TCML : Temporal Convolution based Meta Learner
- DEVIEW slides : https://www.slideshare.net/storykim/cs-deview-2017-81002054
- github : https://github.com/devsisters/TCML-tensorflow
- paper : https://arxiv.org/abs/1707.03141
- 데이터가 적을 때
- 문제가 조금씩 바뀔 때
- 학습할 수 있어야 한다!
- meta learning
- broaden the learner's scope to a distribution of related tasks
- learn a strategy that generalizes
- the goal of meta-learning is generalization across tasks rather than across data points.
- meta-learner
- trained on a distribution of similar tasks
- hard-coding이 많았음
- RNN으로 해본 사람
- A number of methods consider a meta-learner that makes updates to the parameters of a traditional learner Ravi and Larochelle [20] extended this idea, using a similar LSTM meta-learner in a few-shot classification. setting, where the traditional learner was a convolutional-network-based classifier.
- 잘 안됨 (성능 낮음)
- traditional RNN architectures can only propagate information forward through time via their hidden state; this temporally-linear dependency bottlenecks their capacity to perform sophistication computation on a stream of inputs.
- Graves et al. [8] showed that these architectures have difficulties simply storing and retrieving information, let alone performing computation with it
- Compared to traditional RNNs, the convolutional structure offers more direct, high-bandwidth access to past information, allowing them to perform more sophisticated computation on a fixed temporal segment.

we wish to classify data points into N classes, when we only have a small number (K) of labeled examples per class. A meta-learner is readily applicable, because it learns how to compare input points, rather than memorize a specific mapping from points to classes.
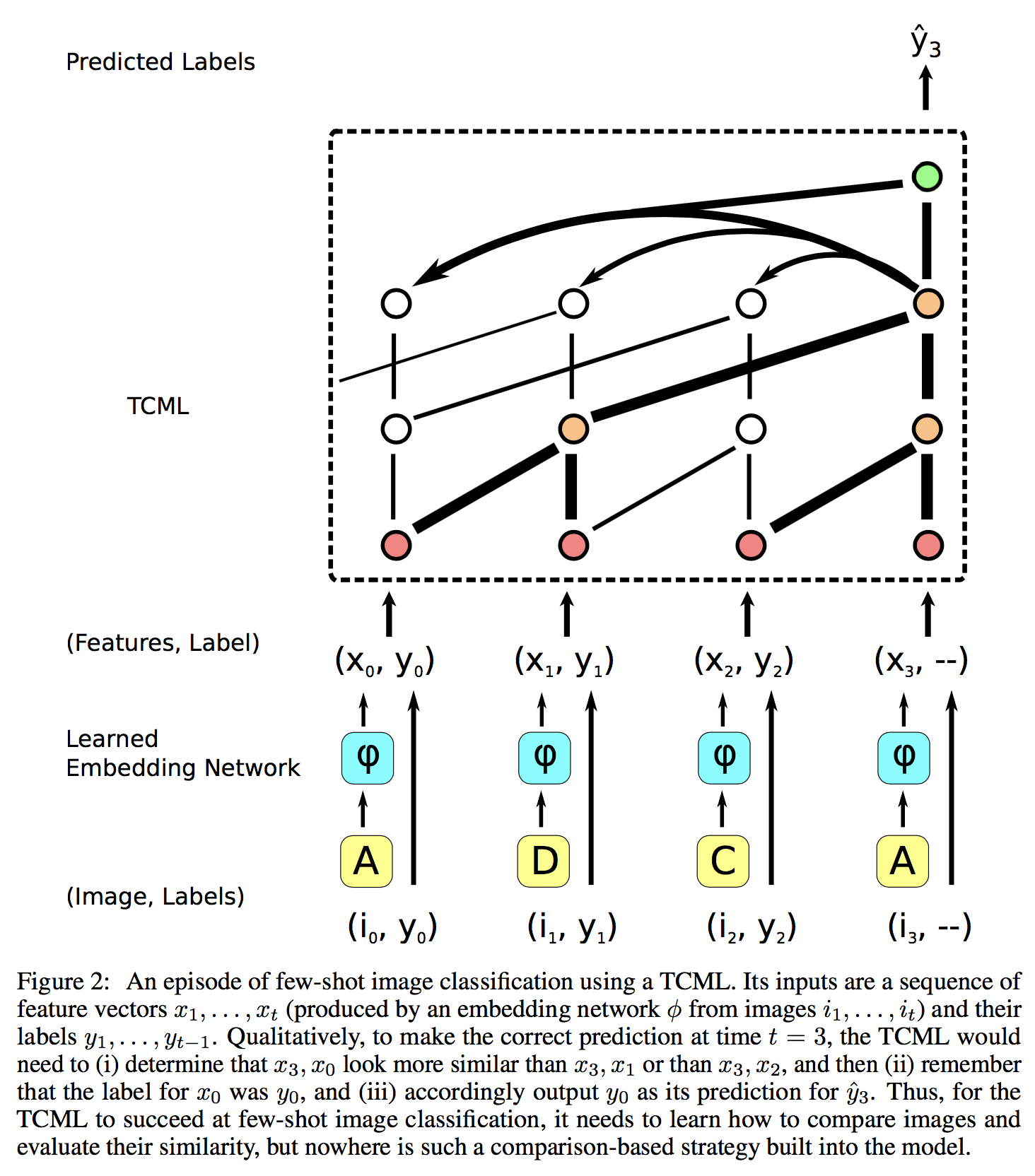
Omniglot : 알파벳 맞추기



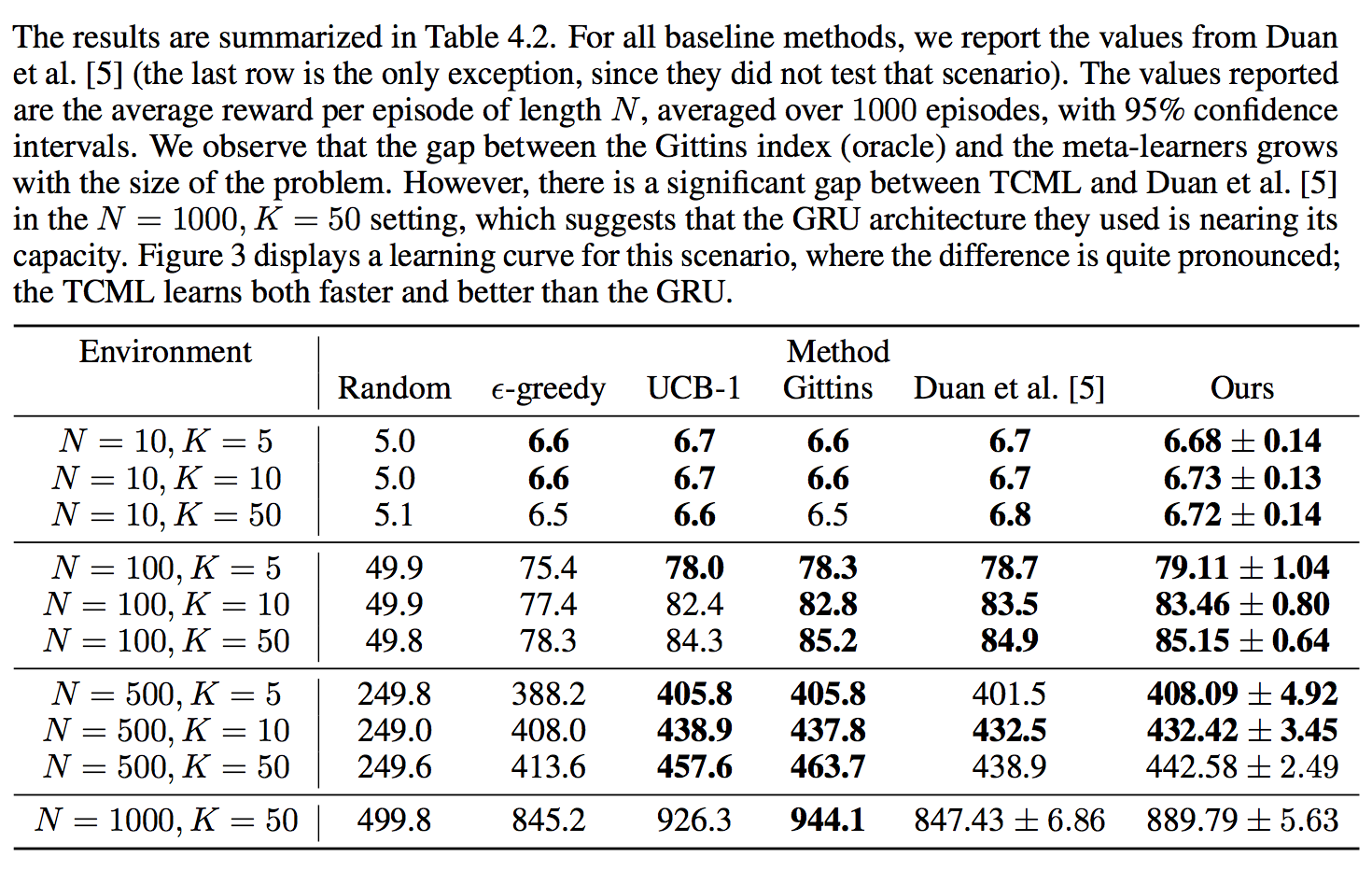
at each timestep, an agent selects one of K arms, and receives a reward according to some unknown distribution. The agent’s goal is to maximize its total reward over an episode of duration N . To perform well in this setting, a meta-learner must learn to balance both exploration and exploitation. exploration-exploitation tradeoff is one of the core algorithmic nuances that distinguishes reinforcement learning from supervised learning