Concepts illustrated
Let's take a simple example of calibration data, say "target position," which is defined by three coordinates x, y, z, each represented by floating point number.
Using C++ as an example language, if a user asks for "target position":
auto data = calibration->GetCalib("/target/position");the calibration database should provide the appropriate data in the current context so it can be used:
if (data["z"] > 30) ..."The current context" is the key phrase here, since the values of target position could be different for different runs, values may change with time, e.g., if more precise calibration is performed. Also, a user may want to use a personal version of data for various reasons.
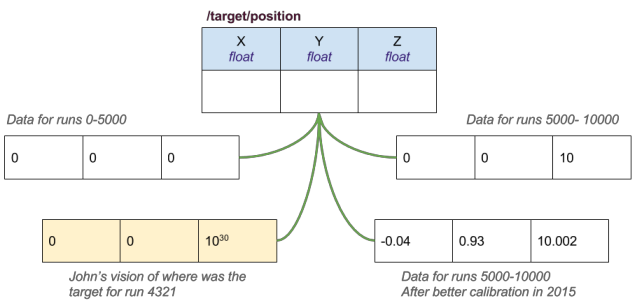
The picture above illustrates features of CCDB that involve control of the context:
- The data returned depends on run number.
- A history mechanism: by default CCDB honors the last assignment of data to a particular run, but one can always recover assignments made in the past.
- Variations (equivalent to "branches" in version control systems): users have the ability to create and work with alternative versions of the data, varying the run assignments and/or the data itself.
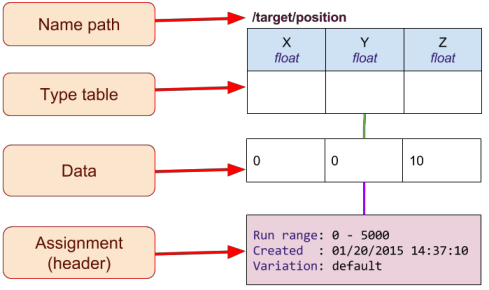
Data is associated by the namepath. The namepath string is unique across all detector systems. Forward slash(/) is used to specify a hierarchical namepath.
For example:
/target/position
/FDC/driftvelocity/timewalk_parameters
/FDC/base_time_offset
This allows implementors of individual detector systems to specify a hierarchy with as much or little depth as is needed, appropriate to the physical structure of their device.
Namepath format: Allowed symbols are a-z, A-Z, 0-9, '_' and '-'. Spaces or other special symbols are not allowed in the namepath (this simplifies console management and database validation of namepath objects).
/My-path/to/data_01 # OK
/Some...thing/is wrong here! # ERROR: illegal symbols '...', '!' and spaces.
Each namepath corresponds to a "table type". Table type * - defines columns and a number of rows. The idea behind of "type table" is that while data values may change, "the shape" of the table never does.
The term "table" is ambiguous when talking about data, and it is especially ambiguous when topic is related to databases. Thus CCDB uses the term "table type" for a definition of data (the shape), and "data set" or "constant set" for the data itself, i.g. values of table type.
In the example with target position, the namepath "/target/position" is a table type, defining data arranged in three columns of type "float" and one row. Whatever the values of /target/position are, they are always presented as one row of "x", "y", "z".
Each column has a type and may have a name. However column names are optional.
The "/target/position" example has 3 columns named "x", "y", and "z". They could be also identified as 0, 1, 2.
As another example, the /FDC/driftvelocity/timewalk_parameters parameters may have members
"slope", "offset", and "exponent".
By contrast, a set of constants with a namepath "/FDC/CathodeStrips/pedestals" may have 100 values identified simply as 0, 1, 2, 3, ...
Column types - Column types may be one of the following:
- int
- uint
- long
- ulong
- bool
- double
- string
Each table type may have multiple versions of constant sets, i.e. the data. Each constant set has at least one "assignment". The assignment holds the information specifying the association of the constant set with a context:
- run range - Runs for which the data is valid
- creation time - Creation time of the assignment (used for the history feature)
- variation - Name of the variation
- comment - Any useful comments about the assignment
One could say that assignment shows the context within which the data "is correct". One could also say that while a constant set is data, an associated assignment is a header for this data.
A particular constant set can have several assignments. This allows the use the same constants for different run ranges and helps avoid "update anomalies."
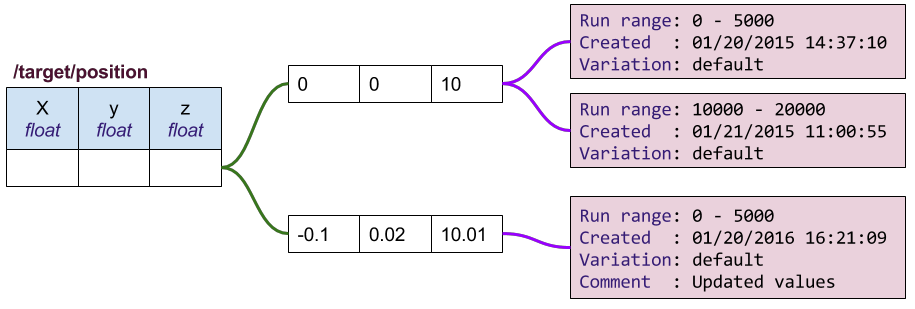
To summarize all of the above concepts: One namepath may have several versions of data (constant sets), each such constant set is connected to one or more assignments. These assignments hold information about the right context (run number, variation, date) for each constant set.
There are two use cases:
- In general, getting constants should be as easy as to say "Give me /target/position for June 2011"
- Sometimes need a way to name (and get) the particular set of constants. This means that there should be an unique key for every set of data.
CCDB uses so called "Requests" to solve both of the problems. The full form of the request is an "unique composite key" for the particular data values.
Full form of the request is
</path/to/data>:<run>:<variation>:<time>
But to get the data user can specify only a part of the request. The minimal request to get the data is just /path/to/data
One may omit any part of the request except name-path:
-
/path/to/data- just path to data, no run, variation and timestamp is specified -
/path/to/data::mc- no run specified, variation is "mc", no date specified -
/path/to/data:::2029- only path and date(year) are specified
So e.g. to to specify path and variation but to use the default run one skips the run number and leaves its place like "::"
+-- variation
|
/path/to/data::mc
|
+-- place where run number should be
And the request
/path/to/data:::2029
means that the path and the date are specified but a run number and a variation should be deduced. See the next chapter (Default values)
The time is parsed as:
YYYY:MM:DD-hh:mm:ss
Any non digit character may be used as separator instead of ':' and '-' so all these time strings are the same
2029/06/17-22:03:05
2029-06-17-22-03-05
2029/06/17:22/03/05
2029a06b17c22d03e05
One can omit any part of the time from the right. In this case the latest date for the omitted part is to be returned.
Example:
"2011" - (Year 2011. Everything else is omitted), it will be interpreted as 2011/12/31-23:59:59 timestamp so the latest constants for the year 2011 will be returned.
"2012/05/21" - it interpreted as 2012/05/21-23:59:59, meaning to be the latest constants for 21 May 2012
CCDB searches the latest constants .
WARNING - Don't use requests (instead of simple namepath) in C++ or Java production code. Use it to manage constants or for debugging. See the next chapter!
There are two general cases of the CCDB usage:
- To read out constants in physics analysis (or similar)
- To manage constants with ccdb console or python
In the case of physics analysis, most probably, the software provides a number of the run being processed and allows to set parameters like a variation name through command line arguments or environment variables.
JANA framework example:
> export JANA_CALIB_CONTEXT="variation=mc"
> hd_root data_for_run_5000.evioNow JANA knows that preferred variation is "mc" and the run number = 5000 is obtained from the data file. Thus when the constants are requested by namepaths "the right context" is deduced:
auto data = ccdb->GetCalib("/target/position");
// The latest data for run=5000 and variation=mc is selected CCDB defaults and priorities (first is the highest)
- Run number, variation or date specified in a request
if "/path/to/data:100" request is used, constants for run 100 are returned even if another run is actually being processed
- Run number, variation or date provided by outer software.
if 10200 run is being processed and
GetCalib("/path/to/data")is called data for run 10200 are returned - If it is not possible to deduce values
- run number 0
- variation "default"
- Current time
Example. ccdb command:
sh> ccdb -r 100 -i # interactive mode, run 100
ccdb> cat /path/to/data # commands get constants for run 100
ccdb> cat /path/to/data:333 # constants for run 333 are returned
# because request run has higher priority
sh> ccdb cat /path/to/data # constants for run 0 are returned
# no other run is given
Sometimes it is vital to get the particular data for debugging purposes. Requests are to be used in this case. Don't forget to remove everything beside a name-path after the debugging, because the production physics analysis code should never use requests, because run, variation and time given in requests override values provided by the software framework.
ccdb->GetCalib("/my/data"); // Good. Use only namepaths in production
ccdb->GetCalib("/my/data:333::2017-04"); // Danger! Use only to DEBUG,
// remove ':333::2017-04' after!!!In order to connect to data source, CCDB uses so called connection strings. The connection strings have the same
form for all API-s and the ccdb CLI tool. The general form is:
dialect://username:password@host:port/database
For MySQL and SQLite databases the connection strings are:
mysql://user_name:password@host:port/database
sqlite:///path_to_file
(!) Note that because SQLite doesn't have user_name and password, it starts with 3 (three) slashes ///.
And thus there are 4 (four) slashes //// in an absolute path to file.
sqlite:////home/user/example.db