2023 Spring
完成Lab过程的一些记录,确保遵守Academic Integrity
可以认为我没有数据库理论知识基础,低年级时草草看过萨师煊先生的《数据库系统概念》,但是一方面当时对数据库没有一个整体的框架,理解不够,另一方面时间太过久远。所以四舍五入下等于没有学过。本次实验前也没有做相关知识的补充,前期唯一的参考资料就是官方手册,基本是它让我干什么,我就对应的去查、去学、去写。C++基础有一些,实现方式基本靠直觉,前两个Lab性能一般。后面大概率不会做优化。
针对在Windows上,编译运行环境使用VMware虚拟机安装Ubuntu,开发环境使用本机VSCode SSH到虚拟机的路线的话。
- https://github.com/zweix123/CS-notes/blob/master/Missing-Semester/WindowsConfigGuide.md 配置一下win的一些环境,主要是针对命令行,可以省略。
- 上面教程的这里 https://github.com/zweix123/CS-notes/blob/master/Missing-Semester/WindowsConfigGuide.md#%E8%99%9A%E6%8B%9F%E6%9C%BAvmware-workstation-pro 提到几个必要的部分:
- 图形化启动虚拟机(图形化启动更快,占用本机资源更少,如无必要勿增实体)
- 本机如何SSH到虚拟机中(可能需要下面配置Linux教程中的一部分)
- 虚拟机共享本机魔法
- 上面教程的这里 https://github.com/zweix123/CS-notes/blob/master/Missing-Semester/WindowsConfigGuide.md#%E8%99%9A%E6%8B%9F%E6%9C%BAvmware-workstation-pro 提到几个必要的部分:
- 当我们可以ssh到linux中后(在这个实验中忘记虚拟机的图形化吧), https://github.com/zweix123/CS-notes/blob/master/Missing-Semester/LinuxConfigGuide.md 用这个教程配置下Linux,其中必要的是关于SSH、软件源和Git,个人强烈建议鼓捣下tmux和zsh,生产力的提升,jyy说”舒服很重要“
- 按照等疾风大佬的视频配置下本机的VSCode, https://www.bilibili.com/video/BV1YG4y1v7uB/ ,我这里也有一些补充 https://github.com/zweix123/CS-notes/blob/master/Missing-Semester/VSCode.md
- 配置VSCode关于C++的东西,其实这些包含于djf的视频中,但是他使用的是ms C++插件,这里有clang的 https://github.com/zweix123/CS-notes/blob/master/Missing-Semester/VSCode.md#cc
- 最后就是VSCode关于debug和cmake的配置,需要的插件也在djf的视频中,对应的配置(其实也在dfj的视频中)在这 https://github.com/Codesire-Deng/TemplateRepoCxx/tree/main/.vscode 理论上直接copy过来就配完了。
上面的资源应该可以拼凑出完整的BusTub开发工作流。
正如经典的程序就是数据结构+算法,一定要理清题目想让我们做什么,以及一个方法的调用会导致内部数据结构如何变化。
就我个人而言,卡住的地方主要有三段。
-
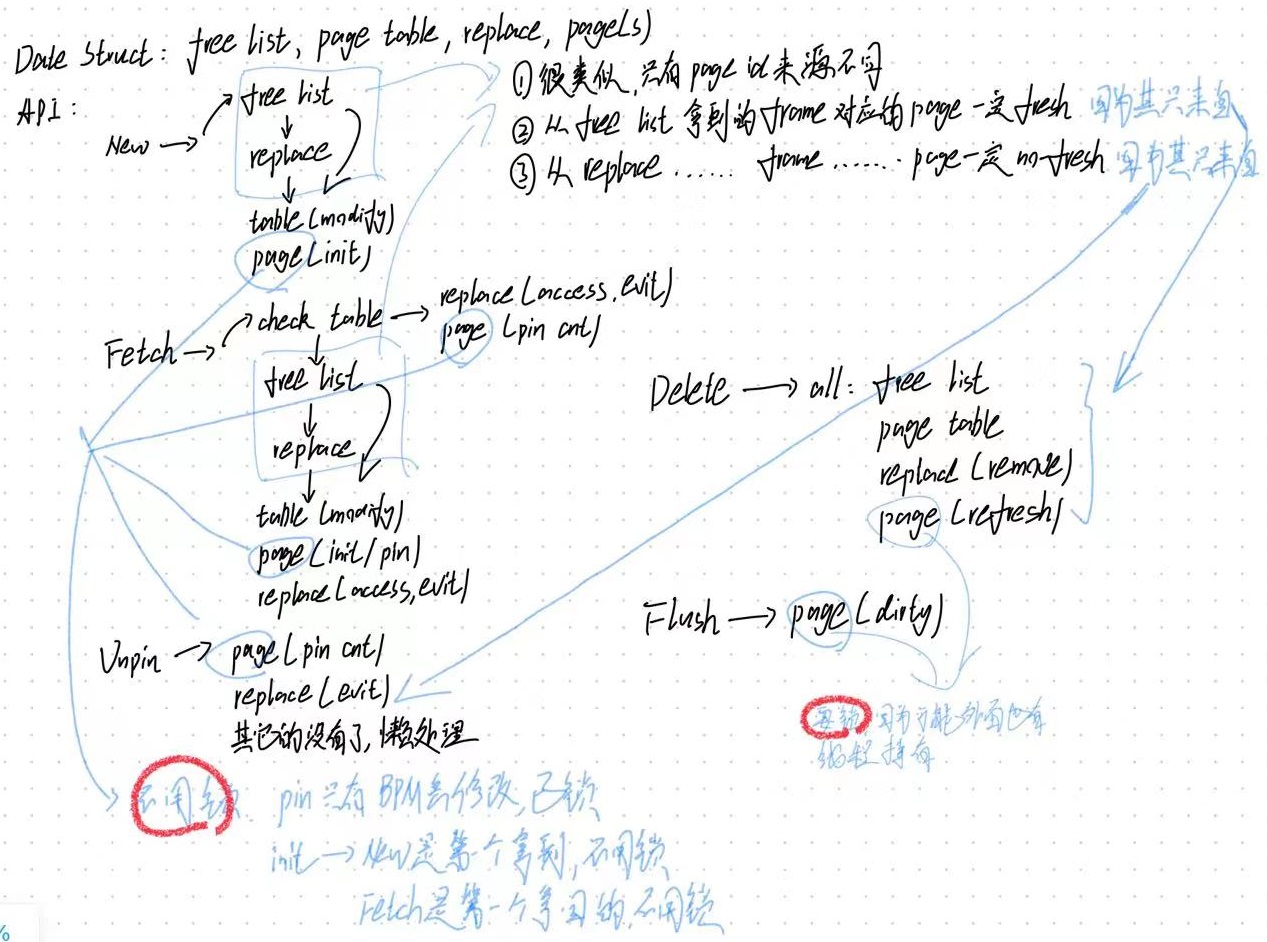
对BPM接口功能的理解以及各个接口应该带来哪些数据结构的哪些变化,理清即可,分数从69的91,结论如下图(自用,不保证可读性)
-
一个类似
unique_ptr功能类的实现,说来惭愧,之前并没有实现过移动相关的标准函数,所以闹了两个乌龙- 在移动构造函数时也
Drop,因为这里有检测,所以这个调用应该没有造成任何变化。这里本来就是为了构造this,肯定是不需要Drop的 - 在移动拷贝函数中没有检测自己移动向自己,出现
pin count错误不过这个不应该在编译器就error的嘛?不知道线上的测试是什么样子的。
- 在移动构造函数时也
-
并发问题,即
FetchPageWrite/FetchPageRead不能使用函数锁,是先锁住拿到页实例指针,然后就释放BPM的锁,然后再获取页实例的Latch,否则就会死锁,这个是看前辈的攻略才知道理解的。比如这样的样例,比如一个线程持有一个page latch,另一个线程通过bpm去fetch同样的页,就在加页锁的时候等待了,而第一个也调用bpm的方法,就死锁了。其实纳入这个想法,我的实现应该还有锅,或者说有的锁可以省略,这些也添加到上面的图里了,但是代码还没有改,而且有锅的地方也通过了测试,可能和测试样例中BPM的用法有关。
- Reference:
主要是对B+Tree的实现,我个人算法实现依照教材《DataBase System Concepts 7th》,下面是对教材中相关内容的简单翻译和整理,个人建议一定要理清伪代码的逻辑,而且教材和Bustub的实现中结点格式是不一样的,一定要定量的理清里面的关系。我基本相当于一遍过的,因为这里卡了两小下一个是对教材中
同时我的实现也很直觉简单,因为Bustub提供的上下文类Content就有树的Header Page Write Guard,这相当于一个可以锁住整个树的写锁了,相当于我直接用的一个大锁,什么螃蟹锁啥的都没有。
-
B Plus Tree首先是一种Balanced Tree
-
B Plus Tree有两种node类型
- noleaf node/internal node:
- 非root的internal node的child数量在
$\lceil \frac{n}{2} \rceil$ 和$n$ 之间(闭区间) - root的child数量在
$2$ 和$n$ 之间
- 非root的internal node的child数量在
- leaf node:
- “child”数量在
$\lceil \frac{n - 1}{2} \rceil$ (相当于$\lfloor \frac{n}{2} \rfloor$ )和$n - 1$ 之间(闭区间)leaf node的child就是recored
- “child”数量在
我理解这里的最小数量也并不神秘,只要保证一个刚刚好溢出的node被尽可能均分后两个页可能的最小值。
上面的描述是符合Bustub中的B+Tree的,当然对应node的n使用对应node类型的max size,值得一提的是internal node中第一个invalid键和其对应的值作为的键值对也包含在size里。
- noleaf node/internal node:
-
对于每个node(无论是internal还是leaf),设其max size为n,则其包含
n - 1个key,n个pointer,如下:
- 其中
K严格单调递增(暂时不讨论相同Key) - 在Internal node中
- pointer为childern node pointer
- 对于一个node pointer
$P_{i}$ ,其指向的node的所有的key都满足,大于等于$K_{i - 1}$ ,小于$K_{i}$ ,即左闭右开区间。
- 在leaf node中
- 前
n -1为正常的键值对,最后一个pointer不与任何键匹配(从图里发现),它指向的是其右边第一个叶子结点。
- 前
- 其中

-
联系:
- 我们知道了为什么internal node最多有n个child,而leaf node却最多有n - 1个“child”,这是因为即使是同样的n,并且确实使用同样的格式,但是leaf node的最后一个pointer有特殊的用法,所以不能用来指向child
- 上面的设计也是合理的,因为这
n - 1个key和n个pointer在不同结点表达的语义不同- internal node:将值域通过
n - 1个key划分成n个左闭右开区间 - leaf node:前
n - 1个<pointer, key>对形成键值对。
- internal node:将值域通过
-
实现:上面的定义和在Bustub的实现还是有挺大的Gap的
- internal:
- Bustub对键值对的存储使用
std::pair<KeyType, ValueType> array_[],至少我对其最直觉的想象是key[0], pointer[0], key[1], pointer[1], key[2], ...的序列,然后还要求key[0]是invalid的,所以序列变成pointer[0], key[1], pointer[1], key[2], ..., key[size - 1], pointer[size - 1],但是我们发现教材上的序列相当于pointer[1], key[1], pointer[2], ..., key[n - 1], pointer[n - 1], pointer[n],这里索引对不上(我指的是Bustub中是第一个pointer单独一组,然后后面的一key一pointer一组,而教材中是第一个pointer和第一个key一组),即两者虽然pointer和key的先后顺序一致,但是具体的对应关系不一致。我本来有一个trick的做法,但是Bustub给我提供了图形化相关的辅助函数,还必须按照上面的方式写。我这里是忽略这里的“成对”的关系,把握“分割”这个性质即可,对应的点也会注释在下面的伪代码中。
- Bustub对键值对的存储使用
- leaf:
- Bustub使用的是索引从0开始到
size - 1的pair线性表,而有特殊作用的pointer使用额外的数据成员表示,这也解释了为什么leaf的内容数量最多到leaf_max_size - 1,是从概念出发的。
- Bustub使用的是索引从0开始到
- internal:
-
单点查询key的recored:函数
find,伪代码如下:function find(v) // Assumes no duplicate keys, // and returns pointer to the record with search key value v if such a record exists, // and null otherwise. // 这里没有讨论树为空 Set C = root node while (C is not a leaf node) begin Let i = smallest number such that v <= C.K[i] if there is not such number i then begin // 即v大于C中所有的键 Let P_m = last non-null pointer in the node // 因为最后的一个pointer表示的child node的key大于等于结点的最后把一个key // 上面可行还是根据最后一个P是独立的, 即没有对应的K(看图), 但是在Bustub就使用最后一个键值对的值 Set C = P_m end else if (v == C.K[i]) then Set C = C.P[i + 1] // 因为区间是左闭右开嘛, 所以如果和边界相等, 应该是右边的 else Set C = C.P[i] // v < C.K[i] // 上面两句在Bustuh中的实现应该是不同的 end // C is a leaf node if for some i, K[i] == v then return P[i] else return null; // No record with key value v exists end
-
range queries区间查询:函数
findRange,伪代码如下:function findRange(lb, ub) // Return all records with search key value V such that lb <= V <= ub(闭区间) Set resultSet = {}; Set C = root node while (C is not a leaf node) begin Let i = smallest number such taht lb <= C.K[i] if there is no such number i then begin Let P_m = last non-null pointer in the node Set C = P_m end else if (lb == C.K[i]) then Set C = C.P[i + 1] else Set C = C.P[i] // lb < C.K[i] end // 上面代码思路和单点查询一致, 值得一提的是区间内的recored是C的一部分 // C (must) be leaf node Let i be the least value such that K[i] >= lb // i是C中大于等于左区间点的第一个键的索引 if there is no such i then Set i = 1 + number of keys in C; // To force move to next leaf // 此时i为指向下一个叶子结点的P的索引 // 主要key的数量是n - 1, 此时其number + 1就是索引n Set done = false; while (not done) begin Let n = number of keys in C. // 如果上面的force move执行了, 则下面的分支不会进入, 再次强调leaf node中key的数量是n - 1 if (i <= n and C.K[i] <= ub) then begin Add C.P[i] to resultSet Set i = i + 1 end else if (i <= n and C.K[i] > ub) then Set done = true; // 别忘了这里的n是key number, 而key number是教材中的n - 1,所以下面没问题 else if (i > n and C.P[n + 1] is not null) then Set C = C.P[i + 1] and i = 1 // Move to next leaf else Set done = true; // No more leaves to the right end return resultSet
对B Plus Tree的Updates可以be modeled as先删除再插入,所以只考虑插入和删除两个操作。而这两个操作涉及node的split和coalese/combine。
procedure insert(value K, pointer P)
// 在树种插入键值对<K, P>
// 注意这里P是一种抽象, 既可以是recored的pointer, 也可以是其他node的pointer, 这样的优势在下面会体现出来
if (tree is empty) create an empty leaf node L, which is alse the root
else Find the leaf node L that should contain key value K
// 检测是否有重复键, 教材是假设输入没有重复
if (L has less than n - 1 key values) // leaf node最多有n - 1个键值对
then insert_in_leaf(L, K, P) // 位置充足, 直接插入
else begin // L has n - 1 key values already, split it
Create (new leaf) node L_
Copy L.P[1], ..., L.K[n - 1] to a block of memory T that can hold n pairs
insert_in_leaf(T, K, P)
Set L_.P[n] = L.P[n];
Set L.P[n] = L_
Erase L.P[1] through L.K[n - 1] from L
Copy T.P[1] through T.K[std::ceil(n / 2)] from T into L starting at L.P[1] // std::ceil(n / 2)个
Copy T.P[std::ceil(n / 2) + 1] through T.K[n] from T into L_ starting at L_.P[1] //。 std::floor(n / 2)个
Let K_ be the smallest key in L_ // 左闭右开区间, 所以划分两个结点的应该是右节点的最小键
insert_in_parent(L, K_, L_)
end
// function insert_in_leaf caller must ensure L hava space to store <K, P>
procedure insert_in_leaf(node L, value K, pointer P) // L: leaf node, K: key, P: recored pointer
// 教材没有检测L为空, 其实也不需要, 因为如果没有键则会在下面的循环中没有结果, 看实现吧
if (K < L.K[1])
then insert P, K into L just before L.P[1]
else begin
Let K[i] be the highest value in L that is less than or equal to K
Insert P, K into L just after L.K[i]
end
procedure insert_in_parent(node N, value K_, node N_)
// N和N_会成为两个兄弟, 其中N本来就在B+Tree上, N_是在格外的空间创建, 他们的边界是K_, 它是N_的最小值, 左闭右开!
if (N is the root of the tree)
then begin
Create a new (internal) node R containing N, K_, N_
// textbook: p[1] = N, k[1] = K_, p[2] = N_
// Bustub: k[0] = INVALUE, p[0] = N, k[1] = K_, p[1] = N_
Make R the root of the tree
return
end
Let P = parent(N)
if (P has less than n pointers)
then insert(K_, N_) in P just after N // 这里不是递归调用上面的procedure insert, 而是表示一个动作, 且这个动作是无递归的
else begin // Split P
Copy P to a block of memory T that can hold P and <K_, N_>
Insert(K_, N_) into T just after N // 同上, 表示动作而非调用
Erase all entries from P;
Create node P_
Copy T.P[1], ..., T.P[std::ceil((n + 1) / 2)] into P
Let K__ = T.K[std::ceil((n + 1) / 2)]
Copy T.P[std::ceil((n + 1) / 2) + 1], ..., T.P[n + 1] into P_
// P size : std::ceil((n + 1) / 2) > std::ceil(n / 2)
// P_ size: std::floor((n + 1) / 2) == std::ceil(n / 2)
// 注意这里的K__的选择, 它选择的是P的中的key么?不是, 反而是P_中的键?为什么
// P[1], K[1], P[2], K[2], ..., P[bound] | K[bound], P[bound + 1], ... P[n + 1]
// 同时类似leaf split, 我们看一下教材和Bustub的差异
// textbook: P[1], K[1], P[2], K[2], ..., K[bound - 1], P[bound] | K[bound] , P[bound + 1], ... P[n + 1]
// Bustub: K[0], P[0], K[1], P[1], K[2], ..., K[buoud - 1], P[bound - 1] | K[bound] = INVALUE, P[bound], ..., P[n]
// 这里Bustub反而好实现, 即copy 0 ~ bound - 1键值对即可
// 在Bustub中的实现要注意上面的问题
insert_in_parent(P, K__, P_) // 递归向上
end删除确实要比插入复杂些,因为如果一个结点的键值对个数不能半满,就需要和sibling兄弟coalesce合并,但是兄弟可能键值对比较多,两者键值对个数加起来又超过一个结点能容纳的量,就需要redistribute
procedure delete(value K, pointer P)
// 树是否空?
find the leaf node L that contains (K, P)
// 键值对是否在该叶子中?
// Bustub中Remove方法的参数只有一个K, 所有我这里只检测值是否存在
delete_entry(L, K, P) // 叶子, 键, 值
procedure delete_entry(node N, value K, pointer P)
// 参数分别是当前结点, 可以是internal也可以是leaf, 但是其实从一开始这个结点就是确定的(废话)
// 参数P在下面的代码中只在找sibling时需要
delete(K, P) from N // 同上, 表示动作而非调用, 我们已经在Delete的入口检测该键值对是否存在了
if (N is the root and N has only one remaining child) // leaf和internal都可以是根, 但是只有internal可能有孩子
then make the child of N the new root of the tree and delete N
else if (N has too few value/pointer) then begin // 数量低于下限, 注意internal是孩子, leaf是键值对个数, 而是还有一个特殊的种类, 根, 根的下限是二
// 整个代码块只有两个分支
// -> 有一个儿子的根
// -> 不足
// 对于leaf
// 是根: 任意键值对个数
// 不是根: 不能低于下限
// 对于internal:
// 是根: 只有1个孩子, 特判; 有两个及以上儿子, 符合根的下限
// 不是根, 不能低于下限
Let N_ be the previous or next child of parent(N)
Let K_ be the value between pointers N and N_ in parent(N)
if (entries in N and N_ can fit in a single node)
then begin // coalesce nodes
if (N is a predecessor of N_) then swap_variables(N, N_)
// 注意!, 这里可以看下教材, swap_variables是指交换N和N_的指针, 即下文中两者互换了, 而不是交换内容
// 即期望: N_ N
// 所有都移动到左边N_
if (N is not a leaf) then append K_ and all pointers and value in N to N_
else append all(K[i], P[i]) pairs in N to N_; set N_.P[n] = N.P[n]
delete_entry(parent(N), K_, N);
delete node N
end
else begin // Redistribution: borrow an entry from N_
// 进入该分支条件: 不足半满, 且相邻两个不能放在一个, 而自己是刚好不足半满, 兄弟一定超过半满, 而不能合在一起, 所以肯定多的给少的一个, 多的那个也是满足半满的
if (N_ is a predecessor of N) then begin // 左右意味着多少, 我觉得没法用一份代码表示
// N_和N的结点类型应该相同, 只是下面以N的类型表示
// 注意下面都是从N_从拿一个放N中, 而不是按方向放的, 方向的意义是间隔的位置
if (N is a nonleaf node) then begin // internal
let m be such that N_.P[m] is the last pointer in N_
remove(N_.K[m - 1], N_.P[m]) from N_
// 这里的数值关系结合上面的图, 总之就是去掉左边的最后一个“边界”
insert(N_.P[m], K_) as the first pointer and value in N, by shifting other pointers and value right
replace K_ in parent(N) by N_.K[m - 1]
// 注意上面, 还是由于internal的键值的对应关系, 删除最后一个键和值, 然后插入的就值和一个新键
// 我们看这个新键来自Parent的N_和N的间隔K_, 而删除的是N_.K[m - 1], 可以保证N_.K[m - 1] < K_,
// 所有原本是N_.K[m - 1]在左儿子, 然后K_在parnet, 现在将K_换到右儿子, N_.K[m - 1]换到Parent, 合理
// 这里推荐画画图, 也挺好用的
end
else begin
let m be such that (N_.P[m], N_.K[m]) is the last pointer/value pair in N_
remove (N_.P[m], N_.K[m]) from N_
insert(N_.P[m], N_.K[m]) as the first pointer and value in N, by shifting other pointers and values rigth
replace K_ in parent(N) by N_.K[m]
// 键的转换关系同上
// 我们看一下如果镜像时候是什么样, 仅仅把握左闭右开区间即可
end
end
else ...symmetric to the then case...
end
end
// 我们可以想象else还有什么情况, 比如叶子是根, 然后pair个数到1- Reference:
- 关键点一:火山模型,即查询解析层究竟在干什么事情,实际上15445几乎完成了这一层的所有需要代码,要理解就顺这代码看即可(gdb出现bug了,我就静态的看然后一步步打日志的)。因为我之前实现过一个解释器,对这部分相对来说理解的比较顺畅。那么如何理解BusTub的火山模型呢?在解释器中,可以编译到AST然后直接在AST上执行即可,火山模型和这个非常非常的像。即树中的每个结点都有以及基类(或者接口),有必须实现的公共的API,然后父节点调用子节点的API,结点之前也以某种数据类(基类)为载体传递信息。那么15445的火山模型中每个结点的公共接口就是
Init和Next,然后父子结点之间通过Next传递Tuple。对于这些抽象出来的类,这个文章讲的很清楚(感谢群友提供) - 关键点二:关键API,比如这里的索引相关的API,不看前辈攻略肯定是不知道的。
这里再推荐两个前辈对BusTub的架构分析,十一和码呆茶,可以把这理解为项目手册
为手册不全的开源项目贡献代码可是很痛苦的。
那么搞懂项目架构之后就按着直觉写就行了,而且这次本地和线上的测试样例还是一样的,无形之中降低了难度。
我也终于知道为啥ddb要考哈希表了,在最开始是问我会不会HashJoin,我说没写到这呢,然后让我写哈希表。可恶,原来是HashJoin的实现需要手写哈希表。BusTub提供的对Value的哈希函数是会出现冲突的,比如INTEGER的9和8200,所以使用的哈希表必须支持哈希冲突,std::unordered_map不行,所以这里需要手写,可能也正是因为面试考过了,我这里实现的挺顺畅。也许面试前这里做到了可能面试能过?毁灭吧赶紧的(最近攻击性见涨)
UPDATE:标准库可以,有群友在聚合函数中15445提供的代码中有找到可借鉴的代码。
相关代码中15445提供了Note,下面是翻译和总结
- 约定一个缩写:
导致TA(Abort Reason)表示导致set the TransactionState as ABORTED and throw a TransactionAbortException(${Abort Reason})
| Dirty Read | Unrepeatable Read | Phantom | |
|---|---|---|---|
| serializable | No | No | No |
| repeatable read | No | No | Maybe |
| read committed | No | Maybe | Maybe |
| read uncommitted | Maybe | Maybe | Maybe |
回来补课了,对不同隔离级别会出现什么问题的理解,很影响Task3的实现。
-
三个问题具体指的是什么?
- 脏读:一个事务读到另一个未提交事务的数据,此时未提交事务可能回滚,继而前一个事务导致读到不正确的数据
群友给出了合适的解释。
- nonrepeatable read:A transaction re-reads data it has previously read and finds that data has been modified by another transaction (that committed since the initial read).
- phantom read:A transaction re-executes a query returning a set of rows that satisfy a search condition and finds that the set of rows satisfying the condition has changed due to another recently-committed transaction
不可重复读适用于同一个Row,幻读适用于一个谓词,还得是U姐姐。
- shared
- exclusive
以上两者即general的读写锁,即读和读不互斥,读和写互斥,写和写互斥。
- intention_shared
- intention_exclusive
- shared_intention_exclusive
以上三者的核心在于intention意向, 即表示事务希望获取对应的锁,其中第三个表示即有可能放共享锁也有可能放排他锁。
-
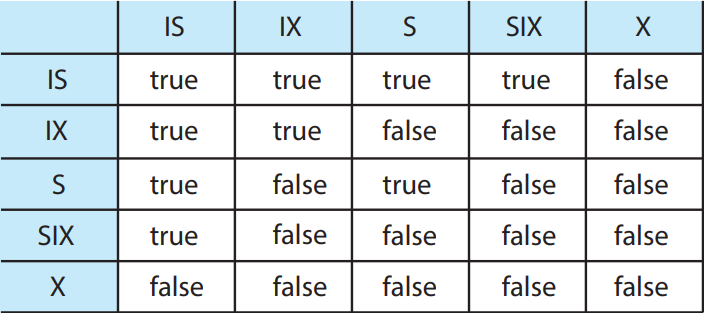
锁模式的兼容:
算是一个小坑点吧,15445的Note没有提到这个问题,教材《Database System Concepts, 7th》中的第18章第3小节(我这里是884页末尾)有对应的表,放在下面。
-
一般行为:对于两个
Lock()方法- 是block的,它们应该等待直到lock is granted
- 如果成功则return true,如果等待过程中事务aborted了,则return false
-
资源:即表或者行
- 对于每个资源都有一个队列,请求这个资源的事务被FIFO的赋予锁
- 如果有多个compatible的锁请求,只要符合FIFO,就可以一起被给
当锁行时,比如确保这个事务有appropriate的对于这个行所在的表的锁,否则导致TA(TABLE_LOCK_NOT_PRESENT)
关于这里的appropriate,我按照下面的理解写的,这里没有找到比较官方的资料
-
S,需要S,IS或SIX
-
X,需要X,IX或SIX
-
IS,IX,SIX,我认为对行使用这样的锁模式是不对的。
-
对于
LockTable()和LockRow(),支持的锁模式是不同的LockTable()支持所有的锁模式LockRow()不支持意向锁,尝试会导致TA(ATTEMPTED_INTENTION_LOCK_ON_ROW)
-
隔离级别和事务阶段对锁的限制:对于某个隔离级别,一个事务可以尝试的锁必须
required且allowedrequire growing allow shrinking allow repeatable read all all none(LOCK_ON_SHRINKING) read committed all all IS, S(LOCK_ON_SHRINKING) read uncommitted IX, X(LOCK_SHARED_ON_READ_UNCOMMITTED) X, IX(LOCK_SHARED_ON_READ_UNCOMMITTED) null(LOCK_ON_SHRINKING) 单元格中即为require或者allow的锁模式,包括中的内容则是违反导致的TA
- 关于读未提交,共享锁相关的锁模式是不允许的,且优先级最高,即在shrinking阶段使用S相关锁是导致TA(LOCK_SHARED_ON_READ_UNCOMMITTED)而不是导致TA(LOCK_ON_SHRINKING)
-
锁升级,如果对资源调用、
Lock()时调用的事务已经持有这个资源的某种锁时的行为。- 如果锁模式一样,则直接return true
- 如果锁模式不一样,考虑升级
- 检查升级条件:
- 有这么个锁
- 锁模式不一样
- 对应的资源没有其他事务在升级锁
- 锁模式转换是合法的。
- Drop当前锁
- 等待新锁
- 检查升级条件:
事务的锁升级这件事是优先于事务的锁请求的
允许的转换:
IS -> [S, X, IX, SIX] S -> [X, SIX] IX -> [X, SIX] SIX -> [X]对其他任何的升级都会导致TA(INCOMPATIBLE_UPGRADE)
- 对于每个资源,只允许对它的一个事务进行锁升级,否则导致TA(UPGRADE_CONFLICT)
-
首先,你
Unlock()得确定这个事务持有这个资源的锁,否则导致TA(ATTEMPTED_UNLOCK_BUT_NO_LOCK_HELD) -
其次,当你释放一个对表的锁时,得保证这个事务没有对这个表的行的锁,否则导致TA(TABLE_UNLOCKED_BEFORE_UNLOCKING_ROWS)
-
最后,释放一个资源的锁,(还记得每个资源有个锁请求队列么?)则将这个资源给到它的下一个锁请求(这个在实现上是condition variable的notice all)
-
事务状态变化:解锁会导致事务状态(根据隔离级别)做appropriately地变化
只有对S或者X的解锁会导致事务状态变化
S X repeatable read shrinking shrinking read committed not affect shrinking read uncommitted UB shrinking - 上面的read uncommited的S的unlock是ub是因为这个隔离级别根本不允许上共享锁
- 具体算法我是按照十一大佬的攻略
- 我的差别在,请求队列中的锁请求的分布,我的队列保证某个前缀(可以是空)全是拿到锁的,剩余部分(一个后缀(可能为空))全是没拿到锁的。然后这个姿态天然决定了优先级,所以对需要升级锁放在未给锁的前面。
- 个人建议;在实现时最好考虑要保证可以对事务状态是Commit和Abort的鲁棒性,且由于T2的测试代码不会测试代码,在T3也要对这部分代码保持怀疑。
吐槽一个小点吧,我个人认为诸如AddEdge和RemoveEdge的这些方法应该设置成私有的,因为他们是服务于后台程序的嘛,但是15445为了测试建图部分,将这部分设置成公有的。这个无形中就对在图上搜索顺序有了要求,比如找环的遍历方式要求从最小的tid开始,实际上这个应该不关键(也许吧,毕竟最小说明被卡的时间最久,所以确实需要优先处理)(但是话又说回来,先从最早的开始也不一定能搜索到最老的导致环的结点吧?)想不清想不清,让我怎么实现我怎么实现吧。
下面是Handout中Note的翻译已经结合别人攻略和自己理解的注解
一个事务可能执行多个查询,即一个事务中,一个tuple可能被不同查询多次访问
-
如果上锁或者解锁失败,事务中止
-
如果事务中止,则需要撤销之前的写入操作,为每个事务维护一个write set,由TransactionManager的
Abort()使用- 关于这里的write set,我们看类
Transaction中有数据成员table_write_set_和index_write_set_,以及相关的方法GetWriteSet和AppendTableWriteRecore,我们ag一下发现这些都是都没有被用过,然后这些东西维护的是这样一个信息类TableWriteRecore,其中包含Table ID, Record ID, Table Heap Pointer, 我们有理由相信这就是15445给我们提供的作为write set的基础设施。
- 关于这里的write set,我们看类
-
如果算子未能获取锁,则抛出
ExecutionException异常。 -
不同隔离级别的处理:
P3涉及的三个算子中,Seq Scan只涉及读,Insert和Delete只涉及写-
读:
- repeatable_read:事务应该为所有读操作获取并持有S锁util it commit or abort
- read_commited:事务应该为所有读操作获取S锁,然后立刻释放它们
- read_uncommited:事务不需要为读操作获取任何S锁
-
写:
- 任何隔离级别的所有写操作都必须持有X锁util it commit or abort
-
-
SeqScan算子
对表加IS锁,对行加S锁。
如果算子中不存在谓词则直接给表上S锁,避免一个个给行上锁(我这里不涉及)
-
Init:- take a table lock.(按照隔离级别)
- 通过
MakeEagerIterator获取迭代器(而不是P3中的MakeIterator)handout说是P3使用是为了解决Halloween problem的问题,我理解就是这个问题在P4中由我们负责(通过事务)
-
Next:- Get the current position of the table iterator. 我理解这里指的是迭代器的自加
- 根据隔离级别为相应的tuple上锁,迭代器可以
GetRid()- 如果executor context的
IsDelete()是真,则这里应该是X锁
- 如果executor context的
- 拿到tuple(我理解是迭代器的GetTuple),检测tuple meta,如果有filter pushdown to scan(我这里不涉及)
- 如果这个tuple不应该被这个事务read,force 对行解锁,否则则是按照隔离级别解锁。
- 这里我理解,就是对于tuple这个资源,在上面第二部进行了加锁,在第三部进行了读取,那么完事之后就应该进行解锁。
- 那么什么时候不应该读呢?一个是上面说的
IsDelete,还有就是是否通过谓词(我这里不涉及)
假设:我使用的tuple meta中的is_deleted检测是否可读(当然第二步的补充还是使用IsDelete)
它是这么说,但是我实现上只要确保这个迭代器按要求上锁了就行,啥时候拿的具体的值对结果没影响。
- 我在P3中是使用迭代式的方式实现,在这里语义上确实奇怪,后换成递归式才顺眼很多。
-
以下两个算子在Init上锁指的是IX锁,在Next对行上X锁。
-
Insert算子
Init:take a table lockNext:- 将LM和事务通过
InsertTuple给到表堆(这个方法是重载的,这里指的是auto InsertTuple(const TupleMeta &meta, const &tuple, LockManager *lock_mgr = nullptr, Transaction *txn = nullptr, table_oid_t oid = 0) -> std::optional<RID>;) - 维护write set
- 将LM和事务通过
-
Delete算子:
Init:如果已经按照上面实现的SeqScan算子(涉及IsDelete),则不需要上任何锁Next:维护write set
-
Transaction Manager:
Commit:仅仅是释放事务相关锁Abort:根据write set去revert这个事务的所有changes
没Summary,就是写烦了放一放,写崩了删掉重写(