Rethinking BiSeNet For Real-time Semantic Segmentation
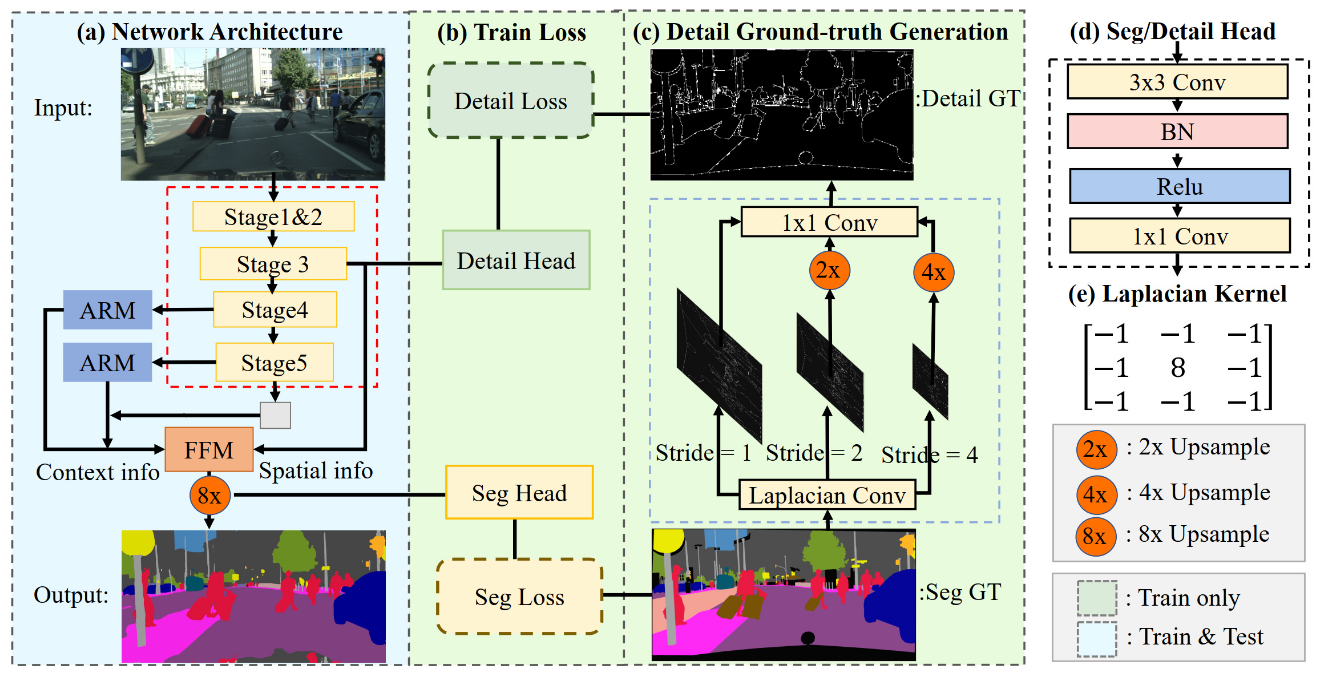
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
@inproceedings{fan2021rethinking,
title={Rethinking BiSeNet For Real-time Semantic Segmentation},
author={Fan, Mingyuan and Lai, Shenqi and Huang, Junshi and Wei, Xiaoming and Chai, Zhenhua and Luo, Junfeng and Wei, Xiaolin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={9716--9725},
year={2021}
}We have provided ImageNet Pretrained STDCNet Weights models converted from official repo.
If you want to convert keys on your own to use official repositories' pre-trained models, we also provide a script stdc2mmseg.py in the tools directory to convert the key of models from the official repo to MMSegmentation style.
python tools/model_converters/stdc2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH} ${STDC_TYPE}E.g.
python tools/model_converters/stdc2mmseg.py ./STDCNet813M_73.91.tar ./pretrained/stdc1.pth STDC1
python tools/model_converters/stdc2mmseg.py ./STDCNet1446_76.47.tar ./pretrained/stdc2.pth STDC2This script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| STDC 1 (No Pretrain) | STDC1 | 512x1024 | 80000 | 7.15 | 23.06 | 71.82 | 73.89 | config | model | log |
| STDC 1 | STDC1 | 512x1024 | 80000 | - | - | 74.94 | 76.97 | config | model | log |
| STDC 2 (No Pretrain) | STDC2 | 512x1024 | 80000 | 8.27 | 23.71 | 73.15 | 76.13 | config | model | log |
| STDC 2 | STDC2 | 512x1024 | 80000 | - | - | 76.67 | 78.67 | config | model | log |
Note:
- For STDC on Cityscapes dataset, default setting is 4 GPUs with 12 samples per GPU in training.
No Pretrainmeans the model is trained from scratch.- The FPS is for reference only. The environment is also different from paper setting, whose input size is
512x1024and768x1536, i.e., 50% and 75% of our input size, respectively and using TensorRT. - The parameter
fusion_kernelinSTDCHeadis not learnable. In official repo,find_unused_parameters=Trueis set here. You may check it by printing model parameters of original repo on your own.