-
Notifications
You must be signed in to change notification settings - Fork 2
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Signed-off-by: Zhiyuan Chen <[email protected]>
- Loading branch information
1 parent
c322030
commit 2be9a54
Showing
6 changed files
with
416 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,9 @@ | ||
| --- | ||
| authors: | ||
| - Zhiyuan Chen | ||
| date: 2024-05-04 | ||
| --- | ||
|
|
||
| # EternaBench | ||
|
|
||
| --8<-- "multimolecule/datasets/eternabench/README.md:21:" |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,110 @@ | ||
| --- | ||
| language: rna | ||
| tags: | ||
| - Biology | ||
| - RNA | ||
| license: | ||
| - agpl-3.0 | ||
| size_categories: | ||
| - 1K<n<10K | ||
| task_categories: | ||
| - text-generation | ||
| - fill-mask | ||
| task_ids: | ||
| - language-modeling | ||
| - masked-language-modeling | ||
| pretty_name: EternaBench-ChemMapping | ||
| library_name: multimolecule | ||
| --- | ||
|
|
||
| # EternaBench-ChemMapping | ||
|
|
||
| 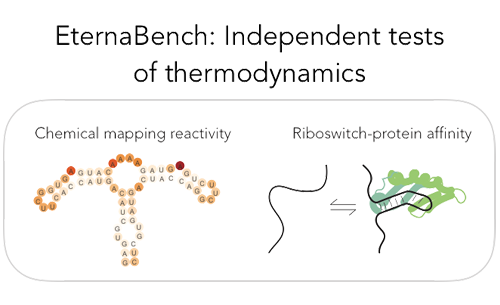 | ||
|
|
||
| EternaBench-ChemMapping is a synthetic RNA dataset comprising 12,711 RNA constructs that have been chemically mapped using SHAPE and MAP-seq methods. | ||
| These RNA sequences are probed to obtain experimental data on their nucleotide reactivity, which indicates whether specific regions of the RNA are flexible or structured. | ||
| The dataset provides high-resolution, large-scale data that can be used for studying RNA folding and stability. | ||
|
|
||
| ## Disclaimer | ||
|
|
||
| This is an UNOFFICIAL release of the [EternaBench-ChemMapping](https://github.com/eternagame/EternaBench) by Hannah K. Wayment-Steele, et al. | ||
|
|
||
| **The team releasing EternaBench-ChemMapping did not write this dataset card for this dataset so this dataset card has been written by the MultiMolecule team.** | ||
|
|
||
| ## Dataset Description | ||
|
|
||
| - **Homepage**: https://multimolecule.danling.org/datasets/eternabench_cm | ||
| - **datasets**: https://huggingface.co/datasets/multimolecule/eternabench-cm | ||
| - **Point of Contact**: [Rhiju Das](https://biochemistry.stanford.edu/people/rhiju-das/) | ||
|
|
||
| The dataset includes a large set of synthetic RNA sequences with experimental chemical mapping data, which provides a quantitative readout of RNA nucleotide reactivity. These data are ensemble-averaged and serve as a critical benchmark for evaluating secondary structure prediction algorithms in their ability to model RNA folding dynamics. | ||
|
|
||
| ## Example Entry | ||
|
|
||
| | index | design | sequence | secondary_structure | reactivity | errors | signal_to_noise | | ||
| | -------- | ---------------------- | ---------------- | ------------------- | -------------------------- | --------------------------- | --------------- | | ||
| | 769337-1 | d+m plots weaker again | GGAAAAAAAAAAA... | ................ | [0.642,1.4853,0.1629, ...] | [0.3181,0.4221,0.1823, ...] | 3.227 | | ||
|
|
||
| ## Column Description | ||
|
|
||
| - **ID**: | ||
| A unique identifier for each RNA sequence entry. | ||
|
|
||
| - **design_name**: | ||
| The name given to each RNA design by contributors, used for easy reference. | ||
|
|
||
| - **sequence**: | ||
| The nucleotide sequence of the RNA molecule, represented using the standard RNA bases: | ||
|
|
||
| - **A**: Adenine | ||
| - **C**: Cytosine | ||
| - **G**: Guanine | ||
| - **U**: Uracil | ||
|
|
||
| - **secondary_structure**: | ||
| The secondary structure of the RNA represented in dot-bracket notation, using up to three types of symbols to indicate base pairing and unpaired regions, as per bpRNA's standard: | ||
|
|
||
| - **Dots (`.`)**: Represent unpaired nucleotides. | ||
| - **Parentheses (`(` and `)`)**: Represent base pairs in standard stems (page 1). | ||
| - **Square Brackets (`[` and `]`)**: Represent base pairs in pseudoknots (page 2). | ||
| - **Curly Braces (`{` and `}`)**: Represent base pairs in additional pseudoknots (page 3). | ||
|
|
||
| - **reactivity**: | ||
| A list of normalized reactivity values for each nucleotide, representing the likelihood that a nucleotide is unpaired. | ||
| High reactivity indicates high flexibility (unpaired regions), and low reactivity corresponds to paired or structured regions. | ||
|
|
||
| - **errors**: | ||
| Arrays of floating-point numbers indicating the experimental errors corresponding to the measurements in the **reactivity**. | ||
| These values help quantify the uncertainty in the degradation rates and reactivity measurements. | ||
|
|
||
| - **signal_to_noise**: | ||
| The signal-to-noise ratio calculated from the reactivity and error values, providing a measure of data quality. | ||
|
|
||
| ## Related Datasets | ||
|
|
||
| - [EternaBench-ChemMapping](https://huggingface.co/datasets/multimolecule/eternabench-cm) | ||
| - [EternaBench-Switch](https://huggingface.co/datasets/multimolecule/eternabench-switch) | ||
|
|
||
| ## License | ||
|
|
||
| This dataset is licensed under the [AGPL-3.0 License](https://www.gnu.org/licenses/agpl-3.0.html). | ||
|
|
||
| ```spdx | ||
| SPDX-License-Identifier: AGPL-3.0-or-later | ||
| ``` | ||
|
|
||
| ## Citation | ||
|
|
||
| ```bibtex | ||
| @article{waymentsteele2022rna, | ||
| author = {Wayment-Steele, Hannah K and Kladwang, Wipapat and Strom, Alexandra I and Lee, Jeehyung and Treuille, Adrien and Becka, Alex and {Eterna Participants} and Das, Rhiju}, | ||
| journal = {Nature Methods}, | ||
| month = oct, | ||
| number = 10, | ||
| pages = {1234--1242}, | ||
| publisher = {Springer Science and Business Media LLC}, | ||
| title = {{RNA} secondary structure packages evaluated and improved by high-throughput experiments}, | ||
| volume = 19, | ||
| year = 2022 | ||
| } | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,63 @@ | ||
| # MultiMolecule | ||
| # Copyright (C) 2024-Present MultiMolecule | ||
|
|
||
| # This program is free software: you can redistribute it and/or modify | ||
| # it under the terms of the GNU Affero General Public License as published by | ||
| # the Free Software Foundation, either version 3 of the License, or | ||
| # any later version. | ||
|
|
||
| # This program is distributed in the hope that it will be useful, | ||
| # but WITHOUT ANY WARRANTY; without even the implied warranty of | ||
| # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the | ||
| # GNU Affero General Public License for more details. | ||
|
|
||
| # You should have received a copy of the GNU Affero General Public License | ||
| # along with this program. If not, see <http://www.gnu.org/licenses/>. | ||
|
|
||
| from __future__ import annotations | ||
|
|
||
| import os | ||
|
|
||
| import danling as dl | ||
| import pandas as pd | ||
| import torch | ||
|
|
||
| from multimolecule.datasets.conversion_utils import ConvertConfig as ConvertConfig_ | ||
| from multimolecule.datasets.conversion_utils import save_dataset | ||
|
|
||
| torch.manual_seed(1016) | ||
|
|
||
| cols = [ | ||
| "id", | ||
| "design", | ||
| "sequence", | ||
| "secondary_structure", | ||
| "reactivity", | ||
| "errors", | ||
| "signal_to_noise", | ||
| ] | ||
|
|
||
|
|
||
| def convert_dataset_(df: pd.DataFrame): | ||
| df.signal_to_noise = df.signal_to_noise.str.split(":").str[-1].astype(float) | ||
| df = df.rename(columns={"ID": "id", "design_name": "design", "structure": "secondary_structure"}) | ||
| df = df.sort_values("id") | ||
| df = df[cols] | ||
| return df | ||
|
|
||
|
|
||
| def convert_dataset(convert_config): | ||
| train = dl.load_pandas(convert_config.train_path) | ||
| test = dl.load_pandas(convert_config.test_path) | ||
| save_dataset(convert_config, {"train": convert_dataset_(train), "test": convert_dataset_(test)}) | ||
|
|
||
|
|
||
| class ConvertConfig(ConvertConfig_): | ||
| root: str = os.path.dirname(__file__) | ||
| output_path: str = os.path.basename(os.path.dirname(__file__)).replace("_", "-") | ||
|
|
||
|
|
||
| if __name__ == "__main__": | ||
| config = ConvertConfig() | ||
| config.parse() # type: ignore[attr-defined] | ||
| convert_dataset(config) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,139 @@ | ||
| --- | ||
| language: rna | ||
| tags: | ||
| - Biology | ||
| - RNA | ||
| license: | ||
| - agpl-3.0 | ||
| size_categories: | ||
| - 1K<n<10K | ||
| task_categories: | ||
| - text-generation | ||
| - fill-mask | ||
| task_ids: | ||
| - language-modeling | ||
| - masked-language-modeling | ||
| pretty_name: EternaBench-RiboSwitch | ||
| library_name: multimolecule | ||
| --- | ||
|
|
||
| # EternaBench-RiboSwitch | ||
|
|
||
|  | ||
|
|
||
| EternaBench-RiboSwitch is a synthetic RNA dataset consisting of 7,228 riboswitch constructs, designed to explore the structural behavior of RNA molecules that change conformation upon binding to ligands such as FMN, theophylline, or tryptophan. | ||
| These riboswitches exhibit different structural states in the presence or absence of their ligands, and the dataset includes detailed measurements of binding affinities (dissociation constants), activation ratios, and RNA folding properties. | ||
|
|
||
| ## Disclaimer | ||
|
|
||
| This is an UNOFFICIAL release of the [EternaBench-RiboSwitch](https://github.com/eternagame/EternaBench) by Hannah K. Wayment-Steele, et al. | ||
|
|
||
| **The team releasing EternaBench-RiboSwitch did not write this dataset card for this dataset so this dataset card has been written by the MultiMolecule team.** | ||
|
|
||
| ## Dataset Description | ||
|
|
||
| - **Homepage**: https://multimolecule.danling.org/datasets/eternabench_switch | ||
| - **datasets**: https://huggingface.co/datasets/multimolecule/eternabench-switch | ||
| - **Point of Contact**: [Rhiju Das](https://biochemistry.stanford.edu/people/rhiju-das/) | ||
|
|
||
| The dataset includes synthetic RNA sequences designed to act as riboswitches. These molecules can adopt different structural states in response to ligand binding, and the dataset provides detailed information on the binding affinities for various ligands, along with metrics on the RNA’s ability to switch between conformations. With over 7,000 entries, this dataset is highly useful for studying RNA folding, ligand interaction, and RNA structural dynamics. | ||
|
|
||
| ## Example Entry | ||
|
|
||
| | id | design | sequence | activation_ratio | ligand | switch | kd_off | kd_on | kd_fmn | kd_no_fmn | min_kd_val | ms2_aptamer | lig_aptamer | ms2_lig_aptamer | log_kd_nolig | log_kd_lig | log_kd_nolig_scaled | log_kd_lig_scaled | log_AR | folding_subscore | num_clusters | | ||
| | --- | ------ | ------------------ | ---------------- | ------ | ------ | ------- | ------ | ------ | --------- | ---------- | ----------------------------- | ------------------ | ------------------ | ------------ | ---------- | ------------------- | ----------------- | ------ | ---------------- | ------------ | | ||
| | 286 | null | AGGAAACAUGAGGAU... | 0.8824621522 | FMN | OFF | 13.3115 | 15.084 | null | null | 3.0082 | .....(((((x((xxxx)))))))..... | .................. | .....(((((x((xx... | 2.7137 | 2.5886 | 1.6123 | 1.4873 | -0.125 | null | null | | ||
|
|
||
| ## Column Description | ||
|
|
||
| - **id**: | ||
| A unique identifier for each RNA sequence entry. | ||
|
|
||
| - **design**: | ||
| The name given to each RNA design by contributors, used for easy reference. | ||
|
|
||
| - **sequence**: | ||
| The nucleotide sequence of the RNA, using standard bases. | ||
|
|
||
| - **activation_ratio**: | ||
| The ratio reflecting the RNA molecule’s structural change between two states (e.g., ON and OFF) upon ligand binding. | ||
|
|
||
| - **ligand**: | ||
| The small molecule ligand (e.g., FMN, theophylline) that the RNA is designed to bind to, inducing the switch. | ||
|
|
||
| - **switch**: | ||
| A binary or categorical value indicating whether the RNA demonstrates switching behavior. | ||
|
|
||
| - **kd_off**: | ||
| The dissociation constant (KD) when the RNA is in the "OFF" state (without ligand), representing its binding affinity. | ||
|
|
||
| - **kd_on**: | ||
| The dissociation constant (KD) when the RNA is in the "ON" state (with ligand), indicating its affinity after activation. | ||
|
|
||
| - **kd_fmn**: | ||
| The dissociation constant for the RNA binding to the FMN ligand. | ||
|
|
||
| - **kd_no_fmn**: | ||
| The dissociation constant when no FMN ligand is present, indicating the RNA's behavior in a ligand-free state. | ||
|
|
||
| - **min_kd_val**: | ||
| The minimum KD value observed across different ligand-binding conditions. | ||
|
|
||
| - **ms2_aptamer**: | ||
| Indicates whether the RNA contains an MS2 aptamer, a motif that binds the MS2 viral coat protein. | ||
|
|
||
| - **lig_aptamer**: | ||
| A flag showing the presence of an aptamer that binds the ligand (e.g., FMN), demonstrating ligand-specific binding capability. | ||
|
|
||
| - **ms2_lig_aptamer**: | ||
| Indicates if the RNA contains both an MS2 aptamer and a ligand-binding aptamer, potentially allowing for multifaceted binding behavior. | ||
|
|
||
| - **log_kd_nolig**: | ||
| The logarithmic value of the dissociation constant without the ligand. | ||
|
|
||
| - **log_kd_lig**: | ||
| The logarithmic value of the dissociation constant with the ligand present. | ||
|
|
||
| - **log_kd_nolig_scaled**: | ||
| A normalized and scaled version of **log_kd_nolig** for easier comparison across conditions. | ||
|
|
||
| - **log_kd_lig_scaled**: | ||
| A normalized and scaled version of **log_kd_lig** for consistency in data comparisons. | ||
|
|
||
| - **log_AR**: | ||
| The logarithmic scale of the activation ratio, offering a standardized measure of activation strength. | ||
|
|
||
| - **folding_subscore**: | ||
| A numerical score indicating how well the RNA molecule folds into the predicted structure. | ||
|
|
||
| - **num_clusters**: | ||
| The number of distinct structural clusters or conformations predicted for the RNA, reflecting the complexity of the folding landscape. | ||
|
|
||
| ## Related Datasets | ||
|
|
||
| - [EternaBench-CM](https://huggingface.co/datasets/multimolecule/eternabench-cm) | ||
| - [EternaBench-RiboSwitch](https://huggingface.co/datasets/multimolecule/eternabench-switch) | ||
|
|
||
| ## License | ||
|
|
||
| This dataset is licensed under the [AGPL-3.0 License](https://www.gnu.org/licenses/agpl-3.0.html). | ||
|
|
||
| ```spdx | ||
| SPDX-License-Identifier: AGPL-3.0-or-later | ||
| ``` | ||
|
|
||
| ## Citation | ||
|
|
||
| ```bibtex | ||
| @article{waymentsteele2022rna, | ||
| author = {Wayment-Steele, Hannah K and Kladwang, Wipapat and Strom, Alexandra I and Lee, Jeehyung and Treuille, Adrien and Becka, Alex and {Eterna Participants} and Das, Rhiju}, | ||
| journal = {Nature Methods}, | ||
| month = oct, | ||
| number = 10, | ||
| pages = {1234--1242}, | ||
| publisher = {Springer Science and Business Media LLC}, | ||
| title = {{RNA} secondary structure packages evaluated and improved by high-throughput experiments}, | ||
| volume = 19, | ||
| year = 2022 | ||
| } | ||
| ``` |
Oops, something went wrong.