Dokumentation Incident Monitoring
Der Honeygrove CIM ist eine Erweiterung eines Incident Monitors um Honeypot Alerts zu betrachten. Durch Clusterbildung und Aggregation dieser Alerts können wir verschiedene Visualisierungen darstellen, welche uns beim Analysieren von Angreifer Verhalten helfen. Die Verwendung von Honeytoken unterstützen uns bei diesem Prozess.
Dies ist eine Entwicklungshilfe für den gesamten Honeygrove CIM. Die Hauptbestandteile des CIMs setzen sich aus einem Broker-Endpoint und einer dockerisierten Version von Elasticsearch und Kibana (EK-Stack) zusammen. Logstash wird hierbei nicht verwendet, kann jedoch für Entwicklungszwecke optional eingesetzt werden.
Für das Incident Monitoring wurden zum größten Teil Software Produkte der Firma Elastic verwendet, sowie weitere unterstützende Software. Eine genauere Übersicht folgt in der Tabelle:
| Logo | Ressource | Version | Beschreibung |
|---|---|---|---|
| Java | 1.8.0_131-b11 | Entwicklungswerkzeug | |
| Python | 3.5.2 | Verwendete Programmiersprache | |
| Elasticsearch | 5.4.0 | Dient zum Verwalten und Speichern der Daten | |
| Kibana | 5.4.0 | Dient zur Visualisierung der Daten | |
| X-Pack | 5.4.0 | Plugin für Elasticsearch und Kibana. Wird für Watcher-Alerts verwendet | |
| Mattermost | 3.9.0 | Open Source, selbst gehostete Slack-Alternative | |
| PyBroker | 0.14.5 | Eine Library für Python zum Erstellen von Endpoints | |
| Docker | 17.06.0 | Eine Container Platform für den EK-Stack | |
| Docker-Compose | 1.8.0 | Ein Tool zum Definieren und Ausführen von Multi-Container Docker Anwendungen | |
| Team Cymru MHR | 07.08.2017 | Malware Hash Registry dient als Look-up Service | |
| Honeygrove | 1.0 | Honeypot | |
| Optionale Software | Version | Beschreibung | |
| Logstash | 5.4.0 | Dient zur Aggregations der Daten |
Der Honeygrove CIM läuft nur auf einem Linux System. Folgende Systemanforderungen sind dabei zu beachten:
- Linux Distributionen: Ubuntu 16.04 LTS oder Debian 9.1
- RAM: mindestens 8GB (Optional: kann auf Kosten der Effizienz verkleinert werden, siehe: Konfiguration)
- Prozessor: Intel ® Core &trade / AMD64
In der folgenden Abbildung wird das Zusammenwirken unserer Software Komponenten dargestellt. Der Honeygrove Honeypot protokolliert Alerts bereits im passenden JSON Format, sodass diese von Elasticsearch (ES) direkt gelesen und verarbeitet werden können.
Als JSON-String versendet, werden diese im CIMBrokerEndpoint durch die Funktion getLogs()empfangen. Dabei steht ein Broker-System zwischen dem Honeypot und dem CIM. Durch Abonnieren des Topics "logs" können, wir diese Logs anfordern. Weitere Informationen dazu im Konfiguration Abschnitt. Der CIMBrokerEndpoint peert sich mit ES und leitet diese JSON-String Logs direkt weiter. Grund für das JSON-Format ist, dass ES nur dieses Format liest, wodurch wir uns entschieden haben bereits im Honeypot Logs so zu parsen, dass diese für ES Verarbeitungs bereit vorliegen.
Bestimmte Logs werden, bevor man diese an ES weiterleitet, erst in einer Malware-Hash-Registry überprüft. Genaueres wird im Abschnitt Malware erläutert.
In ES angekommen, können die Logs wie in einer Datenbank verarbeitet werden. Kibana stellt hierfür eine geeignete Software dar, welche die Logs aus ES verwendet und als Visualisierung in einem Dashboard darstellen kann.
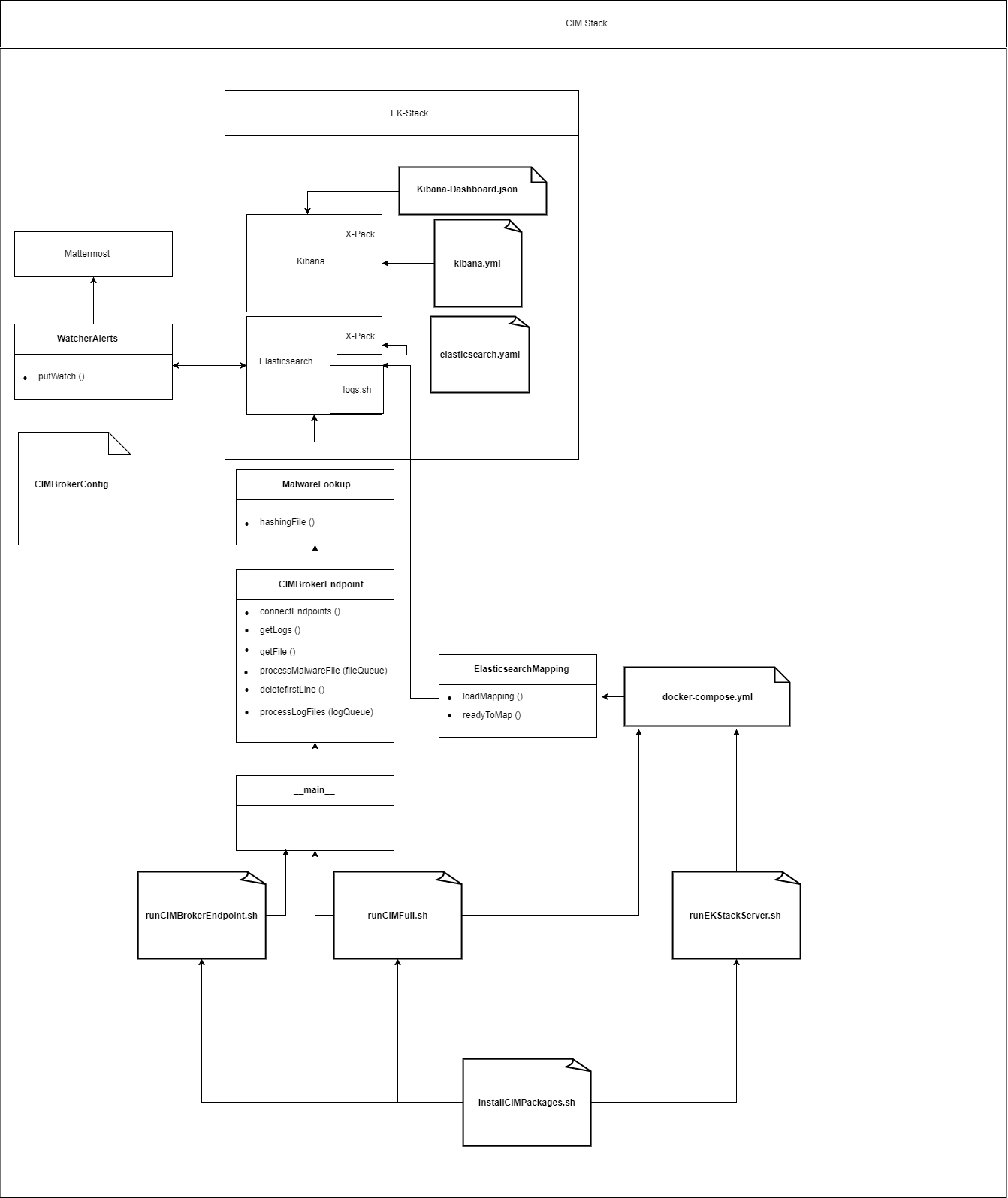
Mit dem Honeygrove CIM wurde ein Feature eingeführt, welches ermöglicht Datein, die in unserem Honeypot Netzwerk versendet werden, zu analysieren um somit mögliche Malware Bedrohungen frühzeitig erkennen zu können. Dabei werden diese Datein vom Honeypot an den CIMBrokerEndpoint versendet und mit der Topic "files" abonniert. Diese Datein werden Lokal abgespeichert, falls man zu einem späteren Zeitpunkt genauere Analysen anstellen möchte.
Für die abgespeicherten Datein, wird ein Hash Wert im Format SHA1 berechnet und dieser an die Malware Hash Registry (MHR) von Team Cymru gesendet. Die MHR leitet diesen Hash nun an verschiedene AV-Engines weiter und berechnet aus deren Antwort einen Prozentwert, der uns sagen kann, ob und wie bedrohlich diese Datei ist. Zusätzlich verweisen wir mit einem Link auf Website virustotal.com, auf welcher weitere Informationen über diese Malware Datei steht.
Das Plugin X-Pack für Elasticsearch und Kibana ermöglicht uns beim Eintreffen gewünschter Bedingungen, Watcher-Alerts zu versenden. Watcher-Alerts sind Benachrichtigungen die wir an uns selbst versenden können. Dabei verwenden wir im Honeygrove CIM Webhooks, um Nachrichten an Mattermost zu senden. Natürlich sind auch noch andere Versendungsarten der Watcher-Alerts möglich, wie z. B. Email, HipChat, etc. Weitere Infos auf der Elastic.co Website. In unserer WatcherAlerts.py, die wir im Abschnitt Konfiguration näher erläutern, kann man die Watcher-Alerts beliebig erstellen und verändern.
Der CIM kann entweder als EK-Stack zusammen mit dem CIMBrokerEndpoint installiert und ausgeführt werden oder aber beide Komponenten getrennt voneinander. Hierbei ist zu beachten, dass vor der ersten Installation alle benötigten Packages installiert werden müssen, damit der CIM laufen kann. Außerdem unterscheiden wir zwischen einem EK-Stack Install Script für den Server und für den Desktop. Der Unterschied liegt darin, dass das Server Script im Hintergrund läuft und Log-files vom Programmablauf erstellt. Beide Scripts befinden sich im Verzeichnis /incidentmonitoring/EKStack/.
Alle EK-Stack Scripte starten eine docker-compose.yml, welche verwendet wird um ein CIM Cluster zu starten. Dieser besteht aus einem Kibana Knoten und drei Elasticsearch Knoten. Dabei teilen sich die ES Knoten in einen Master (es-master) und zwei Slaves (es-data-1, es-data-2) auf. Die Slaves sind verantwortlich für anhaltende Daten und gespiegelte Kopien voneinander. Umgebungsvariablen werden verwendet, um den Zweck eines Clusterknotens zu bestimmen.
Standardmäßig benötigt Elasticsearch eine ziemlich große mmap-Zählung. Damit ES in der Lage ist zu starten, muss der folgende Befehl auf dem ES-Hostsystem ausgeführt werden (nicht innerhalb des Containers, echter Host): sysctl -w vm.max_map_count = 262144. Weitere Informationen finden sich in der offiziellen Dokumentation.
Diese Eigenschaft wird automatisch in allen Start Scripts gesetzt. Um zu überprüfen, ob der CIM korrekt gestartet wurde, kann sudo docker ps verwendet werden. Die Erstellung des Index und Mappings läuft im CIM komplett automatisch und muss nicht vom Benutzer manuell ausgeführt werden. Im Konfigurationsabschnitt unter Elasticsearch wird weiter darauf eingegangen.
cd incidentmonitoring/-
sudo sh installCIMPackages.sh(Nur bei erst Installation) -
sudo sh runCIMFull.sh(CIMEndpoint mit EKStack Desktop Version)
cd incidentmonitoring/-
sudo sh installCIMPackages.sh(Nur bei erst Installation) -
sudo sh runCIMBrokerEndpoint.sh(Führt Endpoint aus) cd EKStack/-
sudo sh runEKStack.sh(Desktop version) -
sudo sh runEKStackServer.sh(Server Version)
**sollte ein CIM Stack bereits einmal installiert worden sein so kann man mittels
curl -XDELETE 'localhost:9200/*
Die Konfiguration resetten.
Man kann den EK-Stack auch manuell mit der docker-compose.yml und dem Befehl docker-compose up --build starten, die ebenfalls im EK-Stack Verzeichnis liegt. Im Benutzerhandbuch finden sich weitere Informationen zur Verwendung des EK-Stacks.
-
CIM-Slaves: sollte in der Vergangeheit bereits einmal eine CIM Stack installiert worden sein so kann man die Einstellung mittels Konsolenbefehl
curl -XDELETE 'localhost:9200/*die Konfiguration resetten.
-
CIMBroker IP & Port: Die IP und den Port auf dem der CIMBrokerEndpoint angesprochen wird, kann in der
CIMBrokerConfig.pyverändert werden. -
Abbonieren von Topics: Das Anlegen und Abonnieren von neuen Topics geschieht in der
CIMBrokerEndpoint.pymit denen wir im CIM die Logs und Datein vom Honeypot erhalten. Ein Topic wird wie nachfolgend abbonniert, wobei<Topic>der Name des zu abbonierenden Topics ist:<NameQueue> = message_queue("<Topic>", listenEndpoint)Um den Content des Topics zu erhalten ist noch eine Funktion notwendig, die wie folgt, aufgebaut ist:@staticmethoddef <NameFunktion>():return CIMBrokerEndpoint.<NameQueue>.want_pop()
-
Kibana Erreichbarkeit: Kibana ist Standardmäßig erreichbar unter
localhost:5601bzw.<serverIP>:5601. Im Falle einer Server IP kann Kibana erst aufgerufen werden, wenn eine SSH Verbindung zu diesem Server besteht und ein Tunnel hergestellt wurde. Außerdem muss bei Verwendung der Port Zugänglichkeit die IP in derdocker-compose.ymlebenfalls verändert werden. SSH:ssh -p <serverPort> <Benutzername>@<serverIP>Tunnel:ssh -L 8080:localhost:5601 -l <Benutzername> <serverIP> -
Port Zugänglichkeit: Es ist möglich, von einem lokal exponierten Port zu einem öffentlich exponierten Port zu wechseln, indem man die folgende Änderung in der
docker-compose.ymlmacht.
ports:
- "127.0.0.1:5601:5601"
ändern zu:
ports:
- "5601:5601"-
Indexing: In Kibana unter
Management -> Index Patternsauf das blaue Plus Symbol, oben Links, klicken. Als Index Namehoneygroveeintippen und als Time-field Name@Timestampauswählen. Dann auf Create klicken. Der Index wurde nun erstellt. (Optional: Bevorzugten Index als Favorit wählen). -
Dashboard: Das Honeygrove Dashboard kann in Kibana unter
Management -> Saved Objectsimportiert werden. Es befindet sich im Verzeichnis/incidentmonitor/EKStack/kibana/. In der folgenden Abbildung wird das genutzte Kibana Dashboard beispielhaft gezeigt:


-
Elasticsearch Erreichbarkeit: Elasticsearch ist Standardmäßig unter
localhost:9200erreichbar bzw.<serverIP>:9200. Im Falle einer Server IP, siehe Abschnitt Konfiguration Kibana. Außerdem muss bei einer Änderung der IP in derCIMBrokerConfig.pydieElasticIpverändert werden, wenn man weiterhin Logs vom CIMBrokerEndpoint empfangen möchte. -
Mapping: Das Mapping wird in Elasticsearch verwendet, um einen Index zu erstellen und Datentypen, wie den Zeitstempel, korrekt zu deklarieren. Um sein eigenes Mapping zu verwenden, kann man in der
ElasticsearchMapping.pyunter/incidentmonitoring/EkStack/elasticsearch/config/scripts/in der FunktionloadMapping()Änderungen vornehmen bevor der EK-Stack gestartet wurde. Wenn ein Mapping bereits erstellt wurde, muss der Index vorher gelöscht werden. Weitere Informationen zum Mapping findet man unter Elastic.co. -
Index Löschen: Wenn man bereits ein Mapping in den Index geladen hat und es nachträglich verändern möchte, muss vorher der Index gelöscht werden. Das kann man im Terminal mit
curl -XDELETE 'localhost:9200/honeygrove?pretty'erreichen oder in Kibana unterDev Toolsin die KonsoleDELETE /honeygroveeingeben. ACHTUNG: Sämtliche Logs gehen dabei verloren. Weitere Informationen unter Elastic.co -
Neues Mapping verwenden: Um ein neues Mapping in den Index zu laden, muss im Mapping Verzeichnis folgender Befehl ausgeführt werden:
python3 ElasticsearchMapping.py.
-
Alerts Erstellen/Ändern/Löschen: Unsere Watcher-Alerts Konfigurationsdatei ist zu finden unter
/incidentmonitor/EKStack/elasticsearch/config/scripts/WatcherAlerts.py. Dort können in der FunktionputWatch()beliebig viele Alerts erstellt oder verändert werden. Die vier wesentlichen Konfigurationsmöglichkeiten sind dabei"triggers","inputs","conditions"und"actions". Eine Dokumentation zur Erstellung von Watcher-Alerts gibt es unter Elastic.co. Watcher-Alerts können mitpython3 WatcherAlerts.pyin Elasticsearch geladen werden. Eine vorherige Löschung, wie beim Mapping ist hier nicht nötig. Sollte man seinen Watcher-Alert trotzdem löschen wollen kann man dies am einfachsten in Kibana unterManagement -> Watcher, den gewünschten Alerts auswählen und mit löschen bestätigen. -
Honeygrove-Alerts: Für den Honeygrove Honeypot werden Alerts für Brute Force Angriffe auf die Services HTTP, FTP und SSH, sowie Malware Detection und Honeytoken Alerts verwendet. Im Falle der Brute Force Alerts wurde eine Bedingung von 100 Fehlgeschlagenen Login Versuchen an einem Service, innerhalb 10 Sekunden definiert, um einen Alert auszulösen. Für Malware Alerts wird ein Bereich zwischen 30-100 Prozent definiert, um einen Alerts auszulösen. Zeit und Anzahl kann in den jeweiligen Alerts für individuelle Zwecke angepasst werden.
'input': {
'filter': {
'range': {
@timestamp': {
'from': 'now-10s',
'to': 'now'}}}}}}}}},
'condition': {
'compare': {
'ctx.payload.hits.total': {
'gt': 100}}},-
Webhooks: Zurzeit wird eine gemeinsame Weebhook URL in der
WatcherAlerts.pydefiniert. Diese kann dort verändert werden bzw. jeder Alert eine individuellen Webhook bekommen, falls gewünscht. -
Dashboard: Das Watcher Dashboard wird zusammen mit dem Honeygrove Dashboard importiert. Um es jedoch nutzen zu können, muss vorher der Watcher Index initialisiert werden. Dazu auf
Management -> Index Patternsnach dem Index Namen".watcher-history-*"suchen und als Timefield Name"trigger_event.triggered_time"auswählen. Dann auf Create klicken. Notfalls nochmal importieren.
- Die komplette CIM Installation benötigt mindestens 8 GB RAM. Für Testzwecke oder bei unzureichender RAM Größe, kann auf Kosten der Effizienz des CIMs, Arbeitsspeicher reduziert werden. In der
docker-compose.ymlmüssen dafür Änderungen vorgenommen werden. Beispielsweise kann man die Slaveses-data-1undes-data-2komplett auskommentieren und zusätzlich den Arbeitsspeicheranteil deses-masterbis auf 256mb reduzieren. Wichtig ist beim Löschen der Slaves, dass auch der AbschnittBM_ES_MASTERundBM_ES_DATAauskommentiert werden. Sowie die ersten beiden Zeilen in der elasticsearch.yml unter/incidentmonitor/EKStack/elasticsearch/config/. Wenn man dann den EK-Stack neu startet, läuft dieser mit deutlich geringerer RAM Anzahl.
docker-compose.yml:
ES_JAVA_OPTS: "-Xms256m -Xmx256m"
# BM_ES_MASTER: "true"
# BM_ES_DATA: "false"
elasticsearch.yml
# node.master: ${BM_ES_MASTER}
# node.data: ${BM_ES_DATA-
Logstash: Wenn man eine andere Protokoll Aggregation verwenden möchte, als die vom Honeygrove Honeypot, dann kann man auf Logstash zurückgreifen. Logstash ermöglicht Logs, wie benötigt, umzuparsen und an Elasticsearch oder andere Suchserver zu versenden. Hierzu können die in der
docker.compose.ymlbetreffenden Zeilen ein kommentiert werden. Beim Start des EK-Stacks wird Logstash dann installiert und ausgeführt. Die Logstash-Konfiguration findet man unter/incidentmonitor/EKStack/logstash/config/. Die Konfiguration verfügt über einen Block von Parsing-Anweisungen pro Log-Datei. Weitere Informationen zu Logstash finden sich auf Elastic.co.
Bei einem Verbindungsabbruch zu Elasticsearch wird eine lokale Datei mit dem Namen json.log im Verzeichnis /incidentmonitoring/ressources/ erstellt in der die Logs gespeichert werden, die während des Verbindungsabbruches verloren gegangen währen. Wenn Elasticsearch wieder hochgefahren ist, kann man im gleichen Ordner das Script logs.sh mit sudo sh logs.sh ausführen.
WICHTIG:
- Bevor das Script ausgeführt wird, muss die logs.json geöffnet werden und geprüft werden, ob die erste Zeile eine Index Zeile ist. Eine Index Zeile hat das folgende Format:
{index: {_type:...}}. Sollte die erste Zeile keine Index Zeile sein, so muss diese gelöscht werden. Grund hierfür ist eine MappingException die Elasticsearch bekommt, wenn eine Index Zeile fehlt. - Außerdem sollte vorher sichergestellt werden, dass Elasticsearch anprechbar ist. Um die Ansprechbarkeit zu testen, kann man im Browser
localhost:9200bzw<serverIP>:9200eingeben. Es erscheint ein Text zur Information des Clusters. Nachdem das Script ausgeführt wurde, löscht sich dielogs.jsonautomatisch.
Es wird empfohlen die korrekte Funktionsweise zu überprüfen.
-
Korrekte Funktionsweise von Logs und der EK Kommunikation überprüfen:
Services verwenden um Testlogs zu generieren, siehe Honeypot. In Kibana unter
Discoverüberprüfen ob diese ankommen.) -
Webalerts Testen:
Test Warnungen auslösen, in dem Schwelle für Bedingung (
"condition) so verändert wird, das Alert sofort ausgelöst wird. Beispiel: Ab dem ersten match triggern:
'condition': {
'compare': {
'ctx.payload.hits.total': {
'gt': 0}}}, # <= 0 Logs nötig zum triggern-
Malware Test mit Hash:
Übersenden einer Testmalware mittels CIM. Dafür in die
MalwareLookup.pygehen undtestMalware.fileals Datei verwenden. Danach in Kibana prüfen ob Log korrekt versendet wurde.
filename = './ressources/%s.file' % timestr
ändern zu
filename = '../ressources/testMalware.file'- PyBroker: Der CIMBrokerEndpoint ist eine Schnittstelle, die uns ermöglicht Logs und Datein, welche vom Honeygrove Honeypot übersendet werden, zu empfangen. Dafür verwenden wir Pybroker welcher uns beim Erstellen dieser Endpoints unterstützt. Im Konfiguration Abschnitt wurde bereits erläutert, wie das abonnieren von Topics funktioniert. Der CIMBrokerEndpoint empfängt die Logs und Datein über unsere Topics als JSON-String und leitet diese weiter an Elasticsearch. Es handelt sich um einen Pythonscript der via main in der IDE oder das entsprechenden skripte runCIMBrokeEndpoint.sh oder runCIMFull gestartet werden kann.
class 'CIMBrokerEndpoint.'input(self,string)
Gibt den string gegebenenfalls aus der Ui zurück.
Instanzvariablen
- listenEndpoint Der Endpunkt an dem die Nachrichten vom Brokerendpunkt im Empfang genommen werden.
- logsqueue ist eine messageQueues (siehe oberer Abschnitt) über die der BrokerEndpoint nachrichn empfängt. Es handelt sich um die logs die der Honeypot verschickt.
- fileQueue ist eine messageQueues (siehe oberer Abschnitt). Es handelt sich um die malwarefiles die der Honeypot verschickt.
Methoden
-
connectEndpoints legt den ansprechbaren BrokerEndpunkt auf den in der Config angegebenen Punkt fest.
-
getLogs nimmt die logs entgegen die an den CIm gesendet werden.
-
getFile nimmt die fiels entgegen die an den CIM gesendet werden.
-
processMalwareFile verarbeitet die MalwareFiles die über einen bestimmten Nachrichtentopic übermittelt fileQueue die FileQueue über die die Files übermittelt werden
-
processLogFiles nimmt die logfiles entgegen formatiert sie in ein für elasticsearch lesbares JSON-Format logQueue die über die logQueue-topic übermittelten Nachrichten
-
messagehndling ruft die Methoden connnectEndpoints, processMalwareFile und processLogFiles auf.
-
Elasticsearch Package: Zum Weiterleiten der Logs und Datein aus dem CIMBrokerEndpoint, verwenden wir das Elasticsearch Package für Python.
Mit
es = Elasticsearch([{'host': ElasticIp, 'port': ElasticPort}])kann man den Elasticsearch Client initialisieren. Zu finden ist dieser in derCIMBrokerConfig.pyMites.index(index='honeygrove', doc_type=t, body=<content>)können wir nun an den Index "honeygrove" mit unseren _types aus den Logs, die zur Partitionierung des Index verwendet werden, den Content an Elasticsearch senden. Der Content muss im JSON Format protokolliert werden.