Google要处理互联网上海量的数据,对于这样数量级的数据,单机是不能在可接受的时间内处理完的,只能分布式的处理。
- 将算法转换成分布式算法
- 处理好分布式要面对复杂性
对于第一个问题,已经有些困难了,不是所有的算法都像Floyd一样天然有分布式的形态。
对于第二个问题,不仅会花费工程师大量的精力,而且这部分成本其实和其本来的工作关系不大。
能不能将分布式的复杂性封装起来,由框架设计者考虑,用户可以直接享用分布式的性能。
启发于函数式编程中的map和reduce源语。
工程师只需要考虑编写分布式程序的第一个问题,即将算法转换成符合“使用Map和Reduce的函数的编程范式”的算法,将两个实现交给MapReduce,系统内部来面对分布式的复杂性,继而满足需求。
这其实是一个受限制的实现,因为将原本的算法转换成符合这个程序模型的实现
- 需要成本
- 可能无解
一点小小的函数式编程震撼
计算任务以一系列输入键值对作为输入,并产生一系列输出键值对作为输出。
- Map
- 输入:输入键值对
- 输出:中间键值对(列表)
- Reduce
- 输入:中间键和其对应的一系列值
- 输出:输出键值对(键就是输入的键,值是关键,所以这里的输出本质是0或1个值)
对于这里的Map,我首先想到的是Python的内置函数map,虽然还有区别,但是有一个直观的理解,但是这里的Reduce确实对我个人来说比较难理解,这里还是借用Python库来理解。
>>> import functools
>>> functools.reduce(lambda x, y: x + y, [1, 2, 3, 4])
10这里的reduce原型类似于reduce(func, iter, init),这里的func一般是一个二元函数,reduce即对于每个迭代的值,将其和之前的结果放进二元函数中,再次拿到结果,以此类推(所以init的作用也是显然)。可以想象,MapReduce中的Reduce就是对于键所对应的所有值进行某种“汇总”。
这是一个批处理的工作流
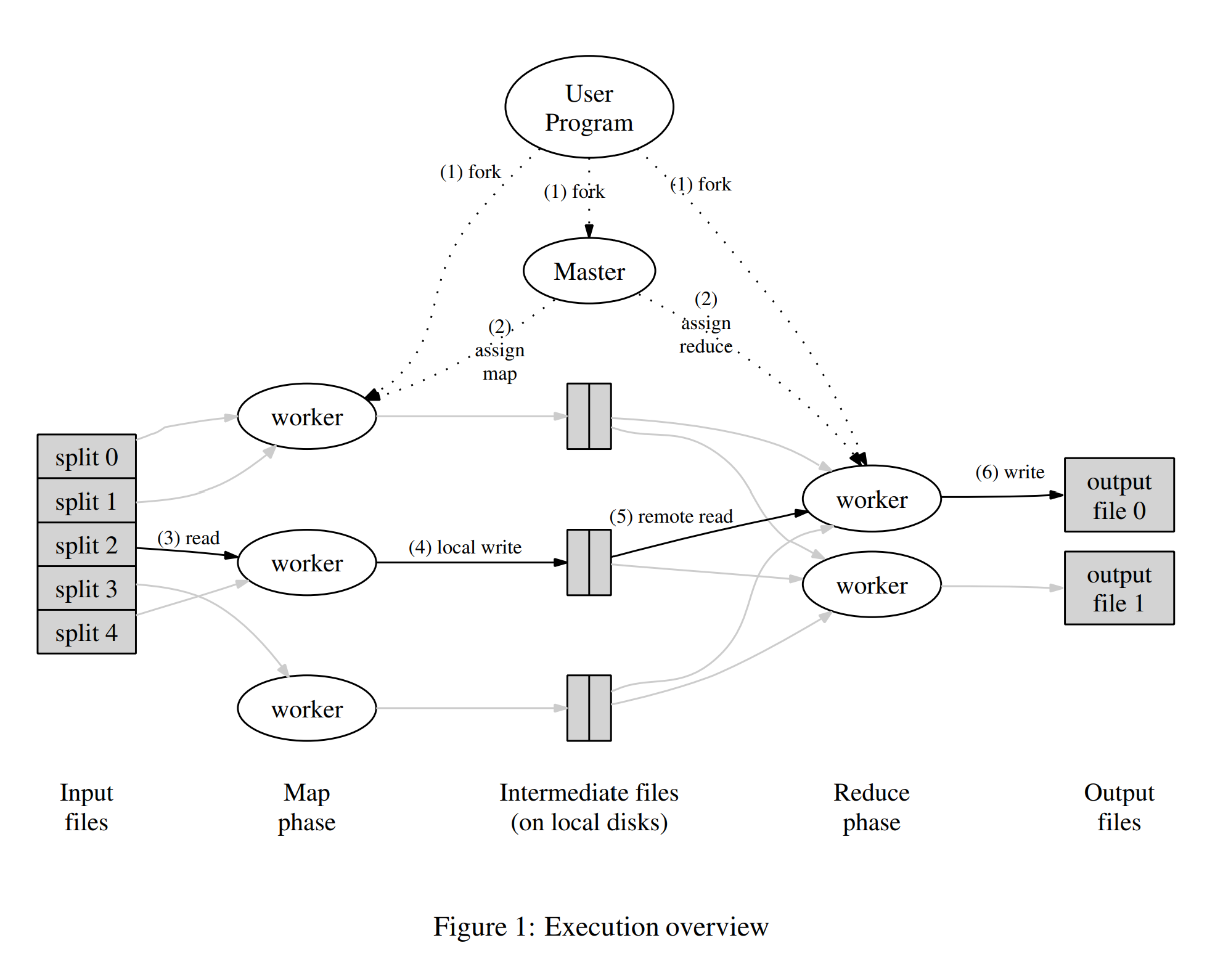
- Map函数的实现
- Reduce函数的实现
- Input files
- 整数M:map task的个数
- 整数R:reduce task的个数
Paper里提到系统将input files分成M份,每个通常是16MB或者64MB大小。但是这里M和input files都是由用户指定的,即这个大小不由系统控制,为什么?
这里用户提供的两个函数尽量确定的,来保证worker容错重运行后的语义。对不确定的函数的语义我不会证明。
- M和R应该远大于worker的机器数。
- 让每个worker执行多个不同的任务可以提高动态负载均衡能力,也可以在一个worker故障时提高恢复速度(该worker完成的多个map任务可以被分散到所有其他的worker机器上(否则,一个worker只有一个任务,它故障,它的任务只能在其他的机器上重跑,不能充分利用并行))
-
Input files分片,系统将程序(MapReduce代码和用户输入函数代码)拷贝部署到集群机器中
- 这里有一份程序是特殊的,叫master,其他的叫worker:master给空闲的worker分配map task或者reduce task
-
map阶段:
- 被指派map task的worker从input files split读取内容,解析其中的键值对,将其传入用户实现的map function中,输出的中间键值对缓存在内存中。
- 这些中间键值对定期写入local desk,并被
parititioning function分成R份 - 在磁盘中缓存的键值对信息会发送给master,master将这些信息进一步给到reduce worker
-
reduce阶段:
- master将part信息告知reduce worker
- 当一个reduce worker被master告知,它通过RPC(从map worker)读取这些键值对,读完后sort(这样同样的key的位置就连续了),如果太大,则使用external sort
- reduce worker将排序后的中间数据中连续的相同的key的数据执行用户实现的reduce function,其结果append追加到这个partition的output file中
- 该task结束,reduce worker会将这个output file rename(有底层的GFS保证这个操作的原子性)
这里的重命名是容错的,如果reduce function是确定的,则任何机器对相同的输入结果都是一样。而重命名保证原子性,保证结果唯一。
-
结束,交回程序控制权,MapReduce的输出可通过R个输出文件访问(每个reduce task一个文件,文件名由用户指定)
不需要合并,实际使用通常是多个MapReduce先后执行,这R个文件可以作为后面的输入。
- 有些东西需要整理下:
-
首先确定一点,MapReduce是分阶段的,即全部map task执行完毕后才进入reduce phase,即在reduce phase中,所有中间结果都是可取的。
- 问题出现在容错,即虽然可能reduce phase阶段中,仍然要保证map worker的活性,因为后者需要从中读,这里有一点异步,且没有说清,所以Lab并不需要。
-
每个map worker都对中间结果进行分区,所以map phase结束后应该是有
$M \times S$ 个分区,然后每个reduce worker都拿到M个分区。- 这里就指示了一点,可能出现一个键出现在一个map worker的两个分区中,或者不仅一个worker可看到。继而有两个reduce task处理厂,所以最后的
R个output files中也会出现多个文件有相同的键。所以最后output files也是对等的,而不是拼起来是正确完整答案。
- 这里就指示了一点,可能出现一个键出现在一个map worker的两个分区中,或者不仅一个worker可看到。继而有两个reduce task处理厂,所以最后的
-
每个reduce worker拿到
M个分区的中间数据,需要将这些数据放在一起然后排序(当然可能涉及外部排序)
-
- master data structure:
- all task(map and reduce) status: idle等待中, in-progress执行中, completed完成
- worker id:具体的指的是每个非等待中的任务所对应的worker的标识符
- intermediate info:具体的指的是每个已经完成的map task中R个中间文件区域的位置
- 当一个map task完成时,这些信息会增量的推送到“有执行中的reduce task”的worker中
这意味着,即两个阶段并行,又每个worker身份最开始就确定?
- 当一个map task完成时,这些信息会增量的推送到“有执行中的reduce task”的worker中
-
master fail:设置checkpoint复原或者直接认为MapReduce失败
-
worker fail
- master周期性的向worker发送心跳检测
- map worker fail:
- 其完成的所有task的状态设置为idle,因为这些中间文件需要通过rpc读,你ping都不行,这些东西肯定也读不了了。
- 这些task将被其他map worker re-execute,这个信息需要告知到reduce work(map task完成,会告知master,然后master告知reduce worker,此时reduce work还不知道对应的map worker fail了)
- 那如果这个worker之后“活”了呢?这里在master处理,因为每个map worker处理完后会通知master嘛,master发现这个worker完成的task是complete的,则忽略这个通知
- reduce worker fail:
- 如果已经执行完了则不会重新执行,因为reduce的结果已经维护在GFS上了,否则设置idle准备重新运行。
- 离群问题,几个worker完成的很慢,MapReduce可能将其上的task给到几个其他worker做部分
- 分区函数(map worker完成task后将中间数据分成R个分区的函数),通常是取模,但是对于特定类型自定义更好,支持自定义。
- 合并函数,比如在统计中,中间键值对可能就是形如
<string: 1>的形式,这样的话在reduce task中可能每个键的值很多。所以这些可以在之前处理一下,比如在map将中间数据落盘前,没有排序可能也有相邻的,这里就可以先进行一次合并。所以合并函数通常和reduce function一样。
- 关于worker,在论文中似乎每个worker是什么类型在部署时确定,但是在lab中每个worker是对等的,可以执行任何任务。
- 我的实现是尽量依照论文的,而且是明确分阶段的(这个我个人在论文中是模糊的),其实脱离论文可以将MapReduce实现的很trick,比如谭新宇的实现。
- 还有一个不同是在论文中worker和master之间是可以相互通信的,但是在Lab只有master有rpc服务端,所以论文中所有master向worker的通信需要改
- master向worker分配任务 -> worker主动向master请求任务
- master ping worker去心跳检测 -> worker定期向master发送心跳检测