
apify NPM package.
It can be used either stand-alone in your own applications
or in actors
running on the Apify Cloud.
- Motivation
- Overview
- Getting started
- What is an "actor"?
- Examples
- Environment variables
- Data storage
- Puppeteer live view
- Support
- Contributing
- License
- Acknowledgments
Thanks to tools like Puppeteer or cheerio, it is easy to write Node.js code to extract data from web pages. But eventually things will get complicated. For example, when you try to:
- Perform a deep crawl of an entire website using a persistent queue of URLs.
- Run your scraping code on a list of 100k URLs in a CSV file, without losing any data when your code crashes.
- Rotate proxies to hide your browser origin.
- Schedule the code to run periodically and send notification on errors.
- Disable browser fingerprinting protections used by websites.
Python has Scrapy for these tasks, but there was no such library for JavaScript, the language of the web. The use of JavaScript is natural, since the same language is used to write the scripts as well as the data extraction code running in a browser.
The goal of the Apify SDK is to fill this gap and provide a toolbox for generic web scraping, crawling and automation tasks in JavaScript. So don't reinvent the wheel every time you need data from the web, and focus on writing code specific to the target website, rather than developing commonalities.
The Apify SDK is available as the apify NPM package and it provides the following tools:
-
BasicCrawler- Provides a simple framework for the parallel crawling of web pages whose URLs are fed either from a static list or from a dynamic queue of URLs. This class serves as a base for more complex crawlers (see below). -
CheerioCrawler- Enables the parallel crawling of a large number of web pages using the cheerio HTML parser. This is the most efficient web crawler, but it does not work on websites that require JavaScript. -
PuppeteerCrawler- Enables the parallel crawling of a large number of web pages using the headless Chrome browser and Puppeteer. The pool of Chrome browsers is automatically scaled up and down based on available system resources. -
PuppeteerPool- Provides web browser tabs for user jobs from an automatically-managed pool of Chrome browser instances, with configurable browser recycling and retirement policies. Supports reuse of the disk cache to speed up the crawling of websites and reduce proxy bandwidth. -
RequestList- Represents a list of URLs to crawl. The URLs can be passed in code or in a text file hosted on the web. The list persists its state so that crawling can resume when the Node.js process restarts. -
RequestQueue- Represents a queue of URLs to crawl, which is stored either on a local filesystem or in the Apify Cloud. The queue is used for deep crawling of websites, where you start with several URLs and then recursively follow links to other pages. The data structure supports both breadth-first and depth-first crawling orders. -
Dataset- Provides a store for structured data and enables their export to formats like JSON, JSONL, CSV, XML, Excel or HTML. The data is stored on a local filesystem or in the Apify Cloud. Datasets are useful for storing and sharing large tabular crawling results, such as a list of products or real estate offers. -
KeyValueStore- A simple key-value store for arbitrary data records or files, along with their MIME content type. It is ideal for saving screenshots of web pages, PDFs or to persist the state of your crawlers. The data is stored on a local filesystem or in the Apify Cloud. -
AutoscaledPool- Runs asynchronous background tasks, while automatically adjusting the concurrency based on free system memory and CPU usage. This is useful for running web scraping tasks at the maximum capacity of the system. -
PuppeteerUtils- Provides several helper functions useful for web scraping. For example, to inject jQuery into web pages or to hide browser origin. - Additionally, the package provides various helper functions to simplify running your code on the Apify Cloud and thus take advantage of its pool of proxies, job scheduler, data storage, etc. For more information, see the Apify SDK Programmer's Reference.
The Apify SDK requires Node.js 8 or later.
Add Apify SDK to any Node.js project by running:
npm install apify --saveRun the following example to perform a recursive crawl of a website using Puppeteer.
const Apify = require('apify');
Apify.main(async () => {
const requestQueue = await Apify.openRequestQueue();
await requestQueue.addRequest(new Apify.Request({ url: 'https://www.iana.org/' }));
const pseudoUrls = [new Apify.PseudoUrl('https://www.iana.org/[.*]')];
const crawler = new Apify.PuppeteerCrawler({
requestQueue,
handlePageFunction: async ({ request, page }) => {
const title = await page.title();
console.log(`Title of ${request.url}: ${title}`);
await Apify.utils.puppeteer.enqueueLinks(page, 'a', pseudoUrls, requestQueue);
},
maxRequestsPerCrawl: 100,
maxConcurrency: 10,
});
await crawler.run();
});When you run the example, you should see Apify SDK automating several Chrome browsers.

By default, Apify SDK stores data to
./apify_storage in the current working directory.
You can override this behavior by setting either the
APIFY_LOCAL_STORAGE_DIR or APIFY_TOKEN environment variable.
For details, see Environment variables
and Data storage.
To avoid the need to set the environment variables manually, to create a boilerplate of your project, and to enable pushing and running your code on the Apify Cloud, you can use the Apify command-line interface (CLI) tool.
Install the CLI by running:
npm -g install apify-cliYou might need to run the above command with sudo, depending on how crazy your configuration is.
Now create a boilerplate of your new web crawling project by running:
apify create my-hello-worldThe CLI will prompt you to select a project boilerplate template - just pick "Hello world".
The tool will create a directory called my-hello-world with a Node.js project files.
You can run the project as follows:
cd my-hello-world
apify runBy default, the crawling data will be stored in a local directory at ./apify_storage.
For example, the input JSON file for the actor is expected to be in the default key-value store
in ./apify_storage/key_value_stores/default/INPUT.json.
Now you can easily deploy your code to the Apify Cloud by running:
apify login
apify pushYour script will be uploaded to the Apify Cloud and built there so that it can be run. For more information, view the Apify CLI and Apify Actor documentation.
You can also develop your web scraping project in an online code editor directly on the Apify Cloud. You'll need to have an Apify Account. Go to Actors page in the app, click Create new and then go to the Source tab and start writing your code or paste one of the code examples below.
For more information, view the Apify actors quick start guide.
When you deploy your script to the Apify Cloud, it becomes an actor. An actor is a serverless microservice that accepts an input and produces an output. It can run for a few seconds, hours or even infinitely. An actor can perform anything from a simple action such as filling out a web form or sending an email, to complex operations such as crawling an entire website and removing duplicates from a large dataset.
To run an actor, you need to have an Apify Account. Actors can be shared in the Apify Library so that other people can use them. But don't worry, if you share your actor in the library and somebody uses it, it runs under their account, not yours.
Related links
An example is better than a thousand words. In the following sections you will find several examples of how to perform various web scraping and automation tasks using the Apify SDK. All the examples can be found in the examples directory in the repository.
To run the examples, just copy them into the directory where you installed the Apify SDK using
npm install apify and then run them by calling, for example:
node basic_crawler.js
Note that for production projects you should set either the APIFY_LOCAL_STORAGE_DIR or APIFY_TOKEN environment variable in order
to tell the SDK how to store its data and crawling state. For details, see
Environment variables and Data storage.
Alternatively, if you're using the Apify CLI,
you can copy and paste the source code of each of the examples into the main.js
file created by the CLI. Then go to the project directory and run the example using:
apify run
This is the most basic example of the Apify SDK, which demonstrates some of its
elementary tools, such as the
BasicCrawler
and RequestList classes.
The script just downloads several web pages with plain HTTP requests (using the
request-promise library)
and stores their raw HTML and URL to the default dataset.
In local configuration, the data will be stored as JSON files in ./apify_storage/datasets/default.
const Apify = require('apify');
const requestPromise = require('request-promise');
// Apify.main() function wraps the crawler logic (it is optional).
Apify.main(async () => {
// Create and initialize an instance of the RequestList class that contains
// a list of URLs to crawl. Here we use just a few hard-coded URLs.
const requestList = new Apify.RequestList({
sources: [
{ url: 'http://www.google.com/' },
{ url: 'http://www.example.com/' },
{ url: 'http://www.bing.com/' },
{ url: 'http://www.wikipedia.com/' },
],
});
await requestList.initialize();
// Create a BasicCrawler - the simplest crawler that enables
// users to implement the crawling logic themselves.
const crawler = new Apify.BasicCrawler({
// Let the crawler fetch URLs from our list.
requestList,
// This function will be called for each URL to crawl.
// The 'request' option is an instance of the Request class, which contains
// information such as URL and HTTP method, as supplied by the RequestList.
handleRequestFunction: async ({ request }) => {
console.log(`Processing ${request.url}...`);
// Fetch the page HTML
const html = await requestPromise(request.url);
// Store the HTML and URL to the default dataset.
await Apify.pushData({
url: request.url,
html,
});
},
});
// Run the crawler and wait for it to finish.
await crawler.run();
console.log('Crawler finished.');
});This example demonstrates how to use CheerioCrawler to crawl a list of URLs from an external file, load each URL using a plain HTTP request, parse the HTML using cheerio and extract some data from it: the page title and all H1 tags.
const Apify = require('apify');
// Apify.utils contains various utilities, e.g. for logging.
// Here we turn off the logging of unimportant messages.
const { log } = Apify.utils;
log.setLevel(log.LEVELS.WARNING);
// A link to a list of Fortune 500 companies' websites available on GitHub.
const CSV_LINK = 'https://gist.githubusercontent.com/hrbrmstr/ae574201af3de035c684/raw/f1000.csv';
// Apify.main() function wraps the crawler logic (it is optional).
Apify.main(async () => {
// Create an instance of the RequestList class that contains a list of URLs to crawl.
// Here we download and parse the list of URLs from an external file.
const requestList = new Apify.RequestList({
sources: [{ requestsFromUrl: CSV_LINK }],
});
await requestList.initialize();
// Create an instance of the CheerioCrawler class - a crawler
// that automatically loads the URLs and parses their HTML using the cheerio library.
const crawler = new Apify.CheerioCrawler({
// Let the crawler fetch URLs from our list.
requestList,
// The crawler downloads and processes the web pages in parallel, with a concurrency
// automatically managed based on the available system memory and CPU (see AutoscaledPool class).
// Here we define some hard limits for the concurrency.
minConcurrency: 10,
maxConcurrency: 50,
// On error, retry each page at most once.
maxRequestRetries: 1,
// Increase the timeout for processing of each page.
handlePageTimeoutSecs: 60,
// This function will be called for each URL to crawl.
// It accepts a single parameter, which is an object with the following fields:
// - request: an instance of the Request class with information such as URL and HTTP method
// - html: contains raw HTML of the page
// - $: the cheerio object containing parsed HTML
handlePageFunction: async ({ request, html, $ }) => {
console.log(`Processing ${request.url}...`);
// Extract data from the page using cheerio.
const title = $('title').text();
const h1texts = [];
$('h1').each((index, el) => {
h1texts.push({
text: $(el).text(),
});
});
// Store the results to the default dataset. In local configuration,
// the data will be stored as JSON files in ./apify_storage/datasets/default
await Apify.pushData({
url: request.url,
title,
h1texts,
html,
});
},
// This function is called if the page processing failed more than maxRequestRetries+1 times.
handleFailedRequestFunction: async ({ request }) => {
console.log(`Request ${request.url} failed twice.`);
},
});
// Run the crawler and wait for it to finish.
await crawler.run();
console.log('Crawler finished.');
});This example demonstrates how to use PuppeteerCrawler
in combination with RequestList
and RequestQueue to recursively scrape the
Hacker News website using headless Chrome / Puppeteer.
The crawler starts with a single URL, finds links to next pages,
enqueues them and continues until no more desired links are available.
The results are stored to the default dataset. In local configuration, the results are represented as JSON files in ./apify_storage/datasets/default
const Apify = require('apify');
Apify.main(async () => {
// Create and initialize an instance of the RequestList class that contains the start URL.
const requestList = new Apify.RequestList({
sources: [
{ url: 'https://news.ycombinator.com/' },
],
});
await requestList.initialize();
// Apify.openRequestQueue() is a factory to get a preconfigured RequestQueue instance.
const requestQueue = await Apify.openRequestQueue();
// Create an instance of the PuppeteerCrawler class - a crawler
// that automatically loads the URLs in headless Chrome / Puppeteer.
const crawler = new Apify.PuppeteerCrawler({
// The crawler will first fetch start URLs from the RequestList
// and then the newly discovered URLs from the RequestQueue
requestList,
requestQueue,
// Run Puppeteer in headless mode. If you set headless to false, you'll see the scraping
// browsers showing up on your screen. This is great for debugging.
launchPuppeteerOptions: { headless: true },
// This function will be called for each URL to crawl.
// Here you can write the Puppeteer scripts you are familiar with,
// with the exception that browsers and pages are automatically managed by the Apify SDK.
// The function accepts a single parameter, which is an object with the following fields:
// - request: an instance of the Request class with information such as URL and HTTP method
// - page: Puppeteer's Page object (see https://pptr.dev/#show=api-class-page)
handlePageFunction: async ({ request, page }) => {
console.log(`Processing ${request.url}...`);
// A function to be evaluated by Puppeteer within the browser context.
const pageFunction = ($posts) => {
const data = [];
// We're getting the title, rank and URL of each post on Hacker News.
$posts.forEach(($post) => {
data.push({
title: $post.querySelector('.title a').innerText,
rank: $post.querySelector('.rank').innerText,
href: $post.querySelector('.title a').href,
});
});
return data;
};
const data = await page.$$eval('.athing', pageFunction);
// Store the results to the default dataset.
await Apify.pushData(data);
// Find the link to the next page using Puppeteer functions.
let nextHref;
try {
nextHref = await page.$eval('.morelink', el => el.href);
} catch (err) {
console.log(`${request.url} is the last page!`);
return;
}
// Enqueue the link to the RequestQueue
await requestQueue.addRequest(new Apify.Request({ url: nextHref }));
},
// This function is called if the page processing failed more than maxRequestRetries+1 times.
handleFailedRequestFunction: async ({ request }) => {
console.log(`Request ${request.url} failed too many times`);
},
});
// Run the crawler and wait for it to finish.
await crawler.run();
console.log('Crawler finished.');
});This example demonstrates how to read and write
data to the default key-value store using
Apify.getValue()
and
Apify.setValue().
The script crawls a list of URLs using Puppeteer,
captures a screenshot of each page and saves it to the store. The list of URLs is
provided as actor input that is also read from the store.
In local configuration, the input is stored in the default key-value store's directory as a JSON file at
./apify_storage/key_value_stores/default/INPUT.json. You need to create the file and set it with the following content:
{ "sources": [{ "url": "https://www.google.com" }, { "url": "https://www.duckduckgo.com" }] }On the Apify Cloud, the input can be either set manually in the UI app or passed as the POST payload to the Run actor API call. For more details, see Input and output in the Apify Actor documentation.
const Apify = require('apify');
Apify.main(async () => {
// Read the actor input configuration containing the URLs for the screenshot.
// By convention, the input is present in the actor's default key-value store under the "INPUT" key.
const input = await Apify.getValue('INPUT');
if (!input) throw new Error('Have you passed the correct INPUT ?');
const { sources } = input;
const requestList = new Apify.RequestList({ sources });
await requestList.initialize();
const crawler = new Apify.PuppeteerCrawler({
requestList,
handlePageFunction: async ({ page, request }) => {
console.log(`Processing ${request.url}...`);
// This is a Puppeteer function that takes a screenshot of the page and returns its buffer.
const screenshotBuffer = await page.screenshot();
// The record key may only include the following characters: a-zA-Z0-9!-_.'()
const key = request.url.replace(/[:/]/g, '_');
// Save the screenshot. Choosing the right content type will automatically
// assign the local file the right extension, in this case .png.
// The screenshots will be stored in ./apify_storage/key_value_stores/default/
await Apify.setValue(key, screenshotBuffer, { contentType: 'image/png' });
console.log(`Screenshot of ${request.url} saved.`);
},
});
// Run crawler.
await crawler.run();
console.log('Crawler finished.');
});This example demonstrates how to load pages in headless Chrome / Puppeteer
over Apify Proxy.
To make it work, you'll need an Apify Account
that has access to the proxy.
The proxy password is available on the Proxy page in the app.
Just set it to the APIFY_PROXY_PASSWORD environment variable
or run the script using the CLI.
const Apify = require('apify');
Apify.main(async () => {
// Apify.launchPuppeteer() is similar to Puppeteer's launch() function.
// It accepts the same parameters and returns a preconfigured Puppeteer.Browser instance.
// Moreover, it accepts several additional options, such as useApifyProxy.
const options = {
useApifyProxy: true,
};
const browser = await Apify.launchPuppeteer(options);
console.log('Running Puppeteer script...');
// Proceed with a plain Puppeteer script.
const page = await browser.newPage();
const url = 'https://en.wikipedia.org/wiki/Main_Page';
await page.goto(url);
const title = await page.title();
console.log(`Page title: ${title}`);
// Cleaning up after yourself is always good.
await browser.close();
console.log('Puppeteer closed.');
});This example demonstrates how to start an Apify actor using
Apify.call()
and how to call Apify API using
Apify.client.
The script extracts the current Bitcoin prices from Kraken.com
and sends them to your email using the apify/send-mail actor.
To make the example work, you'll need an Apify Account.
Go to Account - Integrations page to obtain your API token
and set it to the APIFY_TOKEN environment variable, or run the script using the CLI.
If you deploy this actor to the Apify Cloud then you can set up a scheduler for early
morning. Don't miss the chance of your life to get rich!
const Apify = require('apify');
Apify.main(async () => {
// Launch the web browser.
const browser = await Apify.launchPuppeteer();
console.log('Obtaining email address...');
const user = await Apify.client.users.getUser();
// Load Kraken.com charts and get last traded price of BTC
console.log('Extracting data from kraken.com...');
const page = await browser.newPage();
await page.goto('https://www.kraken.com/charts');
const tradedPricesHtml = await page.$eval('#ticker-top ul', el => el.outerHTML);
// Send prices to your email. For that, you can use an actor we already
// have available on the platform under the name: apify/send-mail.
// The second parameter to the Apify.call() invocation is the actor's
// desired input. You can find the required input parameters by checking
// the actor's documentation page: https://www.apify.com/apify/send-mail
console.log(`Sending email to ${user.email}...`);
await Apify.call('apify/send-mail', {
to: user.email,
subject: 'Kraken.com BTC',
html: `<h1>Kraken.com BTC</h1>${tradedPricesHtml}`,
});
console.log('Email sent. Good luck!');
});This example shows a quick actor that has a run time of just a few seconds. It opens a web page that contains a webcam stream from the Golden Gate Bridge, takes a screenshot of the page and saves it as output.
This actor can be invoked synchronously using a single HTTP request to directly obtain its output as a response, using the Run actor synchronously Apify API endpoint. The example is also shared as the apify/example-golden-gate-webcam actor in the Apify Library, so you can test it directly there simply by sending a POST request to https://api.apify.com/v2/acts/apify~example-golden-gate-webcam/run-sync?token=[YOUR_API_TOKEN]
const Apify = require('apify');
Apify.main(async () => {
// Launch web browser.
const browser = await Apify.launchPuppeteer();
// Load http://goldengatebridge75.org/news/webcam.html and get an IFRAME with the webcam stream
console.log('Opening web page...');
const page = await browser.newPage();
await page.goto('http://goldengatebridge75.org/news/webcam.html');
const iframe = (await page.frames()).pop();
// Get webcam image element handle.
const imageElementHandle = await iframe.$('.VideoColm img');
// Give the webcam image some time to load.
console.log('Waiting for page to load...');
await Apify.utils.sleep(3000);
// Get a screenshot of that image.
const imageBuffer = await imageElementHandle.screenshot();
console.log('Screenshot captured.');
// Save the screenshot as the actor's output. By convention, similarly to "INPUT",
// the actor's output is stored in the default key-value store under the "OUTPUT" key.
await Apify.setValue('OUTPUT', imageBuffer, { contentType: 'image/jpeg' });
console.log('Actor finished.');
});The following table shows the basic environment variables used by Apify SDK:
| Environment variable | Description |
|---|---|
APIFY_LOCAL_STORAGE_DIR |
Defines the path to a local directory where
key-value stores,
request lists
and request queues store their data.
Typically it is set to ./apify_storage.
If omitted, you should define
the APIFY_TOKEN environment variable instead.
|
APIFY_TOKEN |
The API token for your Apify Account. It is used to access the Apify API, e.g. to access cloud storage or to run an actor in the Apify Cloud.
You can find your API token on the Account - Integrations page.
If omitted, you should define the APIFY_LOCAL_STORAGE_DIR environment variable instead.
|
APIFY_PROXY_PASSWORD |
Optional password to Apify Proxy for IP address rotation. If you have have an Apify Account, you can find the password on the Proxy page in the Apify app. This feature is optional. You can use your own proxies or no proxies at all. |
APIFY_HEADLESS |
If set to 1, web browsers launched by Apify SDK will run in the headless
mode. You can still override this setting in the code, e.g. by
passing the headless: true option to the
Apify.launchPuppeteer()
function. But having this setting in an environment variable allows you to develop
the crawler locally in headful mode to simplify the debugging, and only run the crawler in headless
mode once you deploy it to the Apify Cloud.
By default, the browsers are launched in headful mode, i.e. with windows.
|
APIFY_LOG_LEVEL |
Specifies the minimum log level, which can be one of the following values (in order of severity):
DEBUG, INFO, WARNING, SOFT_FAIL and ERROR.
By default, the log level is set to INFO, which means that DEBUG messages
are not printed to console.
|
APIFY_MEMORY_MBYTES |
Sets the amount of system memory in megabytes to be used by the autoscaled pool. It is used to limit the number of concurrently running tasks. By default, the max amount of memory to be used is set to one quarter of total system memory, i. e. on a system with 8192 MB of memory, the autoscaling feature will only use up to 2048 MB of memory. |
For the full list of environment variables used by Apify SDK and the Apify Cloud, please see the Environment variables in the Apify actor documentation.
The Apify SDK has several data storage types that are useful for specific tasks.
The data is stored either on local disk to a directory defined by the APIFY_LOCAL_STORAGE_DIR environment variable,
or on the Apify Cloud under the user account identified by the API token defined by the APIFY_TOKEN environment variable.
If neither of these variables is defined, by default Apify SDK sets APIFY_LOCAL_STORAGE_DIR
to ./apify_storage in the current working directory and prints a warning.
Typically, you will be developing the code on your local computer and thus set the APIFY_LOCAL_STORAGE_DIR environment variable.
Once the code is ready, you will deploy it to the Apify Cloud, where it will automatically
set the APIFY_TOKEN environment variable and thus use cloud storage.
No code changes are needed.
Related links
The key-value store is used for saving and reading data records or files. Each data record is represented by a unique key and associated with a MIME content type. Key-value stores are ideal for saving screenshots of web pages, PDFs or to persist the state of crawlers.
Each actor run is associated with a default key-value store, which is created exclusively for the actor run.
By convention, the actor run input and output is stored in the default key-value store
under the INPUT and OUTPUT key, respectively. Typically the input and output is a JSON file,
although it can be any other format.
In the Apify SDK, the key-value store is represented by the
KeyValueStore
class.
In order to simplify access to the default key-value store, the SDK also provides
Apify.getValue()
and Apify.setValue() functions.
In local configuration, the data is stored in the directory specified by the APIFY_LOCAL_STORAGE_DIR environment variable as follows:
[APIFY_LOCAL_STORAGE_DIR]/key_value_stores/[STORE_ID]/[KEY].[EXT]
Note that [STORE_ID] is the name or ID of the key-value store.
The default key value store has ID default, unless you override it by setting the APIFY_DEFAULT_KEY_VALUE_STORE_ID
environment variable.
The [KEY] is the key of the record and [EXT] corresponds to the MIME content type of the
data value.
The following code demonstrates basic operations of key-value stores:
// Get actor input from the default key-value store
const input = await Apify.getValue('INPUT');
// Write actor output to the default key-value store.
await Apify.setValue('OUTPUT', { myResult: 123 });
// Open a named key-value store
const store = await Apify.openKeyValueStore('some-name');
// Write record. JavaScript object is automatically converted to JSON,
// strings and binary buffers are stored as they are
await store.setValue('some-key', { foo: 'bar' });
// Read record. Note that JSON is automatically parsed to a JavaScript object,
// text data returned as a string and other data is returned as binary buffer
const value = await store.getValue('some-key');
// Delete record
await store.delete('some-key');To see a real-world example of how to get the input from the key-value store, see the screenshots.js example.
Datasets are used to store structured data where each object stored has the same attributes, such as online store products or real estate offers. You can imagine a dataset as a table, where each object is a row and its attributes are columns. Dataset is an append-only storage - you can only add new records to it but you cannot modify or remove existing records.
When the dataset is stored in the Apify Cloud, you can export its data to the following formats: HTML, JSON, CSV, Excel, XML and RSS. The datasets are displayed on the actor run details page and in the Storage section in the Apify app. The actual data is exported using the Get dataset items Apify API endpoint. This way you can easily share crawling results.
Each actor run is associated with a default dataset, which is created exclusively for the actor run. Typically, it is used to store crawling results specific for the actor run. Its usage is optional.
In the Apify SDK, the dataset is represented by the
Dataset
class.
In order to simplify writes to the default dataset, the SDK also provides the
Apify.pushData() function.
In local configuration, the data is stored in the directory specified by the APIFY_LOCAL_STORAGE_DIR environment variable as follows:
[APIFY_LOCAL_STORAGE_DIR]/datasets/[DATASET_ID]/[INDEX].json
Note that [DATASET_ID] is the name or ID of the dataset.
The default dataset has ID default, unless you override it by setting the APIFY_DEFAULT_DATASET_ID
environment variable.
Each dataset item is stored as a separate JSON file,
where [INDEX] is a zero-based index of the item in the dataset.
The following code demonstrates basic operations of the dataset:
// Write a single row to the default dataset
await Apify.pushData({ col1: 123, col2: 'val2' });
// Open a named dataset
const dataset = await Apify.openDataset('some-name');
// Write a single row
await dataset.pushData({ foo: 'bar' });
// Write multiple rows
await dataset.pushData([
{ foo: 'bar2', col2: 'val2' },
{ col3: 123 },
]);To see how to use the dataset to store crawler results, see the cheerio_crawler.js example.
The request queue is a storage of URLs to crawl. The queue is used for the deep crawling of websites, where you start with several URLs and then recursively follow links to other pages. The data structure supports both breadth-first and depth-first crawling orders.
Each actor run is associated with a default request queue, which is created exclusively for the actor run. Typically, it is used to store URLs to crawl in the specific actor run. Its usage is optional.
In Apify SDK, the request queue is represented by the
RequestQueue
class.
In local configuration, the request queue data is stored in the directory specified by the APIFY_LOCAL_STORAGE_DIR environment variable as follows:
[APIFY_LOCAL_STORAGE_DIR]/request_queues/[QUEUE_ID]/[STATE]/[NUMBER].json
Note that [QUEUE_ID] is the name or ID of the request queue.
The default queue has ID default, unless you override it by setting the APIFY_DEFAULT_REQUEST_QUEUE_ID
environment variable.
Each request in the queue is stored as a separate JSON file,
where [STATE] is either handled or pending,
and [NUMBER] is an integer indicating the position of the request in the queue.
The following code demonstrates basic operations of the request queue:
// Open the default request queue associated with the actor run
const queue = await Apify.openRequestQueue();
// Open a named request queue
const queueWithName = await Apify.openRequestQueue('some-name');
// Enqueue few requests
await queue.addRequest(new Apify.Request({ url: 'http://example.com/aaa'}));
await queue.addRequest(new Apify.Request({ url: 'http://example.com/bbb'}));
await queue.addRequest(new Apify.Request({ url: 'http://example.com/foo/bar'}), { forefront: true });
// Get requests from queue
const request1 = await queue.fetchNextRequest();
const request2 = await queue.fetchNextRequest();
const request3 = await queue.fetchNextRequest();
// Mark a request as handled
await queue.markRequestHandled(request1);
// If processing fails then reclaim the request back to the queue, so that it's crawled again
await queue.reclaimRequest(request2);To see how to use the request queue with a crawler, see the puppeteer_crawler.js example.
Apify SDK enables the real-time view of launched Puppeteer browser instances and their open tabs, including screenshots of pages and snapshots of HTML. This is useful for debugging your crawlers that run in headless mode.
The live view dashboard is run on a web server that is started on a port specified
by the APIFY_CONTAINER_PORT environment variable (typically 4321).
To enable live view, pass the liveView: true option to
Apify.launchPuppeteer():
const browser = Apify.launchPuppeteer({ liveView: true });or to PuppeteerCrawler constructor as follows:
const crawler = new PuppeteerCrawler({
launchPuppeteerOptions: { liveView: true },
// other options
})To simplify debugging, you may also want to add the
{ slowMo: 300 } option to slow down all browser operation.
See Puppeteer documentation for details.
Once live view is enabled, you can open http://localhost:4321 and you will see a page like this:
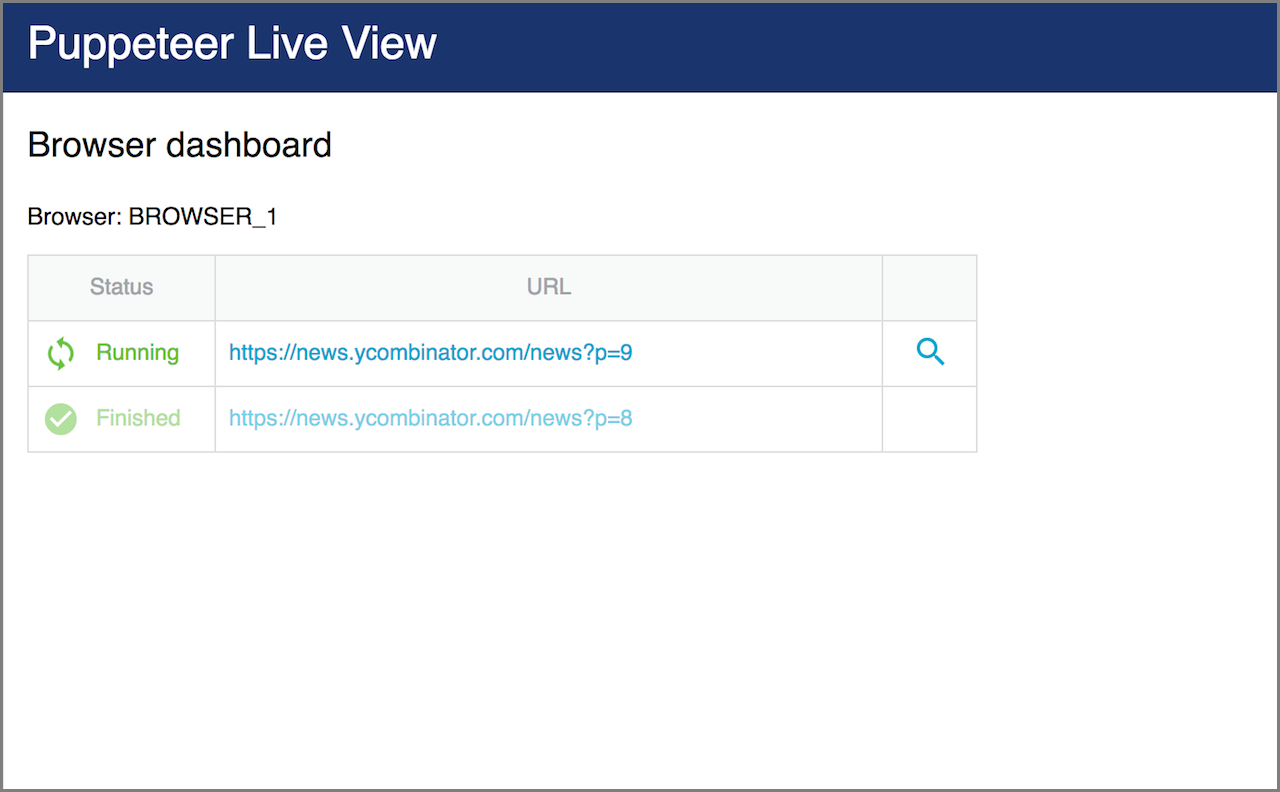
Click on the magnifying glass icon to view page detail, showing page screenshot and raw HTML:
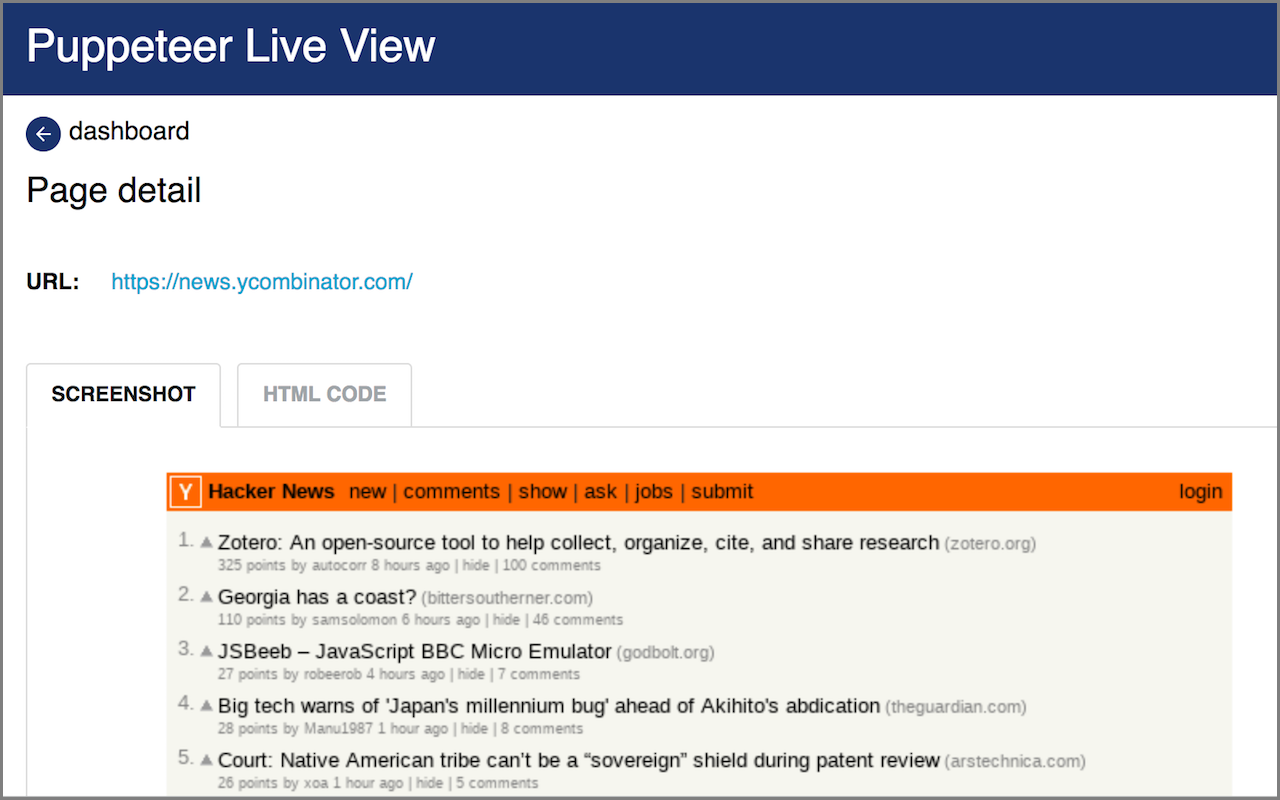
For more information, read the Debugging your actors with Live View article in Apify Knowlege Base.
If you find any bug or issue with the Apify SDK, please submit an issue on GitHub. For questions, you can ask on Stack Overflow or contact [email protected]
Your code contributions are welcome and you'll be praised to eternity! If you have any ideas for improvements, either submit an issue or create a pull request. For contribution guidelines and the code of conduct, see CONTRIBUTING.md.
This project is licensed under the Apache License 2.0 - see the LICENSE.md file for details.
Many thanks to Chema Balsas for giving up the apify package name
on NPM and renaming his project to jsdocify.