This is the development repository of GPU-accelerated LightGBM. LightGBM is a popular Gradient Boosted Decision Tree (GBDT) training system, and has been shown to be faster than XGBoost on large-scale datasets. Our aim is to accelerate the feature histogram construction in LightGBM on GPUs, and we propose an efficient algorithm on GPU to accelerate this process. Our implementation is highly modular and does not affect existing features of LightGBM.
Please consider this repository experimental. If you find any problems during using GPU acceleration, please send an email to Huan Zhang or open an GitHub issue.
GPU acceleration support has been merged into upstream LightGBM in commit 0bb4a82.
The following dependencies should be installed before compilation:
-
OpenCL 1.2 headers and libraries, which is usually provided by GPU manufacture.
The generic OpenCL ICD packages (for example, Debian packageocl-icd-libopencl1andocl-icd-opencl-dev) can also be used. -
libboost 1.56 or later (1.61 or later recommended). We use Boost.Compute as the interface to GPU, which is part of the Boost library since version 1.61. However, since we include the source code of Boost.Compute as a submodule, we only require the host has Boost 1.56 or later installed. We also use Boost.Align for memory allocation. Boost.Compute requires Boost.System and Boost.Filesystem to store offline kernel cache. The following Debian packages should provide necessary Boost libraries:
libboost-dev, libboost-system-dev, libboost-filesystem-dev. -
CMake 3.2 or later for reliably detecting OpenCL and libboost.
Currently only building on Linux has been tested, but it should also work with MinGW on Windows as long as all dependencies are available. To build LightGBM-GPU, use the following procedure:
First clone this repository:
git clone --recursive https://github.com/huanzhang12/lightgbm-gpu.git
Then run cmake and make:
cd lightgbm-gpu
mkdir build ; cd build
cmake -DUSE_GPU=1 ..
make -j$(nproc)
To enable the GPU tree trainer, simply passing the parameter device=gpu to
LightGBM. GPU acceleration works for distributed tree learners as well; for
example, you can specify tree_learner=feature and device=gpu to accelerate
the feature-parallel based distributed learner. Setting tree_learner=gpu is
a shortcut for tree_leaner=serial and device=gpu.
The following new parameters are added:
-
device: can be set togpuorcpu. -
gpu_platform_id: OpenCL Platform ID (default: -1, selecting the default OpenCL platform). This is useful only when you have OpenCL devices from different vendors. -
gpu_device_id: OpenCL Device ID (default: -1, selecting the default device). Specify which GPU to run on if you have multiple GPUs installed. -
gpu_use_dp: When setting totrue, double precision GPU kernels will be used (default:false, using single precision). When setting totrue, the GPU tree trainer should generate (almost) identical results as the CPU trainer, at least for the first a few iterations. -
sparse_threshold: The threshold of zero elements percentage for treating a feature as dense feature. When setting to 1, all features are processed as dense features (default: 0.8).
Our GPU code targets AMD Graphics Core Next (GCN) architecture and NVIDIA Maxwell and Pascal architectures. Most AMD GPUs released after 2012 and NVIDIA GPUs released after 2014 should be supported. We have tested the GPU implementation on the following GPUs:
- AMD RX 480 with AMDGPU-pro driver 16.60 on Ubuntu 16.10
- AMD R9 280X with fglrx driver 15.302.2301 on Ubuntu 16.10
- NVIDIA GTX 1080 with driver 375.39 and CUDA 8.0 on Ubuntu 16.10
- NVIDIA Titan X (Pascal) with driver 367.48 and CUDA 8.0 on Ubuntu 16.04
The use of the following hardware is discouraged:
-
NVIDIA Kepler (K80, K40, K20, most GeForce GTX 700 series GPUs) or earlier NVIDIA GPUs. They don't support hardware atomic operations in local memory space and thus histogram construction will be slow.
-
AMD VLIW4-based GPUs, including Radeon HD 6xxx series and earlier GPUs. These GPUs have been discontinued for years and are rarely seen nowadays.
Datasets HIGGS, Yahoo LTR, Microsoft LTR and Expo that are used for LightGBM benchmarks work on GPUs with good speedup. To prepare these datasets, follow the instructions in this repo.
We also tested our implementation with the epsilon dataset, available at
LibSVM Datasets.
Other large (preferably dense) datasets are also good targets for GPU
acceleration. Currently, we construct histograms for dense features on GPU
and construct histograms for sparse features on CPU simultaneously. The
parameter sparse_threshold can be used to balance the work on GPU and CPU.
The following configuration can be used for training these large-scale datasets on GPU:
max_bin = 63
num_leaves = 255
num_iterations = 500
learning_rate = 0.1
tree_learner = serial
task = train
is_train_metric = false
min_data_in_leaf = 1
min_sum_hessian_in_leaf = 100
ndcg_eval_at = 1,3,5,10
sparse_threshold=1.0
device = gpu
gpu_platform_id = 0
gpu_device_id = 0
num_thread = 28
The last three parameters should be customized based on your machine configuration;
num_thread should match the total number of cores in your system, gpu_platform_id
and gpu_device_id select the GPU to use. If you have a hybrid GPU setting,
make sure to select the high-performance discrete GPU, not the integrated GPU.
The OpenCL platform ID and device ID can be looked up using the clinfo utility.
-
You want to run a few datasets that we have verified with good speedup (including Higgs, epsilon, Bosch, etc) to ensure your setup is correct. Make sure your system is idle (especially when using a shared computer) to get accuracy performance measurements.
-
GPU works best on large scale and dense datasets. If dataset is too small, computing it on GPU is inefficient as the data transfer overhead can be significant. For dataset with a mixture of sparse and dense features, you can control the
sparse_thresholdparameter to make sure there are enough dense features to process on the GPU. If you have categorical features, use thecategorical_columnoption and input them into LightGBM directly; do not convert them into one-hot variables. Make sure to check the run log and look at the reported number of sparse and dense features. -
To get good speedup with GPU, it is suggested to use a smaller number of bins. Setting
max_bin=63is recommended, as it usually does not noticeably affect training accuracy on large datasets, but GPU training can be significantly faster than using the default bin size of 255. For some dataset, even using 15 bins is enough (max_bin=15); using 15 bins will maximize GPU performance. Make sure to check the run log and verify that the desired number of bins is used. -
Try to use single precision training (
gpu_use_dp=false) when possible, because most GPUs (especially NVIDIA consumer GPUs) have poor double-precision performance.
The following example shows how to run the higgs dataset with GPU acceleration.
# build LightGBM with GPU support enabled
git clone --recursive https://github.com/huanzhang12/lightgbm-gpu.git
cd lightgbm-gpu
mkdir build ; cd build
cmake -DUSE_GPU=1 ..
make -j$(nproc)
# Executable lightgbm should be generated here
cd ..
# Now clone the LightGBM benchmark repo for data preparation
git clone https://github.com/guolinke/boosting_tree_benchmarks.git
cd boosting_tree_benchmarks/data
# Download data and unzip
wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00280/HIGGS.csv.gz"
gunzip HIGGS.csv.gz
# Prepare the dataset. This will take some time. At the same time you can read how to prepare other datasets.
cat readme.md && python higgs2libsvm.py
cd ../..
ln -s boosting_tree_benchmarks/data/higgs.train
ln -s boosting_tree_benchmarks/data/higgs.test
# Now we have higgs.train and higgs.test ready
# Generate a configuration file. Remember to check GPU platform ID and device ID if you have multiple GPUs
cat > lightgbm_gpu.conf <<EOF
max_bin = 63
num_leaves = 255
num_iterations = 500
learning_rate = 0.1
tree_learner = serial
task = train
is_train_metric = false
min_data_in_leaf = 1
min_sum_hessian_in_leaf = 100
ndcg_eval_at = 1,3,5,10
sparse_threshold = 1.0
device = gpu
gpu_platform_id = 0
gpu_device_id = 0
EOF
echo "num_threads=$(nproc)" >> lightgbm_gpu.conf
# Now we are ready to run GPU accelerated LightGBM!
# Accuracy test on GPU (make sure to verify the "Using GPU Device" line in output):
./lightgbm config=lightgbm_gpu.conf data=higgs.train valid=higgs.test objective=binary metric=auc
# Speed test on GPU:
./lightgbm config=lightgbm_gpu.conf data=higgs.train objective=binary metric=auc
# Accuracy reference (on CPU):
./lightgbm config=lightgbm_gpu.conf device=cpu data=higgs.train valid=higgs.test objective=binary metric=auc
# Speed reference (on CPU):
./lightgbm config=lightgbm_gpu.conf device=cpu data=higgs.train objective=binary metric=auc
Now let's try the epsilon dataset:
# assume we are in the same directory as the lightgbm binary
# download the dataset and extract them
wget http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/epsilon_normalized.bz2
bunzip2 epsilon_normalized.bz2
wget http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/epsilon_normalized.t.bz2
bunzip2 epsilon_normalized.t.bz2
sed -i 's/^-1 /0 /g' epsilon_normalized
sed -i 's/^-1 /0 /g' epsilon_normalized.t
mv epsilon_normalized epsilon.train
mv epsilon_normalized.t epsilon.test
# datasets are ready, now start training
# Accuracy test on GPU (make sure to verify the "Using GPU Device" line in output):
./lightgbm config=lightgbm_gpu.conf data=epsilon.train valid=epsilon.test objective=binary metric=auc
# Speed test on GPU (without calculating validation set AUC after each iteration):
./lightgbm config=lightgbm_gpu.conf data=epsilon.train objective=binary metric=auc
# Accuracy reference (on CPU):
./lightgbm config=lightgbm_gpu.conf device=cpu data=epsilon.train valid=epsilon.test objective=binary metric=auc
# Speed reference (on CPU):
./lightgbm config=lightgbm_gpu.conf device=cpu data=epsilon.train objective=binary metric=auc
Try to change the number of bins and see how that affects training speed:
# Speed test on GPU with max_bin size of 15:
./lightgbm config=lightgbm_gpu.conf data=epsilon.train objective=binary metric=auc max_bin=15
# Speed test on GPU with max_bin size of 63:
./lightgbm config=lightgbm_gpu.conf data=epsilon.train objective=binary metric=auc max_bin=63
# Speed test on GPU with max_bin size of 255:
./lightgbm config=lightgbm_gpu.conf data=epsilon.train objective=binary metric=auc max_bin=255
We used the following hardware to evaluate the performance of our GPU algorithm. Our CPU reference is a high-end dual socket Haswell-EP Xeon server with 28 cores; GPUs include a budget GPU (RX 480) and a mainstream (GTX 1080) GPU installed on the same server. It is worth mentioning that the GPUs used are not the best GPUs in the market; if you are using a better GPU (like AMD RX 580, NVIDIA GTX 1080 Ti, Titan X Pascal, Titan Xp, P100, etc), you are likely to get a better speedup.
| Hardware | Peak FLOPS | Peak Memory BW | Cost (MSRP) |
|---|---|---|---|
| AMD Radeon RX 480 | 5,161 GFLOPS | 256 GB/s | $199 |
| NVIDIA GTX 1080 | 8,228 GFLOPS | 320 GB/s | $499 |
| 2x Xeon E5-2683v3 (28 cores) | 1,792 GFLOPS | 133 GB/s | $3,692 |
During benchmarking on CPU we used only 28 physical cores of the CPU, and did not use hyper-threading cores, because we found that using too many threads actually makes performance worse.
We use the configuration described in the Datasets section above, except for
Bosch, where we use a smaller learning_rate=0.015 and set
min_sum_hessian_in_leaf=5. For all GPU training we set
sparse_threshold=1, and vary the max number of bins (255, 63 and 15). The
GPU implementation is from commit
0bb4a82
of LightGBM, when the GPU support was just merged in.
| Data | Task | Link | #Examples | #Feature | Comments |
|---|---|---|---|---|---|
| Higgs | Binary classification | link | 10,500,000 | 28 | use last 500,000 samples as test set |
| Epsilon | Binary classification | link | 400,000 | 2,000 | use the provided test set |
| Bosch | Binary classification | link | 1,000,000 | 968 | use the provided test set |
| Yahoo LTR | Learning to rank | link | 473,134 | 700 | set1.train as train, set1.test as test |
| MS LTR | Learning to rank | link | 2,270,296 | 137 | {S1,S2,S3} as train set, {S5} as test set |
| Expo | Binary classification (Categorical) | link | 11,000,000 | 700 | use last 1,000,000 as test set |
The following table lists the accuracy on test set that CPU and GPU algorithms can achieve after 500 iterations. GPU with the same number of bins can achieve a similar level of accuracy as on the CPU, despite using single precision arithmetic. For most datasets, using 63 bins is sufficient.
| CPU 255 bins | CPU 63 bins | CPU 15 bins | GPU 255 bins | GPU 63 bins | GPU 15 bins | |
|---|---|---|---|---|---|---|
| Higgs AUC | 0.845612 | 0.845239 | 0.841066 | 0.845612 | 0.845209 | 0.840748 |
| Epsilon AUC | 0.950243 | 0.949952 | 0.948365 | 0.950057 | 0.949876 | 0.948365 |
| Yahoo-LTR NDCG@1 | 0.730824 | 0.730165 | 0.729647 | 0.730936 | 0.732257 | 0.73114 |
| Yahoo-LTR NDCG@3 | 0.738687 | 0.737243 | 0.736445 | 0.73698 | 0.739474 | 0.735868 |
| Yahoo-LTR NDCG@5 | 0.756609 | 0.755729 | 0.754607 | 0.756206 | 0.757007 | 0.754203 |
| Yahoo-LTR NDCG@10 | 0.79655 | 0.795827 | 0.795273 | 0.795894 | 0.797302 | 0.795584 |
| Expo AUC | 0.776217 | 0.771566 | 0.743329 | 0.776285 | 0.77098 | 0.744078 |
| MS-LTR NDCG@1 | 0.521265 | 0.521392 | 0.518653 | 0.521789 | 0.522163 | 0.516388 |
| MS-LTR NDCG@3 | 0.503153 | 0.505753 | 0.501697 | 0.503886 | 0.504089 | 0.501691 |
| MS-LTR NDCG@5 | 0.509236 | 0.510391 | 0.507193 | 0.509861 | 0.510095 | 0.50663 |
| MS-LTR NDCG@10 | 0.527835 | 0.527304 | 0.524603 | 0.528009 | 0.527059 | 0.524722 |
| Bosch AUC | 0.718115 | 0.721791 | 0.716677 | 0.717184 | 0.724761 | 0.717005 |
We record the wall clock time after 500 iterations, as shown in the figure below:
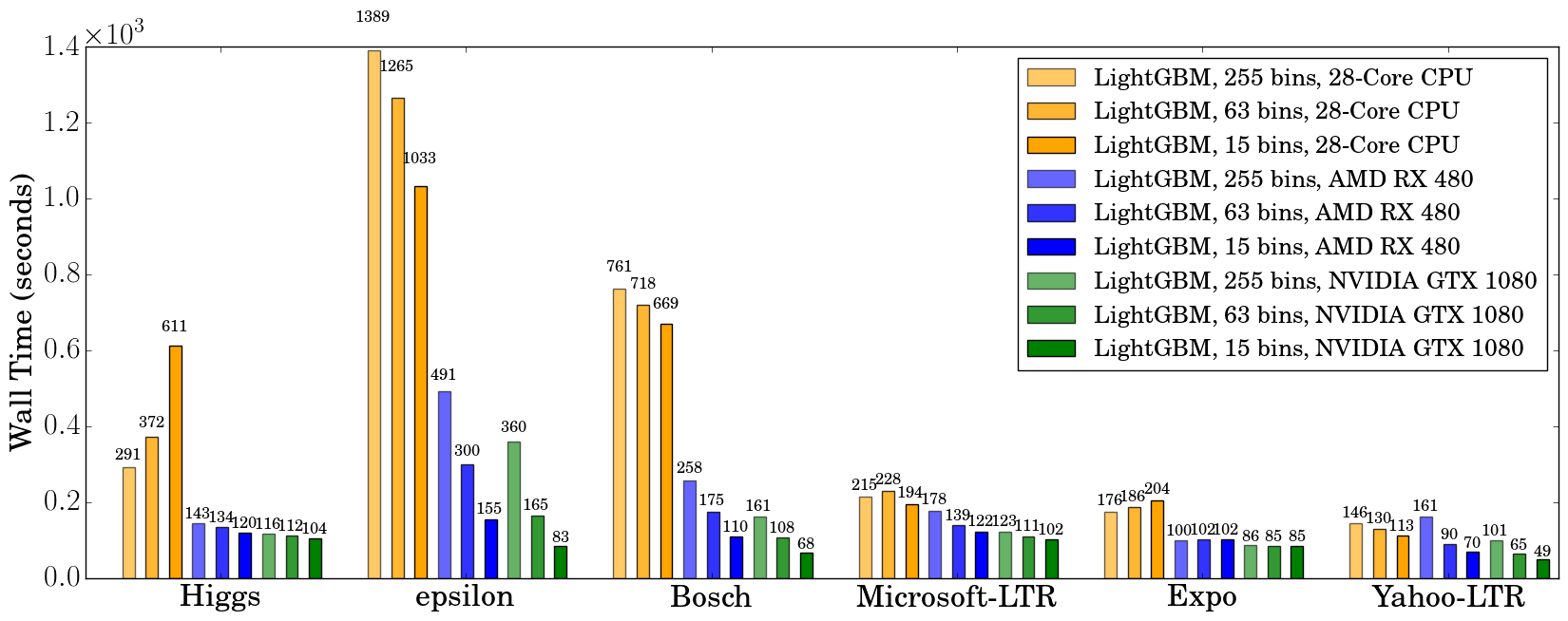
When using a GPU, it is advisable to use a bin size of 63 rather than 255, because it can speed up training significantly without noticeably affecting accuracy. On CPU, using a smaller bin size only marginally improves performance, sometimes even slows down training, like in Higgs (we can reproduce the same slowdown on two different machines, with different GCC versions). We found that GPU can achieve impressive acceleration on large and dense datasets like Higgs and Epsilon. Even on smaller and sparse datasets, a budget GPU can still compete and be faster than a 28-core Haswell server.
The next table shows GPU memory usage reported by nvidia-smi during training
with 63 bins. We can see that even the largest dataset just uses about 1 GB of
GPU memory, indicating that our GPU implementation can scale to huge
datasets over 10x larger than Bosch or Epsilon. Also, we can observe that
generally a larger dataset (using more GPU memory, like Epsilon or Bosch)
has better speedup, because the overhead of invoking GPU functions becomes
significant when the dataset is small.
| Datasets | Higgs | Epsilon | Bosch | MS-LTR | Expo | Yahoo-LTR |
|---|---|---|---|---|---|---|
| GPU Memory Usage (MB) | 611 | 901 | 1067 | 413 | 405 | 291 |
If you are interested in more details about our algorithm and benchmarks, please see our paper (to be published):
GPU Acceleration for Large-scale Tree Boosting
Huan Zhang, Si Si and Cho-Jui Hsieh, 2017.