PPO+ActionMask for Tennis RL
受到b站UP训练网球RL的视频的驱动, 也训练了下自己的RL,这边记录下自己的方案和训练结果。
试过DQN+两阶段训练的方案,但是DQN的收敛速度实在太慢了,没有怎么训练出来🙁。然后就转用ppo算法训练,作为on-policy的算法,收敛速度明显好过于DQN。但是训练过程中总会出现达到最大 episodic-length 的情况,一般情况下两方对打总有实力的落差,在一定steps内总会分出胜负。这显然又是出现了“摆烂”问题🤔, 自己RL在应该开球的时候不“开球”,于是“摆烂”耗到最大 episodic-length🤣。
于是我开始在游戏环境下做研究,因为环境不会显式提供 “开球状态” 等信息,所以需要根据reward和网球规则手动判断是否在开球状态。 基于这个思路,我完成了 tennis-wrapper 的设计,在环境中暴露一个 action_mask 接口,同时也解决了一个小回合结束后的僵直问题😊。在PPO算法中加入mask,对于非法action的 logits 设为负无穷,这样agent就不会选择这个动作了。
| 库名 | 版本要求 |
|---|---|
| ale-py | 0.7.5 |
| AutoROM | 0.5.4 |
| opencv-python | - |
| gym | 0.23.1 |
| tensorboard | - |
| numpy | - |
| torch | - |
python ppo_tennis.pyCleanrl默认训练总步长为10 millon,可通过 --total-timesteps 参数更改设置;实测 20 - 30 millon 完全收敛。可以使用 tensorboard 观察训练过程,如图:
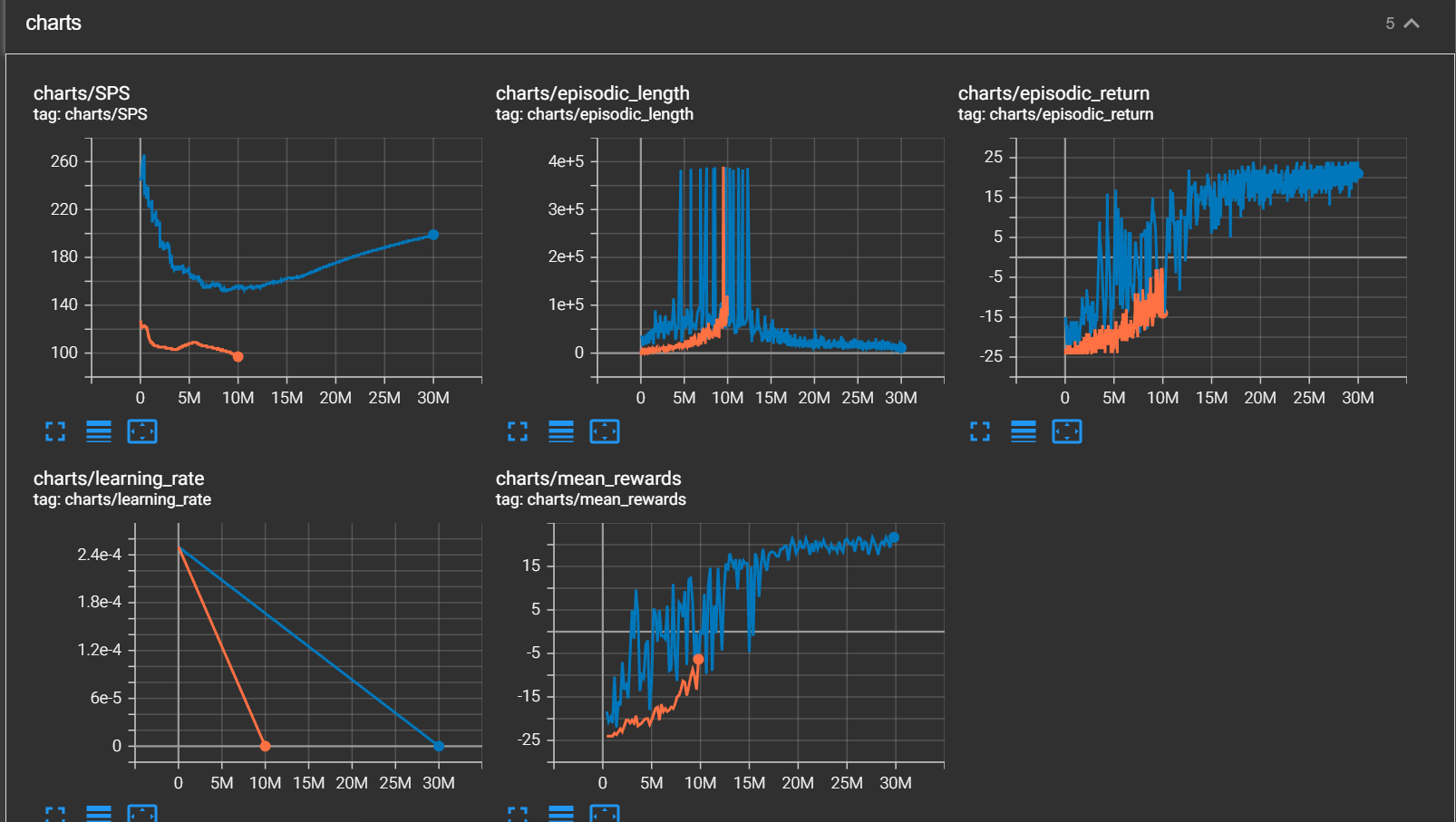
其中 mean_rewards 边训练边多次评估的平均reward的情况,可以发现无论是 episodic-return 还是 mean_rewards 都是稳步上升的。
python ppo_tennis.py --eval默认加载的是 models/TennisNoFrameskip-v4__ppo_tennis__1__1658753671/best.pt 这个训练好的模型, 通过 --model-path 更改待评估模型地址,部分评估录像效果展示如下:

首先了解下atari下tennis的规则,同现实网球比赛一样, 一盘比赛的获胜条件如下
一方先胜6局为胜1盘;双方各胜5局时,一方净胜两局为胜1盘。
而每个小局的获胜条件如下:
每胜1球得1分,先胜4分者胜1局。双方各得3分时为“平分”,平分后,净胜两分为胜1局。
其次每个小局过后由球员交替发球
因此tennis-wrapper 需要在重载reset函数时,需要初始化 小局比分,大比分, 发球手 三个信息
class TennisWrapper2(gym.Wrapper):
def reset(self, **kwargs):
obs = self.env.reset(**kwargs)
self.current_score = [0,0] #小比分
self.score = [0,0] #大比分
self.server = 0 #发球手, 一开始时为 player0
return obs此外在 重载 step 函数时,需要根据reward信息判断一回合结束,当回合结束时需要
- 根据规则更新小比分和大比分
- 如果一小局比赛结束,则需要更换发球手,并在info中显式返回发球手的action_mask
- 小局比赛结束,也需要显式调用 run_reset 处理僵直问题
def step(self, action):
#判断action是否illegel
assert self.action_mask[action], "not a legal action"
#执行相应的动作
obs, reward, done, info = self.env.step(action)
#每回合结束
if reward != 0:
run_winner = 0 if reward == 1 else 1
run_winner = 0 if reward == 1 else 1
self.current_score[run_winner] += 1
# 每小局胜利条件
if self.current_score[run_winner] >= 4 and self.current_score[run_winner] - self.current_score[1-run_winner]>=2:
self.current_score = [0,0]
self.score[run_winner] += 1
self.server = 1 - self.server #更换发球者
obs = self.run_reset(obs.copy())
info["action_mask"] = self.action_mask
return obs, reward, done, info在开球状态下哪些动作为非法动作呢 ,这个就需要查询官网了, 各个动作行为解释如下:
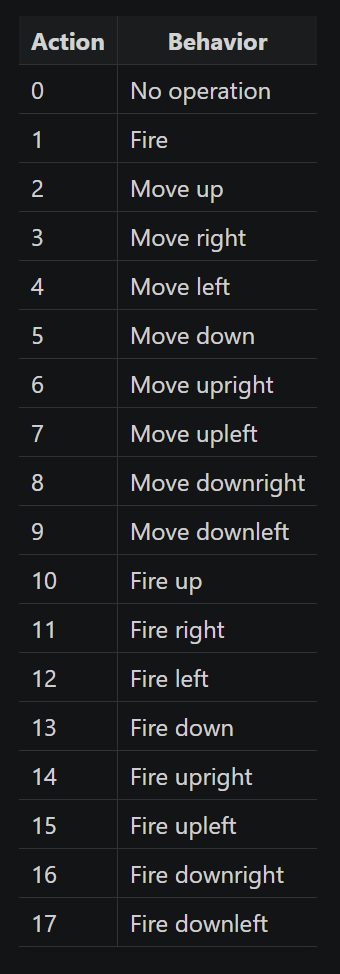
含有Fire的Action为合法的开球动作,基于此完成 action_mask 函数
@property
def action_mask(self):
am = np.array([True]*self.action_space.n)
if self.server == 0 and self.run_length == 0:
am[[0] + list(range(2,10))] = False
return am所谓的僵直问题,则为小局结束后一段时间内;无论传入什么Action,都没有效果,游戏画面也不动。此时我们选择手动传入时间的 action:0也就是 no-op 待僵直问题恢复后,再进行正常的训练。