-
Notifications
You must be signed in to change notification settings - Fork 49
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
46e314e
commit 9d2fdf7
Showing
7 changed files
with
192 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,192 @@ | ||
| --- | ||
| layout: post | ||
| title: "【报告解读】| NIST人工智能报告:对抗性机器学习分类与术语全解析(附原文)" | ||
| date: 2025-1-3 13:30:00 | ||
| author: "安全极客" | ||
| header-img: "img/post-bg-unix-linux.jpg" | ||
| tags: | ||
| - Security | ||
| - AIGC | ||
| - 论文速读 | ||
| --- | ||
|
|
||
|
|
||
|  | ||
|
|
||
| 在当今数字化时代,人工智能(AI)系统正以前所未有的速度发展并广泛应用于各个领域,从自动驾驶汽车到医疗诊断,从智能助手到金融分析。然而,这些系统在带来便利的同时,也面临着严峻的安全挑战。美国国家标准与技术研究院(NIST)发布的《可信与负责任的人工智能》报告,聚焦于对抗性机器学习(AML)领域,旨在构建一个全面的概念分类体系,并明确相关术语定义,为保障人工智能系统的安全提供坚实的理论基础和实践指导。 | ||
|
|
||
| ## 预测性 AI 分类 | ||
|
|
||
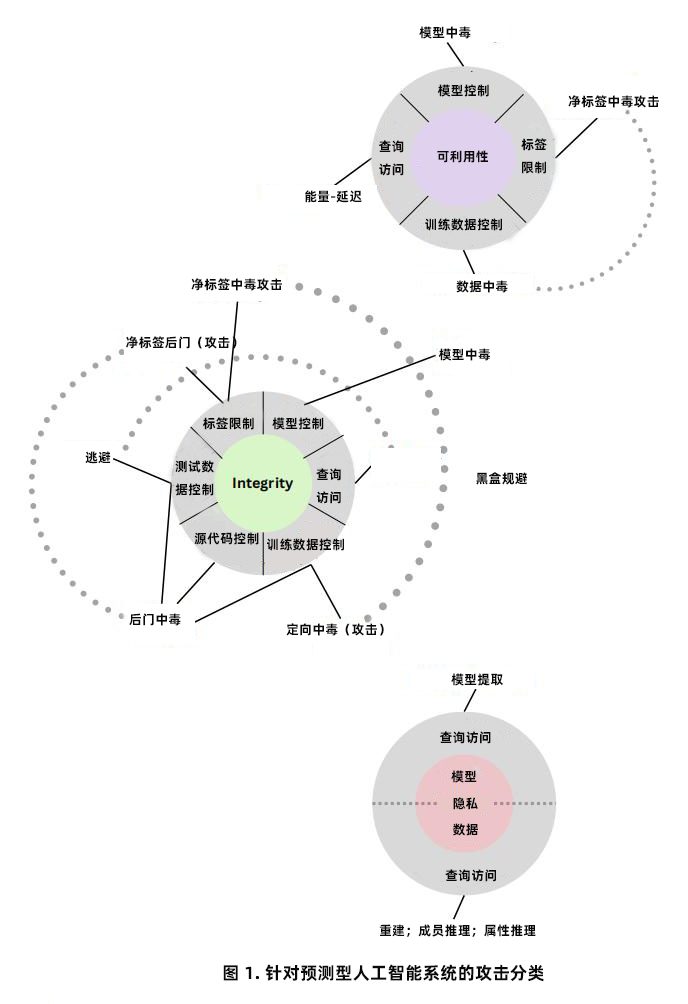
| **1. 攻击分类** | ||
|
|
||
|  | ||
|
|
||
| **· 学习阶段维度** | ||
|
|
||
| 机器学习包含训练阶段和部署阶段。训练阶段利用训练数据学习模型,常见的监督学习技术如分类(预测离散标签)和回归(预测连续标签)。而在部署阶段,训练好的模型应用于新数据进行预测。AML 文献主要关注训练阶段的中毒攻击(如数据投毒、模型中毒)和部署阶段的规避攻击及隐私攻击。 | ||
|
|
||
| **· 攻击者目标和目的维度** | ||
|
|
||
| 攻击者目标主要分为可用性崩溃、完整性违规和隐私泄露。可用性攻击旨在破坏模型性能,如通过数据投毒或模型中毒使模型在部署时失效;完整性攻击通过逃避攻击(部署时)或中毒攻击(训练时)改变模型输出,如使图像分类器将物体错误分类;隐私攻击则聚焦于获取训练数据或模型的敏感信息,如数据重建、成员关系推理等。 | ||
|
|
||
| **· 攻击者能力维度** | ||
|
|
||
| 攻击者可利用训练数据控制(插入或修改训练样本)、模型控制(修改模型参数)、测试数据控制(修改测试样本)、标签限制(在监督学习中限制对标签的控制)、源代码控制(修改算法源代码)和查询访问(向模型提交查询并接收预测)等能力。 | ||
|
|
||
| **· 攻击者知识维度** | ||
|
|
||
| 分为白盒攻击(充分了解系统,包括数据、架构和参数)、黑盒攻击(仅通过查询访问模型,了解最少信息)和灰盒攻击(介于两者之间,如了解模型架构但不知参数,或了解部分数据分布和特征表示)。 | ||
|
|
||
| **· 数据模态维度** | ||
|
|
||
| 对抗性攻击涉及多种数据模态,包括图像、文本、音频、视频和表格数据等。不同模态的攻击和防御方式各有特点,如图像数据模态的对抗性示例可利用连续域优势进行优化,而文本数据模态的攻击需考虑语义约束。 | ||
|
|
||
| **2. 逃避攻击与缓解** | ||
|
|
||
| **· 白盒逃避攻击** | ||
|
|
||
| 基于优化的方法通过计算模型损失函数梯度生成对抗性示例,如 FGSM、PGD 等方法不断改进以优化对抗性示例的生成。通用逃避攻击可构建小型通用扰动,物理上可实现的攻击则针对实际系统,如面部识别系统或道路标志检测系统。此外,对抗性示例概念已扩展到其他领域,如音频、视频和 NLP,但在不同领域面临不同挑战,如 NLP 需遵守文本语义约束。 | ||
|
|
||
| **· 黑盒逃避攻击** | ||
|
|
||
| 主要包括基于分数的攻击(利用模型置信度分数或逻辑值优化创建对抗性示例)和基于决策的攻击(仅根据模型最终预测标签生成攻击)。攻击者在黑盒设置下通过查询模型获取信息,不断改进攻击方法以减少查询次数。 | ||
|
|
||
| **· 攻击的可转移性** | ||
|
|
||
| 攻击者可通过在替代模型上训练攻击并转移到目标模型,不同模型在决策边界学习上的特点影响可转移性。相关研究致力于理解其根本原因,如不同模型在良性和对抗性维度上的交叉决策边界情况。 | ||
|
|
||
| **· 缓解措施** | ||
|
|
||
| 对抗性示例广泛存在,许多缓解措施效果有限。当前有效的缓解措施包括对抗训练(通过迭代生成对抗性示例扩充训练数据)、随机平滑(在高斯噪声扰动下产生鲁棒预测)和形式验证(基于形式方法技术验证模型鲁棒性),但这些措施存在鲁棒性与准确性权衡以及计算成本问题。 | ||
|
|
||
| **3. 中毒攻击和缓解措施** | ||
|
|
||
| **· 可用性中毒** | ||
|
|
||
| 可用性中毒攻击会使机器学习模型性能全面下降,如在网络安全领域针对蠕虫签名生成和垃圾邮件分类器的攻击。攻击者可通过多种方式发动攻击,如 LABEL FLIPPING、基于优化的中毒攻击(适用于不同学习模型)、利用可转移性(在灰盒设置中)以及针对无监督学习和联合学习的攻击。缓解措施包括监测模型性能指标、训练数据清理(利用数据清理技术去除中毒样本)和鲁棒训练(修改训练算法或训练模型集合)。 | ||
|
|
||
| **· 目标中毒** | ||
|
|
||
| 目标中毒攻击针对少量目标样本改变模型预测,在清洁标签设置中研究较多。攻击者可利用影响函数、优化样本特征空间、针对集成模型或利用元学习算法等技术发动攻击,且攻击已扩展到半监督学习算法。缓解措施包括审慎使用数据集来源和完整性证明机制,以及考虑差分隐私(但存在准确性降低问题)。 | ||
|
|
||
| **· 后门投毒** | ||
|
|
||
| 后门投毒攻击自 2017 年提出后不断发展,攻击者通过在训练数据中添加后门模式,使模型在特定输入下产生错误分类。攻击方式包括添加小补丁触发器、混合触发器到训练数据、使用干净标签后门攻击等,且已扩展到不同数据模式。缓解措施包括训练数据清理(如离群值检测、激活聚类)、触发器重建、模型检查和消毒(如修剪、重新训练或微调),但现有措施存在局限性。 | ||
|
|
||
| **· 模型中毒** | ||
|
|
||
| 模型中毒攻击试图直接修改训练好的机器学习模型,在集中式学习和联合学习中均可能发生,可导致可用性和完整性违规,如降低全局模型准确性、在测试时对特定样本造成错误分类或引入后门。缓解措施包括设计拜占庭弹性聚合规则(但可能被绕过)、利用梯度剪裁和差分隐私(存在准确性问题),同时模型检查和消毒技术可用于特定漏洞检测。 | ||
|
|
||
| **4. 隐私攻击** | ||
|
|
||
| **· 数据重建** | ||
|
|
||
| 数据重建攻击旨在从发布的聚合信息中恢复个人数据,如从线性统计数据或神经网络模型中进行重建。神经网络记忆训练数据的趋势增加了此类攻击风险,相关研究已扩展到多类多层感知机分类器的训练样本重建。 | ||
|
|
||
| **· 成员关系推理** | ||
|
|
||
| 成员关系推理攻击用于确定数据样本是否在训练集中,攻击者可通过基于损失的攻击、影子模型等技术发动攻击,且攻击可在白盒或黑盒设置下进行。公共隐私库提供了相关攻击实现,缓解措施包括差分隐私(可限制攻击者成功率)和隐私审计(通过经验测量实际隐私保证)。 | ||
|
|
||
| **· 模型提取** | ||
|
|
||
| 攻击者通过向模型提交查询,试图提取模型架构和参数信息,可采用直接提取、学习方法提取或利用侧通道信息等技术。模型提取虽不是最终目标,但可能为后续更具破坏性的攻击提供基础,缓解措施包括限制查询、检测可疑查询和创建健壮架构等,但可能被攻击者绕过。 | ||
|
|
||
| **· 属性推理** | ||
|
|
||
| 属性推理攻击旨在学习训练数据分布的全局信息,如确定训练集中具有特定敏感属性的部分。攻击者可在白盒或黑盒设置下发动攻击,针对不同类型的模型进行设计,且可通过毒化数据提高攻击效果。 | ||
|
|
||
| ## 生成式人工智能分类体系 | ||
|
|
||
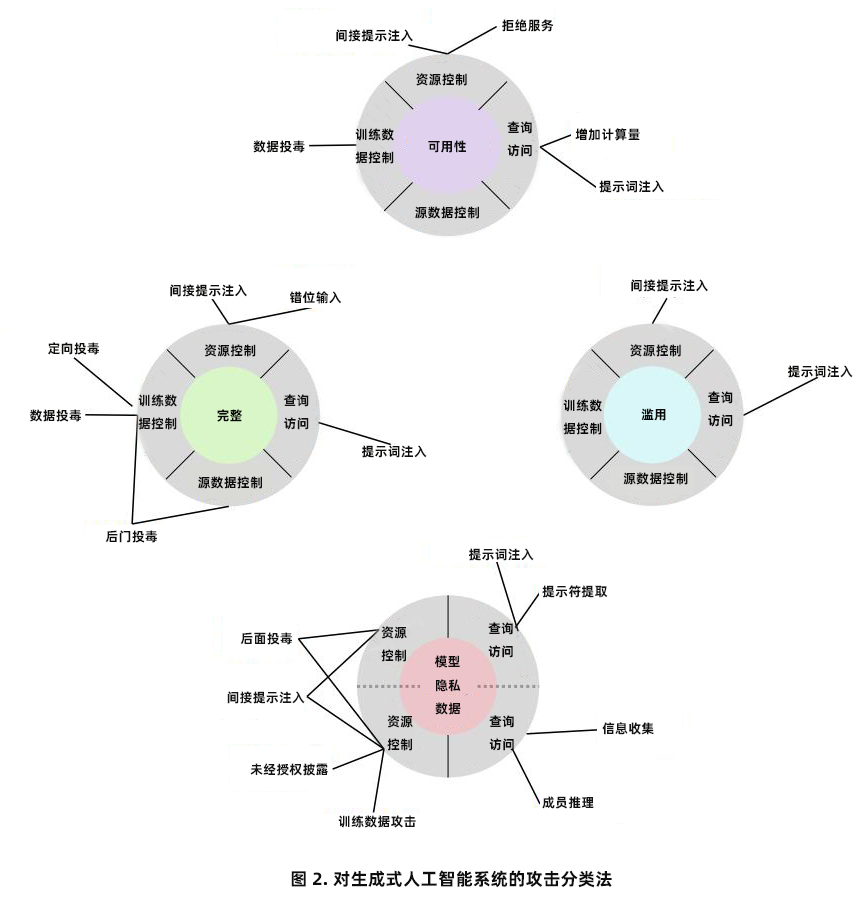
| **1. 攻击分类** | ||
|
|
||
|  | ||
|
|
||
| **1)学习阶段特点** | ||
|
|
||
| 生成式 AI 模型开发模式发生转变,基础模型通过预训练学习模式,再经微调用于特定任务。训练阶段易受中毒攻击,如通过控制训练数据(如 Web 规模数据集中毒)影响模型。部署阶段,LLM 和 RAG 应用因数据和指令通道特点存在多种安全漏洞,如提示注入攻击。 | ||
|
|
||
| **2)攻击者目标和能力** | ||
|
|
||
| 除可用性、完整性、隐私问题外,新增滥用违规,攻击者可能利用模型进行有害内容生成等恶意行为。攻击者能力包括训练数据控制、查询访问、源代码控制和资源控制等,这些能力被用于不同类型的攻击,如提示注入、间接提示注入等。 | ||
|
|
||
| **2. AI 供应链攻击与缓解措施** | ||
|
|
||
| **1)反序列化漏洞** | ||
|
|
||
| 许多 ML 项目使用开源 GenAI 模型,其存储格式可能存在反序列化漏洞,如 pickle 等格式允许任意代码执行,这被归类为关键漏洞。 | ||
|
|
||
| **2)中毒攻击** | ||
|
|
||
| GenAI 模型性能依赖大规模数据,数据抓取过程中可能遭受中毒攻击,如目标中毒、后门中毒和模型中毒。缓解措施包括数据集发布者提供加密哈希值,下载者进行验证,以及采用安全的模型持久化格式。 | ||
|
|
||
| **3)缓解措施** | ||
|
|
||
| 可通过供应链保障措施缓解 AI 供应链攻击,包括对模型文件依赖项进行漏洞扫描、采用安全格式,对大规模数据依赖项进行下载验证和数据完整性检查,以及采用免疫图像等方法(但需额外策略组件)。 | ||
|
|
||
| **3. 直接提示注入攻击和缓解措施** | ||
|
|
||
| **1)攻击方式与目标** | ||
|
|
||
| 攻击者通过注入文本改变 LLM 行为,目标包括滥用(如创建有害内容、越狱)和侵犯隐私(如提取系统提示或私人信息)。攻击技术包括基于梯度的攻击(如 HotFlip 等)、手动方法(如竞争目标和不匹配泛化类别下的多种技术)和基于模型的自动化红队测试。 | ||
|
|
||
| **2)数据提取风险** | ||
|
|
||
| GenAI 模型训练数据可能包含敏感信息,攻击者可通过精心设计提示或利用模型特性提取信息,包括泄露敏感信息(如从模型中提取训练数据中的个人信息)和提示及上下文窃取(如窃取 LLM 的提示或 RAG 应用中的上下文信息)。 | ||
|
|
||
| **3)缓解措施** | ||
|
|
||
| 针对提示注入,可采用对齐训练(优化训练流程和强化学习)、指令和格式化技巧(如精心设计指令和封装提示信息)以及检测技术(如使用基准数据集评估和监控输入输出)。针对提示窃取,防御措施包括比较模型话语与已知提示,但尚未得到严格验证。 | ||
|
|
||
| **4. 间接提示注入攻击和缓解措施** | ||
|
|
||
| **1)攻击导致的违规行为** | ||
|
|
||
| 间接提示注入攻击通过资源控制影响 LLM,可能导致可用性违规(如服务中断)、完整性违规(如生成不可信信息)、隐私泄露(如信息收集和未经授权披露)和滥用违规(如欺诈、恶意软件传播、操纵等)。攻击者通过多种技巧实现攻击,如在商业 RAG 服务中,利用耗时的后台任务、消音、抑制功能、干扰输入或输出等方式导致模型可用性问题;通过操纵模型提供错误摘要或传播虚假信息影响模型完整性;利用人机交互或其他手段收集用户信息或导致未经授权的披露引发隐私泄露;以及通过钓鱼、伪装、传播恶意软件等手段实现滥用违规。 | ||
|
|
||
| **2)缓解措施** | ||
|
|
||
| 针对间接提示注入攻击,提出了多种缓解技术。强化学习来自人类反馈(RLHF)可使 LLMs 更好地与人类价值观保持一致,减少不良行为,如 OpenAI 的 GPT - 4 通过 RLHF 微调后,生成有害内容或幻觉的倾向降低。过滤检索到的输入可以去除指令中的潜在风险。利用 LLM 作为调解员检测攻击,可在一定程度上过滤有害输出,但对某些类型的攻击检测可能有限。基于可解释性的解决方案通过异常值检测预测轨迹,有助于发现异常输入。然而,目前尚无全面或绝对可靠的解决方案,未来工作需进一步研究和评估这些防御方法的有效性。 | ||
|
|
||
| ## 讨论和尚未解决的挑战 | ||
|
|
||
| **1. 规模挑战** | ||
|
|
||
| 随着模型规模扩大,训练数据量需求剧增,数据存储和管理面临新风险。当前 LLM 的数据来源复杂,且多未公布详细信息,数据存储库的分布式特点使传统网络安全边界定义失效。同时,互联网上大规模生成合成内容的能力带来新挑战,如可能影响后续训练模型的能力,导致模型崩溃,水印技术虽可缓解但仍面临诸多问题。 | ||
|
|
||
| **2. 对抗性鲁棒性的理论限制** | ||
|
|
||
| **1)检测与防御困难** | ||
|
|
||
| 设计有效的缓解措施面临挑战,缺乏信息理论上安全的机器学习算法。检测模型攻击困难,如检测对抗性示例等同于鲁棒分类,计算复杂性高且难以构建。同时,检测分布外(OOD)输入也存在困难,相关理论界限研究仍在探索中。 | ||
|
|
||
| **2)缓解措施的局限性与发展方向** | ||
|
|
||
| 数据和模型清理技术可减轻毒化攻击影响,但需结合加密技术提供下游保证。强健训练技术虽有成果,但需扩展到更一般假设,且在应用于大型模型时面临挑战。形式方法验证在高风险应用中有潜力,但成本高昂,需研究扩展到机器学习算法的代数操作、适应大型模型并降低成本。此外,隐私攻击与缓解技术之间存在不平衡,需要解决如何减轻数据记忆利用风险、防止属性推断攻击以及保护模型秘密权重等问题。 | ||
|
|
||
| **3. 开源模型与封闭模型困境** | ||
|
|
||
| 开源模型在软件开发中具有诸多益处,如民主化访问、促进科学成果可重现等,在许多用例中性能与封闭模型相当。然而,其也存在风险,如可能被恶意利用执行非预期任务,引发安全担忧,如社会对加密技术和基因工程的处理方式,人工智能领域也需权衡开源模型的利弊。 | ||
|
|
||
| **4. 供应链挑战** | ||
|
|
||
| 人工智能和机器学习领域面临新攻击趋势,强大开源模型的出现使其可能遭受特洛伊木马攻击,如通过植入信息理论上无法检测的特洛伊木马,这对模型供应链安全提出挑战,需要限制组织内部人员访问权限、审查第三方组件,相关研究如 DARPA 与 NIST 的 TrojAI 计划正在进行中。 | ||
|
|
||
| **5. “Trustworthy AI” 属性之间的权衡** | ||
|
|
||
| 一个 AI 系统的可信度受多种属性影响,如准确性、对抗性鲁棒性、公平性和可解释性等。这些属性之间存在权衡,如仅优化准确性可能导致对抗性鲁棒性和公平性下降,优化对抗性鲁棒性可能影响准确性和公平性。全面表征这些属性之间的权衡是一个重要的研究问题,组织需根据具体情况决定优先考虑的属性。 | ||
|
|
||
| **6. 多模态模型:它们更加健壮吗?** | ||
|
|
||
| 多模态模型在许多任务上表现出潜力,但实践中发现,组合不同模态并在干净数据上训练并不一定提高对抗性鲁棒性,单一模态攻击仍可能有效。对抗性训练在多模态学习中成本过高,且研究人员已设计出同时攻击多种模态的机制,表明多模态模型可能并不比单一模态更能抵抗对抗性攻击,需要进一步研究利用冗余信息提高其鲁棒性。 | ||
|
|
||
| **7. 量化的模型** | ||
|
|
||
| 量化模型可有效部署到边缘平台,但继承了原始模型漏洞并引入新弱点,如计算精度降低导致对抗鲁棒性受影响。PredAI 模型的缓解技术研究较多,但 GenAI 模型相关研究较少,部署量化模型的组织需谨慎监测其行为,以应对可能的安全风险。 | ||
|
|
||
| ## 总结与展望 | ||
|
|
||
| 本报告详细阐述了对抗性机器学习在预测性 AI 和生成式 AI 系统中的分类、攻击手段、缓解措施以及面临的挑战。随着人工智能技术的不断发展,对抗性机器学习领域的研究和实践需要持续推进。解决当前面临的诸多挑战,需要学术界、产业界和政府等各方共同努力,制定更加有效的安全策略和标准,加强合作与交流,以确保人工智能系统的安全、可靠和可信运行。未来的研究方向包括进一步探索强大的防御机制,优化隐私保护技术,建立可靠的评估基准,深入理解和权衡 AI 系统的各种属性,以及应对不断出现的新攻击手段和技术趋势。只有这样,才能充分发挥人工智能技术的优势,为人类社会带来更多的福祉。 | ||
|
|
||
|
|
||
|
|
||
|
|
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.