This tutorial introduces the ArchivesSpace API by way of a common archival data cleanup task: updating container numbers. In the following sections you will learn how to:
- Set up a Python environment on your local computer
- Connect to the ArchivesSpace API
- Retrieve top container data for a collection
- Update top container indicators in bulk using a spreadsheet as input.
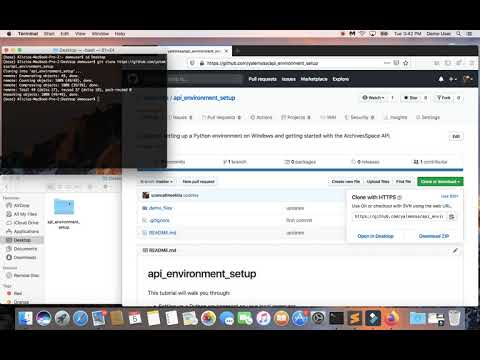
To get started, clone or download this repository.
Clone or download repo demo:
- Miniconda (Python 3.7+)
- Access to ArchivesSpace API and/or MySQL database
While many computers come with Python built-in, it is often many versions behind the latest release. Installing or upgrading Python packages in the system installation of Python can also cause unexpected conflicts and errors within existing programs. It is highly recommended that you use a virtual environment to avoid these issues.
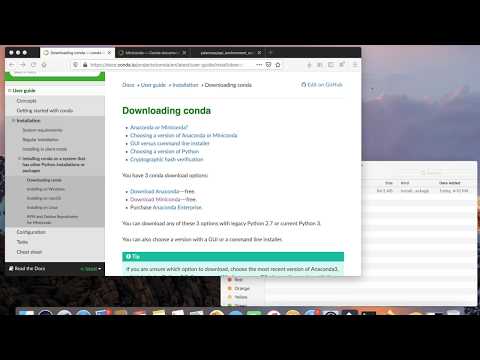
There are many varieties of virtual environments, each with their own benefits and drawbacks. Anaconda and Miniconda are frequently used by those-who-work-with-data (including archivists!), and they come with frequently-used data processing packages preinstalled. Miniconda is a lightweight version of Anaconda, and both are based on conda. A good intro to conda can be found here.
- If you already have the full version of Anaconda, uninstall it
- Download Miniconda
- Click on the installer and follow the on-screen setup instructions. Store the program in your home directory (i.e.
C:\Users\your_username\Miniconda3,/Users/your_username/Miniconda3). On Windows, if you choose, per the installer's recommendations, not to add Miniconda to your PATH, you will need to use the Anaconda Prompt or Anaconda Powershell to interact with the interpreter and run scripts from the command line. The Mac installer should automatically make Miniconda your default Python installation. - After the program is installed, click on the Windows start menu and open the Anaconda Prompt or Anaconda Powershell. If using a Mac, open a Terminal window.
Download and install Miniconda demo:
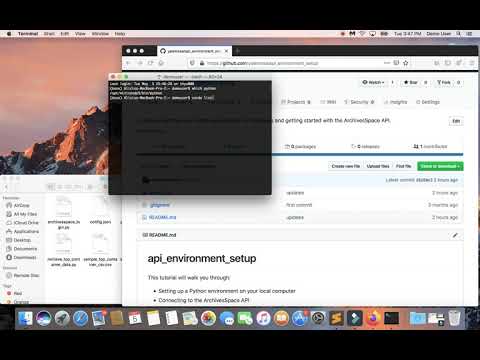
Open the Anaconda Prompt or Terminal and enter python. This will open the interactive Python interpreter. To check the location of your Python installation, enter import sys. Then, enter sys.executable. You should see the path to your Miniconda Python executable. To close the Python interpreter and return to the prompt, enter quit().
To see what Python packages are currently installed, type conda list into the prompt. You should see that requests is already installed. If it is not, enter conda install requests into the Anaconda prompt.
On a Mac you can also type which python into the Terminal to make sure that you are using the Miniconda distribution.
Start Python, check distribution demo:
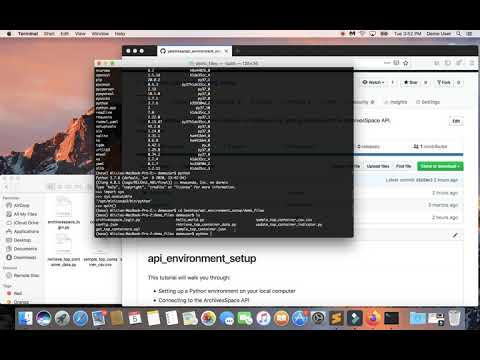
In addition to typing Python commands into the interactive interpreter, you can also run .py files from the Anaconda Prompt or Terminal, and you can import the code from .py files into the interactive interpreter or into other .py files. To run the hello_world.py file, open the Anaconda Prompt or Terminal and enter the following:
#on a Mac this should be something like cd /Users/your_username/path/to/api_environment_setup/demo_files
$ cd C:\Users\your_username\path\to\api_environment_setup\demo_files
demo_files $ python hello_world.py
...stuff happens...
demo_files $
Running scripts from the command line demo:
To connect to the ArchivesSpace API, you first need to enter your credentials into the config.json file included in the demo_files directory. Then open the Anaconda Prompt/Powershell or Terminal (be sure that you are still in the demo_files directory before you open the interpreter) and do the following:
demo_files $ python
Python 3.7.3 (default, Mar 27 2019, 16:54:48)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda custom (64-bit) on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import json
>>> import requests
>>> import archivesspace_login as as_login
>>> api_url, headers = as_login.login()
Login successful!
>>> api_url
https://archivesspace.university.edu/api
>>> headers
LONGSTRINGOFNUMBERSANDLETTERSREPRESENTINGAUTHKEY
The import archivesspace_login as as_login line imports the archivesspace_login.py file into the Python interpreter. This file contains a login() function which you can run to log in to the API. The API URL and the authentication key are stored in the api_url and headers variables so that they can be used in other parts of the script.
Connect to ArchivesSpace API demo:
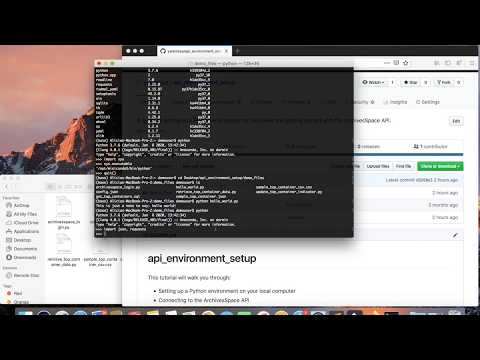
If your login credentials are invalid you should be prompted to enter them again into the interpreter. If your login credentials were accepted, you can send your first API request - to retrieve a top container JSON record - by entering the following into the Python interpreter:
>>> import pprint
>>> top_container_uri = '/repositories/12/top_containers/239815'
>>> top_container_json = requests.get(f"{api_url}/{top_container_uri}", headers=headers).json()
>>> pprint.pprint(top_container_json)
{'active_restrictions': [],
'barcode': '39002102377802',
'collection': [{'display_string': 'Rights and Wrongs records',
'identifier': 'MS 1821',
'ref': '/repositories/12/resources/4869'}],
'container_locations': [],
'container_profile': {'ref': '/container_profiles/113'},
'create_time': '2016-10-14T19:31:11Z',
'created_by': 'cconnoll',
'display_string': 'Box 153D: Series 4 [39002102377802]',
'ils_holding_id': '6879939',
'indicator': '153D',
'is_linked_to_published_record': True,
'jsonmodel_type': 'top_container',
'last_modified_by': 'amd243',
'lock_version': 7,
'long_display_string': 'MS 1821, Series 4, Box 153D [39002102377802], video '
'Beta',
'repository': {'ref': '/repositories/12'},
'restricted': True,
'series': [{'display_string': 'Programs, 1993-1996',
'identifier': '4',
'level_display_string': 'Series',
'publish': True,
'ref': '/repositories/12/archival_objects/2012461'}],
'system_mtime': '2019-10-29T12:53:50Z',
'type': 'Box',
'uri': '/repositories/12/top_containers/239815',
'user_mtime': '2018-09-28T13:04:43Z'}
You will notice that the JSON response corresponds to the fields and values that you see when you look at this record in the staff interface.
Top containers and all other "top level" ArchivesSpace records can be accessed via the API by unique URIs, which correspond with their database identifiers (a very brief overview of "top level" records and the AS data model can be found in the second section of this article, or here). Top containers are scoped to repositories, and so the URI also includes the repository number, for instance /repositories/12/top_containers/32918. See the ArchivesSpace API documentation for more detailed explanations of how URIs and other parameters are formulated.
Retrieve single record demo:
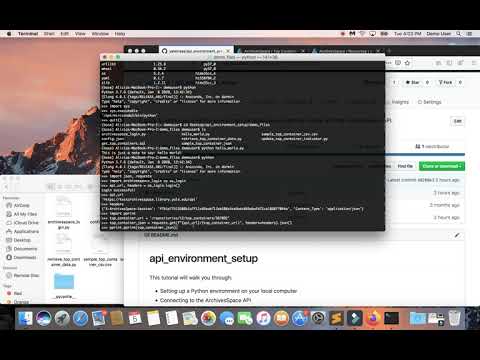
JSON objects are treated essentially like Python dictionaries, which means that Python comes with a variety of built-in ways to manipulate the data that comes from ArchivesSpace.
Updating top container indicators (changing box numbers) is straightforward, as the indicator field is non-repeatable string value that is located at the top level of the record (i.e. it is not nested in a list or other dictionary).
To update an existing top container indicator, open a Python interpreter session (be sure you are in the demo_files directory) and execute the following code:
>>> top_container_json = requests.get(f"{api_url}/{top_container_uri}", headers=headers).json()
>>> top_container_json['indicator'] = '26'
>>> post_record = requests.post(f"{api_url}/{top_container_uri}", headers=headers, json=top_container_json).json()
>>> print(post_record):
{'status': 'updated', 'lock_version': 8, 'id': 239185, uri': '/repositories/12/top_containers/239815'}
>>>
Update single record demo:
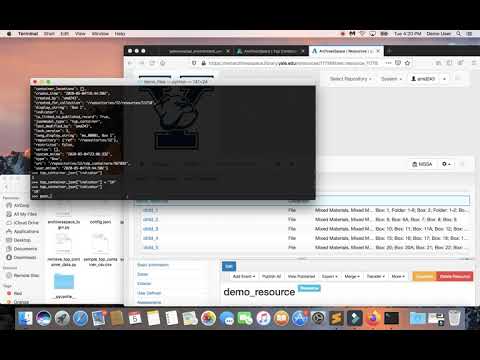
You can update ArchivesSpace data in bulk with Python using a spreadsheet as input. To update a top container indicator you only need the URI of the top container and the new box number. However, you may also want to include the old box number in your spreadsheet so that you can keep track of the previous value while preparing your data and to have a record if something goes wrong.
The easiest way to retrieve existing data from ArchivesSpace and prepare it for update is via the MySQL database. Retrieving data from the API is often slower, and it takes extra processing to manipulate the JSON response into the spreadsheet formats that many archivists rely on use to create and update archival description. Here is a sample query for retrieving top container indicators for two series within a single collection:
select DISTINCT CONCAT('/repositories/', tc.repo_id, '/top_containers/', tc.id) as uri
, tc.indicator as old_box_number
from archival_object ao
left join archival_object ao2 on ao2.id = ao.parent_id
left join archival_object ao3 on ao3.id = ao2.parent_id
left join instance on instance.archival_object_id = ao.id
left join sub_container sc on sc.instance_id = instance.id
left join top_container_link_rlshp tclr on tclr.sub_container_id = sc.id
left join top_container tc on tclr.top_container_id = tc.id
LEFT JOIN enumeration_value ev2 on ev2.id = tc.type_id
where ao.root_record_id = 11718
and tc.id is not null
ORDER BY CAST(tc.indicator AS UNSIGNED)
After running this query you can export the results as a CSV. Open the file and add a column called 'new_box_number'. Then you can fill in the column with the new box number. Save the CSV file.
There are also a few ways to retrieve top container data via the API. This are especially useful if you do not have access to the ArchivesSpace database. The most efficient method for retrieving all top containers in a collection is to use the repositories/:repo_id/top_containers/search endpoint. To retrieve a list of top containers for a given resource, import your modules and enter the following into the Python interpreter:
>>> resource_uri = '/repositories/12/resources/11718'
>>> query = f'{{"query":{{"jsonmodel_type": "field_query", "field": "collection_uri_u_sstr", "value": "{resource_uri}", "literal":true}}}}'
>>> tc_search = requests.get(api_url + "/repositories/12/top_containers/search?filter=" + query, headers=headers).json()
>>> tc_data = [[item['id'], item['json']['indicator']] for item in tc_search['response']['docs']
if `response` in tc_search]
>>> pprint.pprint(tc_data)
The full version of this code is saved in the retrieve_top_container_data.py file so it can be run from the Anaconda Prompt or Terminal. It will output a spreadsheet with two columns: the top container URI will be in the first column and the current box number will be in the second column. It will also have a third column "new_box_number", where you can enter the new box numbers.
Retrieve containers demo:
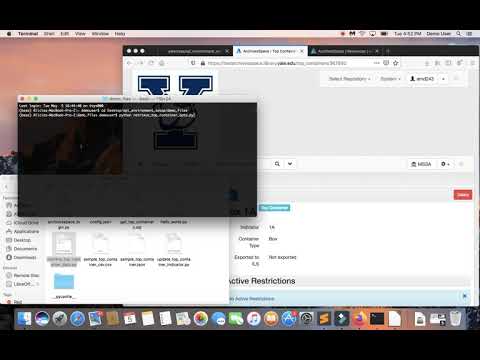
Update numbers in spreadsheet demo:
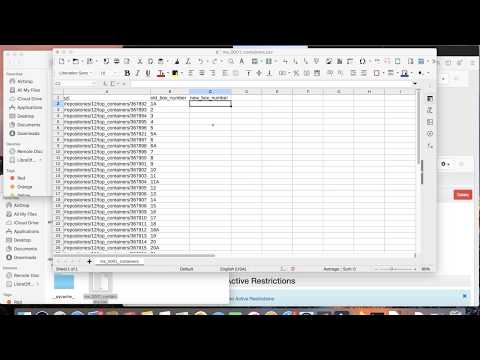
NOTE: There is a /repositories/:repo_id/resources/:id/top_containers endpoint which retrieves similar data, but it is very slow when run against a large resource, as it essentially just loops through all of the archival object records and pulls top container data. It also, as of version 2.7.1, is a bit buggy.
Opening your CSV file and using it to update multiple top container indicators takes only a few more lines of code than the example above which updates a single indicator. To perform the update, import your modules, connect to the ArchivesSpace API, and execute the following code in a Python interpreter (change the file path formulation to /Users/username/path/to/file if using a Mac):
>>> with open('C:\\Username\\Path\\To\\File.csv', 'r', encoding='utf-8') as csvfile:
... csvreader = csv.reader(csvfile)
... next(csvreader, None)
... for row in csvreader:
... top_container_uri = row[0]
... new_box_number = row[2]
... try:
... top_container_json = requests.get(f"{api_url}/{top_container_uri}", headers=headers).json()
... top_container_json['indicator'] = new_box_number
... post_record = requests.post(f"{api_url}/{top_container_uri}", headers=headers, json=top_container_json).json()
... print(post_record)
... except:
... print(traceback.format_exc())
... continue
...
<OUTPUT>
>>>
The full version of this code is also saved in the update_top_container_indicator.py file so it can be run from the Anaconda Prompt. Be aware that this code requires that the top container URI be in the first column of the spreadsheet, the old box number in the second column, and the new box number in the third.
Updating containers in bulk demo:
Updating folder numbers in ArchivesSpace uses a different process than updating box numbers. Sub-container information is stored in instance subrecords in archival object or resource records. This means that the records cannot be accessed directly via their own URIs, but rather via the URI of the archival object or resource record to which they are linked.
Below is an example of an archival object JSON record with two instances. One of these instances has a sub_container subrecord, which is where folder numbers are stored. Note that some fields have been removed for the sake of clarity.
{'create_time': '2015-06-01T19:16:49Z',
'created_by': 'admin',
'dates': [{'begin': '1991-08-14',
'create_time': '2015-06-01T19:16:49Z',
'created_by': 'admin',
'date_type': 'single',
'expression': '1991 August 14',
'jsonmodel_type': 'date',
'label': 'creation',
'last_modified_by': 'admin',
'lock_version': 0,
'system_mtime': '2018-02-09T20:28:50Z',
'user_mtime': '2015-06-01T19:16:49Z'}],
'display_string': 'Beinecke, William S., 1991 August 14',
'extents': [],
'instances': [{'create_time': '2015-06-01T19:16:49Z',
'created_by': 'admin',
'instance_type': 'mixed_materials',
'is_representative': False,
'jsonmodel_type': 'instance',
'last_modified_by': 'admin',
'lock_version': 0,
'sub_container': {'create_time': '2015-06-01T19:16:49Z',
'created_by': 'admin',
'indicator_2': '5',
'jsonmodel_type': 'sub_container',
'last_modified_by': 'admin',
'lock_version': 0,
'system_mtime': '2015-06-01T19:16:49Z',
'top_container': {'ref': '/repositories/12/top_containers/96186'},
'type_2': 'folder',
'user_mtime': '2015-06-01T19:16:49Z'},
'system_mtime': '2015-06-01T19:16:49Z',
'user_mtime': '2015-06-01T19:16:49Z'}],
'jsonmodel_type': 'archival_object',
'last_modified_by': 'admin',
'level': 'file',
'parent': {'ref': '/repositories/12/archival_objects/815180'},
'publish': True,
'repository': {'ref': '/repositories/12'},
'resource': {'ref': '/repositories/12/resources/2623'},
'system_mtime': '2021-05-04T18:12:01Z',
'title': 'Beinecke, William S.',
'uri': '/repositories/12/archival_objects/815185',
'user_mtime': '2015-06-01T19:16:49Z'}
The get_folder_numbers.sql and update_sub_container_indicator.py files can be used together to retrieve and update archival object instance records.
Run the get_folder_numbers.sql query in an SQL client to retrieve folder numbers for a given collection or series. Add the new folder number in column H.
Run the update_sub_container_indicator.py script using the same process
Creating and updating records via the ArchivesSpace API is fast and convenient, but can be dangerous. There is no undo button, and problems can have cascading effects. In order to prevent errors that may take significant effort to identify and remedy, please follow these guidelines:
- When running any updates against the API, have another staff member review your:
- Input data
- Code
- Test output
- ALWAYS run your updates in TEST or DEV before running in production
- Keep all JSON backups, log files, input data, and code. Organize your files by project/task. Document any and all actions you take. Due to the lack of an "edit history" in ArchivesSpace, it can be difficult to trace the source of data quality issues.
- ArchivesSpace API Documentation
- RealPython Python Data Types
- RealPython An Effective Python Environment: Making Yourself at Home
- RealPython Running Python Scripts
- RealPython Python Dictionaries
- RealPython Introduction to Python learning path
- Setting up a miniconda environment
- Python for Archivists