{kind=link}
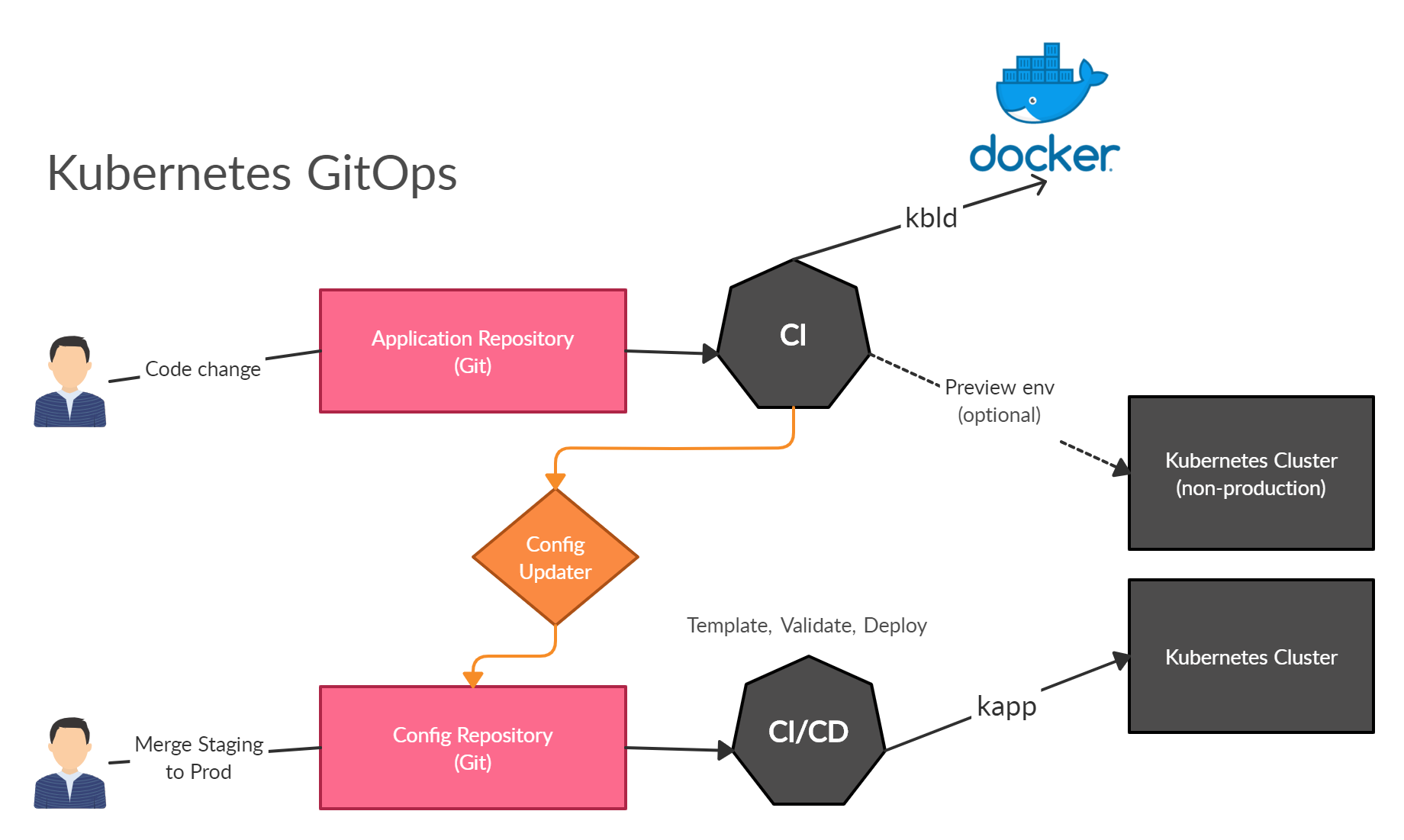
The GitOps workflow to manage Kubernetes applications at any scale (without server components).
Technology should not make our lives harder. Choosing a specific technology should not change the way you do something very basic so drastically that it's harder to use, as opposed to easier to use. That's the whole point of technology. - Chris Short
This guide describes a CI/CD workflow for Kubernetes that enables GitOps without relying on server components.
There are many tools to practice GitOps. ArgoCD and FluxCD are the successors of it. Both tools are great but come with a high cost. You need to manage a complex 130 Open Bugs piece of software (kubernetes operator) in your cluster and it couples you to very specific solutions (CRD's). Additionally, they enforce a Pull based CD workflow. I can't get used to practicing this flow because it feels cumbersome although I'm aware of the benefits:
- Automated updates of images without a connection to your cluster.
- Two-way synchronization (docker registry, config-repository)
- Out-of-sync detection
In search of something simpler I found the k14s tools. They are designed to be single-purpose and composable. They provide the required functionality to template, build, deploy without coupling to full-blown community solutions. Tools like Helm, Kustomize can be easily connected. The result is a predictable pipeline of client tools. The demo in this repository solves:
- The entire release can be described declaratively and stored in git.
- You don't need to run additional software on your cluster.
- You can easily reproduce the state on your local machine.
- The CI/CD lifecycle is sequential. (Push based pipeline)
- No coupling to specific CD solutions. Tools can be replaced like lego.
According to Managing Helm releases the GitOps way you need three things to apply the GitOps pipeline model. I think we can refute the last point.
We consider each directory as a separate repository. That should reflect a real-world scenario with multiple applications.
├── config-repository (contains all kubernetes manifests)
│ ├── .release (temporary snapshot of the release artifact)
│ │ ├── umbrella-chart
│ │ └── state.yaml
│ ├── app-locks (image locks to point to a specific version)
│ │ └── demo-service.kbld.lock.yml
│ ├── umbrella-chart (collection of helm charts which describe the infra)
│ │ ├── charts
│ │ │ ├── demo-service
│ │ ├── Chart.lock (chart lock file to ensure reproducible install)
│ │ ├── Chart.yaml
│ │ └── values.yaml
├── demo-service-repository (example application)
│ ├── build.sh (build and push the image)
│ ├── Dockerfile
│ ├── kbld.yaml (defines what image is build and where to push it)
└ └── umbrella-chart (describe the preview environment "optional")
- helm - Package manager
- kbld - Image building and image pushing
- kapp - Deployment tool
- kpt - Fetch, update, and sync configuration files using git
- kubeval (optional) - Validate your Kubernetes configuration files
- kube-score (optional) - Static code analysis
- sops (optional) - Secret encryption
Helm is the package manager for Kubernetes. It provides an interface to manage chart dependencies. Helm guaranteed reproducible builds if you are working with the same helm values. Because all files are checked into git we can reproduce the helm templates at any commit.
helm dependency build- Rebuild the charts/ directory based on the Chart.lock filehelm dependency list- List the dependencies for the given charthelm dependency update- Update charts/ based on the contents of Chart.yaml
Helm allows you to manage a project composed of multiple microservices with a top-level umbrella-chart. You can define global chart values that are accessible in all sub-charts.
In big teams sharing charts can be exhausting tasks. In that situation, you should think about a solution to host your own Chart Repository. You can use chartmuseum.
The simpler approach is to host your charts on S3 and use the helm plugin S3 to make them manageable with the helm cli.
There is another very interesting approach to share charts or configurations in general. Google has developed a tool called kpt. One of the features is to sync arbitrary files/subdirectories from a git repository. You can even merge upstream updates. This makes it very easy to share files across teams without working in multiple repositories at the same time. The solution would be to fetch a list of chart repositories and store them to umbrella/charts/ and call helm build. Your Chart.yaml dependencies must be prefixed with file://.
# fetch team B order-service subdirectory
kpt pkg get https://github.com/myorg/charts/order-service@VERSION \
umbrella-chart/charts/order-service
# lock dependencies
helm build
# make changes, merge changes and tag that version in the remote repository
kpt pkg update umbrella-chart/charts/order-service@gNEW_VERSION --strategy=resource-mergeWith kpt fn you can generate, transform, and validate configuration files from images, starlark scripts, or binary executables. The command below will provide DIR/ as an input to a container instance of gcr.io/example.com/my-fn executing the function in it and store the output in charts/order-service. This has great potential to align your tooling with containers.
DOCKER all the things!
# run a function using explicit sources and sinks
kpt fn source DIR/ |
kpt fn run --image gcr.io/example.com/my-fn |
kpt fn sink charts/order-service/Sometimes helm is not enough. This can have several reasons:
- The external chart isn't flexible enough.
- You want to keep base charts simple.
- You want to abstract environments.
In that case, you can use tools like kustomize or ytt.
# this approach allows you to patch specific files because file stucture is preserved
helm template my-app ./umbrella-chart --output-dir .release
# this requires a local kustomize.yaml
kustomize build .release
# or with ytt, this will template all files and update the original files
helm template my-app ./umbrella-chart --output-dir .release
ytt -f .release --ignore-unknown-comments --output-files .release- Build an application composed of multiple components.
- Manage dependencies.
- Distribute configurations.
If you practice CI you will test, build and deploy new images continuously in your CI. Every build produces an immutable image tag that must be replaced in your helm manifests. In order to automate and standardize this process, we use kbld. kbld handles the workflow for building and pushing images. In your pipeline you need to run:
./demo-service-repository/build.sh
This command will build and push the image and outputs a demo-service.kbld.lock file. This file must be committed to the config-repository/app-locks to ensure that every deployment reference to the correct images. This procedure will trigger the CI in the config-repository and allows you to practice Continues-Deployment.
Before we can build images, we must create some sources and image destinations so that kbld is able to know which images belong to your application. They are managed in the application repository demo-service-repository/kbld.yaml. They look like CRD's but they aren't applied to your cluster.
The directory config-repository/.release refers to the temporary desired state of your cluster. It's generated on your CI pipeline. The folder contains all kubernetes manifest files.
This command will prerender your umbrella chart to config-repository/.release/state.yaml, builds and push all necessary images and replace all image references in your manifests. It's important to note that no image is built in this step. We reuse all prerendered images references from app-locks. The result is a snapshot of your desired cluster state at a particular commit. The CD pipeline will deploy it straight to your cluster.
$ ./config-repository/render.sh- One way to build, tag and push images.
- Agnostic to how manifests are generated.
- Desired system state versioned in Git.
- Every commit points to a specific image configuration of all maintained applications.
We use kapp to deploy our resources to kubernetes. Kapp ensures that all resources are properly installed in the right order. It provides an enhanced interface to understand what has really changed in your cluster. If you want to learn more you should check the homepage.
$ ./config-repository/deploy.shℹ️ Kapp takes user provided config as the only source of truth, but also allows to explicitly specify that certain fields are cluster controlled. This method guarantees that clusters don't drift, which is better than what basic 3 way merge provides. Source: carvel-dev/kapp#58 (comment)
If you need to delete your app. You only need to call:
$ ./config-repository/delete.sh
This comes handy, if you need to clean up resources on dynamic environments.
- One way to diffing, labeling, deployment and deletion
- Agnostic to how manifests are generated.
In order to manage multiple environments like development and staging, you can create different branches. Every branch has a different set of image references (stored in config-repository/app-locks) and values for your helm charts.
You can use sops to encrypt yaml files. The files must be encrypted before they are distributed in helm charts. In the deployment process, you can decrypt them with a single command. Sops support several KMS services (Hashicorp Vault, AWS Secrets Manager, etc).
💡 CI solutions are usually shipped with a secret store. There you can store your certificate to encrypt the secrets.
# As a chart maintainer I can encrypt my secrets with:
find ./.release -name "*secret*" -exec sops -e -i {} \;
# Before deployment I will decrypt my secrets so kubernetes can read them.
kapp deploy -n default -a my-app -f <(sops -d ./.umbrella-state/state.yaml)The big strength of GitOps is that any commit represent a releasable version of your infrastructure setup.
Where kubernetes controller really show its strength is locality. They are deployed in your cluster and are protected by their environment. We can use that fact and deploy a controller like secretgen-controller which is responsible to generate secrets on the cluster. secretgen-controller works with CRD's. In that way, the procedure to generate the secret is stored in git but you can't run into the situation where you accidentally commit your password. You will never touch the secret.
The hardest thing [about running on Kubernetes] is gluing all the pieces together. You need to think more holistically about your systems and get a deep understanding of what you’re working with. - Chris Short
🏁 As you can see the variety of tools is immense. The biggest challenge is to find the right balance for your organization. The proposed solution is highly opinionated but it tries to solve common problems with new and established tools. I placed particular value on a solution that doesn't require server components. I hope this guide will help organization/startups to invest in kubernetes. Feel free to contact me or open an issue.
Check out the demo to see how it looks like.