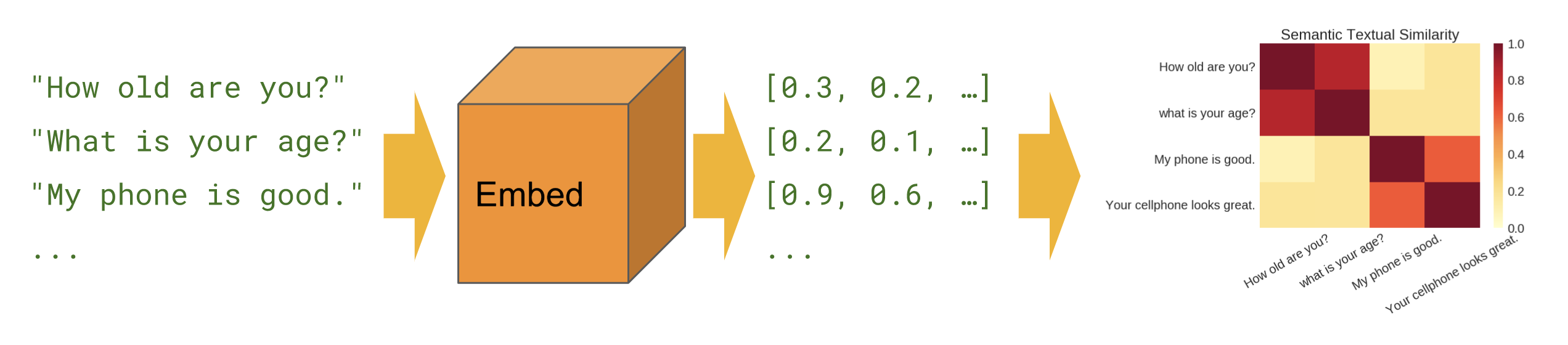
The semsim is Python3 based web application(Fast API) that can be used to identify the semantic similarity between agiven input text and a set of inputs. Semantic similarity is a measure of the degree to which two pieces of text carry the same meaning. This is broadly useful in obtaining good coverage over the numerous ways that a thought can be expressed using language without needing to manually enumerate them.
We make use of Universal Sentence Encoder model Large 5. This module is about 800MB. Depending on your network speed, it might take a while to load the first time you instantiate it. After that, loading the model should be faster as modules are cached by default learn more about caching. Further, once a module is loaded to memory, inference time should be relatively fast.
Please see Universal Sentence Encoder 4 for details about the embedding
Currently the API end points are:
- /similarity: Find similarity between the input text and list of texts and returns a json with texts as keys and similairty as value.
Follow the steps described in CONTRIBUTE.md
- Run the application locally:
- Installing the required libraries.
pip install -r requirements.txt- running the developement server
uvicorn app.main:APP- /similarity/
- Query Params: text, show
restart system
Response: In the order of similarity
[{"id":0,"text":""}]No parts of the code are covered with tests.