下图为文件写入流程剖析图:

想要上传一个200M的文件ss.avi到HDFS,它的写入流程是这样的:
- 客户端创建
Distributed FileSystem,该模块向HDFS的老大哥NameNode请求上传文件ss.avi - 老大哥
NameNode是个做事很守规矩的人,所以他要检查权限和目录结构是否存在,如果存在就向Distributed FileSystem响应可以上传文件 - 但是
Distributed FileSystem并不知道我上传的文件应该传给哪个小老弟(DataNode1、2、3),就问老大哥:”大哥,我应该上传到哪个DataNodee小老弟服务器啊?“ - 老大哥
NameNode需要想一下文件应该存到哪个机器上(这个过程叫做副本存储节点选择,下文有写),想好之后就返回dn1、2、3说”这三个可以存文件“ - 这时候客户端就要创建
文件输出流FSDataOutPutStream让他去上传数据 - 数据是需要通过
管道进行传输的,所以文件输出流就需要先铺设管道,它首先请求dn1、dn1再调用dn2,最后dn2调用dn3,将这个通信管道建立完成,dn1、2、3逐级应答客户端建立完毕 - 这时候,客户端就开始往
dn1上传第一个Block,以Packet为单位,dn1收到一个Packet就会传给dn2,dn2再传给dn3。为了保证数据不丢失,三个机器在传数据的时候,都有自己的一个应答对列放Packet,直到收到下一台机器传回的ack应答信息,才把Packet删掉。 - 当一个
Block传输完成之后,客户端会再次请求NameNode上传第二个Block的服务器。重复执行上面的操作,直到所有的数据都上传完成
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据,需要计算出这个距离。
节点距离:两个节点到达最近的功能祖先的距离总和
现实生活中,服务器都会在机架上放着,然后形成一个图,看下图:
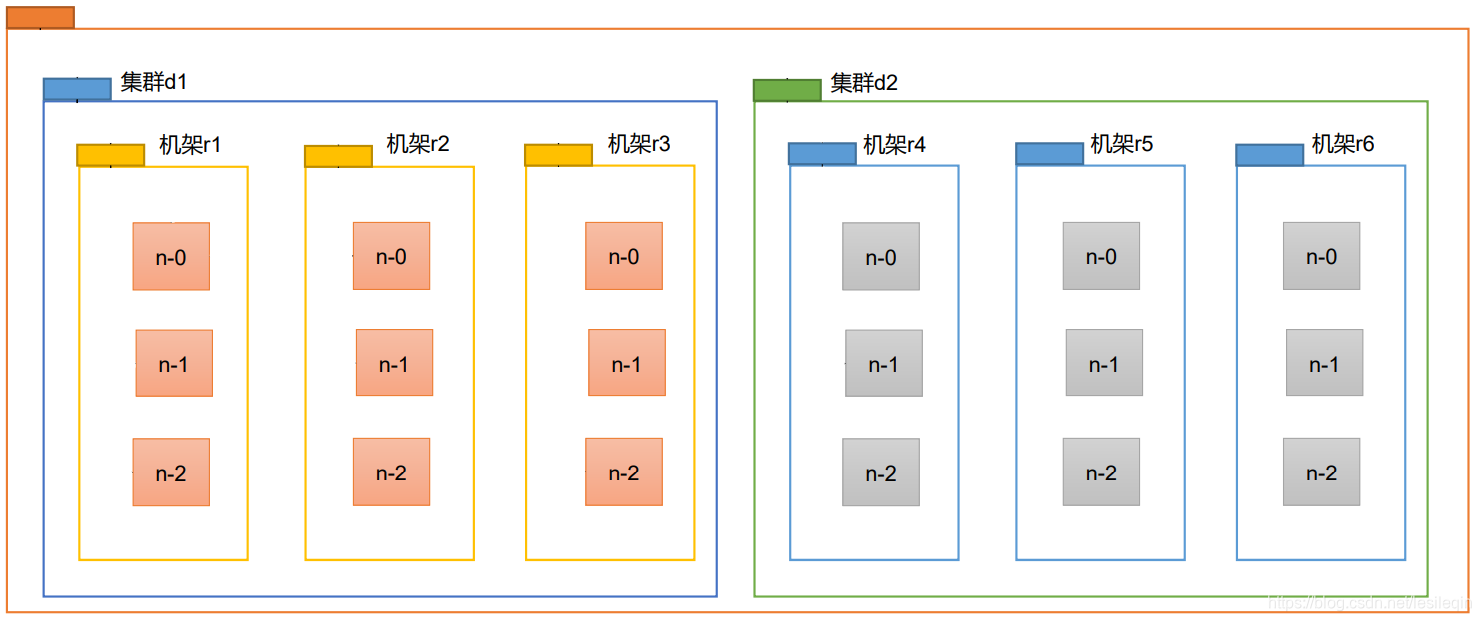
我们要想计算节点距离,可以把他抽象成一个图:

如果我们要算机器d1->r2->n1到d2->r6->n0的距离,则需要找到他们的共同祖先,然后把把路径相加就可以了,如下图所示:
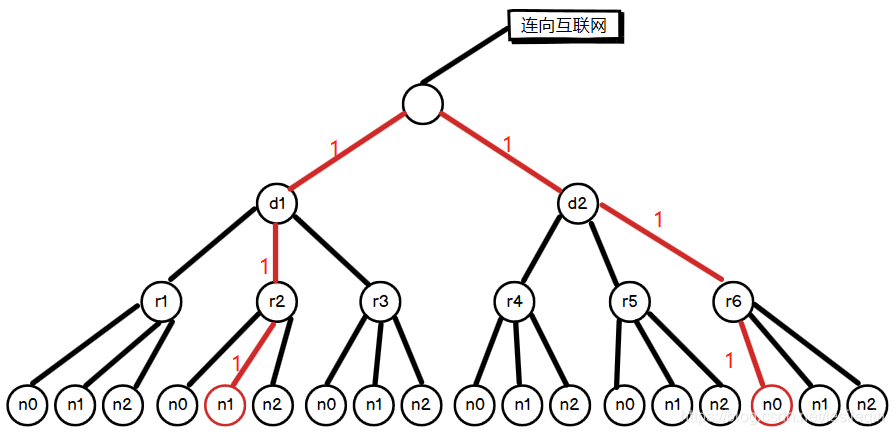
则:Distance(d1/r2/n1,d2/r6/no) = 6
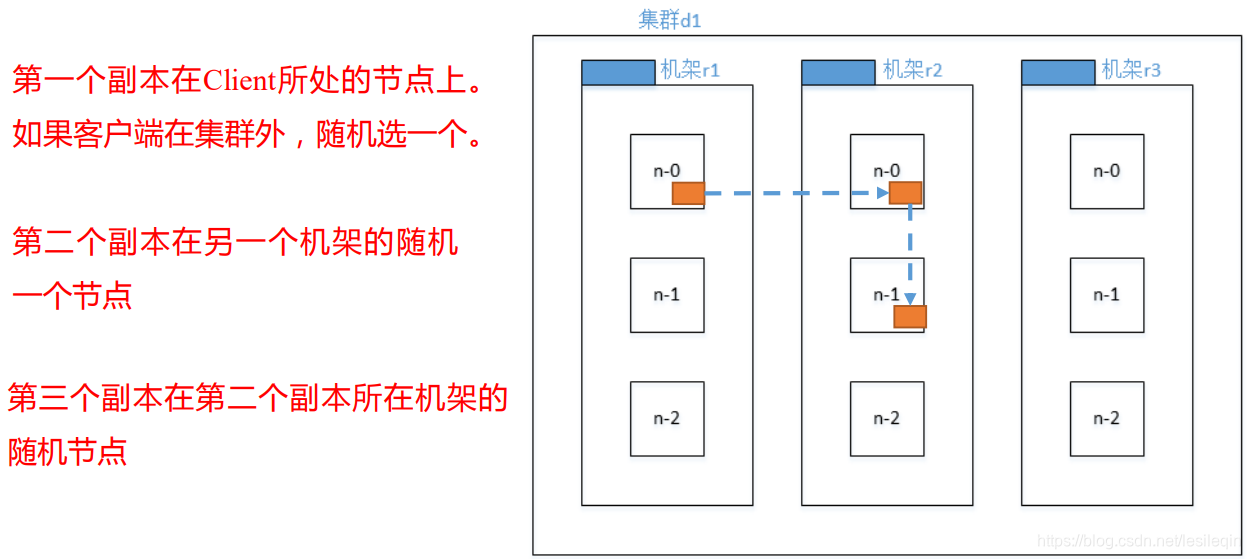
HDFS写文件会把第一个副本存储在客户端所处节点上,第二个副本在另一个机架上的随机一个节点,第三个副本在第二个副本所在机架的另外一个随机节点上。如下图所示:
HDFS读数据流程如下图所示:
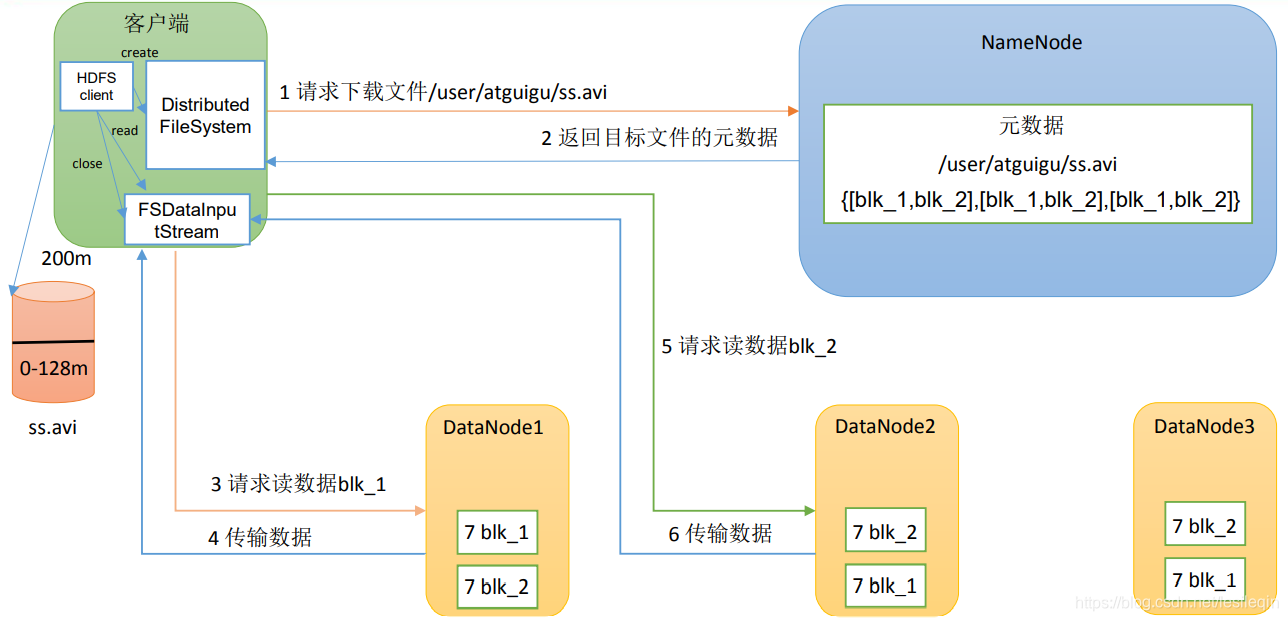
- 客户端通过
DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址 - 挑选一台
DataNode(就近原则,然后随机)服务器,请求读取数据 DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)- 客户端以
Packet为单位接收,现在本地缓存,然后写入目标文件