Residual Networks Behave Like Ensembles of Relatively Shallow Networks
https://arxiv.org/abs/1605.06431
내용은 세가지로 요약할 수 있다.
- Residual networks는 여러가지 길이의 path의 모임으로 볼 수 있다.
- 그 path들은 서로 별로 연관성을 보이지 않는다 -> emsenble이다.
- 긴 path들은 거의 영향력이 없고 짧은 path들이 대부분의 영향력을 가진다.
- 예를 들어, 110 레이어라면 10-34 레이어짜리 path가 거의 대부분의 일을 한다.
- identity skip-connections를 도입했다. residual layers를 지나쳐서 데이터를 바로 전송한다. <-> sequential pipeline
- 엄청 깊은(예:1202) 네트워크를 가능케 했다. <-> AlexNet는 6개 정도
- training 후에 test할 때 레이어 몇개 빼도 괜찮더라 <-> VGG 같은 모델에서 레이어 빼면 큰일난다
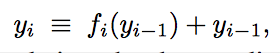

yi+1 ≡ fi+1(yi) · ti+1(yi) + yi · (1 − ti+1(yi)) gating function t에 의하여 입력과 출력이 정해진다. residual networks를 highway networks의 한 경우로 볼 수 있다.
- unraveled view라는 걸 만들어서 residual networks를 새롭게 보았다. 덕분에 여러가지 분석이 가능했다.
- Residual networks는 gradient를 깊은 레이어까지 전달하면서 vanishing gradient 문제를 해결하는 것이 아니다.
- 오히려, 엄청 깊은 네트워크에서 지름길을 만든 것이다.
- 여전히 깊은 네트워크 학습을 위해서는 짧은 paths들이 필요하다.

- 여러 path가 서로 의존성이 있거나 redundant한가?
- 만약 의존성이 없다면 ensenble처럼 되나?
- 여러가지 길이의 path가 네트워크게 다르게 영향을 미치나?
-
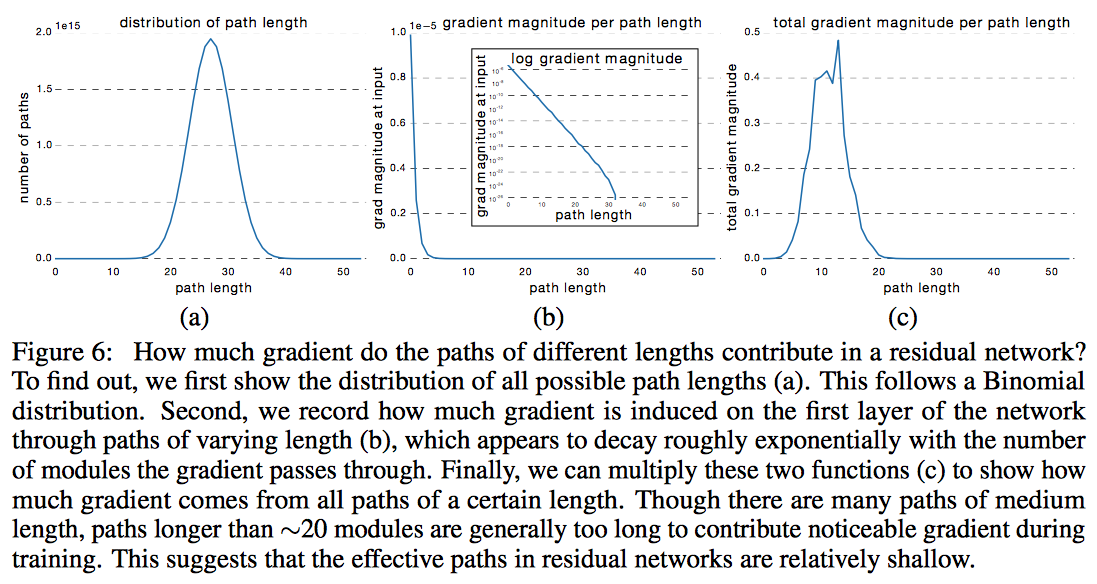
여러 path가 서로 의존성이 있거나 redundant한가? 레이어를 지워보자. 레어어를 지우는건 path를 절반으로 줄이는 것과 같다. 보통 모델에서는 하나밖에 없는 연결을 끊는 것과 같다.
결과는
즉 의존성이 없다.
-
만약 의존성이 없다면 ensenble처럼 되나? ensenble의 특징 : 모델 개수에 따라 성능이 스무스하게 변한다. 2-1. 레이어 여러개를 지워보자 2-2. 순서를 바꿔보자.
 결과는
결과는
 즉 의존성이 없다.
즉 의존성이 없다.- k 개의 랜덤 pair를 swap했다.
- 몇개 path를 없애고 training에서 보지 못했던 새로운 path를 도입하는 것이다.
- 말하자면 high-level transformation을 low-level transformation 전에 두는 것이다.
- Kendall Tau rank correlation

좀 corrupt 해도 괜찮다는 결론!
- 여러가지 길이의 path가 네트워크게 다르게 영향을 미치나?
3-1 path 길이의 분포
- path 길이는 binomial distribution을 따른다. 즉, 110 레이어짜리의 대부분의 path는 55 레이어만 갖고 있다.
3-2 path 길이에 따른 vanishing gradients 측정하기
- batch 하나를 feedforward한다
- k개의 residual blocks를 랜덤으로 뽑는다.
- 뽑힌 k개의 residual blocks에 대해서는 residual moduled에 대해서만 backprop한다.
- 나머지 n-k개의 residual blocks에 대해서는 skip connection으로만 backprop한다. 즉 backprop이 없는 것과 같다
- k 깊이의 모델에 대해서 input까지의 gradient를 측정한다.
- 이거를 k의 개수에 따라 곱하면 각 길이마다의 영향력을 알 수 잇다.
- 54개 모듈에서 23개 모듈만 랜덤으로 샘플링해서 학습을 시켜보았다.
- 즉 평균 11.5의 길이의 네트워크가 학습도니 것이다.
- 5.96% 에러율 달성 (전체는 6.10%)
- 통계적으론 별 차이 없음. effective paths면 충분하다!
54개에서 10개 정도 죽여도 괜찮다. 20개 죽이면 좀 심각하다.
보통 t가 skip connection으로 많이 보내는 쪽을 선호한다고 한다. 즉 short path가 중요하다는 걸 네트워크가 학습하는 것이다.
최근에 학습할 때 배치마다 모듈 몇개만 랜덤으로 선택해서 학습시키는 방식이 등장했다고 한다.
이건 학습할 때 짧은 path만 보이는 것과 같다. 각각 좋은 성과를 내도록 학습시킨다.
그래서 test할 때 레이어 몇개 빼도 거의 영향이 없다.
별로 놀라운 건 아니다.
"residual networks가 왜 좋냐고? 더 깊으니까!"("going deeper", by He)는 거~짓