Live now on the LAION Discord Server for you to try!

- Highly Scalable: Leverages
dalle-flowgRPC interface to independently serve images from any number of GPUs, while higher memory calls to the gRPC through the bot are forked onto individual instances of Python. - Support For Other Popular Models: Latent diffusion GLID3XL or DALLE-MEGA can easily by turned on in addition to Stable Diffusion through
dalle-flowfor text-to-image generation. - Support For Low VRAM GPUS: Stable Diffusion fork supports image generation with GPUs >= 7 GB.
- Supports Slash and Legacy Style Commands: While Discord is moving towards the new slash style commands that feature auto-completion functions, YASD Discord Bot also features direct commands prefixed with
>-- whichever you find easier. - Easy User Interface Including Buttons and Loading Indicators: Riffing and upscaling your creations has never been easier! It even comes with a manual!
- Stores All Images and Prompts by Default: Never lose your previous generations!
- Changelog
- Content advisory
- What do I need?
- Installation
- What can it do?
- User Manual
- Something is broken
- Closing Remarks
- License
- 2022-10-23: Added support for RunwayML inpainting/outpainting, replacing outriffing. This is now the recommended model.
- 2022-10-01: Added clipseg to automatically detect and mask images for inpainting, added RealESRGAN upscaler as an alternative to SwinIR.
- 2022-09-24: Add usage of the SD concepts library, add subprompts and negative/positive conditioning, add ability to prevent users from making prompts if they have not been on the server long enough, remove the optimized-sd branch since we have now moved to a local
stable-diffusionbranch that is more optimized than that one. - 2022-09-11: Add optional NSFW spoiler filter and NSFW wordlist filter. Added the ability to set default steps and queue any quantity of images on a per user basis with a new flag.
- 2022-09-06: Added the ability to change make images of any size and riff into different sizes ("outriffing").
- 2022-09-05: The
sd-litebranch has been merged upstream, so now low VRAM is available with docker images too. - 2022-08-30:
optimized-sdbranch has moved tosd-litebranch, which will be merged upstream. Includes small bugfixes and enhanced interpolation. Upstream docker image is now functional, so instructions have been added for installing that. - 2022-08-30: Updated to add slash commands in addition to legacy commands, added a manual link instead of help, added multi-user support (more than one user may now use the bot at a time without waiting), added
interpolatecommand. - 2022-08-28: Add ability to use with low VRAM cards through optimized
dalle-flowbranchoptimized-sd. - 2022-08-27: Add content advisory.
- 2022-08-26: Stable Diffusion branch merged into upstream
dalle-flow. Added docker installation instructions. - 2022-08-24: Added k_lms and other k-diffusion samplers, with k-lms now the default. DDIM is still electable with "(sampler=ddim)" argument.
This bot does not come equipped with a NSFW filter for content by default and will make any content out of the box. Please be sure to read and agree with the license for the weights, as well as the MIT license, and abide by all applicable laws and regulations in your respective area.
To enable the NSFW filter to automatically add the spoiler tag to any potential NSFW images, use the flag --nsfw-auto-spoiler. You must first pip install -r requirements_nsfw_filter.txt to get the modules required for this.
To enable NSFW prompt detection via BERT, use the flag --nsfw-prompt-detection and be sure to pip install -r requirements_nsfw_filter.txt.
To reject any prompts if they contain a word within a wordlist, use the --nsfw-wordlist flag, e.g. --nsfw-wordlist bad_words.txt. The wordlist should be strings separated by newlines.
Python 3 3.9+ with pip and virtualenv installed (Ubuntu 22.04 works great!)
CUDA runtime environment installed
An NVIDIA GPU with >= 7 GB of VRAM
If running with a low VRAM GPU, you will not have access to the >upscale endpoint as you will run out of RAM. Buying an RTX 3090 or renting a server with one is recommended.
This installation is intended for debian or arch flavored linux users. YMMV. You will need to have Python 3 and pip installed.
sudo apt install python3 python3-pip
sudo pip3 install virtualenvInstall the Nvidia docker container environment if you have not already.
Pull the dalle-flow docker image with:
docker pull jinaai/dalle-flow:latestLog into Huggingface, agree to RunwayML's terms of service, go to RunwayML's repository for the latest version, then download sd-v1-5-inpainting.ckpt. Rename that to model.ckpt and then, from that directory, run the following commands:
mkdir ~/ldm
mkdir ~/ldm/stable-diffusion-v1
mv model.ckpt ~/ldm/stable-diffusion-v1/model.ckptThen run the container with this command:
sudo docker run -e DISABLE_CLIP="1" \
-e DISABLE_DALLE_MEGA="1" \
-e DISABLE_GLID3XL="1" \
-e ENABLE_CLIPSEG="1" \
-e ENABLE_REALESRGAN="1" \
-e ENABLE_STABLE_DIFFUSION="1" \
-p 51005:51005 \
-it \
-v ~/ldm:/dalle/stable-diffusion/models/ldm/ \
-v $HOME/.cache:/home/dalle/.cache \
--gpus all \
jinaai/dalle-flow
Somewhere else, clone this repository and follow these steps:
git clone https://github.com/AmericanPresidentJimmyCarter/yasd-discord-bot/
cd yasd-discord-bot
python3 -m virtualenv env
source env/bin/activate
pip install -r requirements.txtThen you can start the bot with:
cd src
python -m bot YOUR_DISCORD_BOT_TOKEN -g YOUR_GUILD_IDBe sure you have the "Message Content Intent" flag set to be on in your bot settings!
Where YOUR_DISCORD_BOT_TOKEN is your token and YOUR_GUILD_ID is the integer ID for your server (right click on the server name, then click "Copy ID"). Supplying the guild ID is optional, but it will result in the slash commands being available to your server almost instantly. Once the bot is connected, you can read about how to use it with >help.
The bot uses the folders as a bus to store/shuttle data. All images created are stored in images/.
OPTIONAL: If you aren't running jina on the same box, you will need change the address to connect to declared as constant JINA_SERVER_URL in imagetool.py.
Install the Nvidia docker container environment if you have not already.
Make a folder for dalle-flow:
mkdir ~/dalle
cd ~/dalle
git clone https://github.com/jina-ai/dalle-flow
cd dalle-flowLog into Huggingface, agree to RunwayML's terms of service, go to RunwayML's repository for the latest version, then download sd-v1-5-inpainting.ckpt. Rename that to model.ckpt and then, from that directory, run the following commands:
mkdir ~/ldm
mkdir ~/ldm/stable-diffusion-v1
mv model.ckpt ~/ldm/stable-diffusion-v1/model.ckptIn the dalle-flow folder (cd ~/dalle/dalle-flow), build with this command:
docker build --build-arg GROUP_ID=$(id -g ${USER}) --build-arg USER_ID=$(id -u ${USER}) -t jinaai/dalle-flow .Then run the container with this command:
sudo docker run -e DISABLE_CLIP="1" \
-e DISABLE_DALLE_MEGA="1" \
-e DISABLE_GLID3XL="1" \
-e ENABLE_CLIPSEG="1" \
-e ENABLE_REALESRGAN="1" \
-e ENABLE_STABLE_DIFFUSION="1" \
-p 51005:51005 \
-it \
-v ~/ldm:/dalle/stable-diffusion/models/ldm/ \
-v $HOME/.cache:/home/dalle/.cache \
--gpus all \
jinaai/dalle-flow
Somewhere else, clone this repository and follow these steps:
git clone https://github.com/AmericanPresidentJimmyCarter/yasd-discord-bot/
cd yasd-discord-bot
python3 -m virtualenv env
source env/bin/activate
pip install -r requirements.txtThen you can start the bot with:
cd src
python -m bot YOUR_DISCORD_BOT_TOKEN -g YOUR_GUILD_IDBe sure you have the "Message Content Intent" flag set to be on in your bot settings!
Where YOUR_DISCORD_BOT_TOKEN is your token and YOUR_GUILD_ID is the integer ID for your server (right click on the server name, then click "Copy ID"). Supplying the guild ID is optional, but it will result in the slash commands being available to your server almost instantly. Once the bot is connected, you can read about how to use it with >help.
The bot uses the folders as a bus to store/shuttle data. All images created are stored in images/.
OPTIONAL: If you aren't running jina on the same box, you will need change the address to connect to declared as constant JINA_SERVER_URL in imagetool.py.
Follow the instructions for dalle-flow to install and run that server. The steps you need to follow can be found under "Run natively". Once flow is up and running, proceed to the next step.
At this time, if you haven't already, you will need to put the stable diffusion weights into dalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt.
Need to download the weights? Log into Huggingface, agree to RunwayML's terms of service, go to RunwayML's repository for the latest version, then download sd-v1-5-inpainting.ckpt. Rename that to model.ckpt and put it into the location specified above.
To start jina with old models disabled when you're all done:
python flow_parser.py --enable-stable-diffusion --disable-dalle-mega --disable-glid3xl
jina flow --uses flow.tmp.ymlJina should display lots of pretty pictures to tell you it's working. It may take a bit on first boot to load everything.
Somewhere else, clone this repository and follow these steps:
git clone https://github.com/AmericanPresidentJimmyCarter/yasd-discord-bot/
cd yasd-discord-bot
python3 -m virtualenv env
source env/bin/activate
pip install -r requirements.txtThen you can start the bot with:
cd src
python -m bot YOUR_DISCORD_BOT_TOKEN -g YOUR_GUILD_IDBe sure you have the "Message Content Intent" flag set to be on in your bot settings!
Where YOUR_DISCORD_BOT_TOKEN is your token and YOUR_GUILD_ID is the integer ID for your server (right click on the server name, then click "Copy ID"). Supplying the guild ID is optional, but it will result in the slash commands being available to your server almost instantly. Once the bot is connected, you can read about how to use it with >help.
The bot uses the folders as a bus to store/shuttle data. All images created are stored in images/.
OPTIONAL: If you aren't running jina on the same box, you will need change the address to connect to declared as constant JINA_SERVER_URL in imagetool.py.
- Generate images from text (
/image foo bar) - Generate images from text with a frozen seed and variations in array format (
/image [foo, bar]) - Generate images from text while exploring seeds (
/image foo bar (seed_search=t)) - Generate images from images (and optionally prompts) (
>image2image foo bar) - Diffuse ("riff") on images it has previously generated (
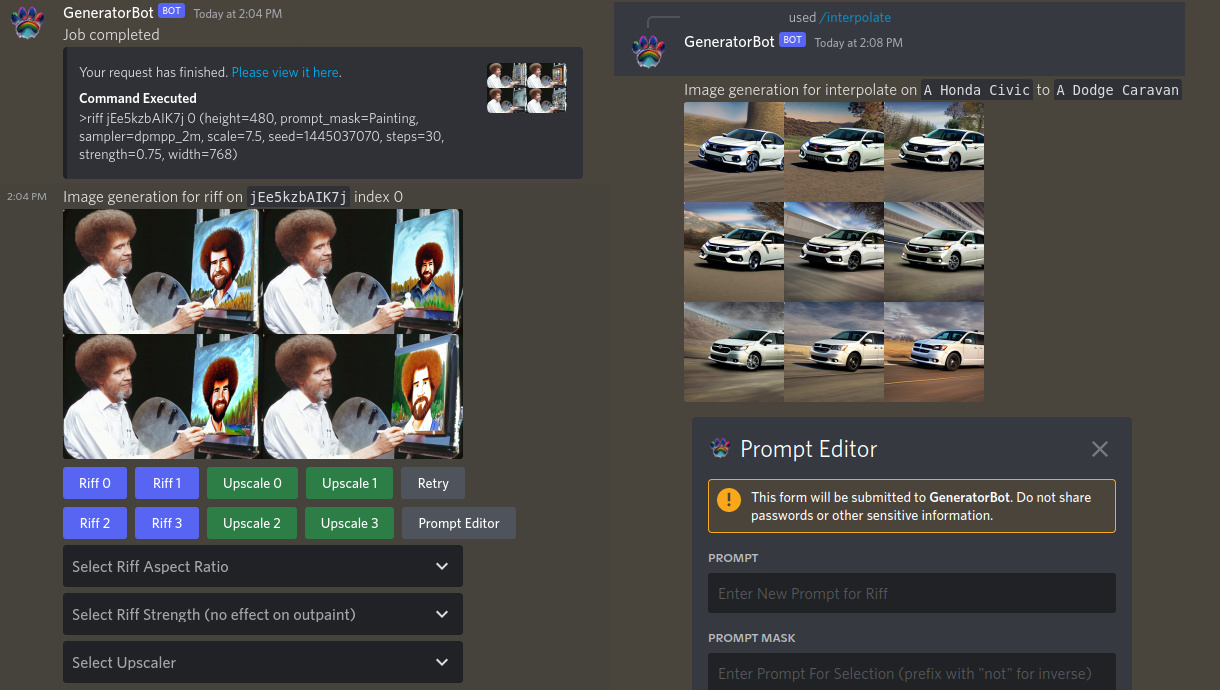
/riff <id> <idx>) - Interpolate between two prompts (
/interpolate <prompt 1> <prompt 2>) - Use any k-diffusion sampler to generate images
- Outpaint images directionally or in all directions at once
- Inpaint images with a mask selected automatically from text
- Queue generations per user and restrict the user queue to n-many generations at time
Examples:
>image A United States twenty dollar bill with [Jerry Seinfeld, Jason Alexander, Michael Richards, Julia Louis-Dreyfus]'s portrait in the center (seed=2)

>image2image Still from Walt Disney's The Princess and the Frog, 2001 (iterations=4, strength=0.6, scale=15)
Attached image

Output image

>interpolate Sonic the Hedgehog portrait | European Hedgehog Portrait

Open an issue here.
Be cool, stay in school.
Copyright 2022 Jimmy (AmericanPresidentJimmyCarter)