
The simplest implementation for playing Atari games using game screen as input. Also contains code to implement visual foresight using adversarial action conditioned video prediction model (Still working on this).
Paper: Playing Atari the right way!, ECE6504 Project, 2017
Install virtualenv and creating a new virtual environment:
pip install virtualenv
virtualenv -p /usr/bin/python3 atari
Install dependencies
pip3 install -r requirements.txt
Notes:
-
Training the agent to play breakout at a reasonable level took about 80 hours on two p100s. Don't even think about running this on a CPU. I would highly appreciate it if you can submit a pull request that makes training faster (I know some of my methods suck).
-
The trained models can easily be used to test the performance of an agent on a CPU.
python3 play_cartpole.py
To change the hyperparameters modify mission_control_cartpole.py.
Note:
- This isn't as computationally demanding as Breakout using frames.
python3 play_breakout.py
To change the hyperparameters modify mission_control_breakout.py.
Note:
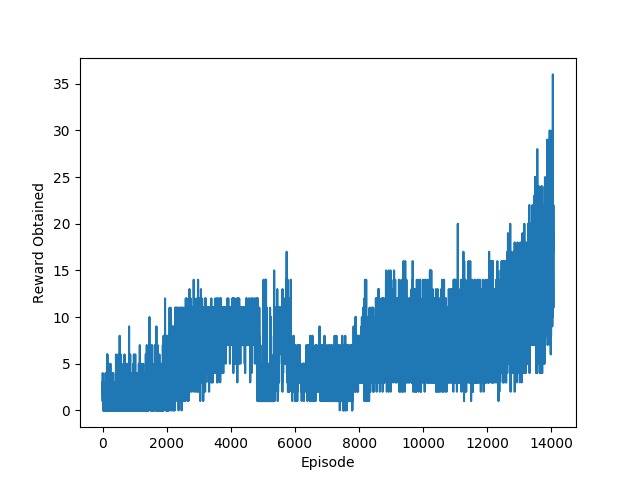
- I have included the trained model for Breakout after 14 million episodes. Just explore the Results director for Breakout.
- Change
train_modeltoFalseandshow_uitoTrueto load the saved model and see the agent in action.
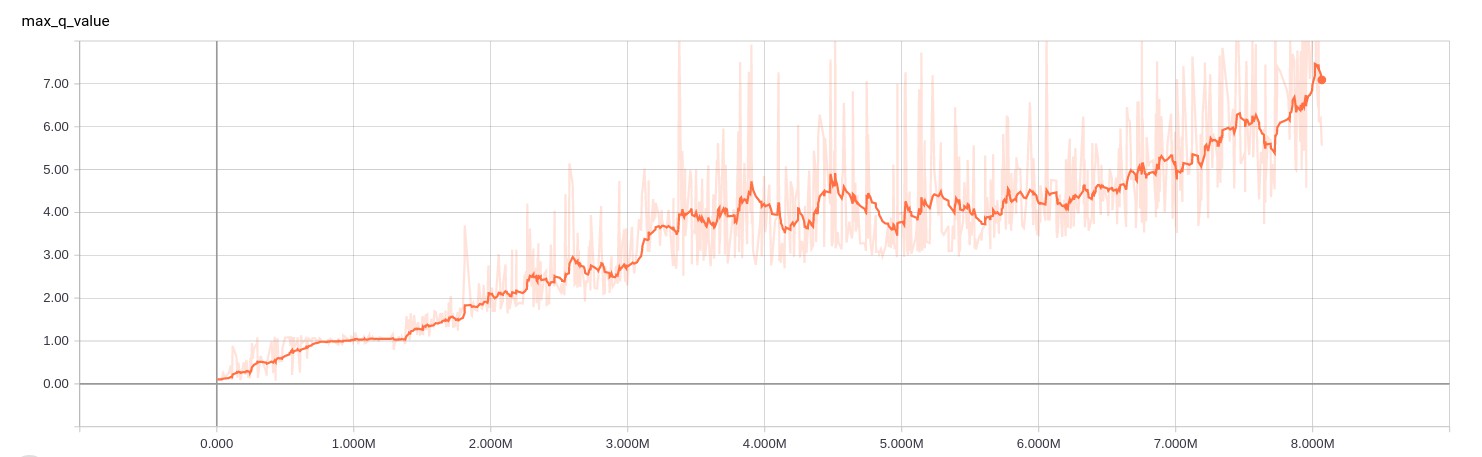
python3 generate_dataset.py
Note:
- You might get some directory nt found errors (Will fix it soon) or just figure it out.
python3 generate_model_skip.py
Note:
- This uses the adversarial action conditioned video prediction model.
- Run
generate_model.pyto use the architecture from [2].

python3 play_breakout_ram.py
To change the hyperparameters modify mission_control_breakout_ram.py.
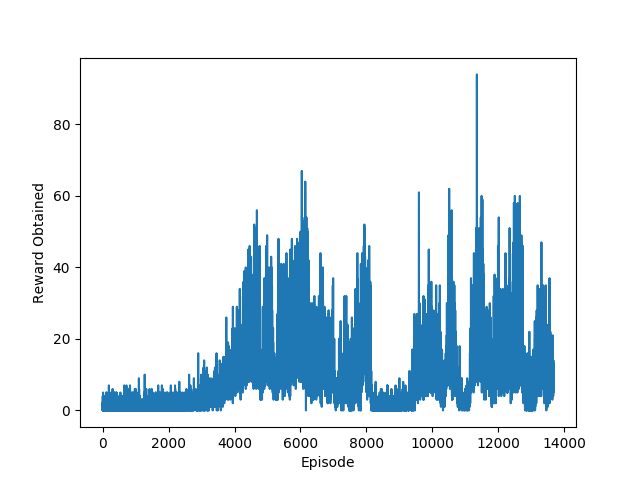
Note:
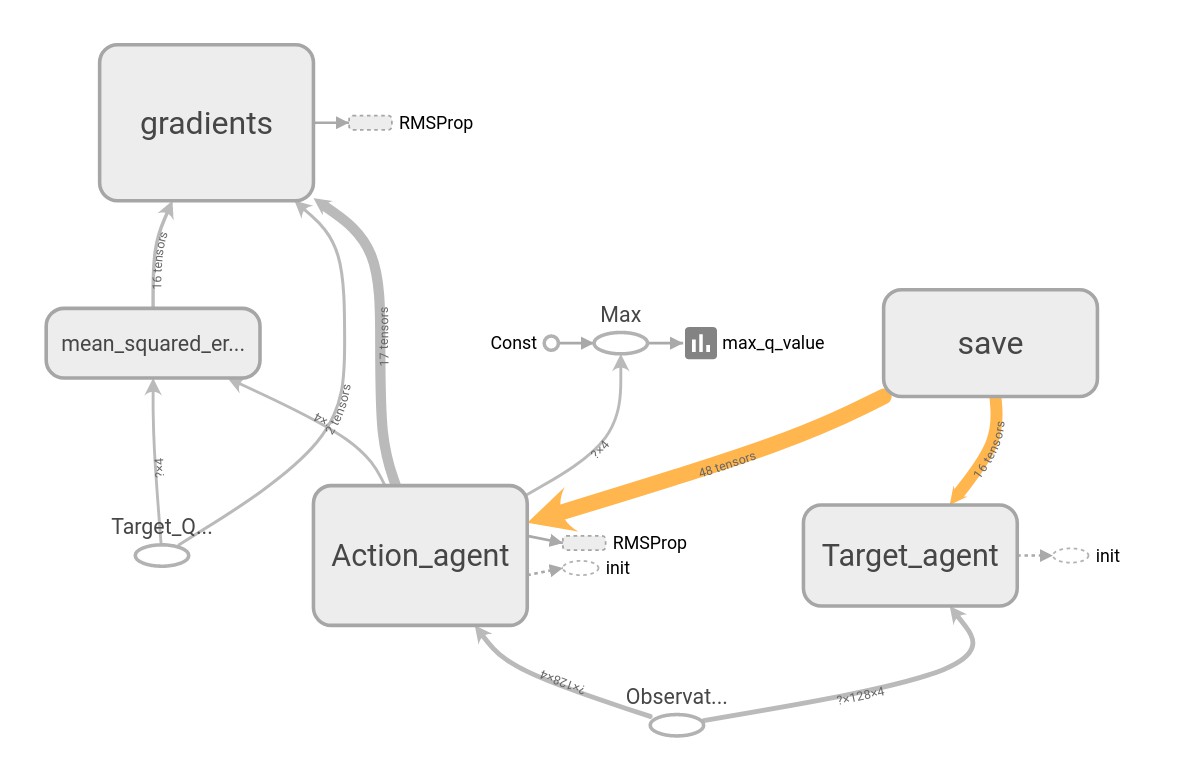
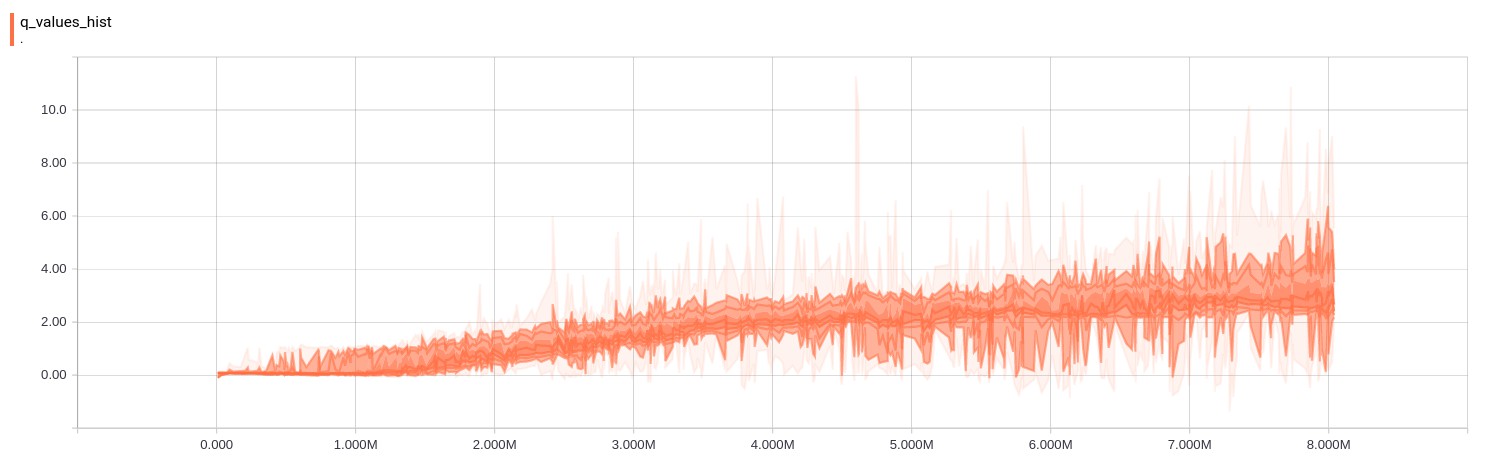
- Each run generates a required tensorboard files under
./Results/<model>/<time_stamp_and_parameters>/Tensorboarddirectory. - Use
tensorboard --logdir <tensorboard_dir>to look at loss variations, rewards and a whole lot more. - Windows gives an error when
:is used during folder naming (this is produced during the folder creation for each run). I would suggest you to remove the time stamp fromfolder_namevariable in theform_results()function. Or, just dual boot linux!
[1] Human Level Control Through Deep Reinforcement Learning
[2] Action-Conditional Video Prediction using Deep Networks in Atari Games