This repository has been archived by the owner on Mar 14, 2023. It is now read-only.
Guru | Word Embeddings
- Normal vocabulary encoding doesn't help identify the relation between two words.
- We want a way to identify
manandwomanare opposites andappleandorangeare similar because they're fruits. - So we create multiple features per word. And give each feature a number. For instance, a
genderfeature may exist wheremangets a-1value and woman geta a+1value. This is merely an example. We'll have algorithms to optimize this entire process just like we do for neural network weights. - Embeddings would train on large embeddings of unlabelled text.
- A general word embedding usecase would look something like this.

- Word analogies can be made by taking the difference of their embedding vectors.
Man:Woman :: King:?eMan - eWoman = eKing - e?- Compare the vector difference between man-woman and king-queen
- Find a word W such that the cost between the embedding differences is minimum.
-
sim(eW, eKing - eMan + eWoman)should meadure the similarity between the two words. - The most common similarity used is Cosine similarity.
sim(u,v) = (u_t.V)/(|u||V|)
- The Embedding Matrix has dimensions
[features * vocab_size]. If E is the embedding matrix, thenE_6250 = E . O_6250.E_6250represents the corresponding Embedding column for the 6250th word in the vocabulary.O_6250is a one hot vector for the 6250th word.
- Get the Embedding vectors for every word in the sentence.
- Use the vectors as input for a softmax layer. The softmax layer will have its' own parameters.
- A historical window for the words. Take n words at a time instead of an entire sentence. Sentences have varying lengths. This is also the context that the algorithm is given to make a prediction.
- The Matrix
Eand the softmax layer parameters become the parameters for backprop. So we perform gradient descent to maximize the probability of the required output in the training set. - Works pretty well. Because the algorithm is incentivized to learn the relations between words. Recognizing similar words would allow it to make better predictions later on.
- The context could also be 4 words on the left and the right. Or any word in the sentence. The context could be the previous word or any nearby word in a sentence. The nearby word model is what's used in a skipgram model used by Word2Vec. While using a historical window is good for a language model, other types of contexts also work really well for learning word embeddings.
- Computationally inexpensive and faster
- Randomly pick a word to be the context. And randomly pick a word to be the target word.
Given a context word, predict what a randomly chosen word (target word) is in a given window.
- Use the above supervised learning problem to build good word emeddings.
O_c -> E -> e_c -> Softmax -> y_hat

- This is the SkipGram model.
- The problem with using a softmax classifier like the one above is because of the sum over the entire vocabulary. This takes too long.
- A better way is using heirarchial classifiers.
- Instead of having one classifier for the entire vocabulary, use a binary tree structure where every node is a classifier.
- The top node would tell if the target word would belong to the first half of the vocabulary or the second half of the vocabulary.
- This would be in logarithmic time.
- We could even skew the tree to have more common words on top and less common words deeper in the tree. This would improve the speed even further.
- How do you sample context c?
- We can't randomly sample because there are some words that occur very frequently (the, to, of, a..etc). Randomly sampling would cause frequent updates to the embedding matrix for these words but not for the less common but more useful words like orange, apple or durin.
- We use other heuristics for sampling.
Given a pair of words, do the pair of words form a context-target pair? Orange and Juice would form a positive pair. Orange and King would be a negative pair.
Orange and Juice => 1 Orange and Book, King, The, Of => 0
- To generate this data set, pick a context word and a target word nearby in the same sentence, and give them a label 1. The pick K random words from the dictionary and label it 0.
- So, we ask the algorithm, did I get these pair of words by taking them from the same sentence or by taking a random word from the dictionary.
- K = 5 to 20 for small datasets. 2 to 5 for larger datasets. For every positive example, we have K negative examples.
- Use a simple logistic regression model to train it.
- We basically would have N binary classifiers, where N is the size of the vocabulary. But instead of training all N of them at the same time, we train the actual target node and K random nodes.
- This is pretty cheap to compute.
- This is Negative Sampling. Because we choose K random negative words.
- Sample according to how often different words occurs. Which is trash.
- Samply uniformly randomly. Which has the same problem as before.
- Take somewhere in between. The 0.75 power heuristic.
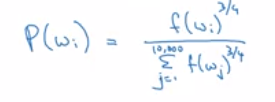
Experimentally found. Don't ask questions. Just roll with it.
INDIVIDUAL ROWS OF THE EMBEDDING MATRIX CANNOT HAVE HUMAN MEANING ATTACHED TO THEM.