BladeRunnerJS Internals
We have a set of domain objects that model the BladeRunnerJS concepts like blades, bladeset, aspects, etc. It looks something like this:
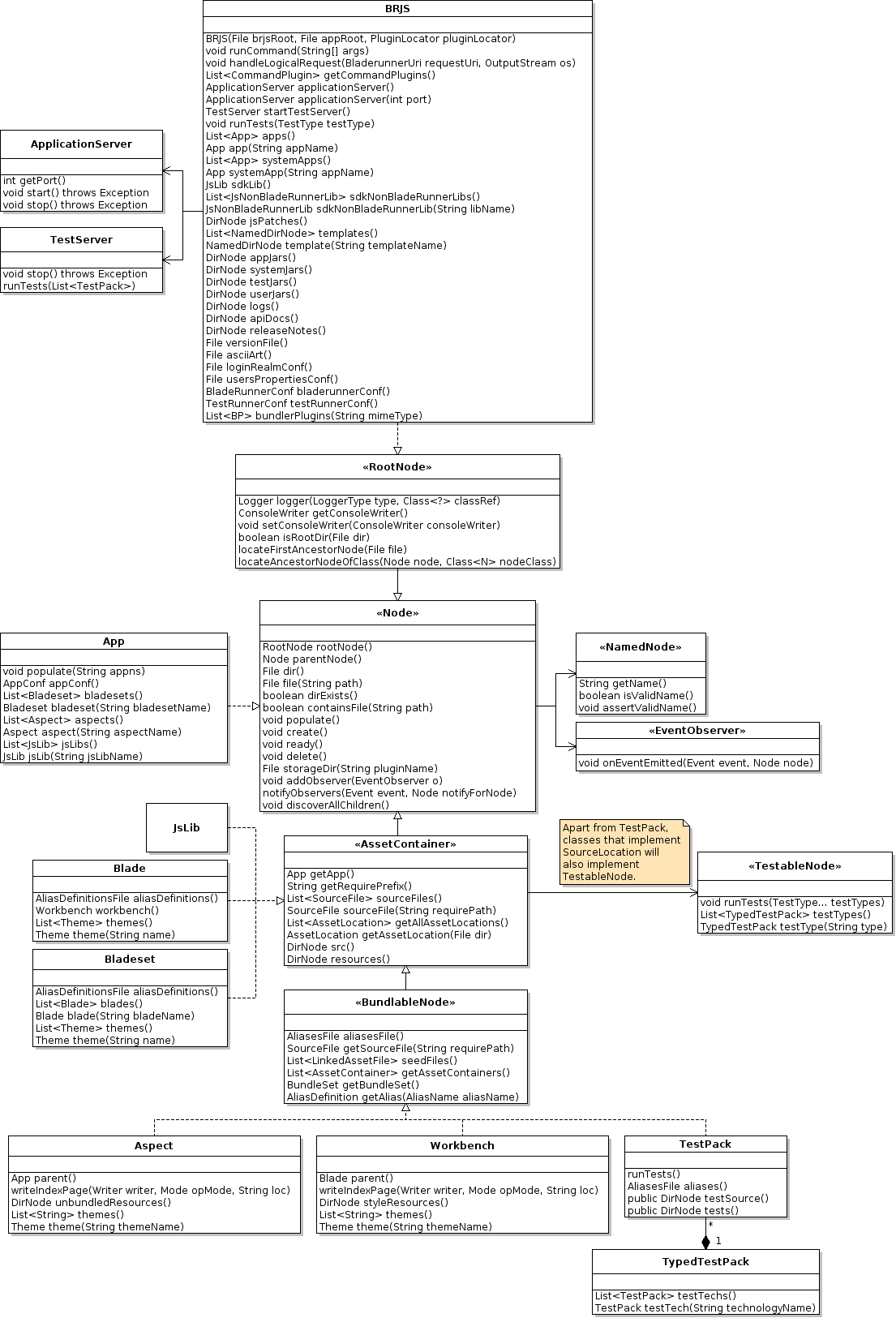
and this:
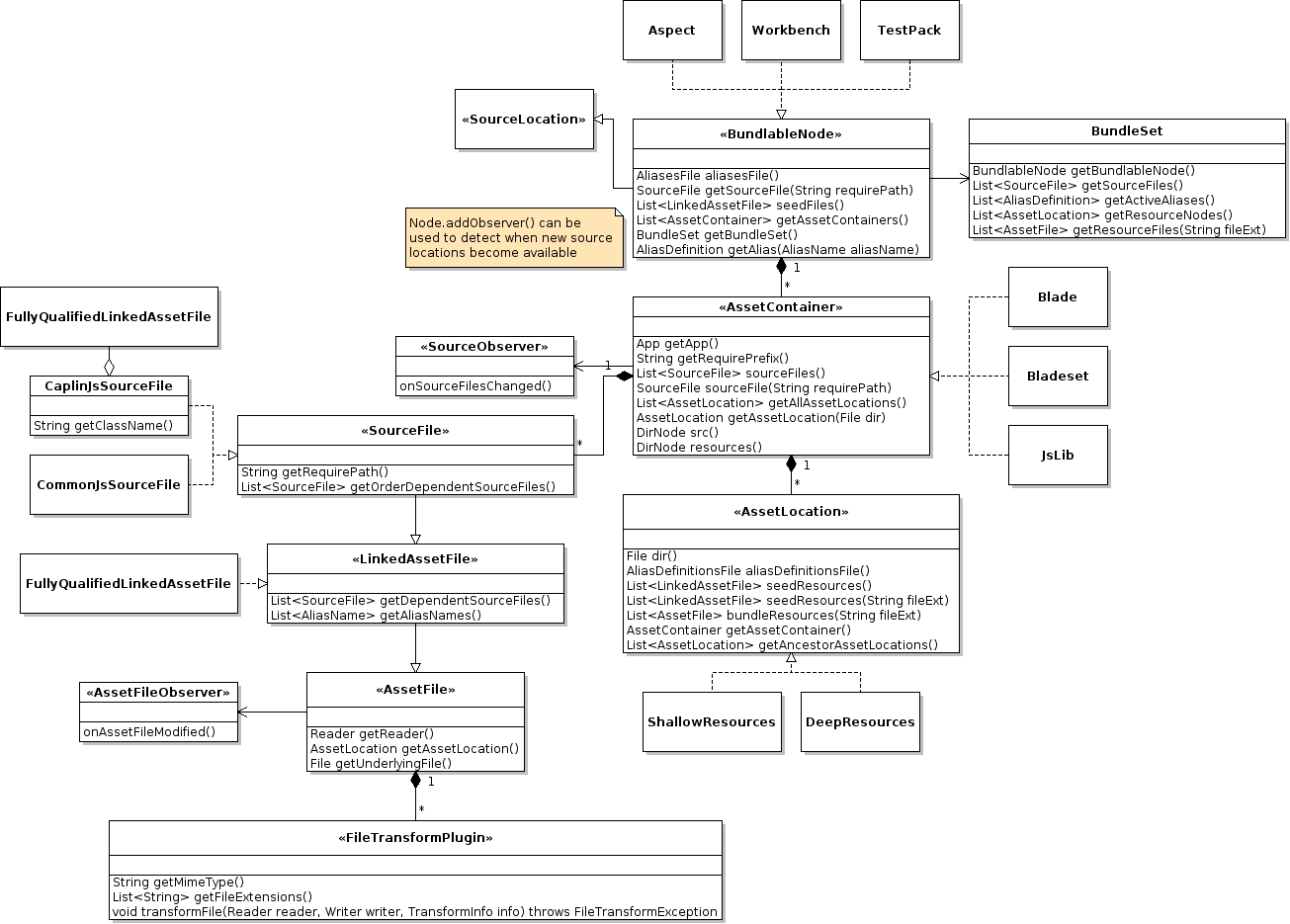
The domain objects can be used to both talk about things that currently exist on the file system, and talk about things that have yet to be created on the file system. This allows us to create new items on disk in a convenient way, for example:
brjs.app("myapp").bladeset("default").blade("blade1").create();
We have two utility classes (NodeList and NodeItem) that allow us to automatically create and delete domain objects as the physical file system changes. We use NodeList.list(), NodeList.item(String itemName) and NodeItem.item() within our domain APIs to return domain object(s) based on the current state of the file system.
The App class provides a good example of NodeList and NodeItem being used:
We have a MemoizedValue class that allows us to safely memoize objects that are expensive to compute, without worrrying about introducing pernicious caching bugs.
Here's some information about its use:
- The
Memoized.value()method is used to safely wrap access to memoized values. - If the underlying object has changed the method used to generate a fresh copy is re-invoked.
- We can be fairly sure there are no caching bugs since when we run our tests we ensure that each
MemoizedValueclass correctly declares the files, which if they changed, should cause us to create a fresh copy of the object. - We do this by installing a Java
SecurityManagerwhen running tests (calledBRJSSecurityManager) that is informed of all file-access, and which ensures that any file access withinMemoizedValue.value()invocations has been pre-registered.
The PersistentAliasesData class provides an example of it's use:
The MemoizedValue class makes use of the BRJS.getFileInfo() method, which in turn makes use of an underlying FileModificationService instance which is passed into the BRJS constructor at initialization. We have three implementations of FileModificationService:
-
Java7FileModificationService(used in the real app) -
PessimisticFileModificationService(used within the majority of tests where we want changes to the file system to be picked up immediately) -
OptimisticFileModificationService(used within a few tests where we don't want file system changes to be picked up)
The FileModificationService interface, and corresponding FileModificationInfo interface, are here:
org.bladerunnerjs.utility.filemodification.FileModificationServiceorg.bladerunnerjs.utility.filemodification.FileModificationInfo
The BundlableNode.getBundleSet() method is used to create a BundleSet instance of all the assets that could potentially be sent to the client. Aspect, Workbench and TestPack all implement BundlableNode, and can have bundle-sets created for them.
The actual assets that are sent to the client depend on the tag-handlers a developer uses in their index page, and whether classes like HtmlResourceService and XmlResourceService are used, since these make XHR requests to content plug-ins within the server to fetch more data to the client.
You can follow the entire bundling process by inspecting the BundleSetCreator and BundleSetBuilder classes here:
What happens when the BundlableNode.getBundleSet() method is invoked depends on the set of plug-ins available, since these affect what assets will be found on disk, and how they will be processed. More information on plug-ins is available here:
A number of plug-ins make use of the Trie and TrieFactory utilities, that allow implicit dependencies (dependencies that are not explicitly defined using require(), etc) to be efficiently found within file content those plug-ins scan. The Trie class itself is generic, and does the real work, whereas the TrieFactory is used to share Trie instances that are common to an AssetContainer.
Whereas a map (e.g. Map<String, Book>) allows books to be efficiently retrieved using a key of type String, the trie (e.g. Trie<Book>) allows references to books to be efficiently discovered while scanning arbitrary text content.
More information on tries can be found here:
and the Trie and TrieFactory code is available here: