务执行的最大时间 单位:小时
env: @env@
# 发送配置邮件的发送者
mail:
host: smtp.mxhichina.com
protocol: smtp
port: 465
user: xxx
password: xxx
logging:
config: classpath:logback-spring.xml
path: /opt/logs/spring-boot
level:
root: INFO
org.springframework: ERROR
com.dfire.common.mapper: ERROR
mybatis:
configuration:
mapUnderscoreToCamelCase: true
#spark 配置
spark :
address : jdbc:hive2://localhost:10000
driver : org.apache.hive.jdbc.HiveDriver
username : root
password : root
master : --master yarn
driver-memory : --driver-memory 1g
driver-cores : --driver-cores 1
executor-memory : -- executor-memory 1g
executor-cores : --executor-cores 1
---
## 开发环境
spring:
profiles: dev
logging:
level:
com.dfire.logs.ScheduleLog: ERROR
com.dfire.logs.HeartLog: ERROR
---
## 日常环境 通常与开发环境一致
spring:
profiles: daily
---
## 预发环境
spring:
profiles: pre
druid:
datasource:
url: jdbc:mysql://localhost:3306/lineage?characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&autoReconnect=true&allowMultiQueries=true
username: root
password: root
#spark 配置
spark :
address : jdbc:hive2://localhost:10000 #spark地址
master : --master yarn
driver-memory : --driver-memory 2g
driver-cores : --driver-cores 1
executor-memory : -- executor-memory 2g
executor-cores : --executor-cores 1
---
## 正式环境
spring:
profiles: publish
druid:
datasource:
url: jdbc:mysql://localhost:3306/lineage?characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&autoReconnect=true&allowMultiQueries=true
username: root
password: root
#spark 配置
spark :
address : jdbc:hive2://localhost:10000
master : --master yarn
driver-memory : --driver-memory 2g
driver-cores : --driver-cores 1
executor-memory : -- executor-memory 2g
executor-cores : --executor-cores 1
当上面的操作完成后,即可使用maven的打包命令进行打包
mvn clean package -Dmaven.test.skip -Pdev
打包后可以进入hera-admin/target目录下查看打包后的hera.jar 。此时可以简单使用java -server -Xms4G -Xmx4G -Xmn2G -jar hera.jar 启动项目,此时即可在浏览器中输入
localhost:8080/hera
即进入登录界面,账号为hera 密码为biadmin,点击登录即进入系统。
顺便附上我的启动脚本
#!/bin/sh
JAVA_OPTS="-server -Xms4G -Xmx4G -Xmn2G -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:CMSFullGCsBeforeCompaction=5 -XX:+CMSParallelInitialMarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/opt/logs/spring-boot/gc.log -XX:MetaspaceSize=128m -XX:+UseCMSCompactAtFullCollection -XX:MaxMetaspaceSize=128m -XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/logs/spring-boot/dump"
log_dir="/opt/logs/spring-boot"
log_file="/opt/logs/spring-boot/all.log"
jar_file="/opt/app/spring-boot/hera.jar"
#日志文件夹不存在,则创建
if [ ! -d "${log_dir}" ]; then
echo "创建日志目录:${log_dir}"
mkdir -p "${log_dir}"
echo "创建日志目录完成:${log_dir}"
fi
#父目录下jar文件存在
if [ -f "${jar_file}" ]; then
#启动jar包 错误输出的error 标准输出的log
nohup java $JAVA_OPTS -jar ${jar_file} 1>"${log_file}" 2>"${log_dir}"/error.log &
echo "启动完成"
exit 0
else
echo -e "\033[31m${jar_file}文件不存在!\033[0m"
exit 1
fi此时就登录上了。下面需要做的是在worker管理这里添加执行任务的机器IP,然后选择一个机器组(组的概念:对于不同的worker而言环境可能不同,可能有的用来执行spark任务,有的用来执行hadoop任务,有的只是开发等等。当创建任务的时候根据任务类型选择一个组,要执行任务的时候会发送到相应的组的机器上执行任务)。
对于执行work的机器ip调试时可以是master,生产环境建议不要让master执行任务。如果要执行map-reduce或者spark任务,要保证你的work具有这些集群的客户端。
那么我们就在work管理页面增加要执行的work地址以及机器组。
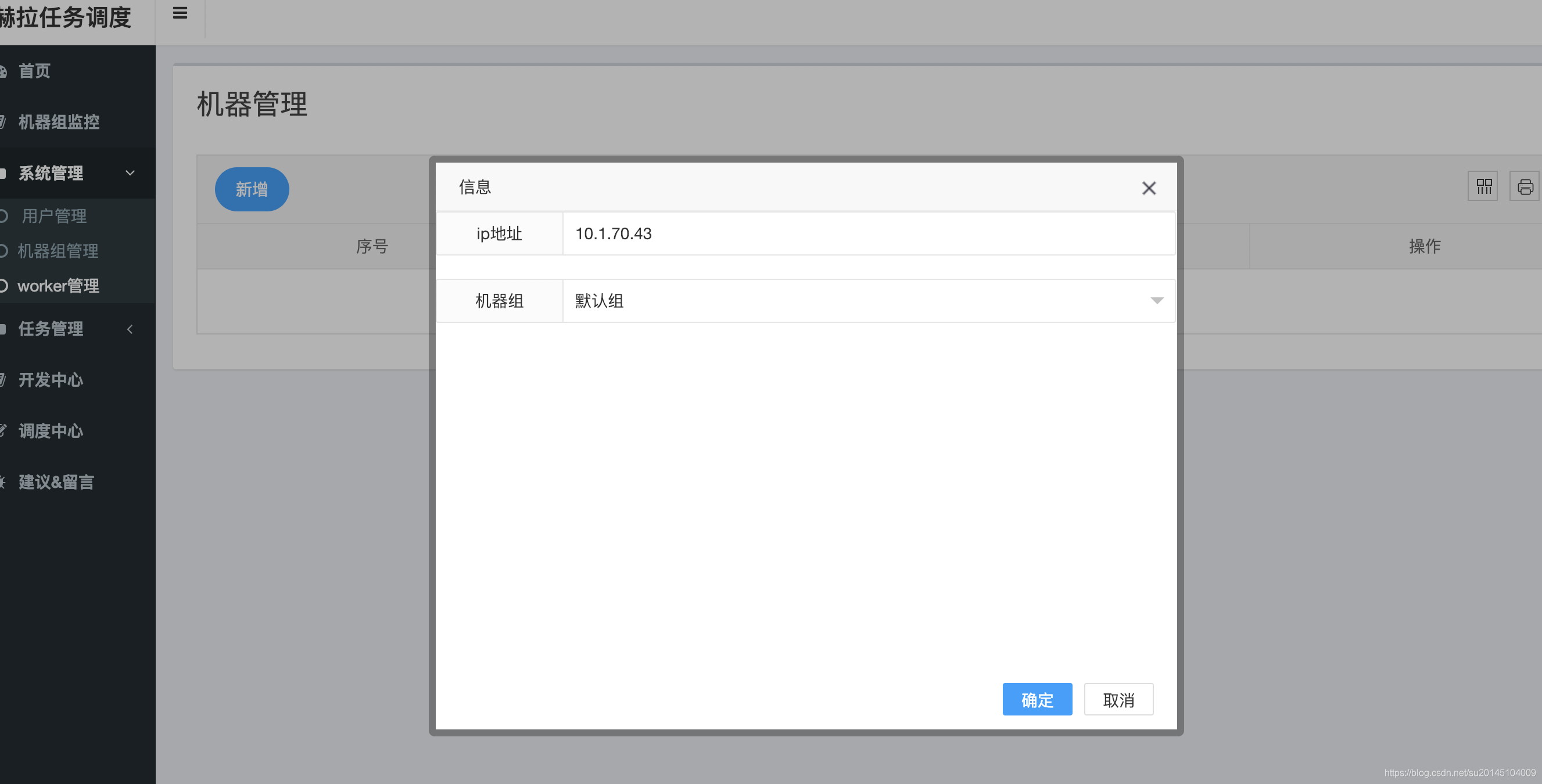
此时有30分钟的缓冲时间,master才会检测到该work加入。为了测试,此时我们可以通过重启master来立刻使该work加入执行组(后面会增加一键刷新work信息)。
重启后我们可以进入调度中心 ,在搜索栏里搜索1,然后按回车
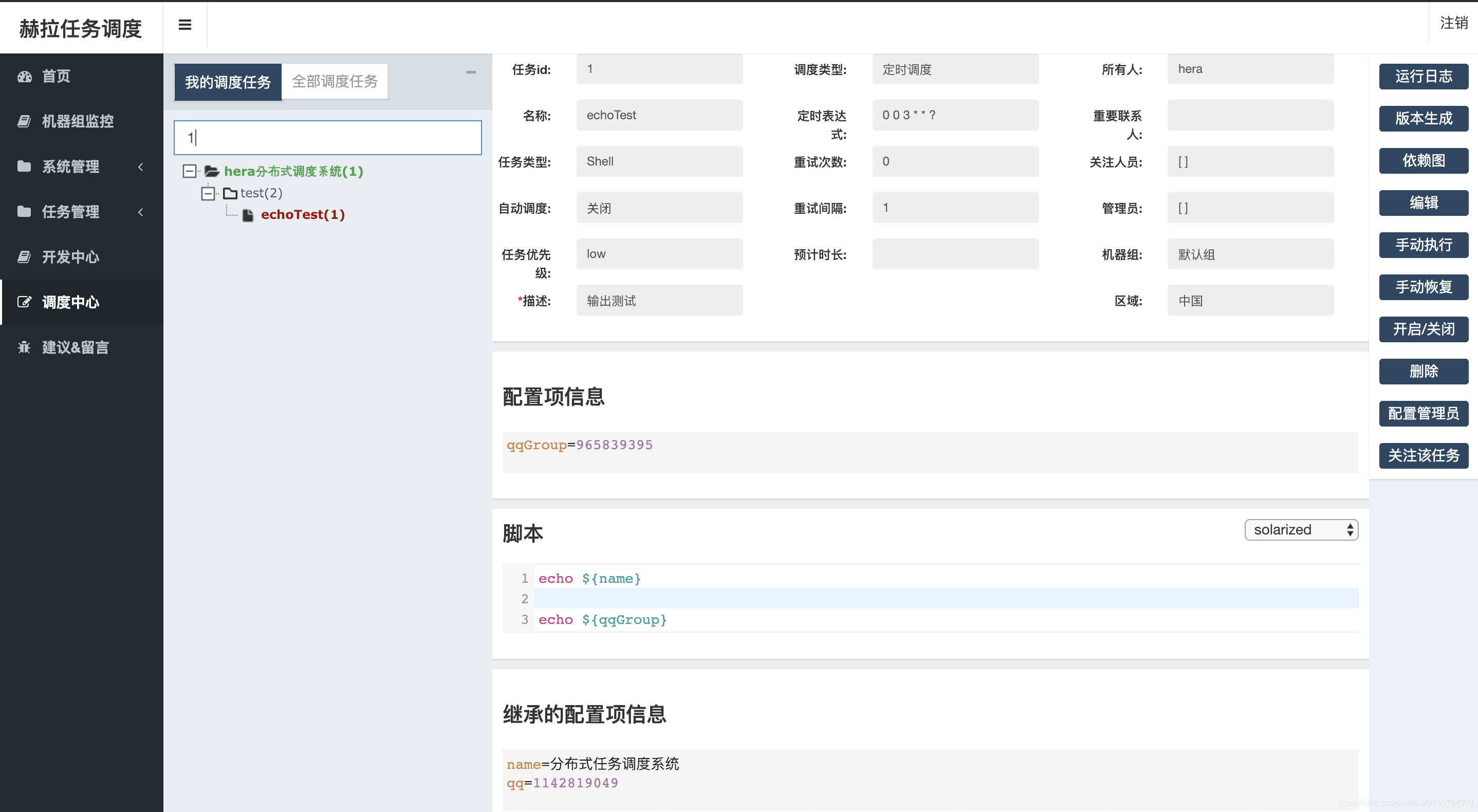
会发现一个echoTest任务 ,此时我们还不能执行任务,因为我们的所有任务的执行者登录用户。比如此刻我使用hera登录的,那么此时一定要保证你的work机器上有hera这个用户。
否则执行任务会出现sudo: unknown user: hera 异常。
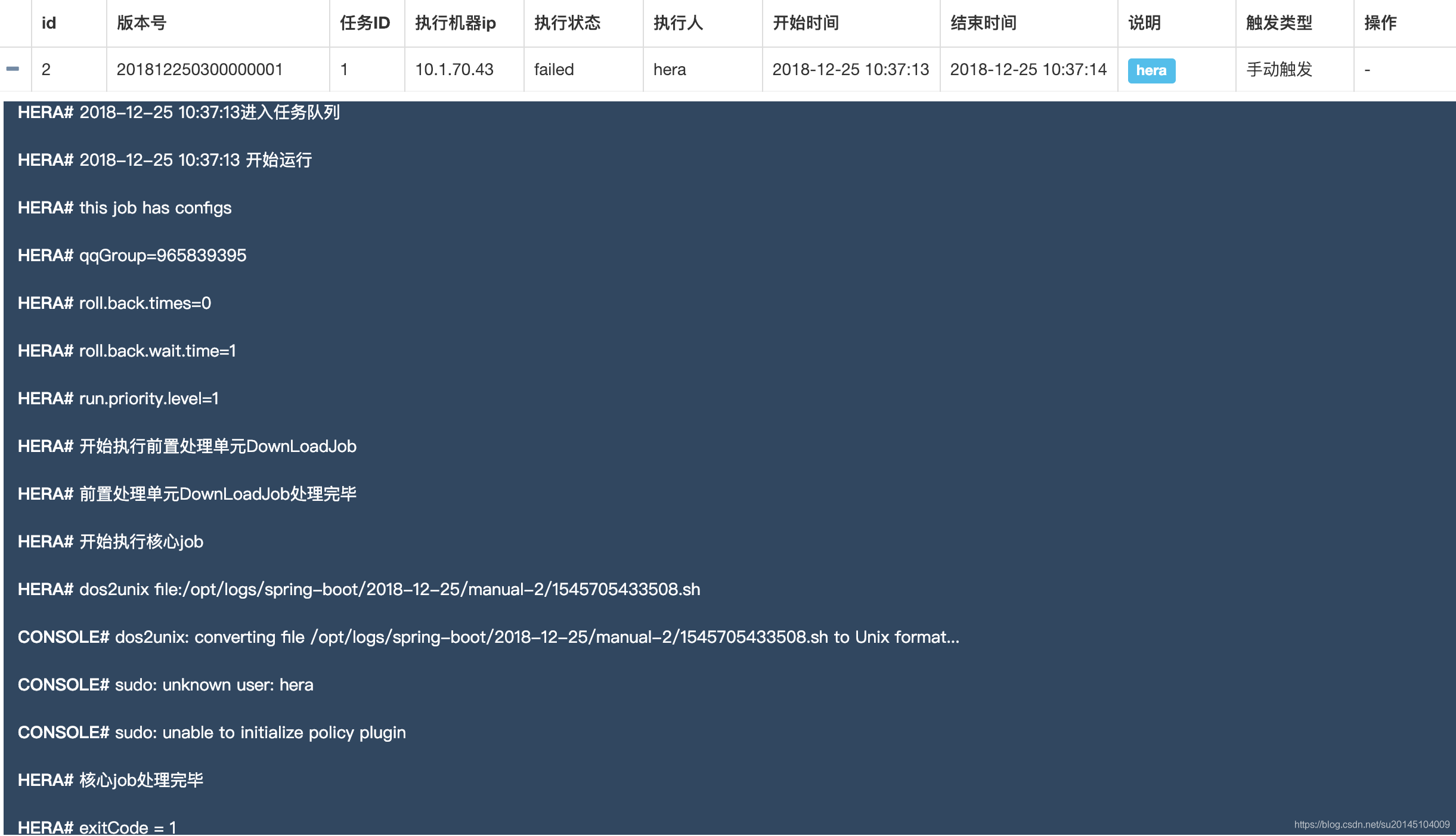
此时可以向我们填写的work机器上增加hera用户。
useradd hera
如果是mac系统 那么可以使用以下命令创建hera用户
sudo dscl . -create /Users/hera
sudo dscl . -create /Users/hera UserShell /bin/bash
sudo dscl . -create /Users/hera RealName "hera分布式任务调度"
sudo dscl . -create /Users/hera UniqueID "1024"
sudo dscl . -create /Users/hera PrimaryGroupID 80
sudo dscl . -create /Users/hera NFSHomeDirectory /Users/hera
此时点击手动执行->选择版本->执行。此时该任务会运行,点击右上角的查看日志,可以看到任务的执行记录。
此时如果任务执行失败,error日志内容为
sudo: no tty present and no askpass program specified
那么此时要使你启动hera项目的用户具有sudo -u hera的权限(无须输入root密码,即可执行sudo -u hera echo 1 ,具体可以在sudo visudo中配置)。
比如我启动hera的用户是wyr
那么首先在终端执行sudo visudo命令,此时会进入文本编辑
然后在后面追加一行
wyr ALL=(ALL) NOPASSWD:ALL
如下图:

root用户启动,即可跳过这段。
如果一切配置完成,那么即可看到输出任务执行成功的日志。
开发中心,顾名思义。我们进行开发的地方(当然我们也可以直接在调度中心加任务,建议任务首先在开发中心测试,通过之后再加到调度中心)。
***项目地址:[email protected]:scxwhite/hera.git ***
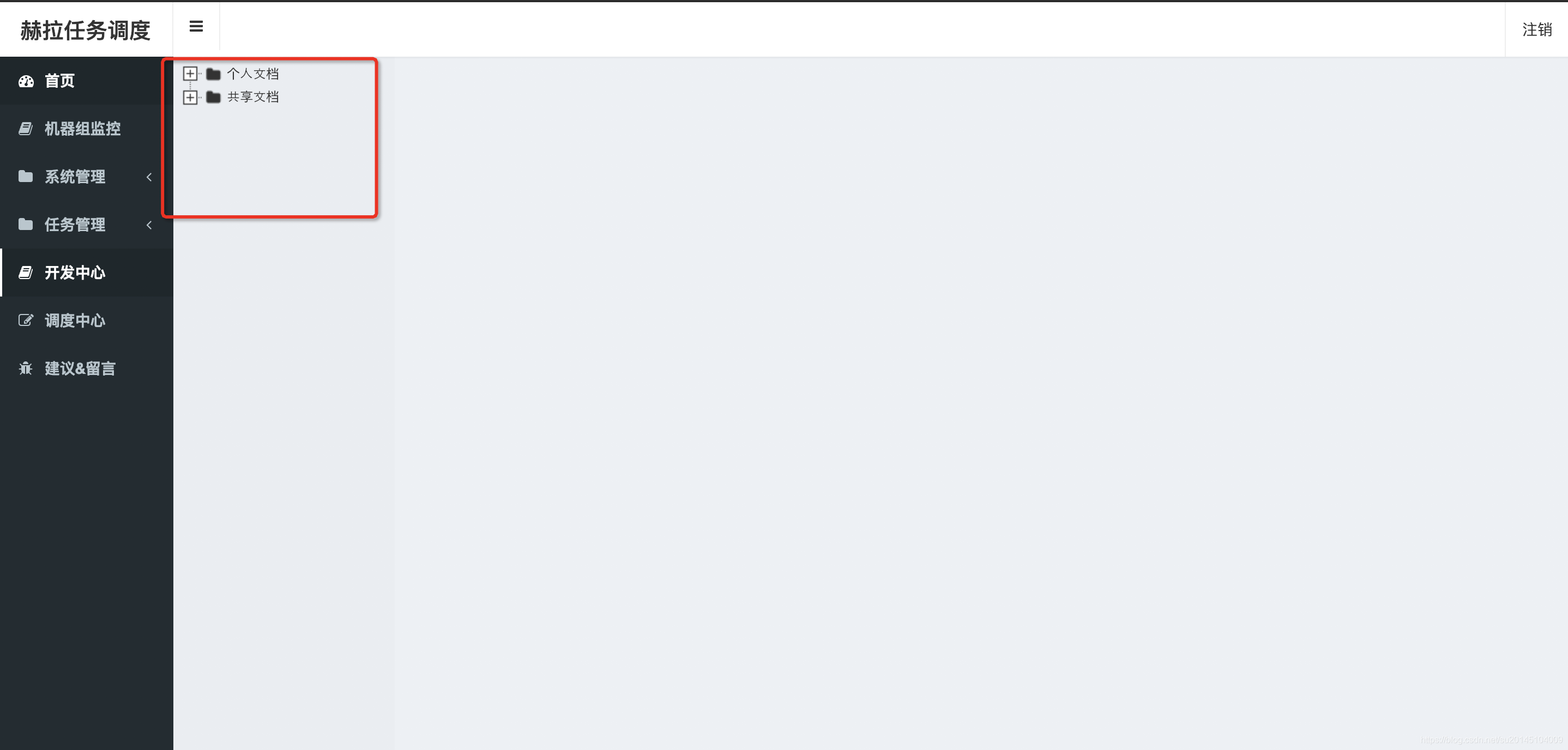
个人文档、共享文档。这两个文件夹不允许删除。
- 个人文档 提供给账户登录者使用的,私人目录可以在这里创建,执行任务时的用户,以创建者为准
- 共享文档 文件夹内的脚本对所有用户可见,执行时任务的用户以实际的登录者为准
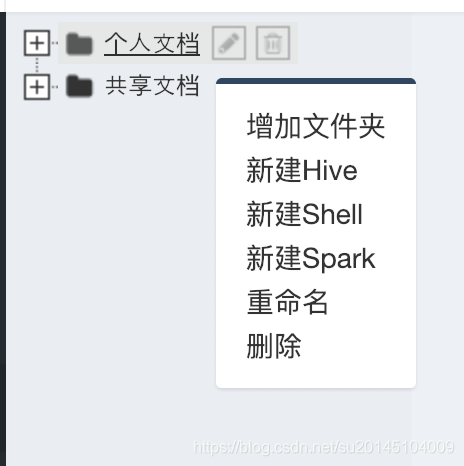
鼠标放在个人中心,然后点击鼠标右键选择新建shell脚本。
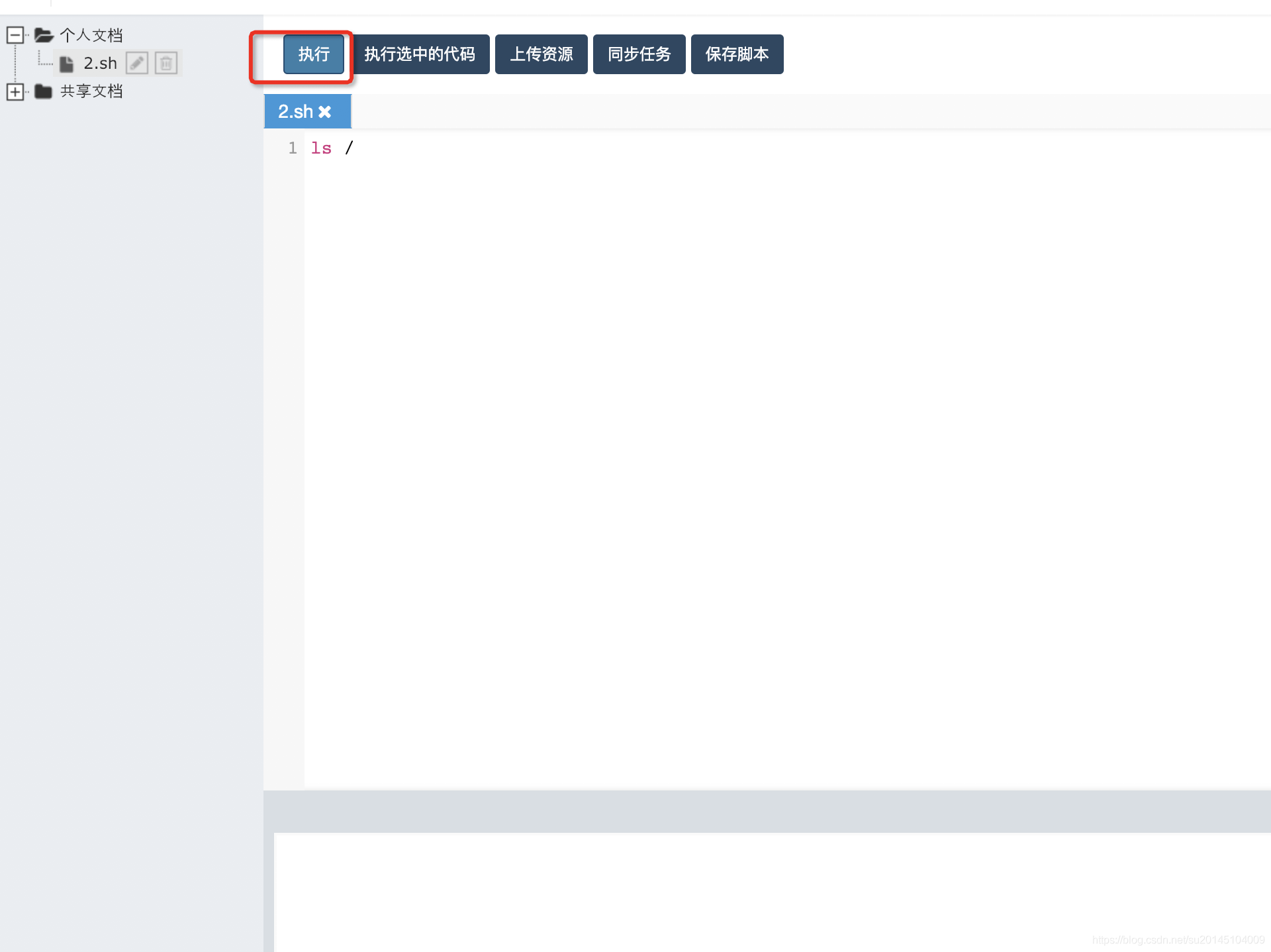
然后在编辑区写入要执行的脚本内容点击执行即可
此时在编辑区下方会有当前执行任务的日志信息输出
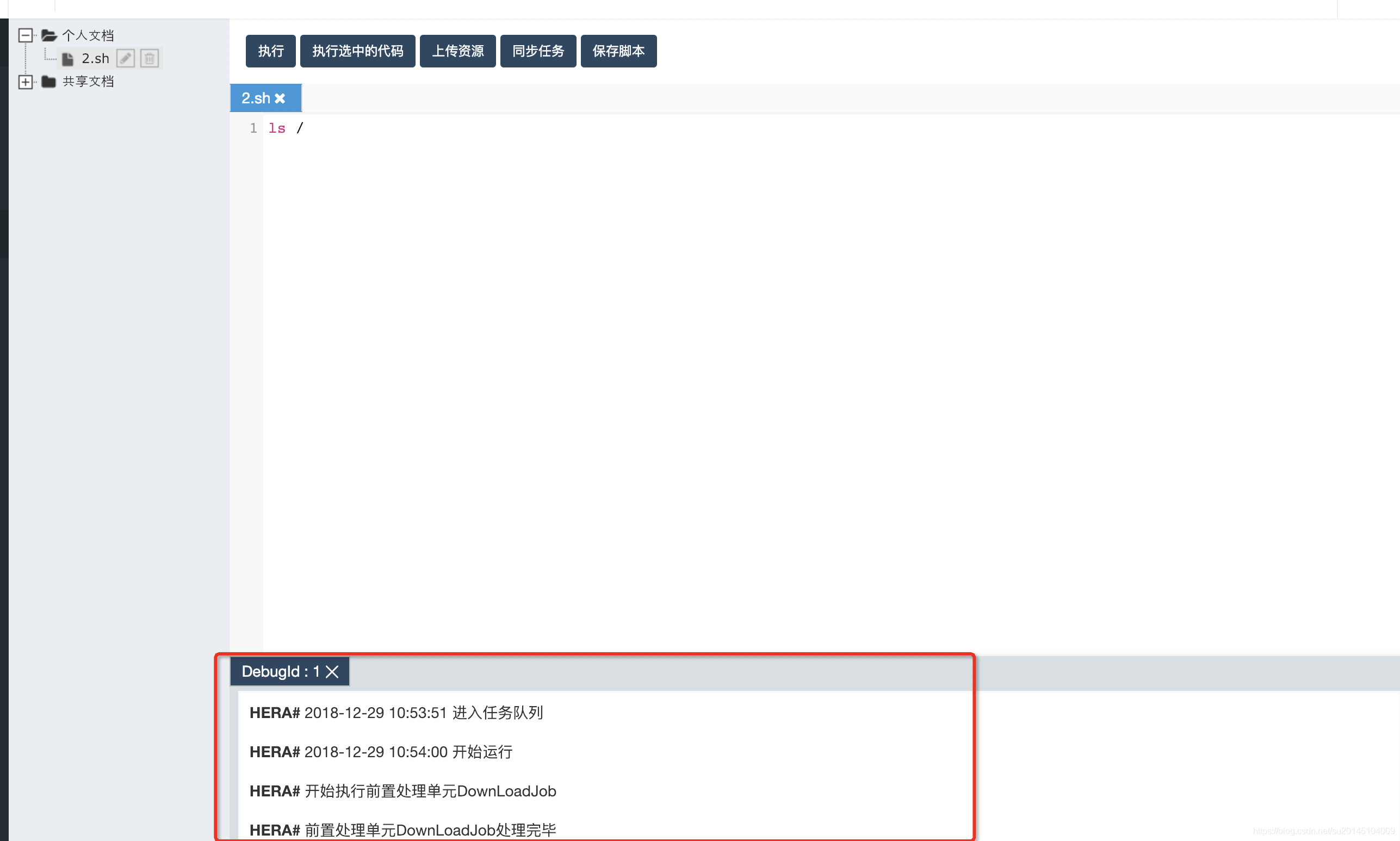
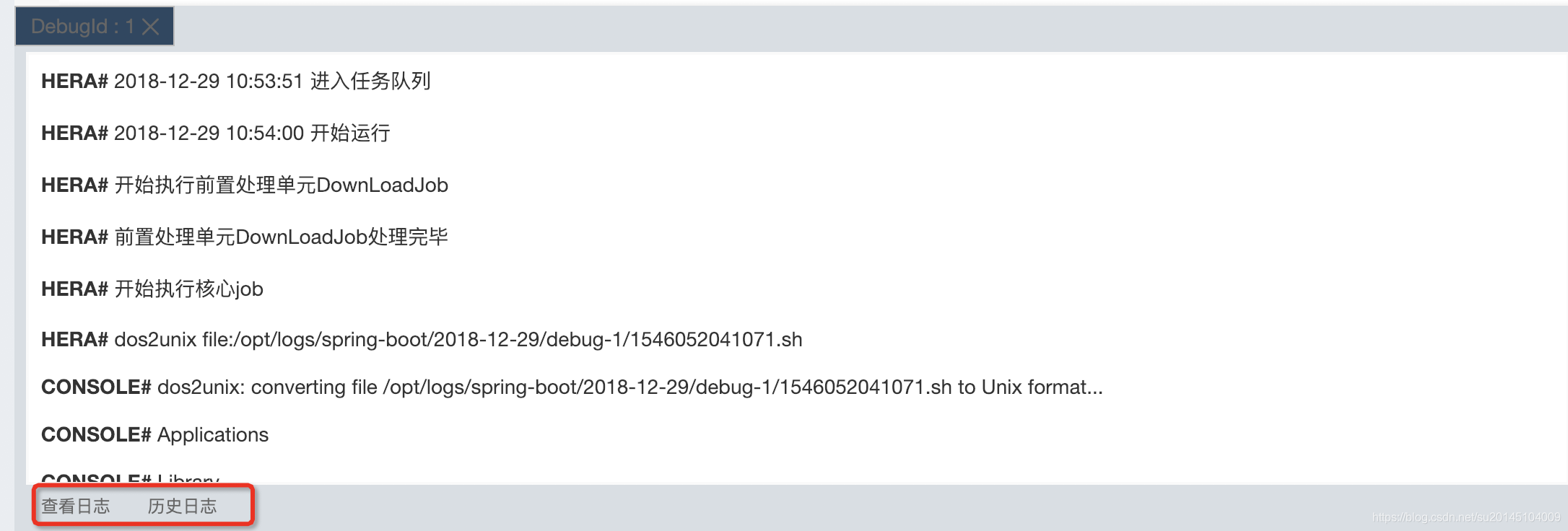
当然也可以通过点击下方历史日志看所有日志信息。
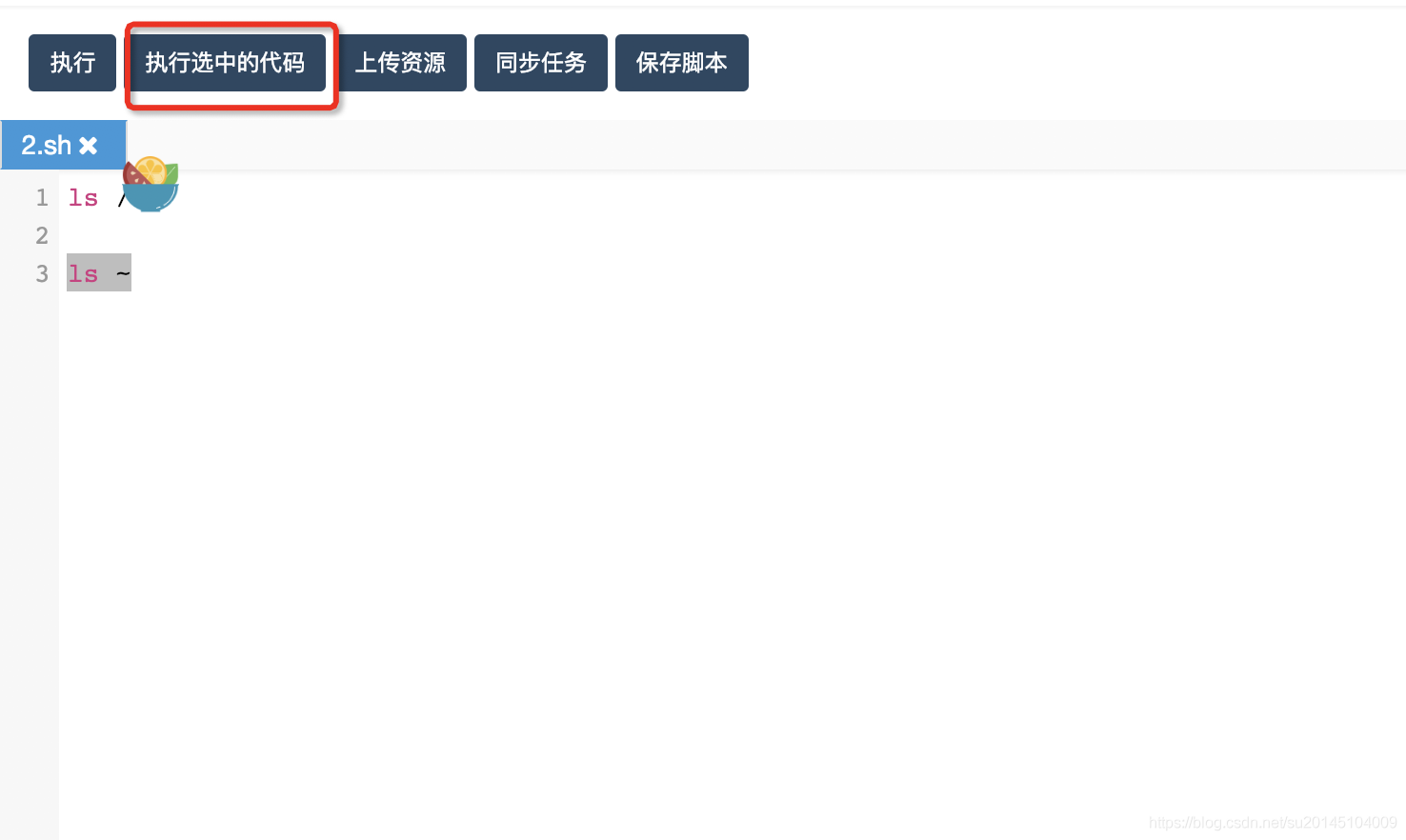
我们可以通过在编辑区使用鼠标选中我们要执行的代码,然后点击执行选中代码即可
当需要上传资源(py, jar, sql, hive, sh, js, txt, png, jpg, gif等等)时要注意,要保证我们的master和work有hadoop环境,能够执行hadoop fs -copyFromLocal命令。
上传完资源后。
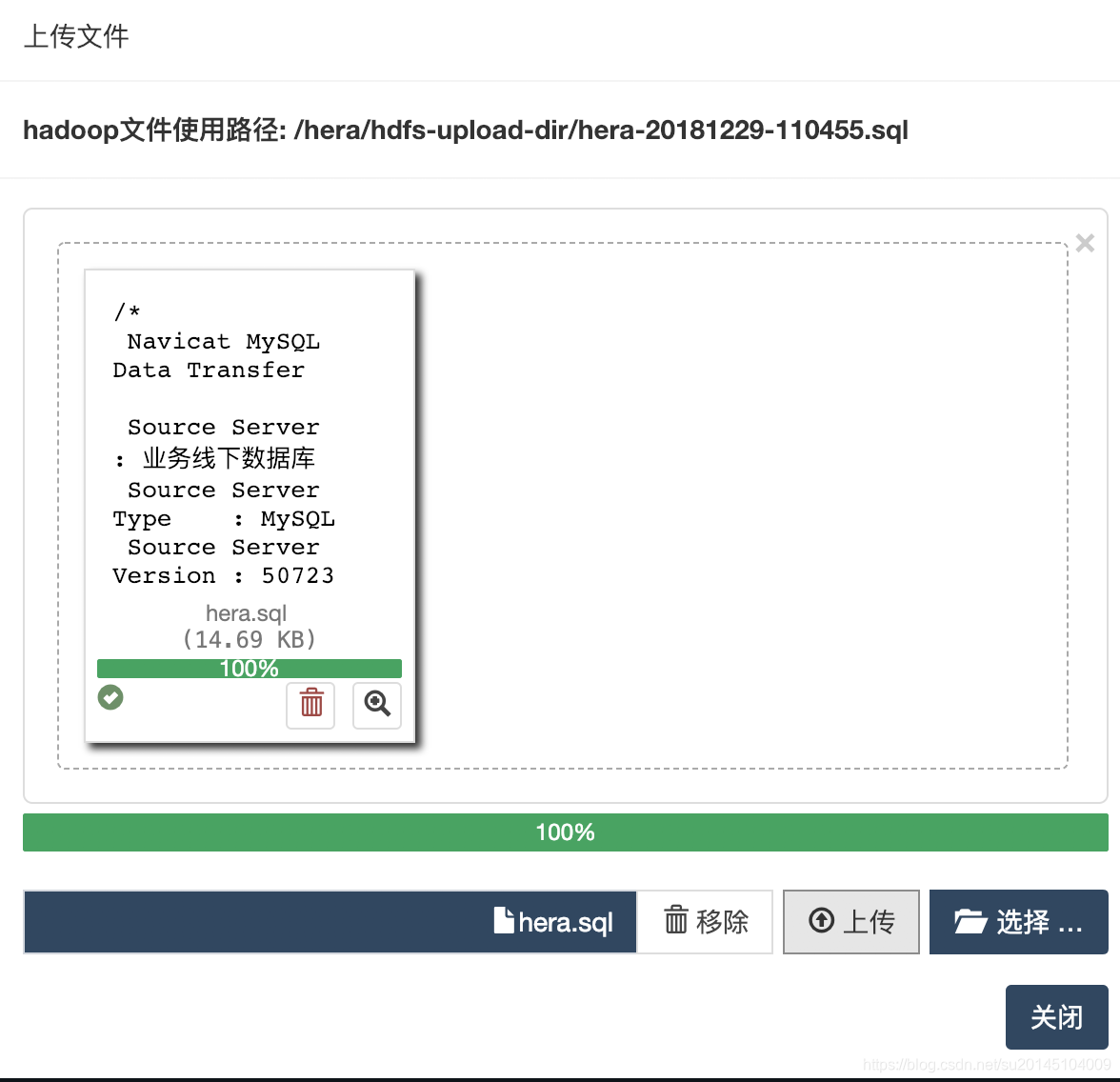
最上方会返回该资源文件的使用地址。
/hera/hdfs-upload-dir/hera-20181229-110455.sql
如果我们是使用spark-submit 或者hive udf 的 add jar 命令,直接加上hadoop路径即可。
比如:
add jar hdfs:///hera/hive_custom_udf/2dfire-hivemr-log.jar;或者:
spark2-submit --class com.dfire.start.App \
--jars hdfs:///spark-jars/common/binlog-hbase-1.1.jar \
当然如果是一些python脚本,或者txt。我们需要下载下来执行的。就需要执行
download[hdfs:///hera/hdfs-upload-dir/hera-20181229-110455.sql hera.sql]
启动download为hera的定制命令。[]分为两部分,使用空格分开。空格左部分为hdfs文件的路径,空格右部分为重命名后的文件名。

暂未开发
当在开发中心写脚本时,脚本会自动保存。当然也可以通过点击保存脚本进行手动保存。
使用Spark需要自行选择Spark版本,并部署在worker上,具体部署方法和示例之后会整理给出。