whitepaper 202206
For almost 70 years, computing has focused on processing and programs. Chips were built into systems, into clusters of systems, into computing clouds. Throughout all of this, the focus has been on the program - its algorithm, how fast it is, how unique it is, and how it could provide an advantage over the competition. We are now in a new era - where the means of differentiation no longer lies in an algorithm, but in the quantity and quality of data to which one has access. It is truly a data-dominated world -- businesses are opened and closed based on their ability to collect quality data.
In 2020, human society passed an incredible milestone -- it amassed more total data in the digital universe than all words spoken in human history -- the total digital universe size of 44 Zettabytes crossed the total spoken universe size of 42 Zettabytes.1 2 3
 The idea is to learn insights by deriving patterns from data. The better the data, the better the insights -- therefore, if one can
use the volumes of data gathered from decades or centuries in business, it provides a competitive advantage. But this data exists
beyond the cloud -- in countless repositories in on-premise storage and even in mainframes.
The idea is to learn insights by deriving patterns from data. The better the data, the better the insights -- therefore, if one can
use the volumes of data gathered from decades or centuries in business, it provides a competitive advantage. But this data exists
beyond the cloud -- in countless repositories in on-premise storage and even in mainframes.
AI algorithms work by training a model on the data. This training process requires specialized hardware, usually in the form of GPUs, which are quite expensive, not only to purchase, but to operate, as they are very power-intensive. Supply-chain constraints have also made it difficult for anyone but the largest purchasers to obtain this hardware. Therefore, there is a lot of desire to use public cloud GPU resources as a more cost-effective way to operate AI systems.
However, businesses have always looked to avoid vendor lock-in by using open source software. In this new world, that is not enough -- even open source software that can only access data within a single public cloud or region is still lock-in. It's important to think beyond just open source and think also about openness of access to your organization's data, wherever it is.
With this in mind, how can enterprises modernize their approach to the data-driven world while still avoiding lock-in? For enterprises that have been careful to do so, how does the new data- and AI-driven world affect this?
The first thing to realize is that the value is in the data rather than in the algorithms. The algorithms being run are all open source, and they are all the same. The concept of "open" needs to expand beyond "open source" to achieve the benefits originally envisioned by open source. Specifically, private data must be securely shareable to train public cloud AI systems. We believe an open, secure fabric for sharing private data into public cloud AI systems can achieve the following:
- Keep individual data sets separate and controlled by their owners
- Collaborate with other enterprises without sharing data
- Sharing data causes problems due to regulations, permissions, security
- Share AI models across this shared data environment
- Share expensive, hard-to-get hardware, and use it for the most appropriate purpose
- Use Federated Learning so that data can remain near where it is analyzed
To a large extent, data becomes locked away in the systems where it is collected. IT projects are largely a means of finding ways to unlock this data. AI projects, because they are so data-dependent, are really not that different. If any AI model has equal access to any data in the enterprise, then one can truly say that the enterprise is maximizing its value from its data.
 Early approaches to solving this problem were done
with "data lake" architectures, but these exhibit several problems -- they are expensive, due to their duplicate storage
requirements (if certain types of middleware are used to enter/exit the data lake, then storage duplication occurs yet again, for a
4x requirement). They also have regulatory and security issues, because data that used to be compartmentalized is now in one place,
meaning that any future breach would have a high risk. Finally, they are not real-time, as the lake is filled before it is used, so
the fill period adds latency.
Early approaches to solving this problem were done
with "data lake" architectures, but these exhibit several problems -- they are expensive, due to their duplicate storage
requirements (if certain types of middleware are used to enter/exit the data lake, then storage duplication occurs yet again, for a
4x requirement). They also have regulatory and security issues, because data that used to be compartmentalized is now in one place,
meaning that any future breach would have a high risk. Finally, they are not real-time, as the lake is filled before it is used, so
the fill period adds latency.
A more modern approach is to provide a service layer interconnect to the source of the data, so the consumer can access it as needed. This is the initial use case of how we use the skupper.io project, which we will cover in more detail.
Finally, the most futuristic approach is called federated learning. This is where hardware is available near each data source to do learning, and only the aggregate parameter values are collected by the model. No data is ever shared over the network. One example of how Federated Learning can be used in practice is Google's predictive typing.
To do federated learning in an open, interoperable manner, we need a secure AI fabric to cross different domains of trust to collect the parameter values. We can reuse the skupper.io project for this purpose as well, as outlined in the proposal for the National AI Research Resource -- NAIRR.
While new investments in AI projects are being spent in "green field" areas such as Kubernetes, the vast majority of data in large enterprises is still in either "brown field" VMs or "grey field" legacy systems. The most valuable data is the most protected data, and this is not cloud-native -- in fact, decades of information still may be in mainframes. Wholesale migration efforts to cloud, if there is no specific business value, can also lead to the loss of critical knowledge. As Joel Spolsky famously wrote decades ago, and is still true today:
When you throw away code and start from scratch, you are throwing away all that knowledge. All those collected bug fixes. Years of programming work.
You are throwing away your market leadership. You are giving a gift of two or three years to your competitors, and believe me, that is a long time in software years.
-- Joel Spolsky, "Things You Should Never Do," April 6, 2000
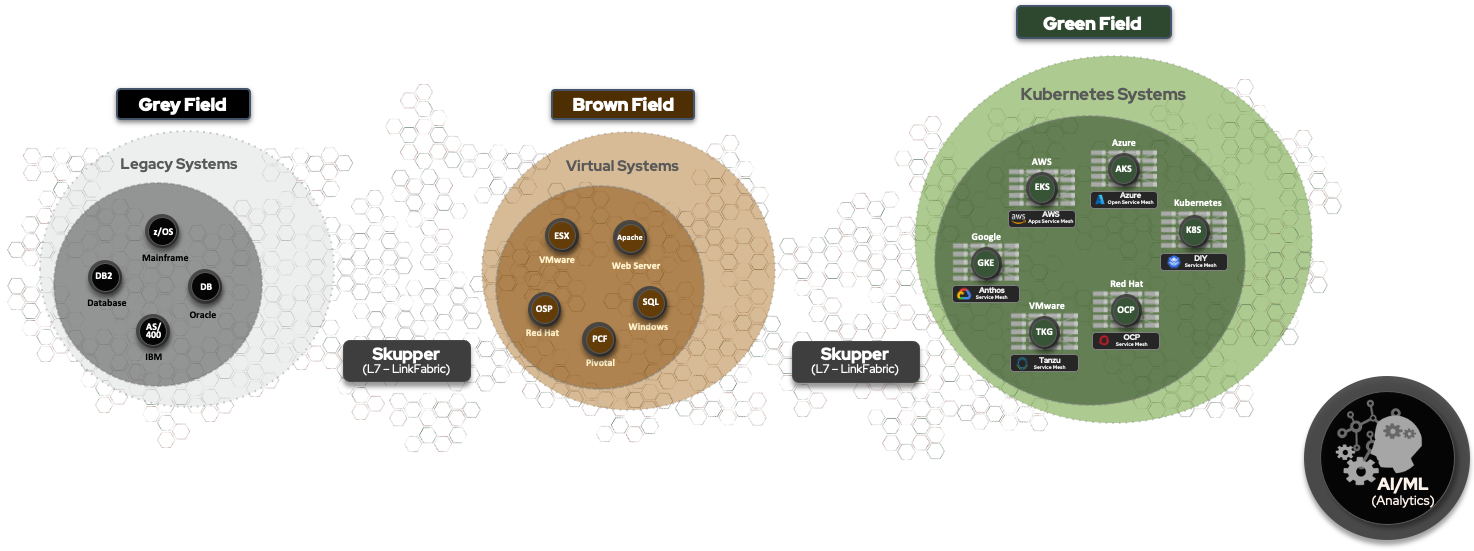 A better way to resolve this is to use the service-layer interconnect
mechanism to bring together these silos, so that valuable legacy data built up over decades in business can be used in place, to
train AI models in the cloud, with no code changes or porting.
A better way to resolve this is to use the service-layer interconnect
mechanism to bring together these silos, so that valuable legacy data built up over decades in business can be used in place, to
train AI models in the cloud, with no code changes or porting.
Even as these clustered systems have expanded to "multi-cluster" systems, most solutions assume that these environments are all homogeneous -- running a single vendor's Kubernetes, and in most cases the same exact version. This doesn't fit with the demands of the modern AI-driven enterprise. Parts of the application may be using ISVs specifically designed for Amazon's Sagemaker APIs -- they must run on EKS. The database may have data subject to regulatory constraints that require it to be in a private environment on OpenShift.
Modern application design shows that it is possible to secure OTT environments. Witness the rise of specific web-based app suites – Microsoft 365, Google Apps, Salesforce, and Slack. These provide safe environments in handling confidential corporate data without the need for complex networking reconfiguration. Given that is the case, why can’t enterprise applications also follow the same path?
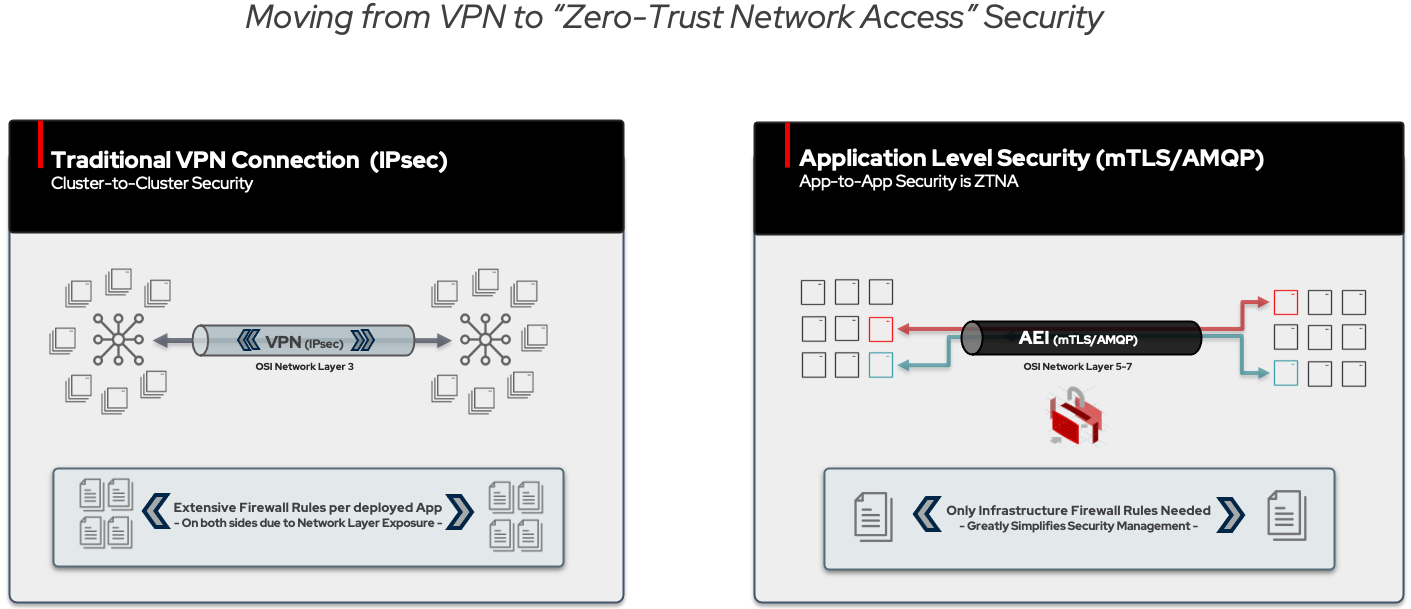
The skupper.io project provides a foundation for a Zero Trust Network Access (ZTNA) “security-by-design” (instead of “security-by-orchestration”) to give AI systems access to critical proprietary data. Only the service access point of the application is exposed, not the whole network where it is running. The result is compartmentalization -- the concept that a vulnerability in one application will not reveal all the other applications.
From a security perspective, everything is secured by mutual TLS, with keys that can be time- or usage-bound. In this way, one can
provide access across different administrative domains without fully "opening up" access. Further, all traffic sourced from the
identified Kubernetes services will flow out only from the defined IP addresses of the mTLS links -- it will not be random as would
happen with general Kubernetes environments. The internal framing protocol is based on ISO 19464, so with appropriate management
software, can be examined with network tools in a fully open manner. Finally, since routing is done only by service names, it is
not necessary to be concerned with uniqueness of IP addresses in each environment before providing connectivity. Service-based
routing also allows for traversing one or multiple DMZs should that be necessary.
Some use cases that apply to this technology include:
- AI training / learning with proprietary data
- Connect to proprietary data sources without major network issues
- Partial migration
- Making parts of your application cloud-native, while keeping others as-is
- Cloud-native database instance replication
- Creating instances of cloud-native databases on environments that differ from each other (MongoDB on OpenShift + EKS)
- Cloud-Native Data and App-to-App Connectivity
- Connecting cloud-native instances hosting data even over unreliable links, even when running on different versions of k8s (i.e., EKS, AKS, GKE, Tanzu, OCP, etc.) or operating systems. (Generalization of above, i.e. even Redis, Kafka)
- Harmonizing IPv4 Applications with IPv6 Networks
- Enable IPv4 applications to work over IPv6 networks transparently.
- Telemetry Capture
- Collect continuous streams of data from disparate sources efficiently, without taxing system resources and/or building large storage clusters at every aggregation point.
- Support Data Locality + Governance
- Proper governance of data for regulatory purposes requires locating data in various geographic regions and having instances of applications that process such data in those regions. These instances need to be connected.
AI permeates the enterprise -- it is not simply a matter of creating an "AI team" and having them do some work. The skupper.io
project can serve as a critical foundation for a fully open Zero-Trust AI Fabric strategy to ensure trusted access to your
proprietary data from public resources.
