Running Juicer on Amazon Web Services
You'll first need to create an account with Amazon Web Services.
Log in to your acount by clicking on the Sign in to the AWS Console button.
Click on EC2 - Virtual Servers in the Cloud.
Click the Launch Instance button.

Click the Community AMIs link and search for the AMI corresponding to your AWS region:
- ami-458fc22f (us-east-1)
- ami-03967083204a71d76 (us-west-2)
- ami-0cf958a247826ffa0 (us-east-2)
Then press the Select button.
If you cannot find the AMI, you can change your AWS region via the navbar.

You'll now need to choose an instance type. We recommend an instance with at least 8 vCPUs. Processing times will depend on the number of vCPUs and amount of memory. At minimum, we suggest the m3.2xlarge, though any instance with 8+ vCPUs will be fine. A GPU node (e.g. g2.8xlarge) is required for loop calling (HiCCUPS). To save costs, we suggest running the majority of juicer, including the building of a .hic file and Arrowhead, using a CPU instance (e.g. c3.8xlarge) and running just HiCCUPS loop calling on a GPU instance.
Disclaimer: Running EC2 has a cost by the hour - as long as the instance is running, you will be charged. Please make sure you understand Amazon's pricing policies before you start working with AWS.Click Next: Configure Instance Details to continue.

You now have the option to configure the instance. The defaults here are fine. Continue by clicking Next: Add Storage.

Unless you have a specific library size in mind, you should keep defaults for storage options. As a general guide, 1B PE reads will require about 5TB of storage. Continue by clicking Next: Tag Instance.

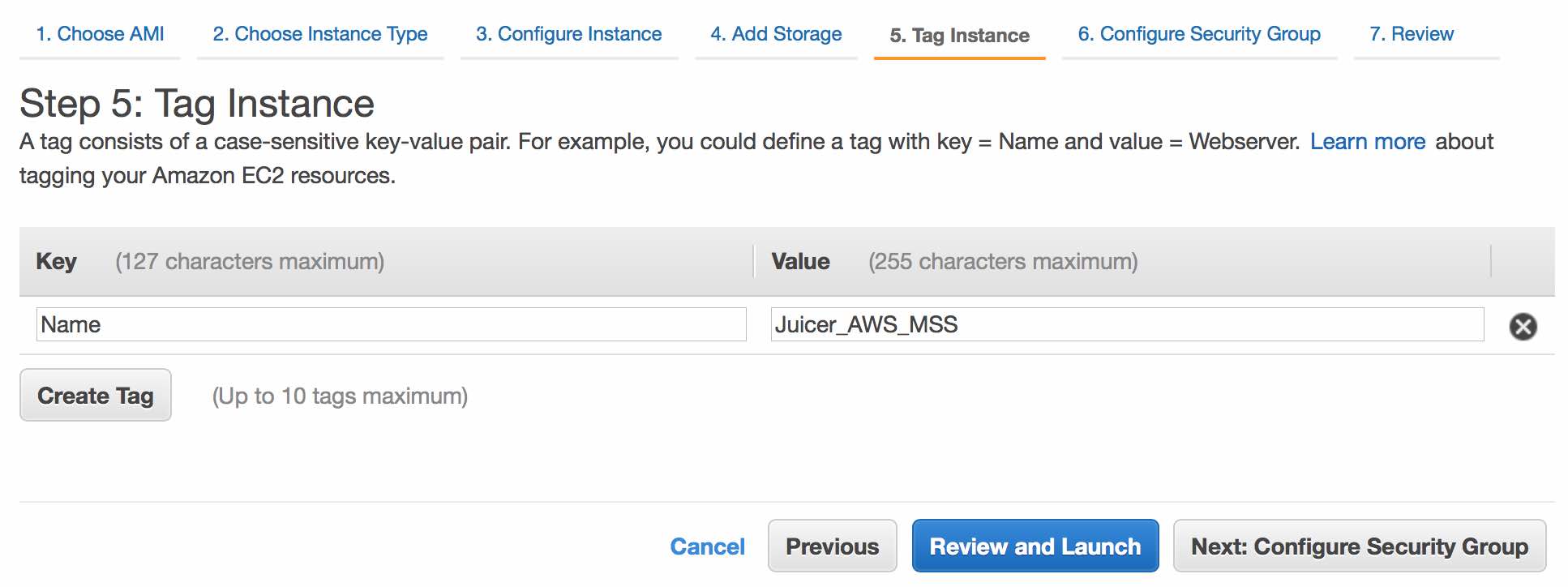
Name your instance (e.g. "Juicer_AWS"). Continue by clicking Next: Configure Security Group.
The default security rules are fine for now (although you can/should edit them later). Continue by clicking Review and Launch.

Review the settings, then click Launch.

Now you'll need to create a new key (e.g. "juicer_aws"). Download the key pair, and it should save the file to your Downloads folder. If the file is saved as a .pem.txt file, you can remove the .txt extension to make it a .pem file.
This file will act as a password of sorts, and should be saved in a secure location on your computer.
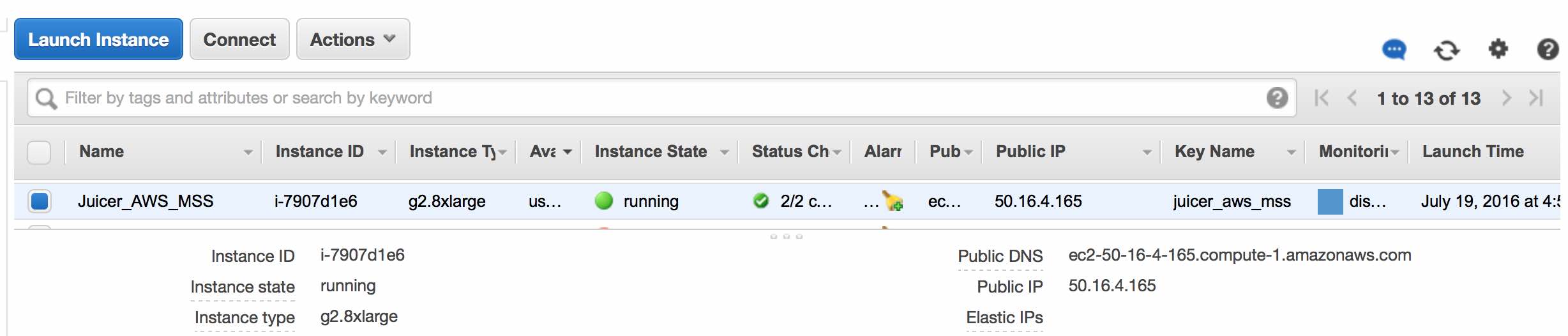
You should now click Launch Instances and see something like this:

Click View Instances to see details regarding your new instance.
AWS has detailed instructions for how to connect to your instance. We will briefly summarize them below.
Note: get the public IP address from the View Instances page (50.16.4.165 in the example here).
Open Terminal and go to the folder containing the private key (.pem file).
cd /path/to/folder
Update the permissions for the private key.
chmod 600 juicer_aws.pem
Connect with the AWS instance (ssh via public IP).
ssh -i juicer_aws.pem [email protected]
Source: AWS Instructions
Download PuTTY and PuTTYgen. Run PuTTYgen. Under Load an existing private key file, select the existing .pem file that was created above (e.g. juicer_aws.pem). Do not select "Generate a public/private key pair". A pop-up will appear saying you have imported a key. You'll then have the option to Save private key. Save it without a passphrase as juicer_aws.ppk.
Launch PuTTY. Expand the tabs under Connection>SSH>Auth. On the Auth page, there's an option to browse/load a private key file for authentication. Load the juicer_aws.ppk file here. Then go to the main session page. Use ubuntu@<public_ip> as the host name. Select Open.
The very first time that you log into the instance (or if you ever stop and restart an instance), you'll need to configure LSF. First, find your internal IP address. This is different from your public IP address.
/sbin/ifconfig | grep "inet addr" | awk -F: '{print $2}' | awk '{print $1}' |head -1
Now change the last line in the hosts file to list the internal IP address
sudo vim /etc/hosts
Then set the hostname and restart the services
sudo hostname HEADNODE
sudo service openlava restart
sudo /etc/init.d/networking restart
You should also update your password (default is aidenlab2015)
sudo passwd ubuntu
Before running Juicer for the first time, you should also update to the latest version of Java and scripts from Github by running the following
sudo add-apt-repository -y ppa:webupd8team/java
sudo apt-get update
sudo apt-get install -y oracle-java8-installer
cd ~
wget https://github.com/theaidenlab/juicer/archive/master.zip
unzip master.zip
sudo cp -TR juicer-master/AWS/scripts /opt/juicer/scripts
And finally add the latest juicer_tools.jar to the scripts folder.
cd /opt/juicer/scripts
wget latest_juicer_tools.jar
mv latest_juicer_tools.jar juicer_tools.7.0.jar
latest_juicer_tools.jar should be replaced with an appropriate url from the download page. Note that AWS uses CUDA 7 by default and as such the juicer scripts expect the jar to be named juicer_tools.7.0.jar (hence the renaming of the jar in the last line with mv).
Optional: If you added more than the default amount of storage when creating the instance, you will have to resize the filesystem for it to be able to use that space. Find the name of the filesystem using df -h and then run the following
sudo resize2fs filesystem-name
For example, when creating the instance if you chose 8 TB for the EBS volume size, and using df -h you found the 8 TB volume to be /dev/xvdf then you would run sudo resize2fs /dev/xvdf
Switch to the working directory
cd /opt/juicer/work
Create a new directory for each experiment. Also create a fastq folder in each experiment's directory.
mkdir -p EXP1/fastq
Copy all your fastq files into the appropriate fastq folder (e.g. /opt/juicer/work/EXP1/fastq).
Switch to the experiment's directory (outside of the fastq folder)
cd /opt/juicer/work/EXP1/
And issue the juicer command (default assumes -g hg19 -s MboI, see Usage for more possibilities)
/opt/juicer/scripts/juicer.sh
You will see a series of messages sending jobs to the cluster. Do not kill the script or close the server connection until you see: “(-: Finished adding all jobs... please wait while processing.”
At this point you can close the connection and come back later. To see the progress of the pipeline as it works, type: bjobs -w
Eventually the bjobs command will report “No unfinished job found”. Type: tail lsf.out
You should see “(-: Pipeline successfully completed (-:”
Results are available in the aligned directory under your work directory (e.g. /opt/juicer/work/EXP1/aligned). The Hi-C maps are in inter.hic (for MAPQ > 0) and inter_30.hic (for MAPQ >= 30). The Hi-C maps can be loaded in Juicebox and explored. They can also be used for automatic feature annotation and to extract matrices at specific resolutions. The output files include a genome-wide annotation of loops and, whenever possible, the CTCF motifs that anchor them (identified using the HiCCUPS and MotifFinder algorithms). The files also include a genome-wide annotation of contact domains (identified using the Arrowhead algorithm). The formats of these files are described in the Juicebox tutorial online; both files can be loaded into Juicebox as a 2D annotation.
To download a file (e.g. inter.hic) from AWS to load into Juicebox, type:
sftp -i Juicer_AWS.pem ubuntu@<given IP address>
cd /opt/juicer/work/MBR19/aligned
get inter.hic
get inter_30.hic
get ... (each of hiccups, apa, motifs, and arrowhead output files)
Especially when dealing with larger datasets, Juicer currently has a bug where after aligning and merging the jobs are stuck in only pending jobs. A temporary fix that may work is to first kill all the remaining jobs, and then run the following in screen (replacing the filenames matching with your files):
cat aligned/a1499807923_msplit*_optdups.txt > aligned/opt_dups.txt; cat aligned/a1499807923_msplit*_dups.txt > aligned/dups.txt;cat aligned/a1499807923_msplit*_merged_nodups.txt > aligned/merged_nodups.txt;
After it finishes, then run juicer.sh -S final
If you find a lot of jobs pending, there might be a problem with how much memory your instance has vis-a-vis how much it needs. You can see if this is the case by running bjobs -l <job_id> where <job_id> is the lowest job number pending. If the job says it is pending due to needing memory, you likely started with too little.