-
Notifications
You must be signed in to change notification settings - Fork 84
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
feat(module: eks-monitoring) Add NVIDIA gpu monitoring dashboards (#257)
* gpu dashboards * fixing locals * doc start * Update gpumon.md * fixing typos and doc names * fixing module name * fixing mkdocs * gpu to nvidia * Apply pre-commit --------- Co-authored-by: Rodrigue Koffi <[email protected]>
- Loading branch information
1 parent
d8b3067
commit ada16d5
Showing
7 changed files
with
95 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,38 @@ | ||
| # Monitoring NVIDIA GPU Workloads | ||
|
|
||
| GPUs play an integral part in data intensive workloads. The eks-monitoring module of the Observability Accelerator provides the ability to deploy the NVIDIA DCGM Exporter Dashboard. | ||
| The dashboard utilizes metrics scraped from the `/metrics` endpoint that are exposed when running the nvidia gpu operator with the [DCGM exporter](https://developer.nvidia.com/blog/monitoring-gpus-in-kubernetes-with-dcgm/) and NVSMI binary. | ||
|
|
||
| !!!note | ||
| In order to make use of this dashboard, you will need to have a GPU backed EKS cluster and deploy the [GPU operator](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/amazon-eks.html) | ||
| The recommended way of deploying the GPU operator is the [Data on EKS Blueprint](https://github.com/aws-ia/terraform-aws-eks-data-addons/blob/main/nvidia-gpu-operator.tf) | ||
|
|
||
| ## Deployment | ||
|
|
||
| This is enabled by default in the [eks-monitoring module](https://aws-observability.github.io/terraform-aws-observability-accelerator/eks/). | ||
|
|
||
| ## Dashboards | ||
|
|
||
| In order to start producing diagnostic metrics you must first deploy the nvidia SMI binary. nvidia-smi (also NVSMI) provides monitoring and management capabilities for each of NVIDIA’s devices from Fermi and higher architecture families. We can now deploy the nvidia-smi binary, which shows diagnostic information about all GPUs visible to the container: | ||
|
|
||
| ``` | ||
| cat << EOF | kubectl apply -f - | ||
| apiVersion: v1 | ||
| kind: Pod | ||
| metadata: | ||
| name: nvidia-smi | ||
| spec: | ||
| restartPolicy: OnFailure | ||
| containers: | ||
| - name: nvidia-smi | ||
| image: "nvidia/cuda:11.0.3-base-ubuntu20.04" | ||
| args: | ||
| - "nvidia-smi" | ||
| resources: | ||
| limits: | ||
| nvidia.com/gpu: 1 | ||
| EOF | ||
| ``` | ||
| After producing the metrics they should populate the DCGM exporter dashboard: | ||
|
|
||
| 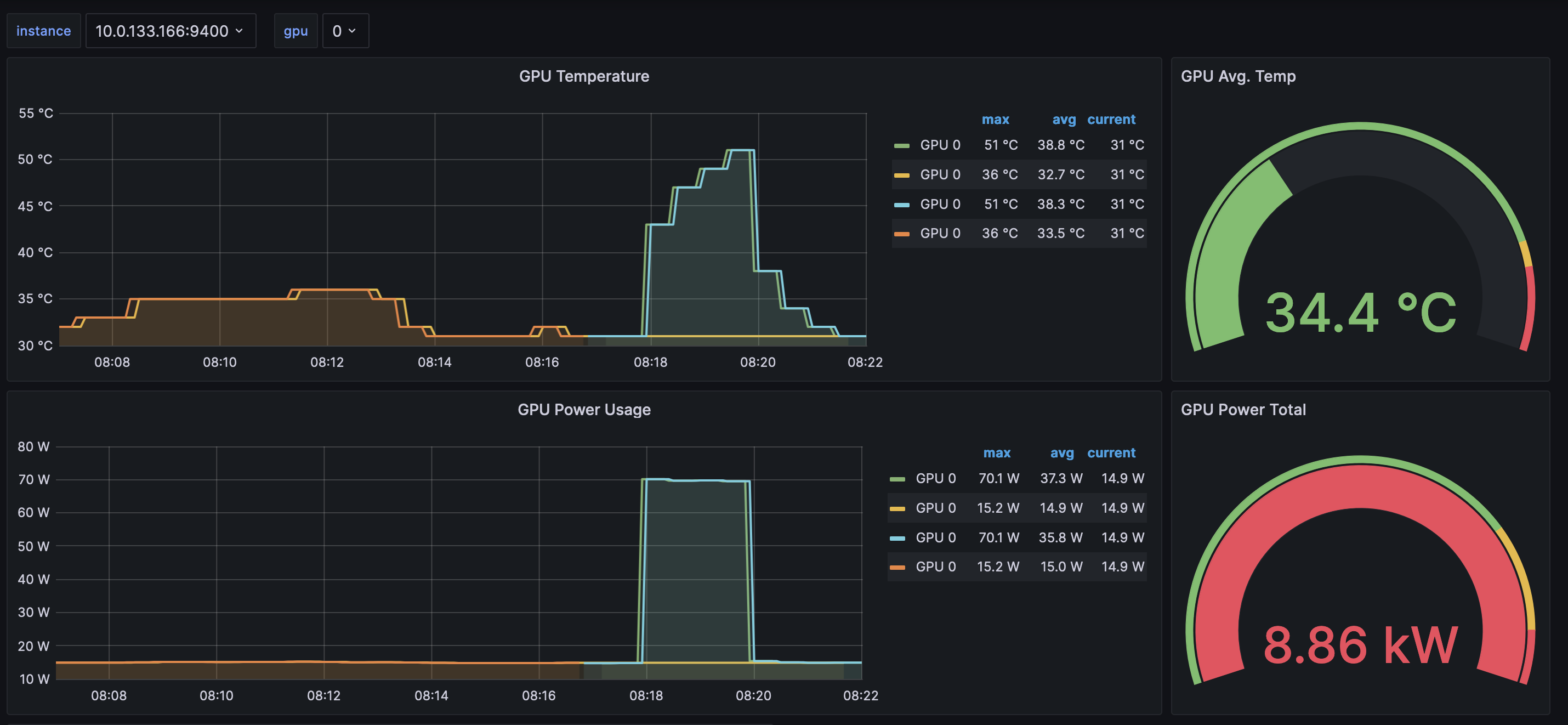 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters