查看hadoop的目录结构:
[wzq@hadoop102 hadoop-3.1.3]$ ll
总用量 176
drwxr-xr-x. 2 wzq wzq 183 9月 12 2019 bin
drwxr-xr-x. 3 wzq wzq 20 9月 12 2019 etc
drwxr-xr-x. 2 wzq wzq 106 9月 12 2019 include
drwxr-xr-x. 3 wzq wzq 20 9月 12 2019 lib
drwxr-xr-x. 4 wzq wzq 288 9月 12 2019 libexec
-rw-rw-r--. 1 wzq wzq 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 wzq wzq 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 wzq wzq 1366 9月 4 2019 README.txt
drwxr-xr-x. 3 wzq wzq 4096 9月 12 2019 sbin
drwxr-xr-x. 4 wzq wzq 31 9月 12 2019 share重要目录:
bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本ect目录:Hadoop的配置文件目录,存放Hadoop的配置文件lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)sbin目录:存放启动或停止Hadoop相关服务的脚本share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop的运行模式包括:本地模式、伪分布式以及完全分布式
- 本地模式:单机运行,只是用来演示一下官方案例。 生产环境不用
- 伪分布式模式:也是单机运行,但是具备
Hadoop集群的所有功能,一台服务器模拟一个分布式的环境, 个别缺钱的公司用来测试,生产环境不用 - 完全分布式模式:多台服务器组成分布式环境, 生产环境不用
本人学习阶段全部使用伪分布式模式
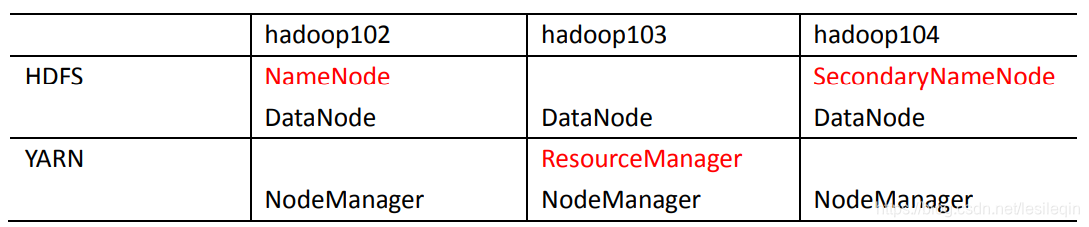
需要注意的是:
NameNode和SecondaryNameNode不安装在同一个虚拟机ResourceManager很消耗内存,不和NameNode与SecondaryNameNode配置在同一台虚拟机
只要用户想修改某一默认配置文件中的配置,才需要修改自定义配置文件,更改相应属性值
| 默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| core-default.xml | hadoop-common-3.1.3,jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-3.1.3,jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-3.1.3,jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapred-client=core-3.1.3,jar/mapred-default.xml |
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml均存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置
进入到$HADOOP_HOME/etc/hadoop:

vim core-site.xml;将以下代码插入到<configuration></configuration>标签中
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 你的用户名-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>你的用户名!!!!<alue>
</property>vim hdfs-site.xml将以下代码插入到<configuration></configuration>标签中
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>vim yarn-site.xml将以下代码插入到<configuration></configuration>标签中:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>22528</value>
<discription>每个节点可用内存,单位MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1500</value>
<discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
<discription>单个任务可申请最大内存,默认8192MB</discription>
</property>
<!-- Site specific YARN configuration properties -->
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>vim mapred-site.xml将以下代码插入到<configuration></configuration>标签中:
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>1500</value>
<description>每个Map任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3000</value>
<description>每个Reduce任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1200m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2600m</value>
</property>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>xsync /opt/module/hadoop-3.1.3/etc/hadoop/效果如下:
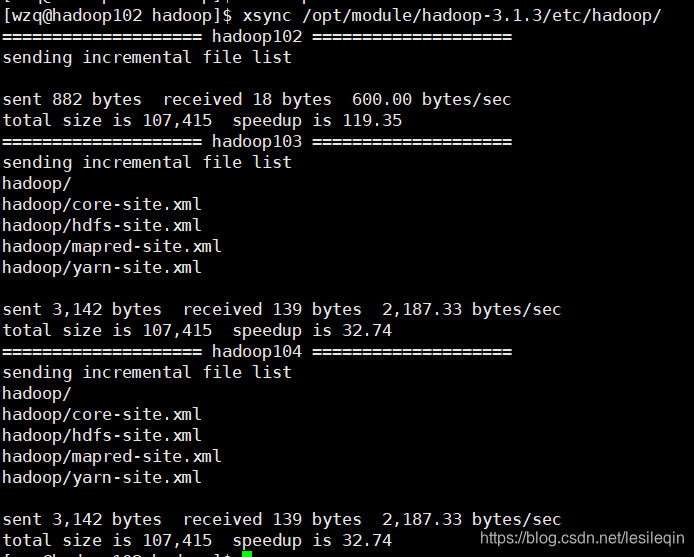
然后去另外两台机器验证有没有分发成功
为了查看程序的历史运行情况,需要配置一下历史服务器。
在配置历史服务之前,需要在hadoop103上停掉yarn
[wzq@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh编辑mapred-site.xml:
[wzq@hadoop103 hadoop-3.1.3]$ vim etc/hadoop/mapred-site.xml在mapred-site.xml中插入以下代码:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>配置完成之后,一定要把配置文件分发到另外两台虚拟机
[wzq@hadoop102 hadoop-3.1.3]$ xsync etc/hadoop/
在启动历史服务器之前,需要先在hadoop103上启动yarn:
[wzq@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh随后在hadoop102的hadoop/bin目录上启动历史服务器:
[wzq@hadoop102 bin]$ mapred --daemon start historyserver使用jps命令查看:
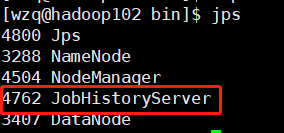
搞个wordcount程序测试历史服务器:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /woutput回车等待运行成功之后,打开http://hadoop103:8088,可以看到有一个任务已经成功运行:

点击蓝色的history,就可以查看历史服务器的内容了:

上图中可以看到点击history后跳转到了19888端口
但是值得我们注意的是,右下角有个logs,这里是查看程序运行的日志,现在点击一下:

报错了,这是因为还没有配置日志聚集,下面来配置一下。
如下图所示,每个hadoop服务器都有自己的日志,但是如果程序出了bug,在单个服务器上查看日志是很不方便的,所以hadoop就做了日志聚集的功能,他把所有服务器的日志都聚集到了hdfs

日志聚集的好处就是可以方便查看程序的运行详情,方便开发调试
编辑yarn-site.xml:
[wzq@hadoop102 hadoop-3.1.3]$ vim etc/hadoop/yarn-site.xml在yarn-site.xml最后插入以下代码:
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>配置完成之后要做集群分发:
[wzq@hadoop102 hadoop-3.1.3]$ xsync etc/hadoop/
因为修改了yarn的配置文件,所以需要在hadoop103上重启yarn和在hadoop102上重启HistoryServer历史服务器
停止yarn:
[wzq@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh 停止HistoryServer:
[wzq@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver启动yarn:
[wzq@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh 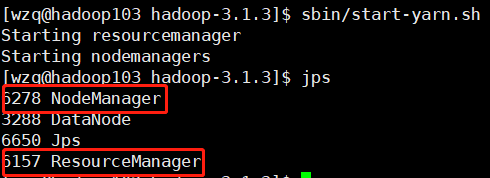
启动historyserver:
[wzq@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
删除刚刚测试历史服务器中自动生成的woutput文件夹:
[wzq@hadoop103 hadoop-3.1.3]$ hadoop fs -rm -r /woutput
执行wordcount程序:
[wzq@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output在程序运行期间,可以打开yarn:

可以看到正在执行,等待执行完成,点击History:

再点进去logs:

日志聚集配置成功
