The objective of this assignment is to learn streaming of data from social media platform like Twitter and applying machine learning techniques like classification algorithms and pattern recognition using big data analytical tools like Apache Spark.
The task of this assignment was to perform sentiment analysis on stream of tweets using Apache spark and storing the results in CSV format. We were instructed to install Apache Spark on AWS however we installed it on Microsoft Azure. We are using python 2.7 for this assignment and Spark 2.3.1. We wrote python code to stream real time Twitter data into Microsoft Azure VM instance using Apache Spark. We then trained the model with labeled training data using MLlib (Apache Spark Machine Learning Library). Using the trained model we carried out sentiment analysis on the batches of streamed data to classify them into positive, negative or neutral. To avoid issues with our cloud instance we terminated the streaming process after analyzing 2000 tweets using our trained model.
We are using tweepy [1] to run a query and extract tweets. The tweets are fetched using Twitter Stream Listener. We are not cleaning the tweets and pushing it directly to the model. The model is trained using a training csv and then the model is fitted into the pipeline.
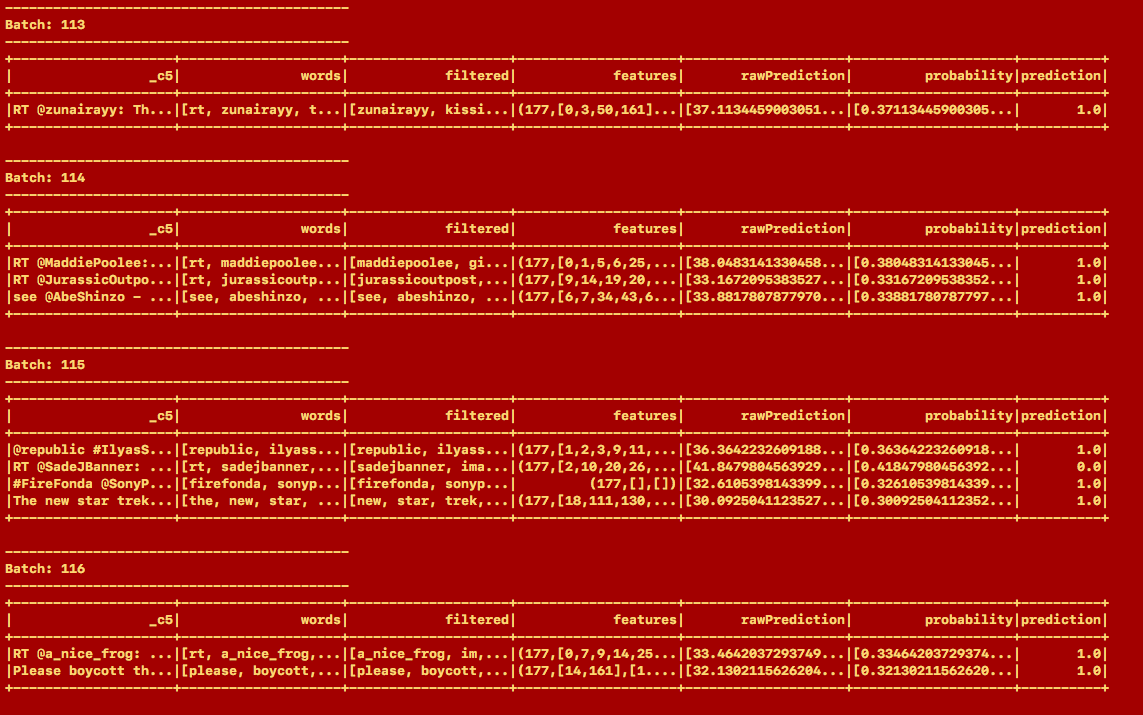
For this Assignment we have used RandomForestClassifier because from our analysis it gave us the maximum accuracy. We trained the model with 500 tweets and the accuracy is 57%. Despite our various attempts, we were not able to increase the accuracy of the model more than 57%. Since it is a classification problem, the model which was trained had 3 labels, making it a 3-class classification problem.
We already received labelled data to train our model. The data is available here [2]. The data is in a CSV format with mostly all the emojis removed. The file has 6 fields and 3 labels. the polarity of the tweet (0 = negative, 2 = neutral, 4 = positive).
We included tweets with relevant words as features and filtered irrelevant words.
add_stopwords = ["http","https","amp","rt","t","c","the","@"]
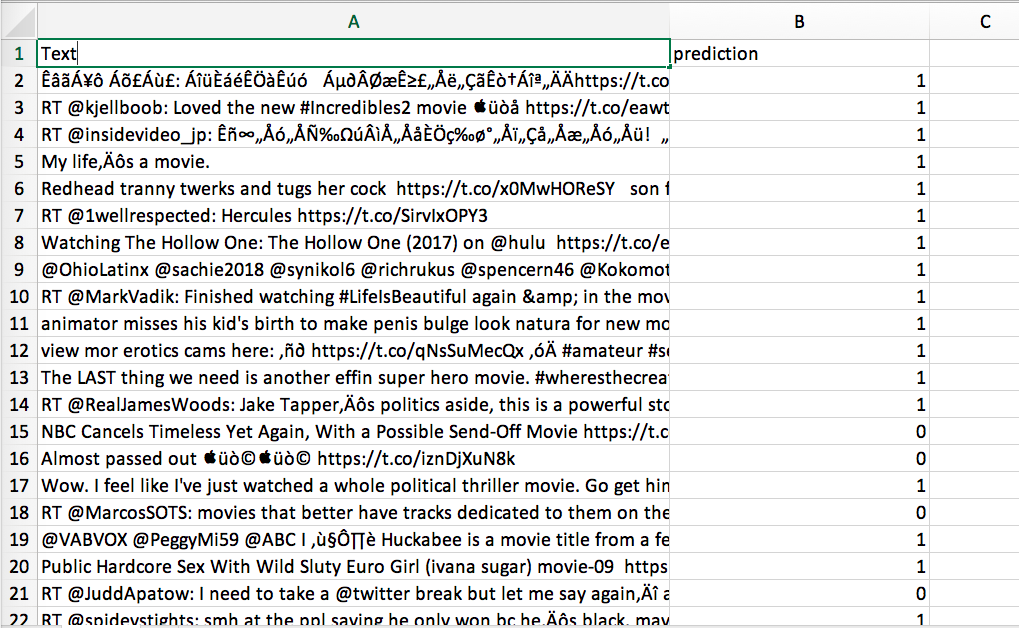
stopwordsRemover = StopWordsRemover(inputCol="words", outputCol="filtered").setStopWords(add_stopwords)The result after the completion of sentiment analysis is stored in a csv file containing tweets and the result. The result is in given in range 0 to 2 with positive, neutral and negative respectively.